

word count的reduce过程以及项目打包部署
map过程已经写完了,上面那个流程我们涉及到了泛型以及序列化,我们要知道每个参数代表的含义,这样有助于我们理解整个流程。
下面我们开始reduce,这个过程我们要把map输出的键值对把key值相同的放在一起,具体的流程我们看代码:
package MR.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* <KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN, VALUEIN这两个参数是map段输出的值,就是之前的key,value键值对(Text, IntWritable)
* KEYOUT, VALUEOUT这两个参数是我们要输出的数据格式,比如(“hello",5),("Hadoop",1)等等等等
* Reduce类中有一个迭代器,会循环获取数据
* */
//继承Reducer类
public class wcReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
/**
* 重写reduce方法
* Text key:就是读取进来的每一个单词(比如:hello)
* Iterable<IntWritable> values hello这个key里面所有的value值(1,1,1,1,1)
* */
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum=0;
//对values做迭代累加
for (IntWritable value : values) {
//把IntWritable转成int值累加
sum+=value.get();
}
//通过上下文输出
context.write(key,new IntWritable(sum));
}
}
然后我们再写驱动类,这个类基本是一些固定的写法:
package MR.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class wcDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//设置文件输入路径,也是就我们要读取的那个文本文件路径(第一个参数)
//第二个参数是我们的输出路径
String[] path=new String[]{"/word.txt","/output007"};
//设置配置文件
//获取配置文件对象
Configuration conf = new Configuration();
//这里我们可以使用Windows环境里面的hadoop去运行,但是现在我们先把它放到集群上,所以要先配置集群资源
/**
* 配置conf对象,要根据/opt/module/hadoop-2.8.4/etc/hadoop/core-site.xml 这个文件里面的去配置
* <property>
* <name>fs.defaultFS</name>
* <value>hdfs://bigdata101:9000</value>
* </property>
* */
conf.set("fs.defaultFS","hdfs://bigdata101:9000");//设置集群资源地址
//1,加载任务
Job job = Job.getInstance(conf);
//2,设置任务的驱动类(jar加载路径),通过反射获取
job.setJarByClass(wcDriver.class);
//3,设置map程序信息
job.setMapperClass(wcMapper.class);
job.setMapOutputKeyClass(Text.class);//设置输出的key类型,map阶段的输出key类型
job.setMapOutputValueClass(IntWritable.class);//设置输出的value类型,map阶段输出的value类型
//4,设置reduce程序信息
job.setReducerClass(wcReduce.class);
job.setOutputKeyClass(Text.class);//reduce阶段输出的key类型
job.setMapOutputValueClass(IntWritable.class);// reduce阶段的value类型
//5,设置输入路径和输出路径
FileInputFormat.setInputPaths(job,new Path(path[0]));
FileOutputFormat.setOutputPath(job,new Path(path[1]));
// 6,提交任务
boolean res=job.waitForCompletion(true);
System.exit(res?0:1);
System.out.println(res?"执行成功":"执行失败");
}
}
现在整个流程就写完了。写完以后我们先在集群上跑一下试试效果。先打一个jar包:
IDEA 右边:
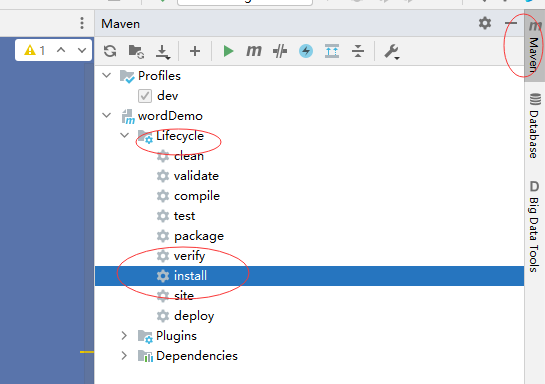
运行完以后我们可以在左边看见打好的jar包:
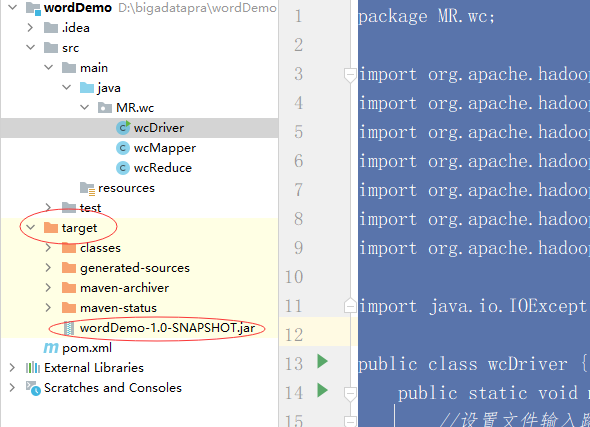
把这个jar包拖到桌面上,改一下名字:wordDemo.jar
然后打开三台虚拟机,在namenode上启动hdfs:start-dfs.sh
在102上启动yarn:start-yarn.sh
启动完毕以后我们先手动建一个文件:vim word.txt
写入数据:
hello world
hello scala
hello spark
hello hadoop
hello mr
保存推出。然后把这个文件放到hdfs根目录上:hdfs dfs -put word.txt /
现在我们把jar包上传到Linux上:
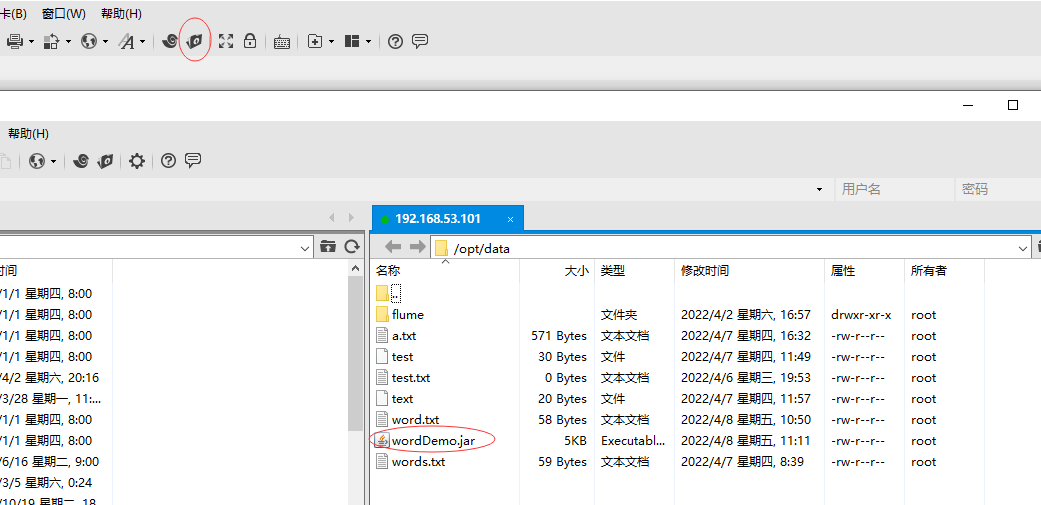
上传完毕以后是这样:
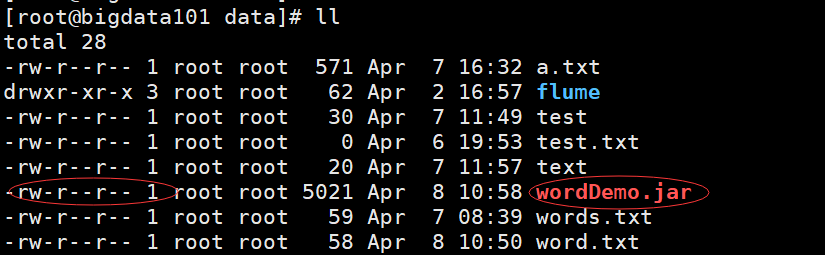
这个文件我们没有执行权限,给他授权:chmod 755 wordDemo.jar
然后就绿了:
绿了以后就可以使用Hadoop命令执行这个文件了,执行的时候我们要用到这个文件驱动的全类名,我们提前把路径复制下来:
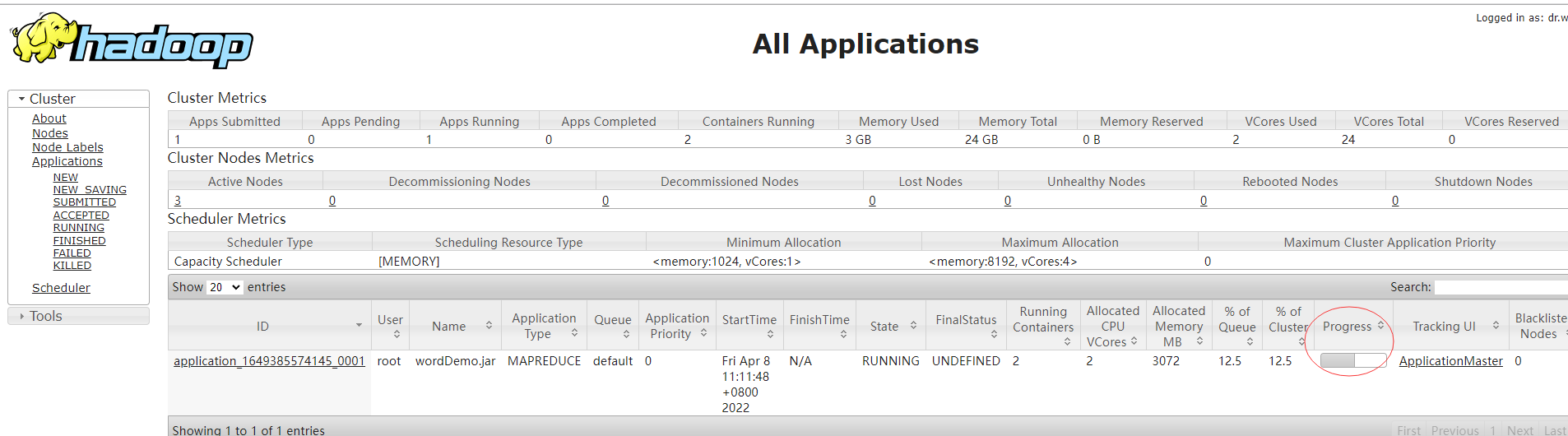
然后执行:hadoop jar wordDemo.jar MR.wc.wcDriver
我们打开浏览器,输入yarn的地址:http://192.168.53.102:8088/,可以看见作业运行的信息:
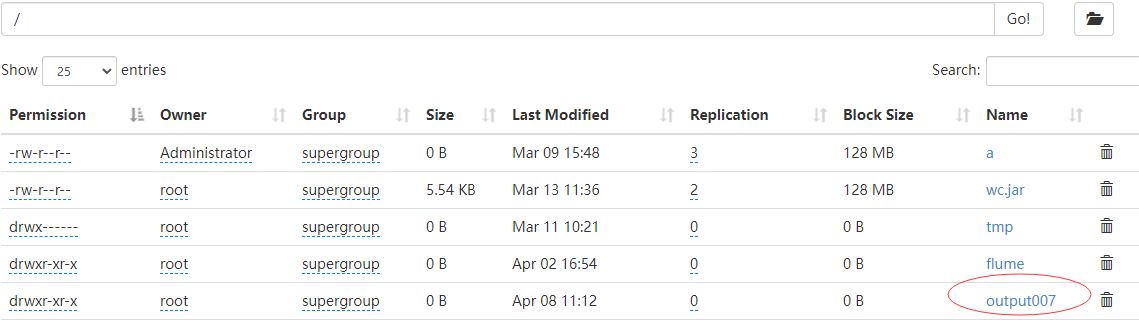
运行完以后,我们再打开一个网页窗口,输入hdfs地址:http://192.168.53.101:50070/,可以看见我们指定的那个文件已经生成了(我们每次运行的时候都会新生成一个文件):
我们给他打开:
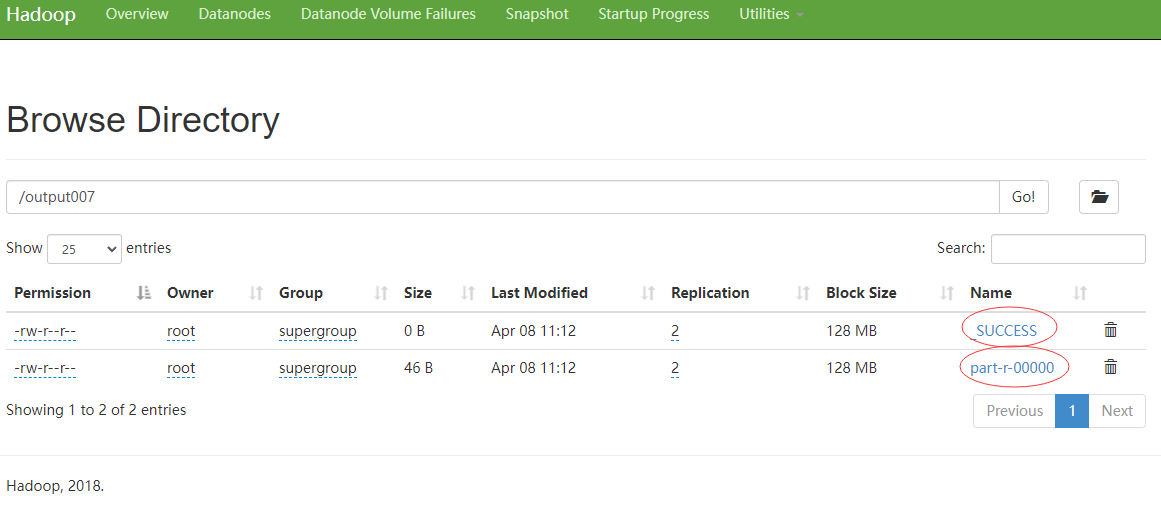
点击part开头的文件:
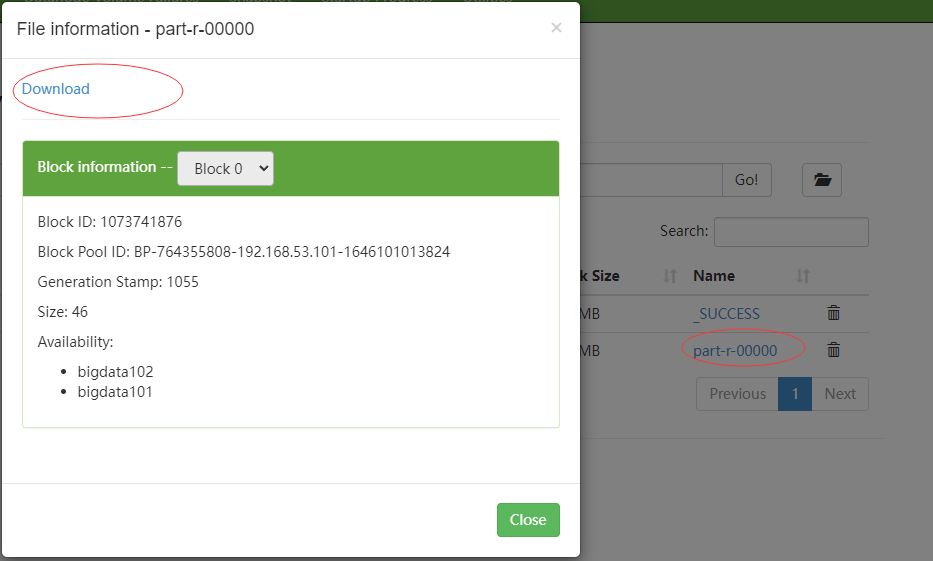
可以把这个文件下载下来,用notepad打开:
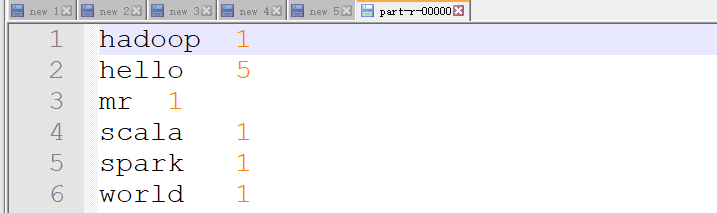
ok,搞定。其实这里就是两个步骤,一个map,一个reduce,当然了,细心的童鞋有可能发现了这个结果还被排序了,我们在代码里面没有看见,不着急,后面会慢慢展开来说。现在对mapreduce过程应该有一个大致的了解了。现在再回去看看那个mapreduce的流程图,会稍微清晰一些。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏