

正则表达式(基础篇)
1 什么是正则表达式
正则表达式(英语:Regular Expression,在代码中常简写为regex、regexp或RE),又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法,是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。 --Wikipedia
简单的来说,正则表达式就是一个字符串,代表了一定的格式,然后我们用这个字符串去判断另外一个字符串中有没有符合这个格式的字符串。例如有一串记录了学生姓名学号等信息的字符串
student = “张三 2017612403”
现在想把这个字符串中学生的学号也就是“2017612403”这个字符串提取出来,已知学号都是10位的。使用最简单的正则表达式怎么做呢?如下:
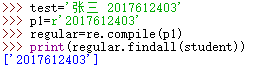
p1 = r’ 2017612403’
regular=re.compile(p1)
print(reg ular.findall(student))
是不是很简单,前面说过,正则表达式表示的其实就是一个格式,然后程序用在另一个字符串中找到符合这个格式的字符串,上面这个程序中,第一句话设置正则表达式的字符串,这里是p1 = r’2017612403’。然后第二句话表示将字符串编译成一个正则表达式(Pattern)对象,也就是把字符串转换成其对应的格式,这里的格式就是表示从待匹配的字符串中寻找一个’ 2017612403’子字符串。第三句话就是执行正则表达式寻找待匹配字符串中满足格式的子字符串了,如果匹配到,python中会返回所有匹配的子字符串列表。执行结果如下:
所以说,可以简单地将正则表达式理解为表达了一定格式的字符串,程序通过这个格式,在待匹配的字符串中寻找满足这个格式的子字符串,并返回所有找到的子字符串的列表(python)。
2 正则表达式常用规则
2.1 匹配任意字符
假设有一段字符串:
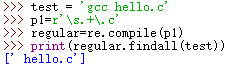
test = ‘gcc hello.c’
需要从中将hello.c匹配出来,可以使用正则表达式:
p1 = r’\s.+\.c’
执行结果:
现在解释一下上面的正则表达式:r’\s.+\.c’。’\s’、’+’、’.’都是正则表达式中的元字符,正则表达式中常用的元字符定义为:
|
. |
代表任意字符 |
|
| |
逻辑或操作符 |
|
[ ] |
匹配内部的任一字符或子表达式 |
|
[^] |
对字符集和取非 |
|
- |
定义一个区间 |
|
\ |
对下一字符取非(通常是普通变特殊,特殊变普通) |
|
* |
匹配前面的字符或者子表达式0次或多次 |
|
*? |
惰性匹配上一个 |
|
+ |
匹配前一个字符或子表达式一次或多次 |
|
+? |
惰性匹配上一个 |
|
? |
匹配前一个字符或子表达式0次或1次重复 |
|
{n} |
匹配前一个字符或子表达式 |
|
{m,n} |
匹配前一个字符或子表达式至少m次至多n次 |
|
{n,} |
匹配前一个字符或者子表达式至少n次 |
|
{n,}? |
前一个的惰性匹配 |
|
^ |
匹配字符串的开头 |
|
\A |
匹配字符串开头 |
|
$ |
匹配字符串结束 |
|
[\b] |
退格字符 |
|
\c |
匹配一个控制字符 |
|
\d |
匹配任意数字 |
|
\D |
匹配数字以外的字符 |
|
\t |
匹配制表符 |
|
\w |
匹配任意数字字母下划线 |
|
\W |
不匹配数字字母下划线 |
从表中我们知道,’\s’表示匹配任意的空白字符一次,’.’表示匹配任意字符(换行符除外)一次,有关’+’的详细规则将在2.2中介绍,现在只需要知道它的作用是重复匹配其前面的字符,比如这里,’+’前面的字符是’.’,就表示在这里可以有任意数量的字符,而且字符的内容也是任意的。于是上述正则表达式r’\s.+\.c’就可以知道其作用如下:
需要匹配的格式为:以一个空白字符开始,紧跟着任意个数的任意字符,并以’.c’格式结尾,也就是’ xxx.c’这种格式。
2.2 重复匹配的元字符
上面已经了解了什么是正则表达式,也了解了重复匹配元字符’+’的用法。现在看一下1中的正则表达式,会发现它只能匹配’ 2017612403’这一个字符串,如果需要提取一个班中所有人的学号,用上面的正则表达式的话,岂不是要将所有人的学号都列出来,这样还需要程序干嘛?下面介绍正则表达式的一些基本规则,使用这些规则我们可以写出灵活度很高的匹配规则。
还是上面的例子,如果一个班有60人,学生的信息都以”姓名 学号”的格式储存在all_student这个列表中,需要提取所有人的学号信息,如果不用正则表达式,在python中可以使用下面的语句:
all_student_id = [student[-10:] for student in all_student]
这样的问题是,如果student的格式稍微改变一下或添加了其他的信息,如写成:
student = “张三 2017612403 22 电子信息工程”
那上面的语句就失效了,有没有一种方法能准确的将字符串中十位数的学号提取出来呢?这里就需要使用正则表达式了。先看一下正则表达式里面提取十位数学号的办法:
p1 = r’\d{10}?’
regular=re.compile(p1)
print(reg ular.findall(student))
这里的p1就是正则表达式的字符串,现在看不懂没关系,只需要知道这个正则表达式表示的格式是一个十个数字的字符串,那么执行regular.findall(student)后,正则表达式就会再student这个字符串中寻找一个十个数字的字符串。执行结果:

现在来解释一下上面的正则表达式。正则表达式的字符串为r’\d{10}?’,整个正则表达式可以分解为三部分:’\d’、’{10}’、’?’,这里的’\d’、’{}’、’?’也是正则表达式中的元字符。
’\d’表示需要匹配字符串中的任意一个数字,注意是一个,上面这个例子中,如果设置正则表达式为’\d’的执行结果是这样的:
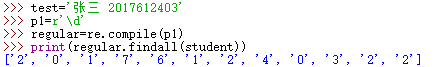
发现虽然数字都匹配出来了,但是每个数字都被分开了,如果需要匹配很多个数字怎么办呢?--使用’+’或’*’这个元字符,’+’表示匹配一个或多个前一个字符,’*’表示匹配0个或多个前一个字符如果这样用的话:r’\d+’就代表匹配一个或多个数字,看一下执行结果:

可以看见使用r’\d+’也将我们需要的学号提取出来了。但是从元字符’+’的定义中可以发现,元字符’+’只是表示匹配一个或多个其前一个字符,没有指定匹配多少次,那么如果待匹配的字符串中有多个数字串的话,比如这样的:
student = “张三 2017612403 22 电子信息工程”
那么正则表达式就会把我们不需要的字符也匹配出来了:

那么如何指定匹配字符的个数呢?这里就需要用到’{}’这个元字符了。有关’{}’的详细介绍可以看上面的表格,’{n}’表示匹配n个前面的字符,已知学号是10位,那么可以用r’\d{10}’来从待匹配字符串中寻找10个连续的数字,也就是我们要提取的学号。
那么只剩最后一个问题了,一开始的正则表达式中的r’\d{10}?’中的’?’是干什么的呢?从’?’元字符的定义中,可以知道它的作用是惰性匹配又称贪婪匹配。
2.3 惰性匹配与贪婪匹配
贪婪匹配就是从待匹配字符串中一次性尽可能多的匹配字符,惰性匹配就是从待匹配字符串中一次性尽可能少的匹配字符。
从2.1中可以知道,元字符’+’、’*’、’{}’可以从待匹配字符串中重复匹配某一个指定的字符,那么就存在这种情况:
test = ‘This is a <EM>first</EM> test’
需要从test中匹配两次分别得到<EM>和</EM>,根据上面的知识,应该用正则表达式:r’<.+>’,但实际上这个表达式执行的结果是:

这是因为python中默认的匹配模式是贪婪匹配,当表达式匹配到一个’>’后,会再次尝试从后面的字符串中匹配’>’,直到遇到换行符,所以这里会一直匹配’<EM>first</EM>’,而不是’<EM>’。为了改变这种行为,需要将匹配模式设置为惰性匹配模式,惰性匹配模式下,当表达式匹配到第一个’>’后,就会直接返回。通过元字符’?’可以将其前面的字符匹配模式设置为惰性匹配模式。
2.4 限定范围的匹配
我们知道web通过<h1></h1>、<h2></h2>这种表示一级标题、二级标题等,如果现在需要提取一个web中三级标题到6级标题中的内容,使用上面的知识,很容易知道,可以使用下面的正则表达式来提取:
p1 = r’<h3>.+</h3>?’
p2 = r’<h4>.+</h4>?’
p3 = r’<h5>.+</h5>?’
这样写起来十分繁琐,而且如果需要匹配的范围是一个很大的范围,就没有办法使用这种方式进行匹配,为了解决这个问题,就需要用到正则表达式范围匹配的规则:’[]’。’[]’中括号中表示了当前位置字符需要满足的取值范围。假设有下面一段待匹配字符串:
test = r’css tss gss rss’
只需要将test中以字符’c、t、r’开头的单词提取出来,可以使用下面的正则表达式:
p1 = r’[ctr]ss’
执行结果:

‘[]’元字符中,在中括号里面的是当前位置上的字符的取值范围,上面的例子表示’ss’前面的字母只能是’c’、’t’、’r’中的一个。
有了限定范围的匹配,正则表达式的规则中,也有限定范围内排除的规则,使用元字符’[^]’来表示,如上面的例子,如果正则表达式写成:
p1 = r’[^ctr]ss’
就会把’ss’前面的字母除了’c’、’t’、’r’之外的单词匹配出来。执行结果:

作者:Brccq
出处:http://www.cnblogs.com/br170525//
出处:http://www.loveyfyq.com//
欢迎转载,必须在文章页面明显位置给出原文连接,如需本博文源代码或者有任何问题,请在博文留下您的邮箱或者问题说明。
