

Node.js 中的进程和线程
Node.js 阻塞
我们利用 Koa 简单地搭建一个 Web 服务,用斐波那契数列方法来模拟一下 Node.js 处理 CPU 密集型的计算任务:

// app.js
const Koa = require('koa')
const router = require('koa-router')()
const app = new Koa()
// 用来测试是否被阻塞
router.get('/test', (ctx) => {
ctx.body = {
pid: process.pid,
msg: 'Hello World'
}
})
router.get('/fibo', (ctx) => {
const { num = 38 } = ctx.query
const start = Date.now()
// 斐波那契数列
const fibo = (n) => {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1
}
fibo(num)
ctx.body = {
pid: process.pid,
duration: Date.now() - start
}
})
app.use(router.routes())
app.listen(9000, () => {
console.log('Server is running on 9000')
})
node app.js 启动服务,用 Postman 发送请求,可以看到,计算 38 次耗费了 617ms,换而言之,因为执行了一个 CPU 密集型的计算任务,所以 Node.js 主线程被阻塞了六百多毫秒。如果同时处理更多的请求,或者计算任务更复杂,那么在这些请求之后的所有请求都会被延迟执行。
我们再新建一个 axios.js 用来模拟发送多次请求,此时将 app.js 中的 fibo 计算次数改为 43,用来模拟更复杂的计算任务:
// axios.js
const axios = require('axios')
const start = Date.now()
const fn = (url) => {
axios.get(`http://127.0.0.1:9000/${ url }`).then((res) => {
console.log(res.data, `耗时: ${ Date.now() - start }ms`)
})
}
fn('test')
fn('fibo?num=43')
fn('test')
效果如下图:

可以看到,当请求需要执行 CPU 密集型的计算任务时,后续的请求都被阻塞等待,这类请求一多,服务基本就阻塞卡死了。对于这种不足,Node.js 一直在弥补。
master-worker
master-worker 模式是一种并行模式,核心思想是:系统有两个及以上的进程或线程协同工作时,master 负责接收和分配并整合任务,worker 负责处理任务。

多线程
线程是 CPU 调度的一个基本单位,只能同时执行一个线程的任务,同一个线程也只能被一个 CPU 调用。如果使用的是多核 CPU,那么将无法充分利用 CPU 的性能。
多线程带给我们灵活的编程方式,但是需要学习更多的 Api 知识,在编写更多代码的同时也存在着更多的风险,线程的切换和锁也会增加系统资源的开销。
worker_threads 工作线程,给 Node.js 提供了真正的多线程能力,worker_threads 是 Node.js 提供的一种多线程 Api。对于执行 CPU 密集型的计算任务很有用,对 I/O 密集型的操作帮助不大,因为 Node.js 内置的异步 I/O 操作比 worker_threads 更高效。worker_threads 中的 Worker,parentPort 主要用于子线程和主线程的消息交互。
将 app.js 稍微改动下,将 CPU 密集型的计算任务交给子线程计算:// app.js
const Koa = require('koa')
const router = require('koa-router')()
const { Worker } = require('worker_threads')
const app = new Koa()
// 用来测试是否被阻塞
router.get('/test', (ctx) => {
ctx.body = {
pid: process.pid,
msg: 'Hello World'
}
})
router.get('/fibo', async (ctx) => {
const { num = 38 } = ctx.query
ctx.body = await asyncFibo(num)
})
const asyncFibo = (num) => {
return new Promise((resolve, reject) => {
// 创建 worker 线程并传递数据
const worker = new Worker('./fibo.js', { workerData: { num } })
// 主线程监听子线程发送的消息
worker.on('message', resolve)
worker.on('error', reject)
worker.on('exit', (code) => {
if (code !== 0) reject(new Error(`Worker stopped with exit code ${code}`))
})
})
}
app.use(router.routes())
app.listen(9000, () => {
console.log('Server is running on 9000')
})
新增 fibo.js 文件,用来处理复杂计算任务:
const { workerData, parentPort } = require('worker_threads')
const { num } = workerData
const start = Date.now()
// 斐波那契数列
const fibo = (n) => {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1
}
fibo(num)
parentPort.postMessage({
pid: process.pid,
duration: Date.now() - start
})
执行上文的 axios.js,此时将 app.js 中的 fibo 计算次数改为 43,用来模拟更复杂的计算任务:

可以看到,将 CPU 密集型的计算任务交给子线程处理时,主线程不再被阻塞,只需等待子线程处理完成后,主线程接收子线程返回的结果即可,其他请求不再受影响。
上述代码是演示创建 worker 线程的过程和效果,实际开发中,请使用线程池来代替上述操作,因为频繁创建线程也会有资源的开销。
多进程
Node.js 为了能充分利用 CPU 的多核能力,提供了 cluster 模块,cluster 可以通过一个父进程管理多个子进程的方式来实现集群的child_process 子进程,衍生新的 Node.js 进程并使用建立的 IPC 通信通道调用指定的模块- cluster 集群,可以创建共享服务器端口的子进程,工作进程使用 child_process 的 fork 方法衍生
新增 fibo-10.js,模拟发送 10 次请求:
const axios = require('axios')
const url = `http://127.0.0.1:9000/fibo?num=38`
const start = Date.now()
for (let i = 0; i < 10; i++) {
axios.get(url).then((res) => {
console.log(res.data, `耗时: ${ Date.now() - start }ms`)
})
}
可以看到,只使用了一个进程,10 个请求慢慢阻塞,累计耗时 15 秒:

接下来,将 app.js 稍微改动下,引入 cluster 模块:
// app.js
const cluster = require('cluster')
const http = require('http')
const numCPUs = require('os').cpus().length
// const numCPUs = 10 // worker 进程的数量一般和 CPU 核心数相同
const Koa = require('koa')
const router = require('koa-router')()
const app = new Koa()
// 用来测试是否被阻塞
router.get('/test', (ctx) => {
ctx.body = {
pid: process.pid,
msg: 'Hello World'
}
})
router.get('/fibo', (ctx) => {
const { num = 38 } = ctx.query
const start = Date.now()
// 斐波那契数列
const fibo = (n) => {
return n > 1 ? fibo(n - 1) + fibo(n - 2) : 1
}
fibo(num)
ctx.body = {
pid: process.pid,
duration: Date.now() - start
}
})
app.use(router.routes())
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`)
// 衍生 worker 进程
for (let i = 0; i < numCPUs; i++) {
cluster.fork()
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`)
})
} else {
app.listen(9000)
console.log(`Worker ${process.pid} started`)
}
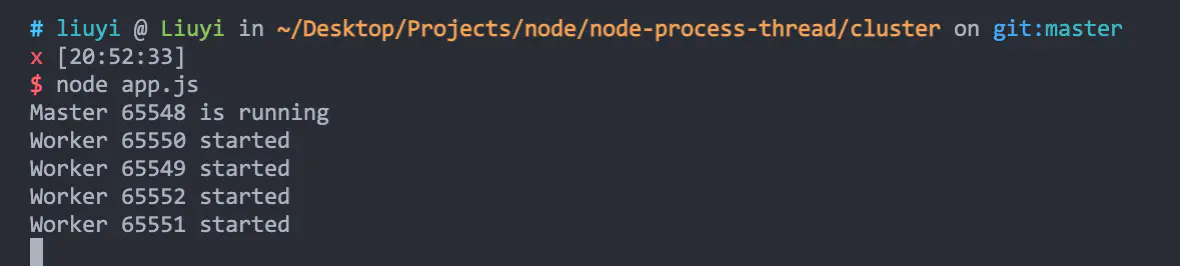
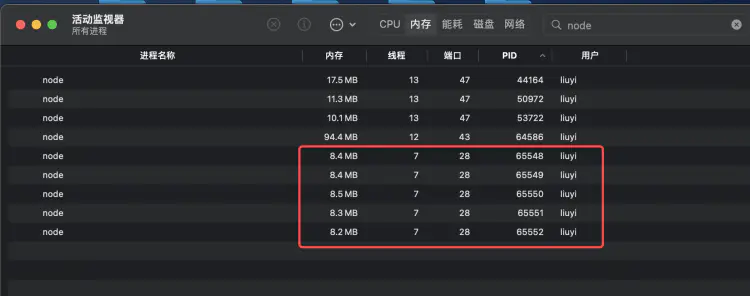
执行 node app.js 启动服务,可以看到,cluster 帮我们创建了 1 个 master 进程和 4 个 worker 进程:
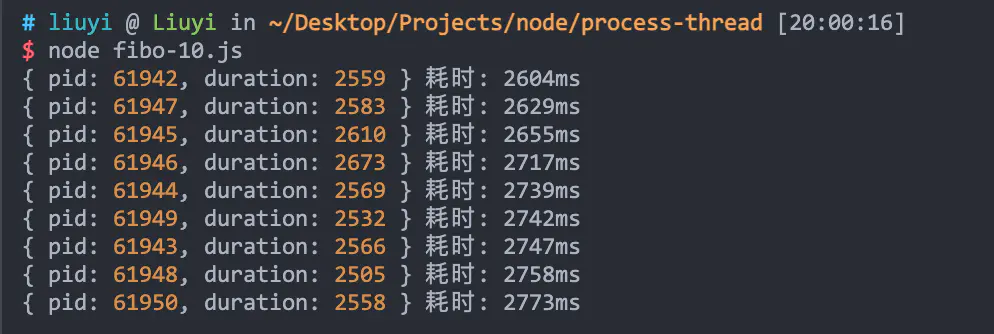
通过 fibo-10.js 模拟发送 10 次请求,可以看到,四个进程处理 10 个请求耗时近 9 秒:

当启动 10 个 worker 进程时,看看效果:
总结
- 大部分通过多线程解决 CPU 密集型计算任务的方案都可以通过多进程方案来替代;
- Node.js 虽然异步,但是不代表不会阻塞,CPU 密集型任务最好不要在主线程处理,保证主线程的畅通;
- 不要一味的追求高性能和高并发,达到系统需要即可,高效、敏捷才是项目需要的,这也是 Node.js 轻量的特点。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具
2019-06-13 如何判断对象是否为空对象