从n元文法到神经语言模型
资料来源
https://www.bilibili.com/video/BV11g4y1i7MW
80年代的n元语法
隐马尔科夫模型
SVM
MRF
CRF
等等
提纲
1.n元文法
2.神经语言模型
3.问题思考
历史

后面词的出现受前面词的影响,改进为条件概率,数据量太大

改进,当前词只和前面n个词相关,这样就出现了n阶马尔科夫链

要解决的问题:
1.数据稀疏问题-会出现新的词-很可能在训练数据中从未出现过,需要数据平滑
2.领域自适应
3.以离散符号为统计单元,忽略了词与词之间的相似性-比如英文的单词有不同的时态,但其实是一样的意思

枯燥和乏味是相近词-n元文法做不到
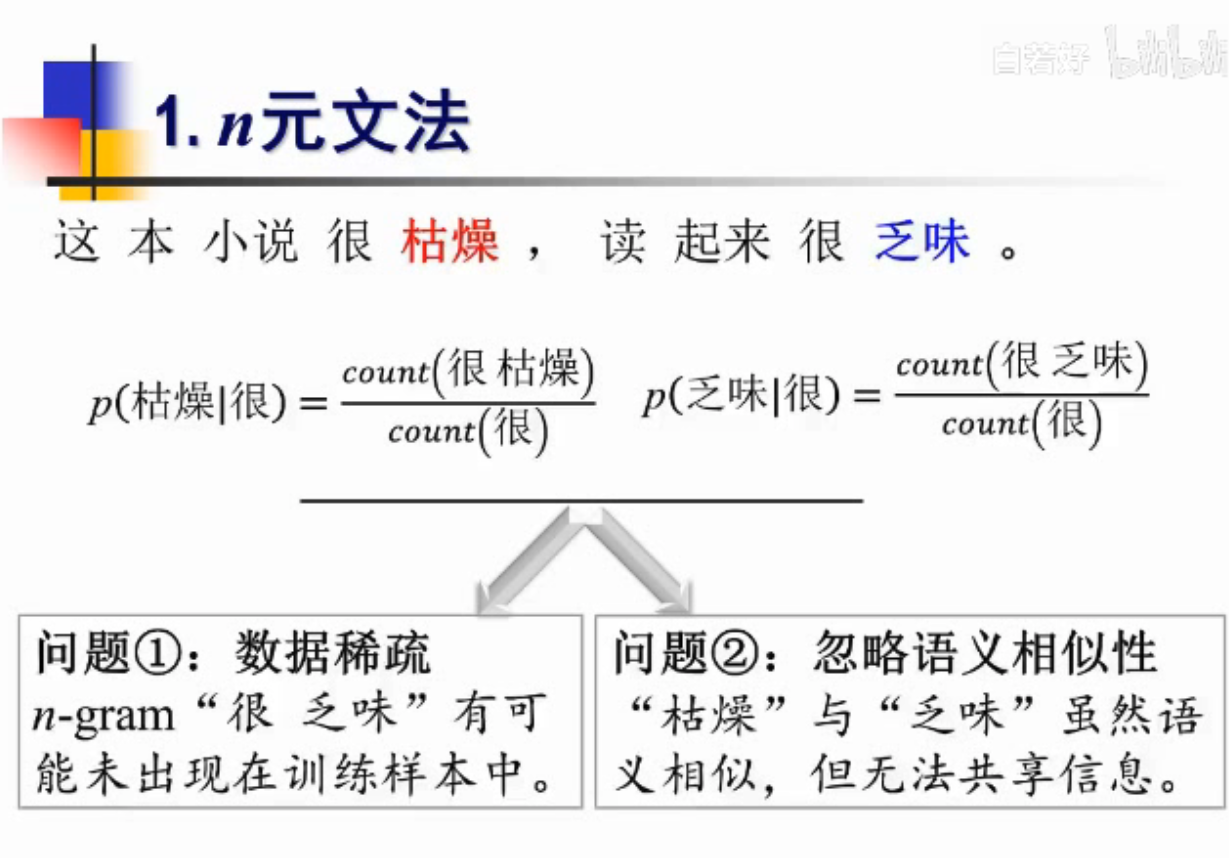
分析原因
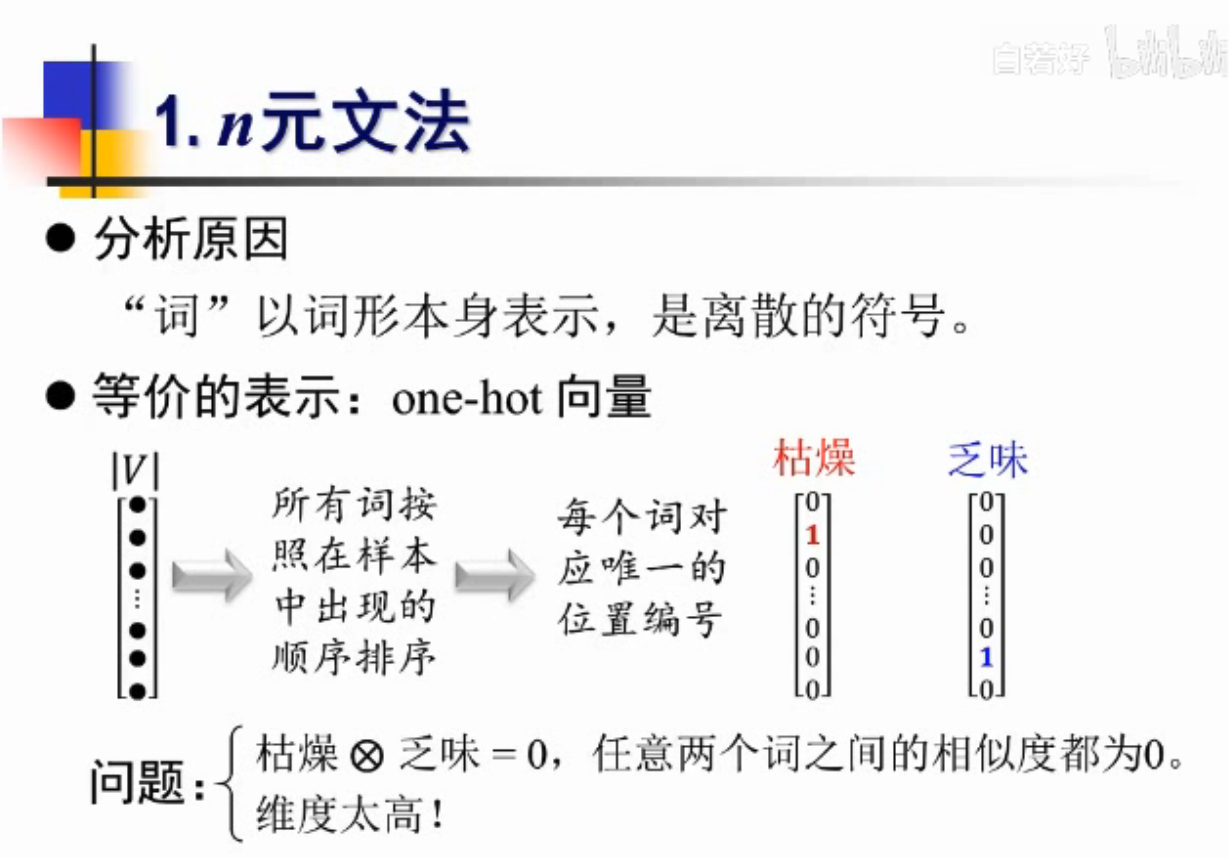
带来的问题:相似度没有体现
想办法解决,用连续空间去编码,同时也要降低维度,one-hot维度太大

还有一个好处,同时算概率的时候,可以共享一些历史数据
历史数据-“很”是一样的
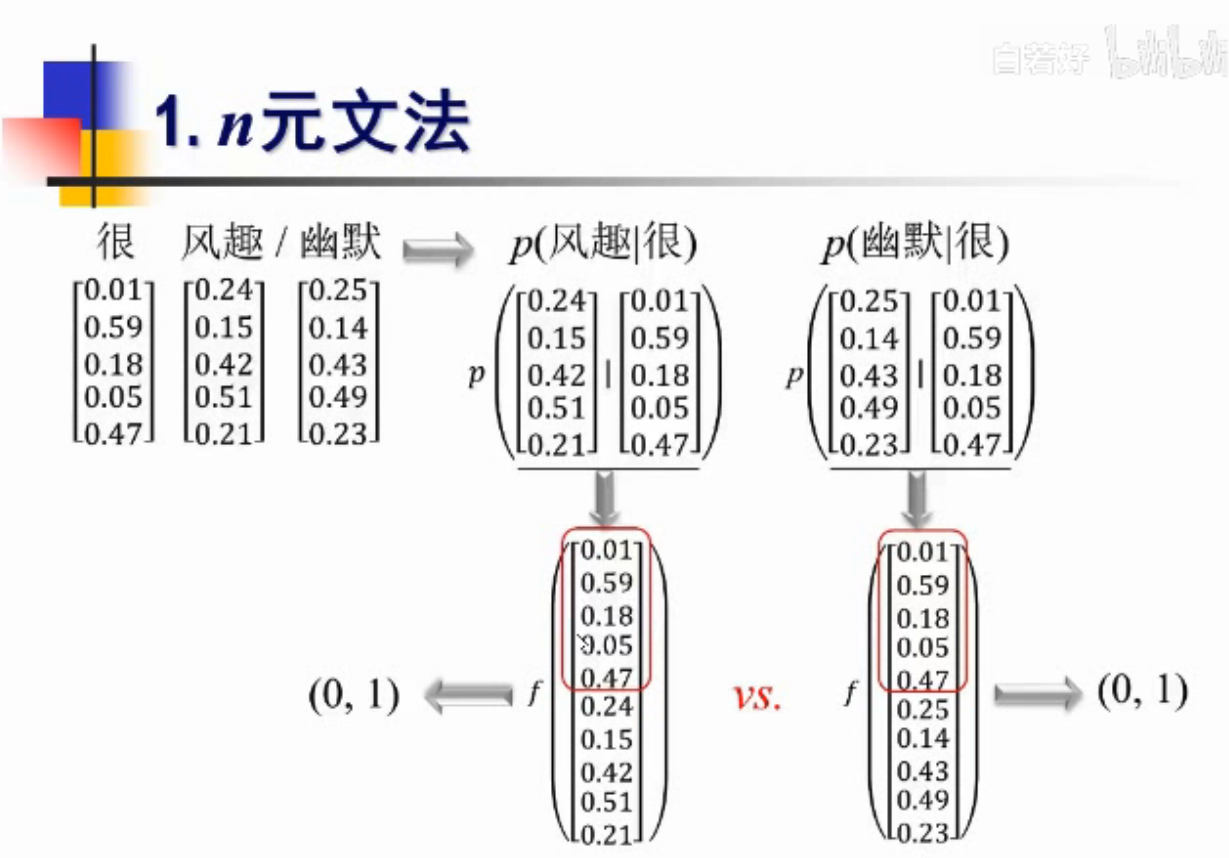
怎么赋值呢?
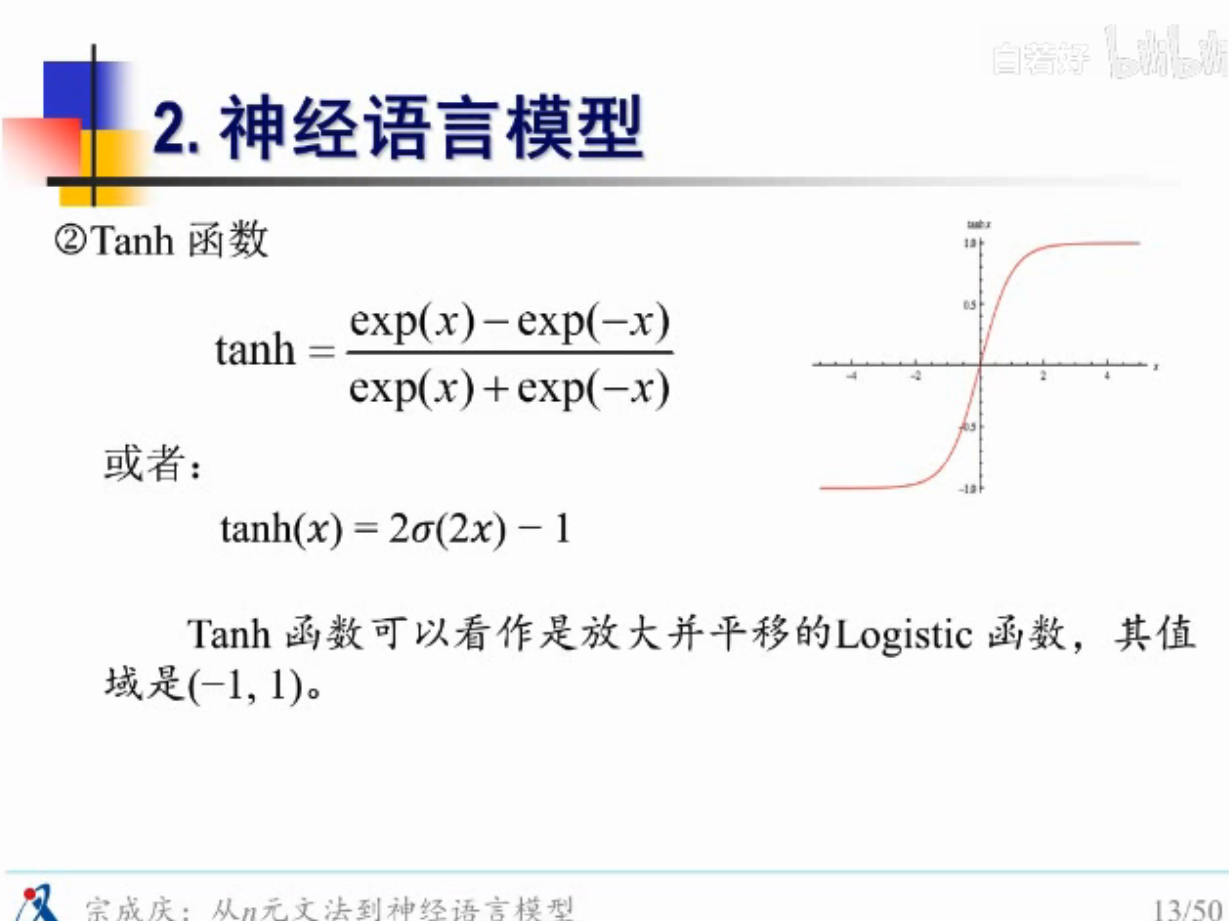
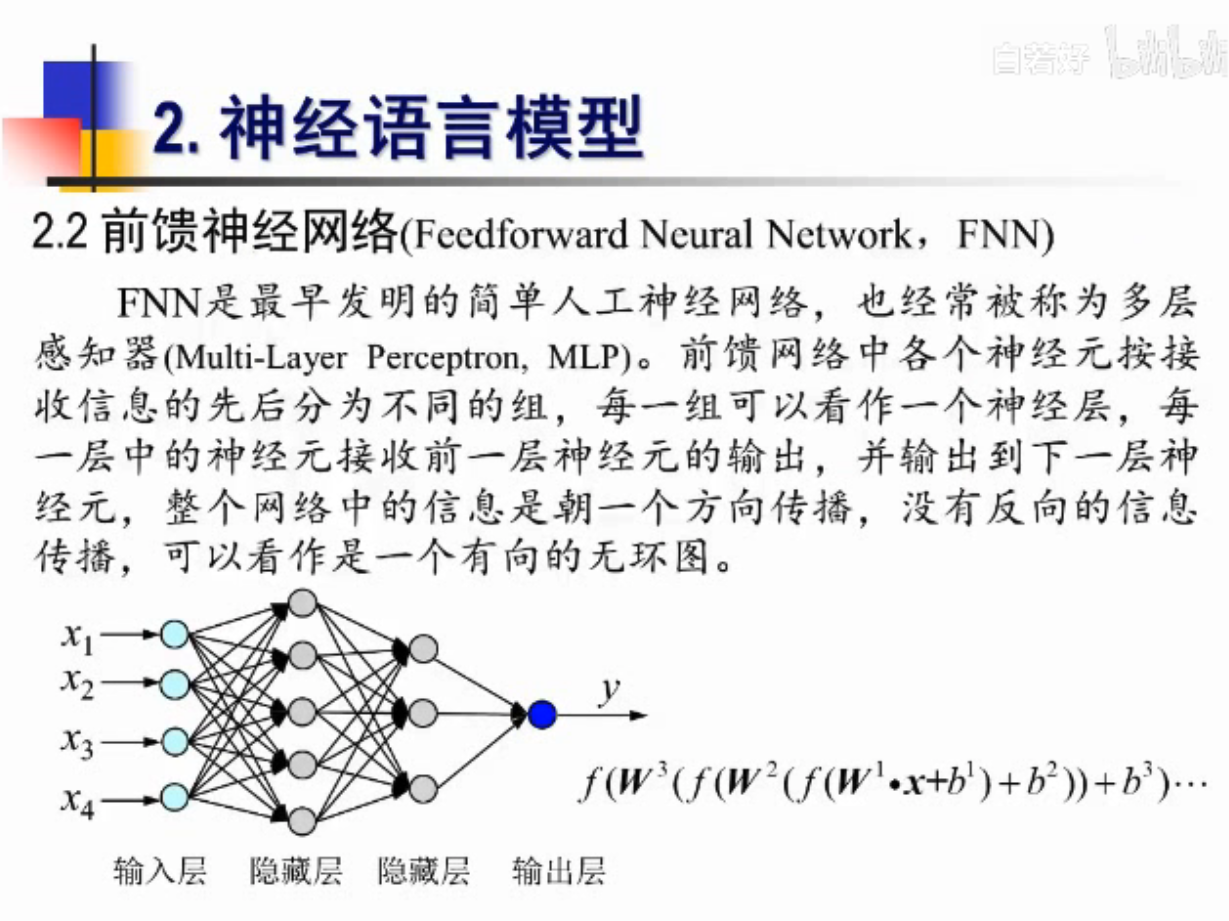
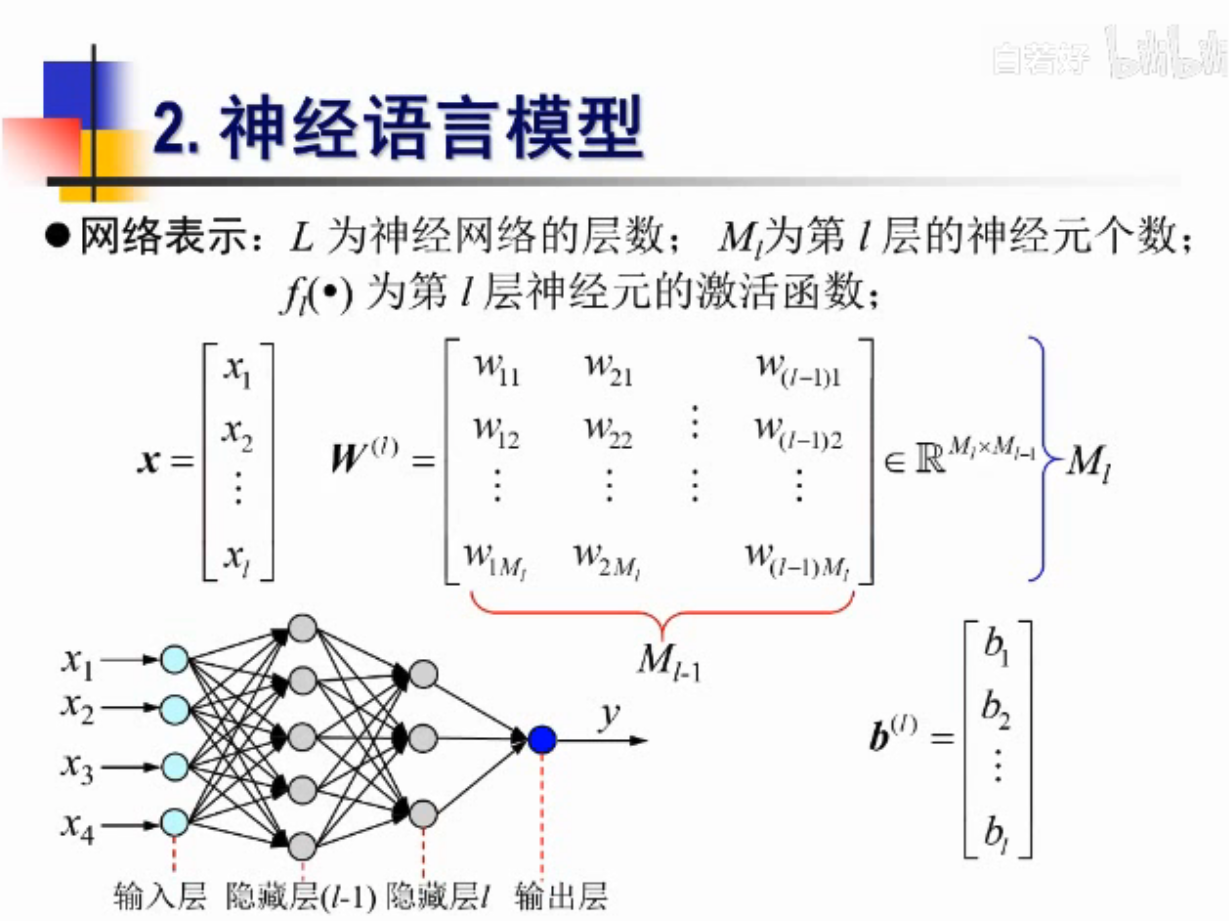
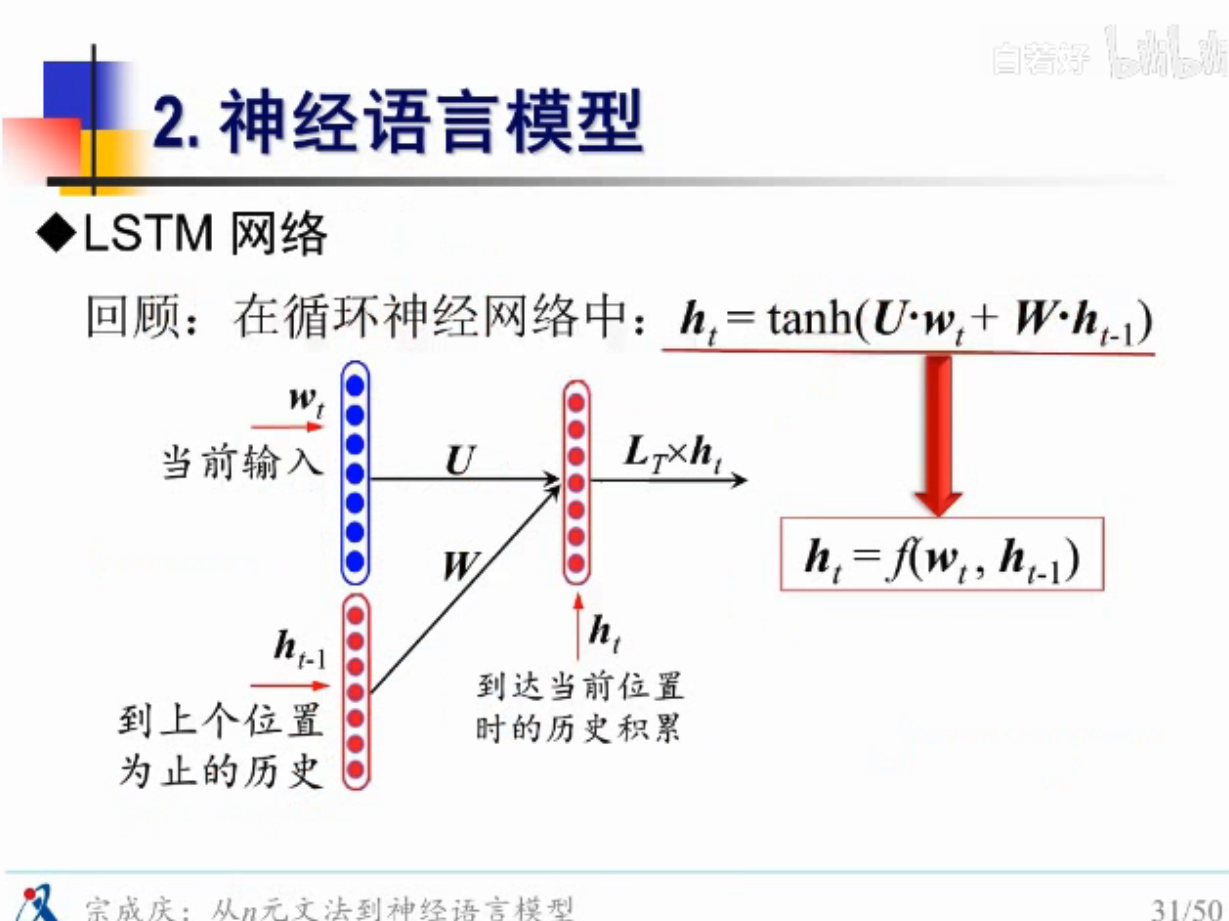
神经语言模型



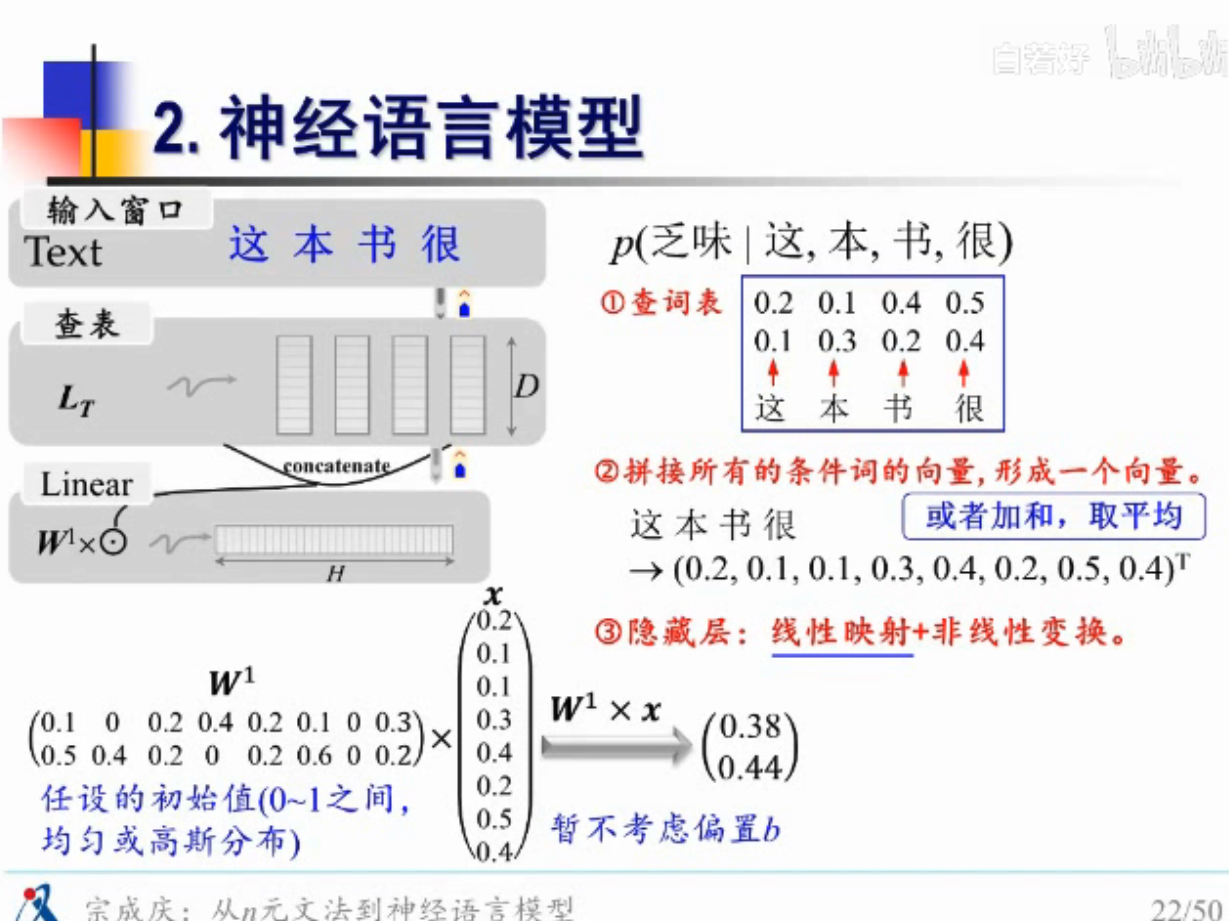
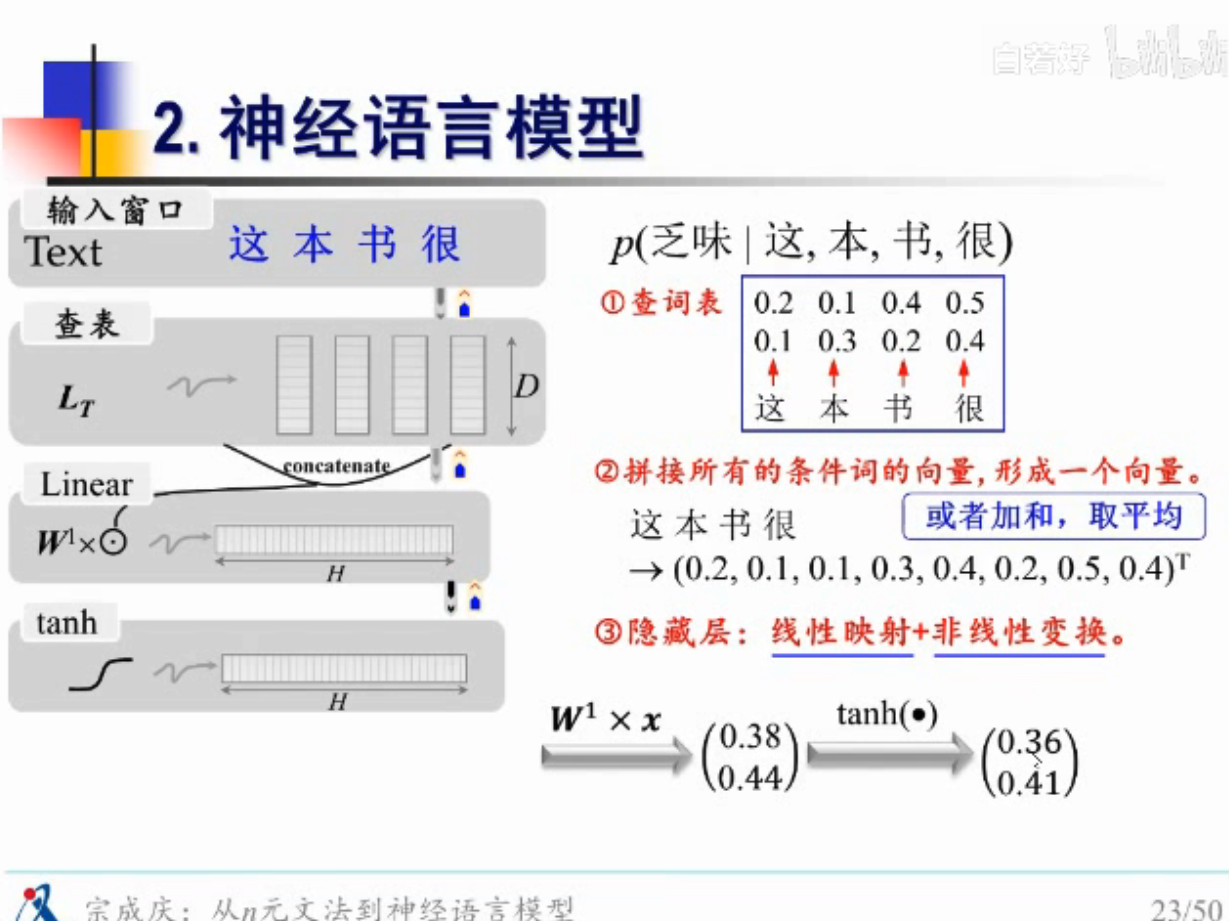
FNN怎么实现语言模型的计算?
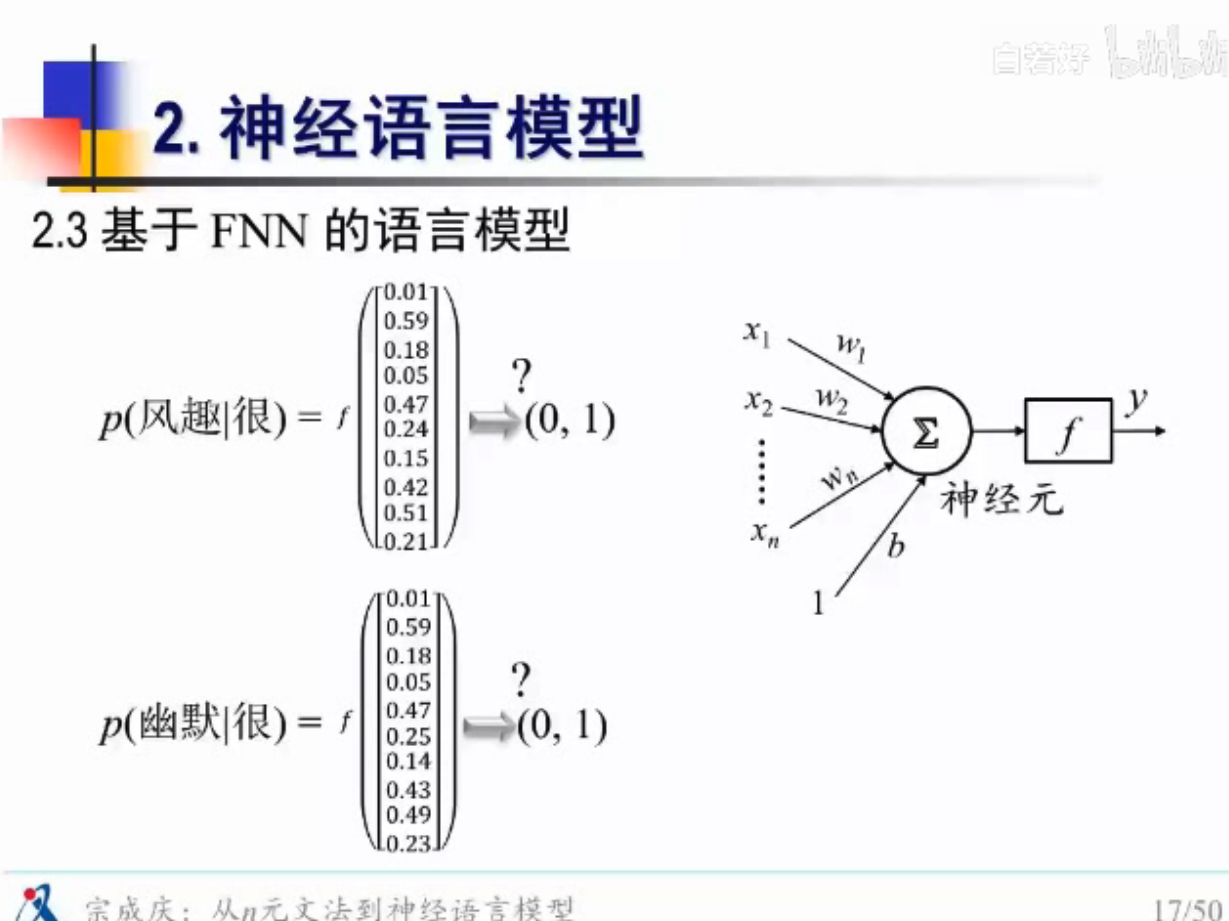
1.查词向量
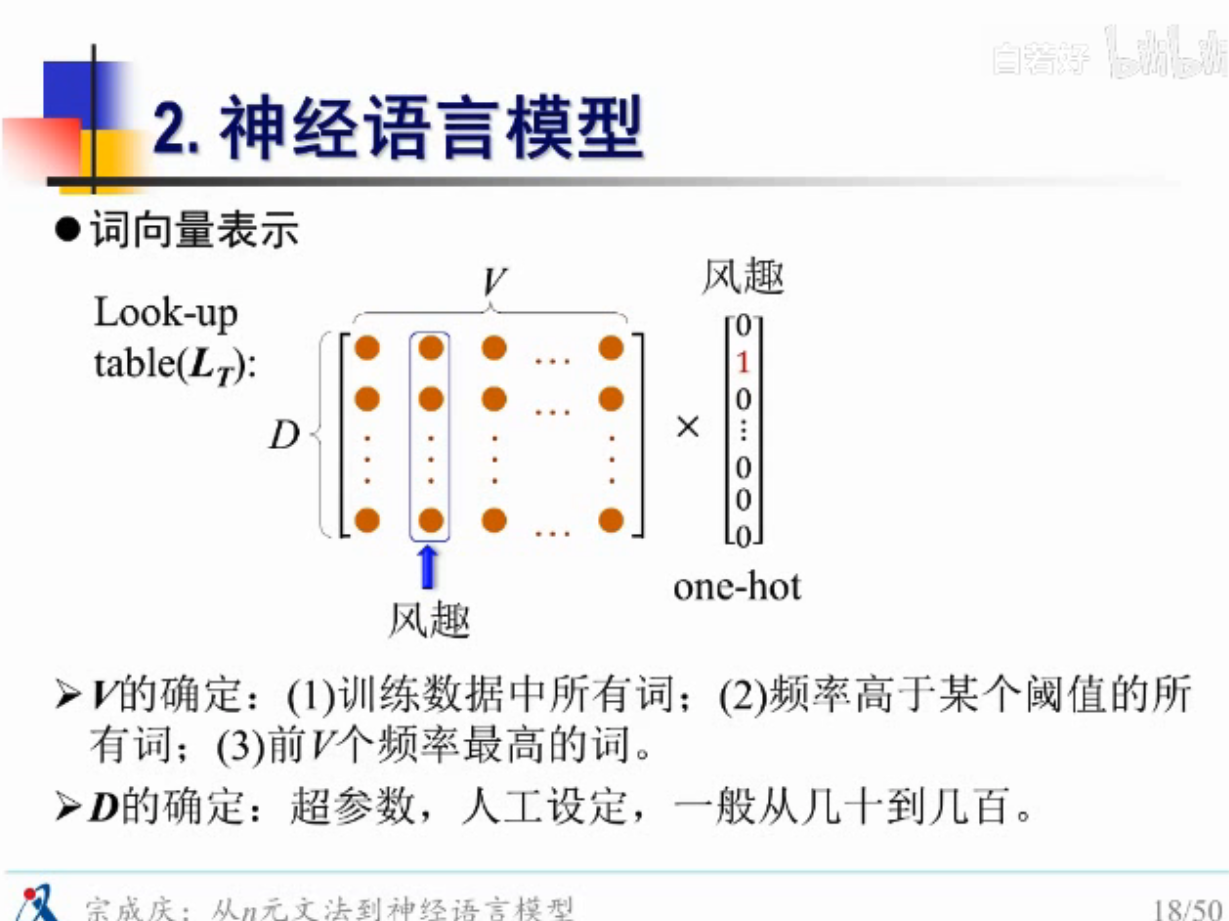
2.计算后验概率
\(L_T\)是查表
输入是一个句子,


举例说明

非线性变换
注意,这里输入的是 “这本书很乏味”,这个完整的句子了,不再是 “这本书很”
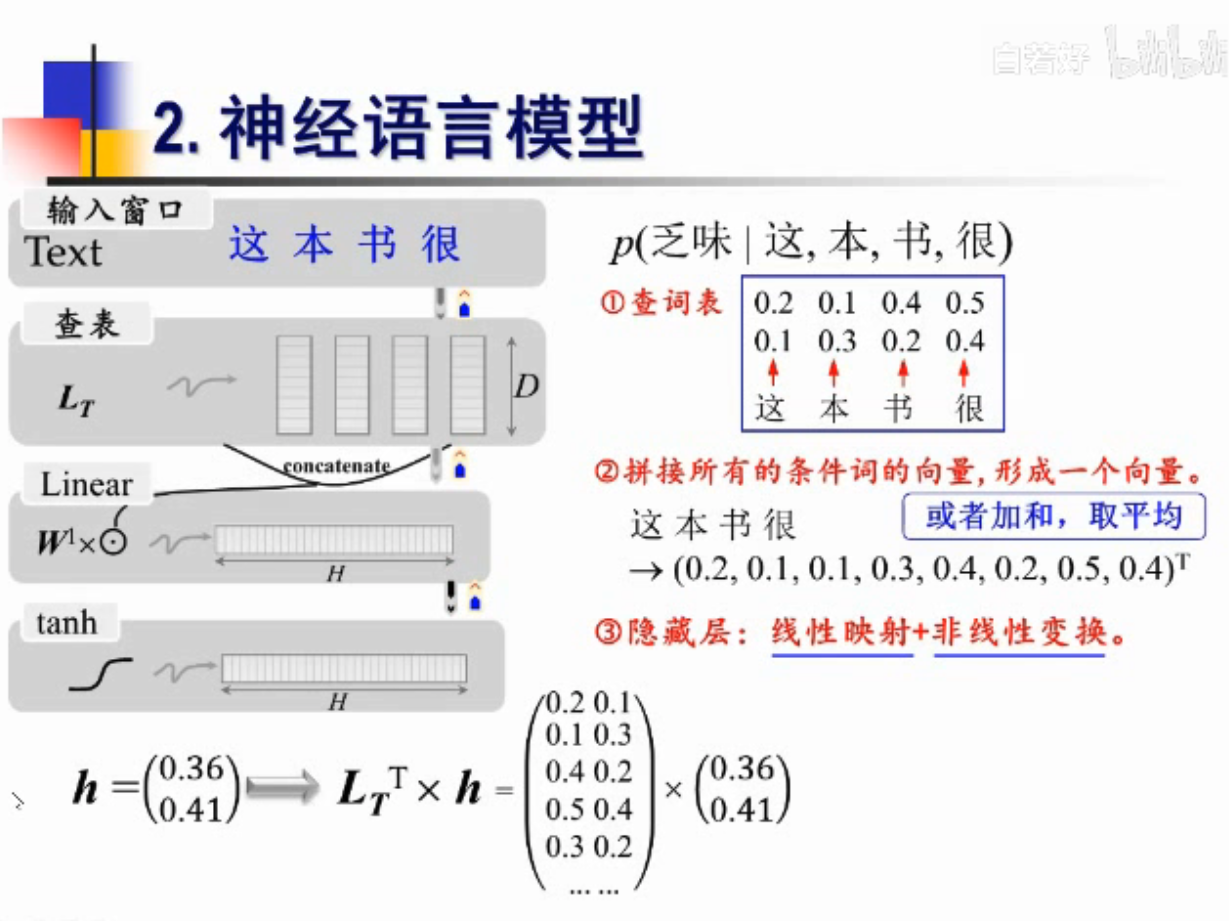
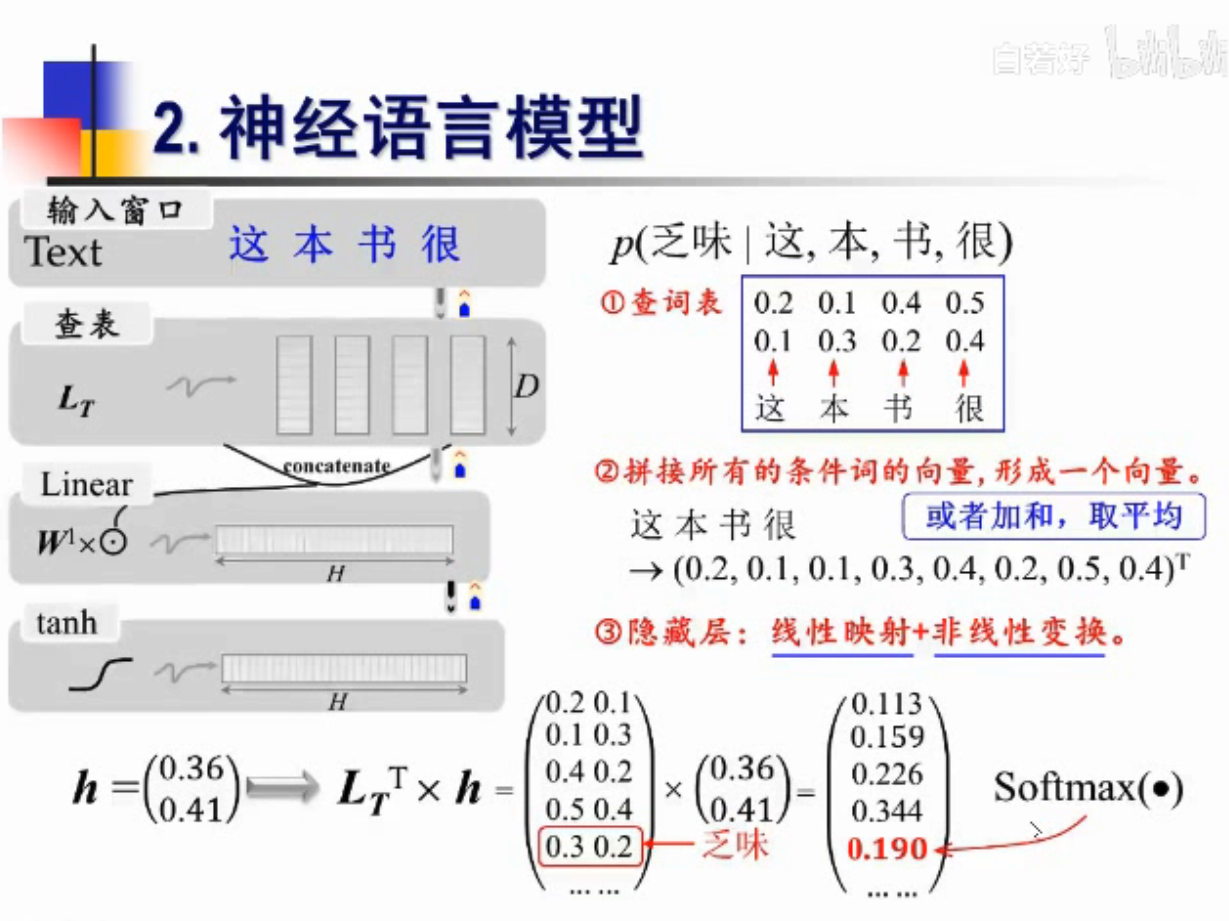
需要n-1个词的历史数据
仅对小窗口的历史信息进行建模
能不能把所有的历史数据考虑进去

RNN登场
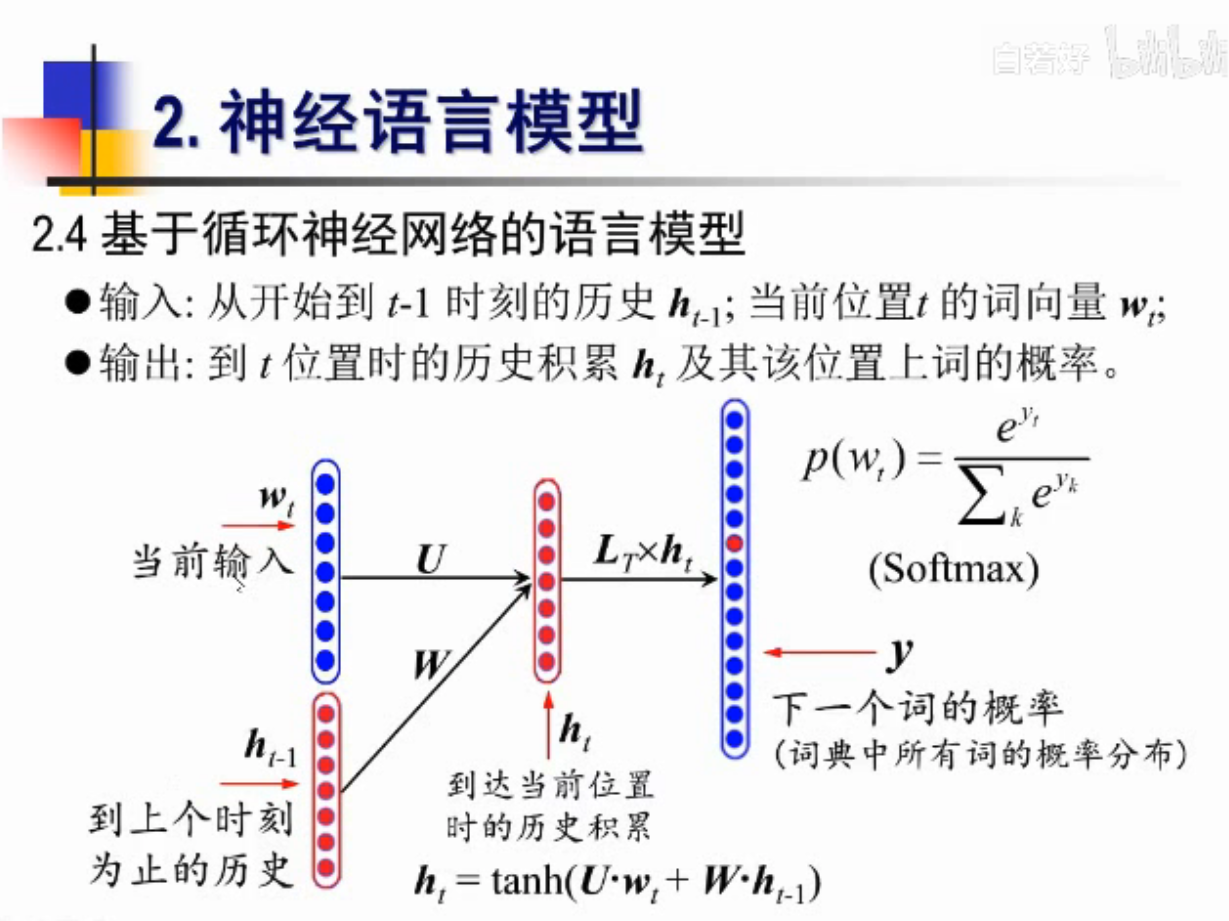
完整的图
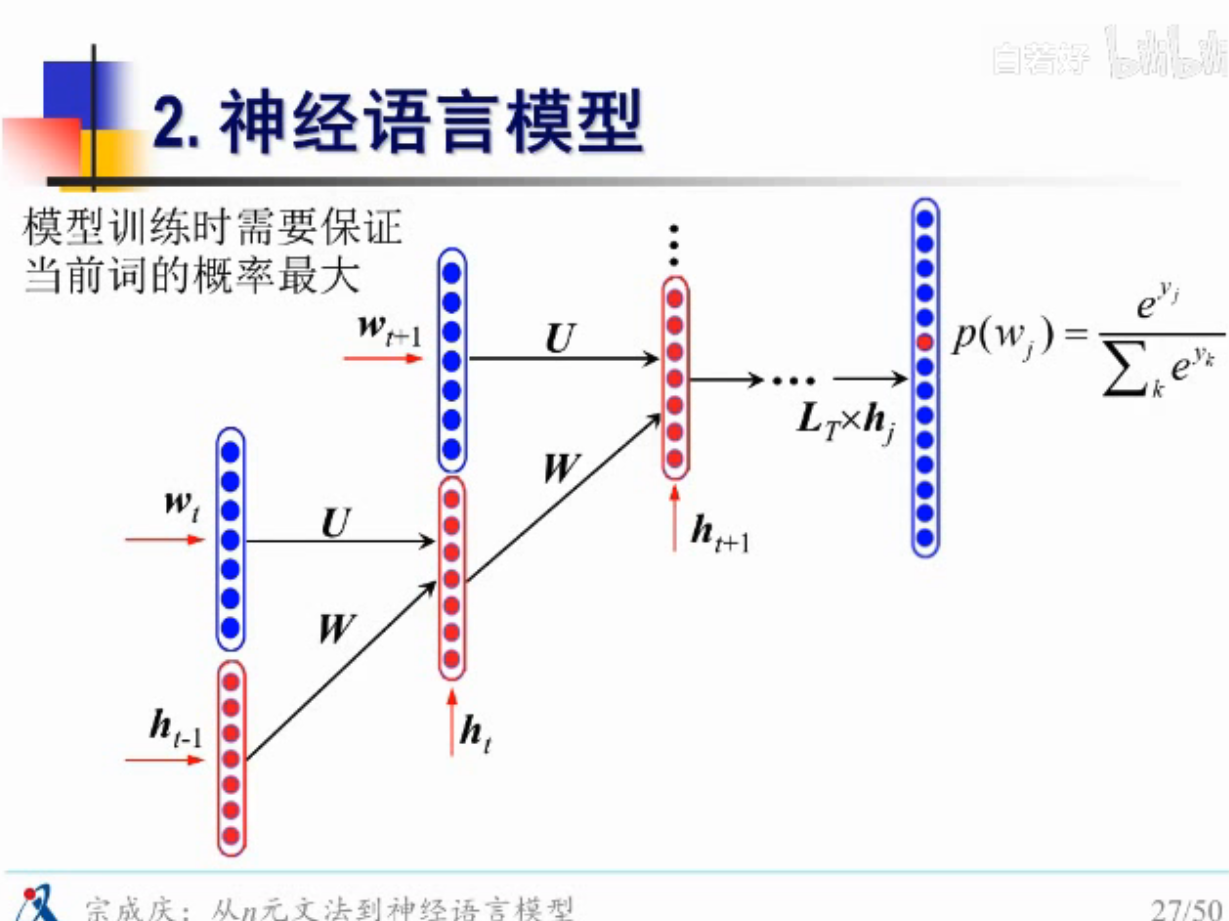
案例的RNN模型
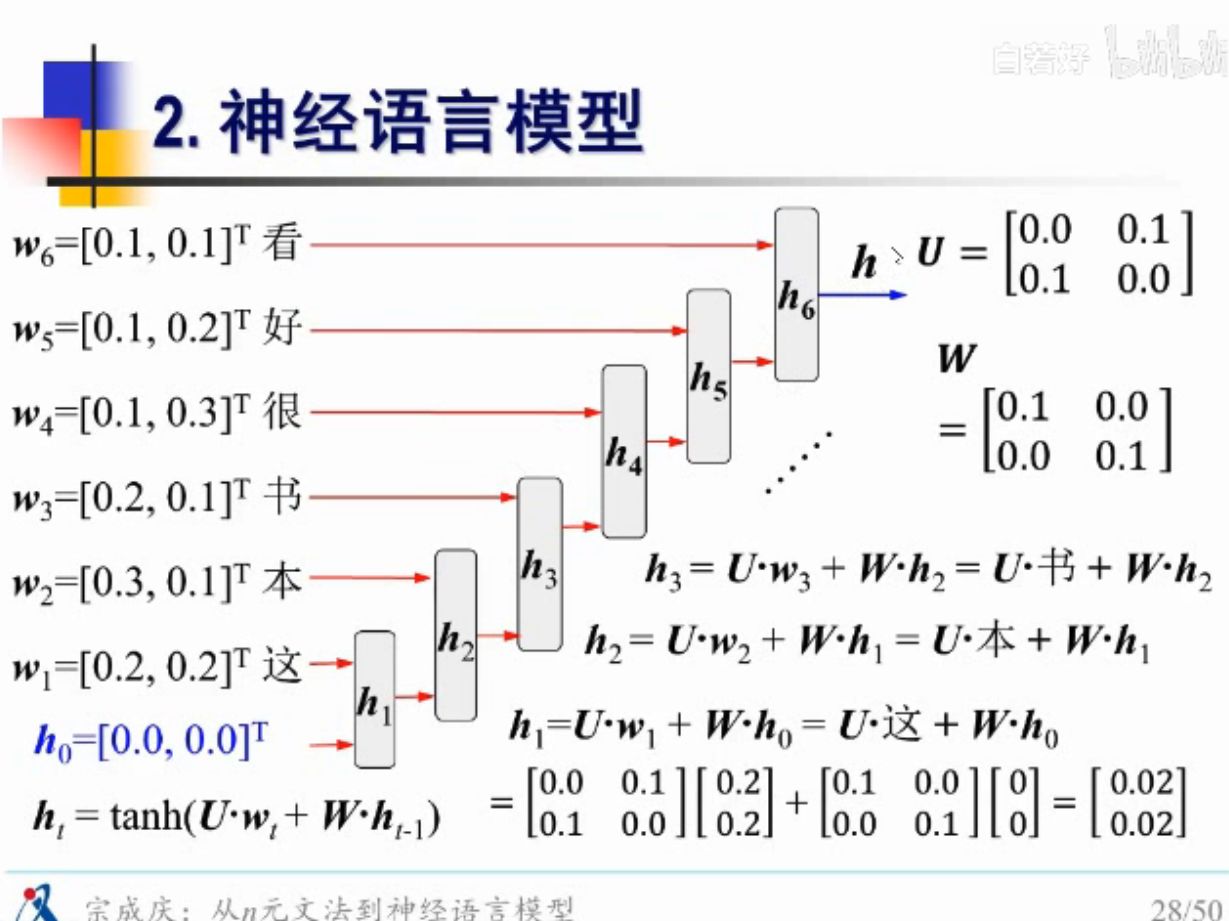
梯度爆炸,弥散问题

能不能选择性的遗忘一些东西?
LSTM登场
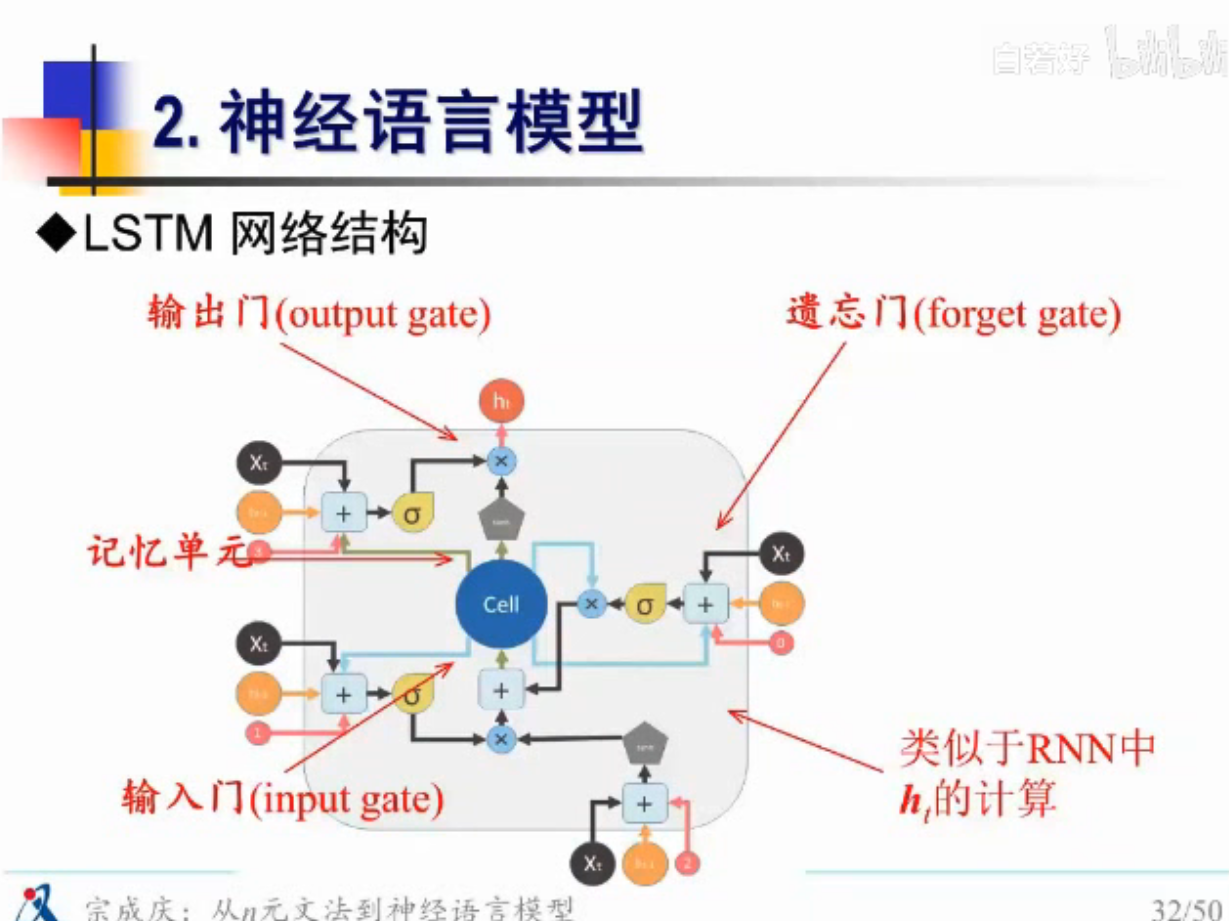

不管是RNN 还是LSTM 都只考虑了历史,没有考虑历史哪个词对当前影响性大
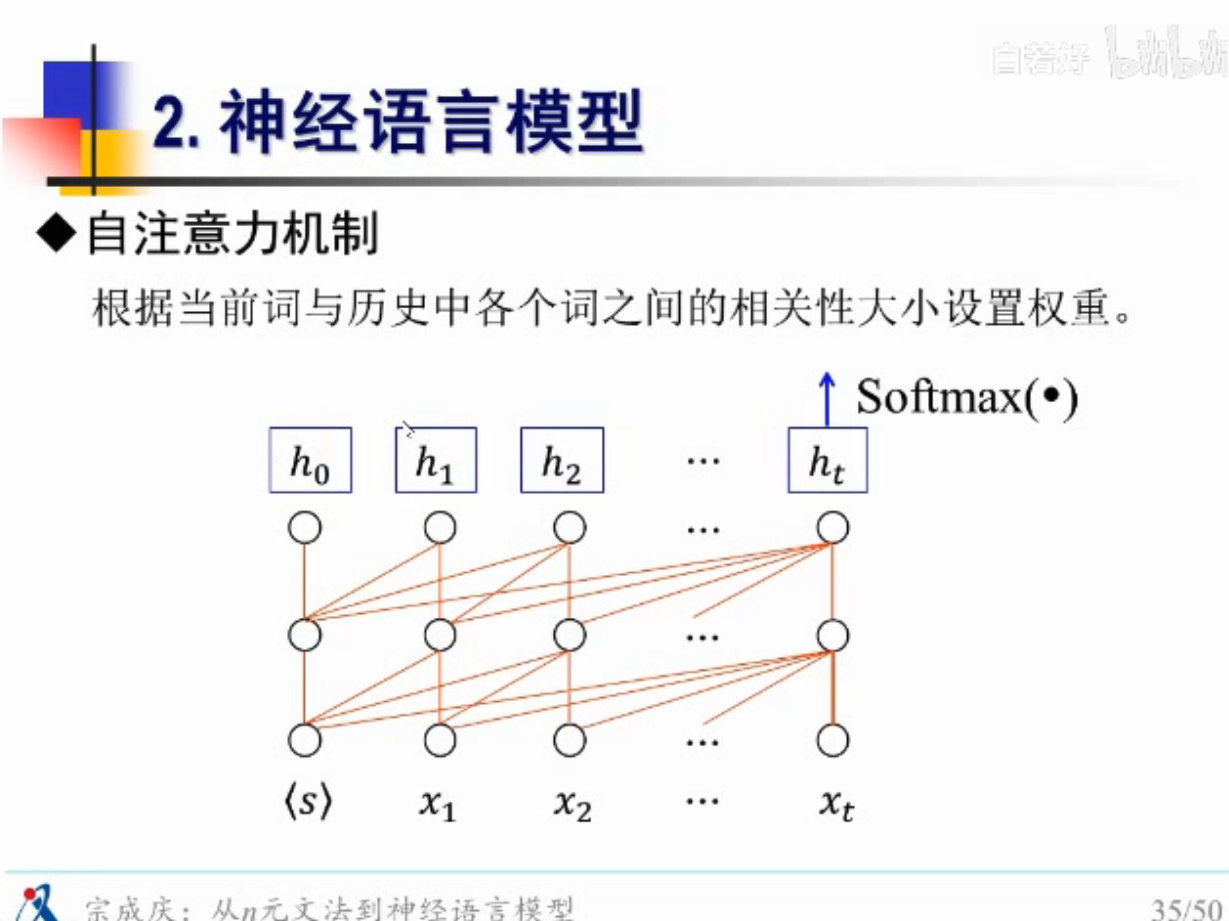
不同的影响性要赋予不同的权重
自注意力机制
考虑了语境信息
Transformer
Bert模型
问题思考


问题1:样本的局限性
案例-脱贫困难,资源就那么点

问题2:和自然语言的局限性

问题3:东施效颦,没有学到精髓

近年来老师团队的成果
比如出租车,车很重要,车怎么可以赋予更高的权重?得到质量跟高的向量
论文1 - EMNLP 2017

光在文本上学也是有问题的,有时候的图文结合的,所以要利用图片信息
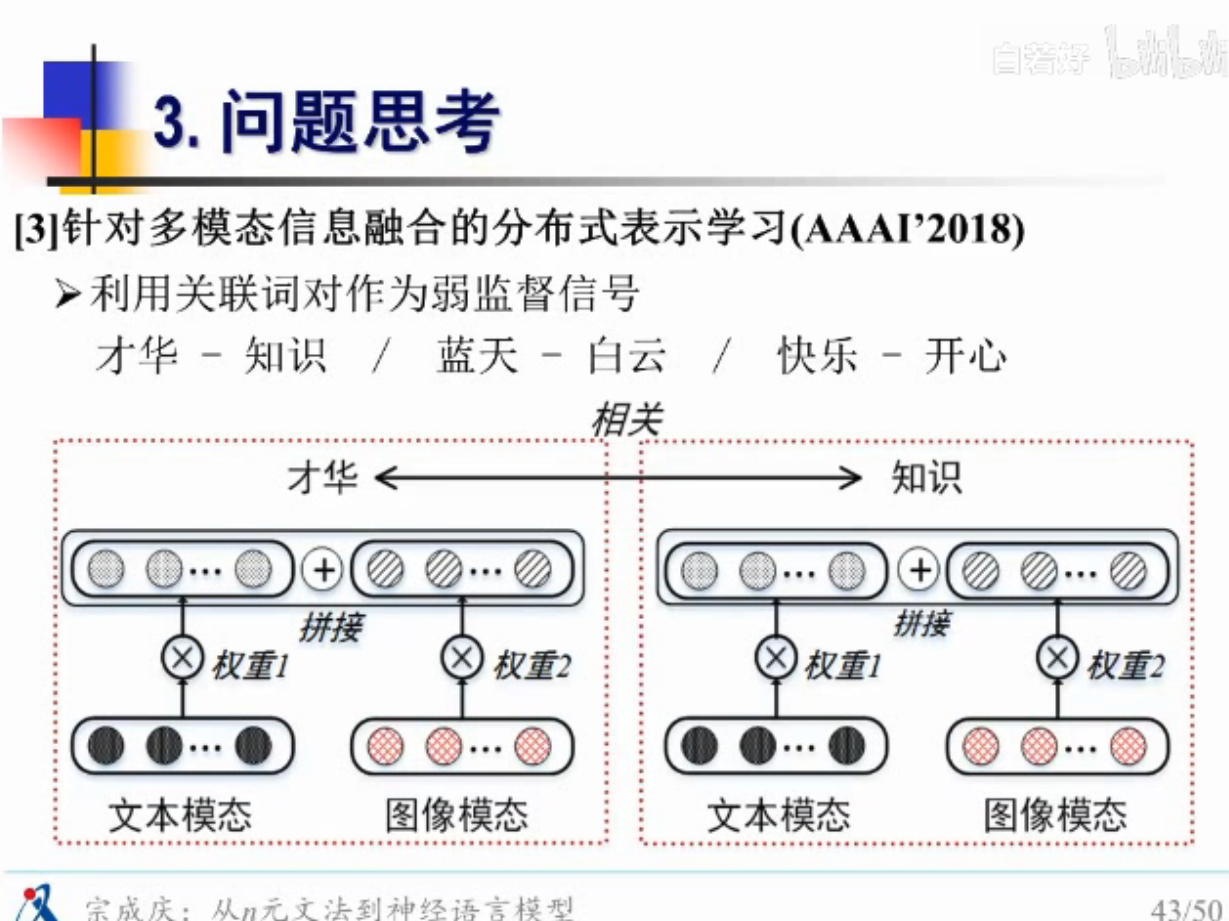
词也不一样,有些是抽象词,有些是具体词,具象词,这种不同模态的词,赋予不同的权重
论文2 -
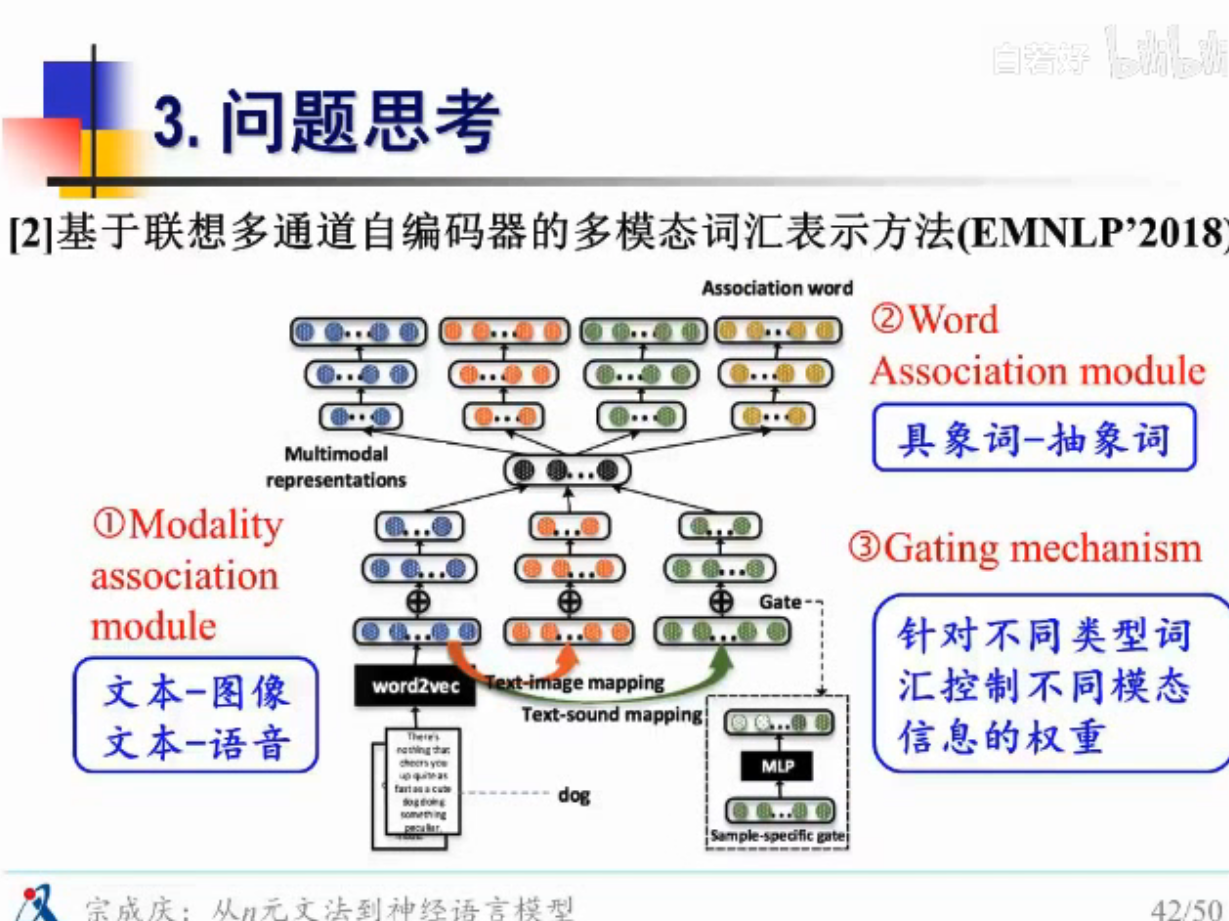
不同此类的词相互的影响
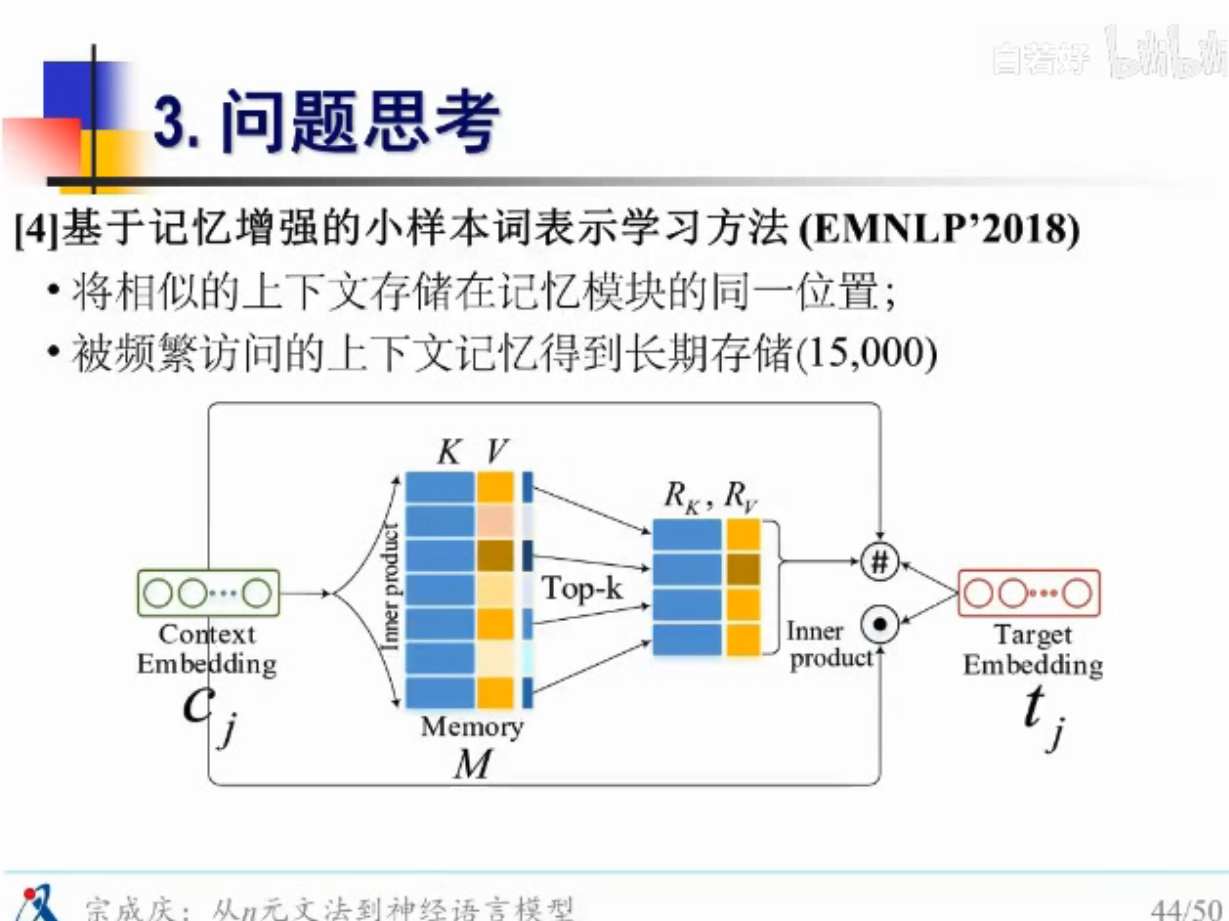
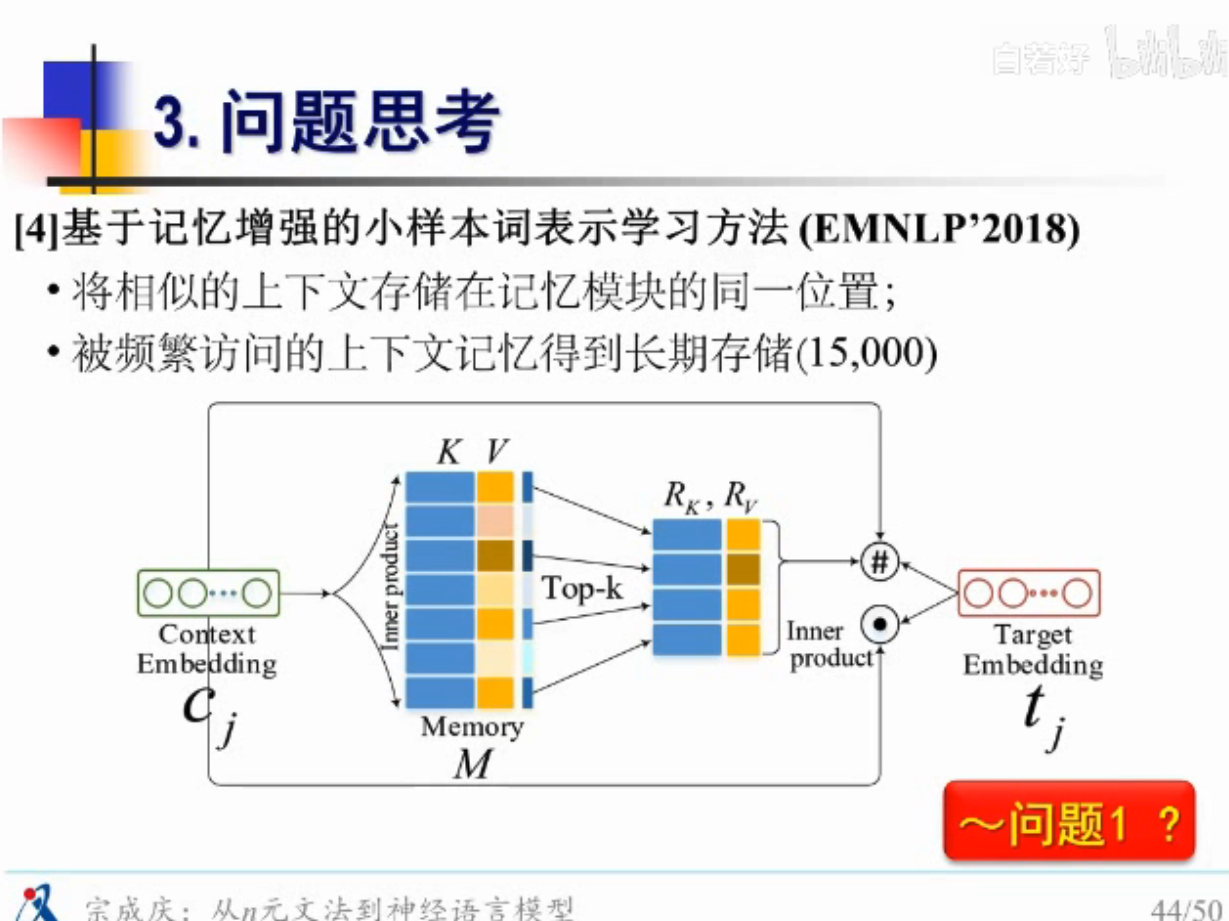
把上下文语境信息存起来,对一些频繁访问的上下文信息,记录在缓存中
看起来挺新的,但其实很早就这么做了,基于缓存的n元文法,有点像外部记忆
上面的东西
基本是在解决问题1
包括把声音的信息都拿进来
惊异度机制

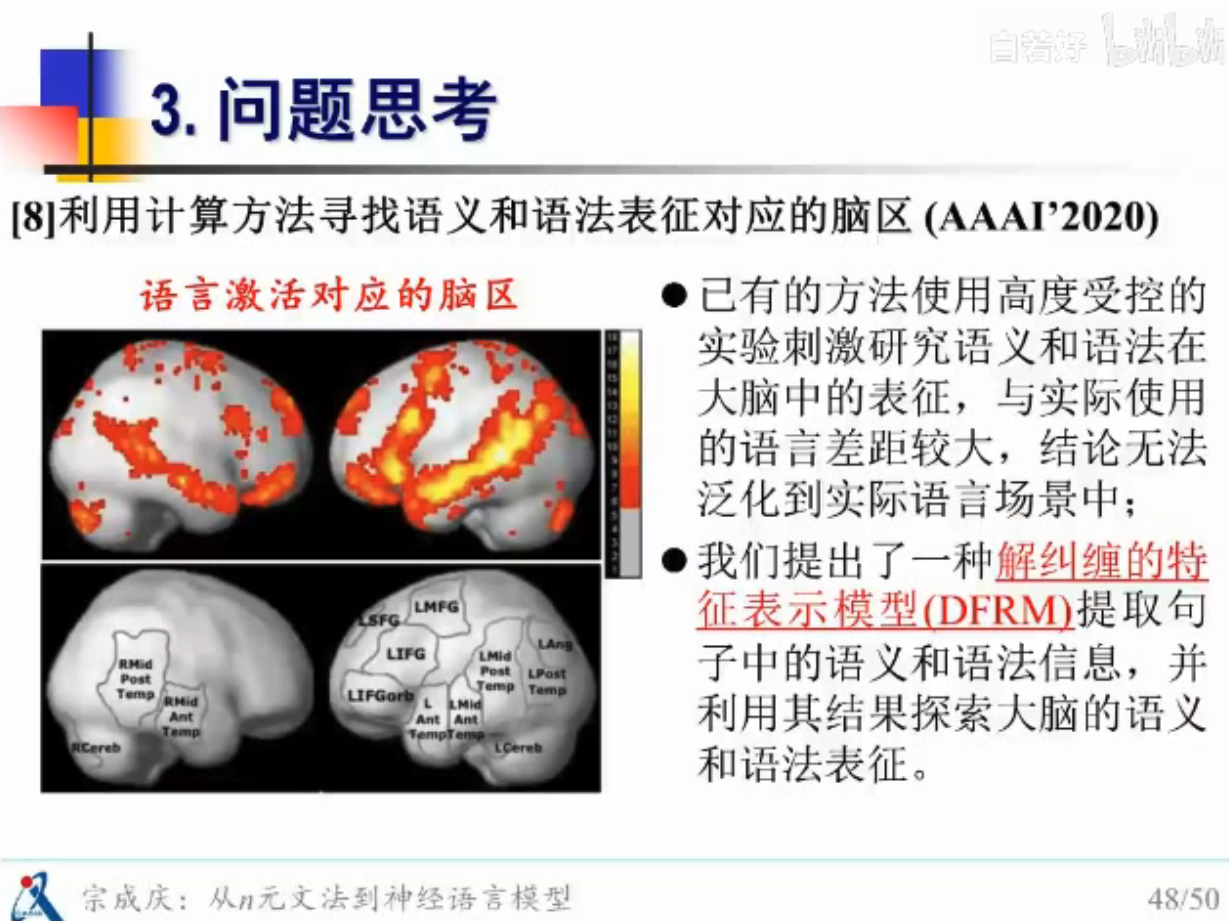
借助外部仪器的图像-探索大脑的解析形式
fMRI 核磁共振图像
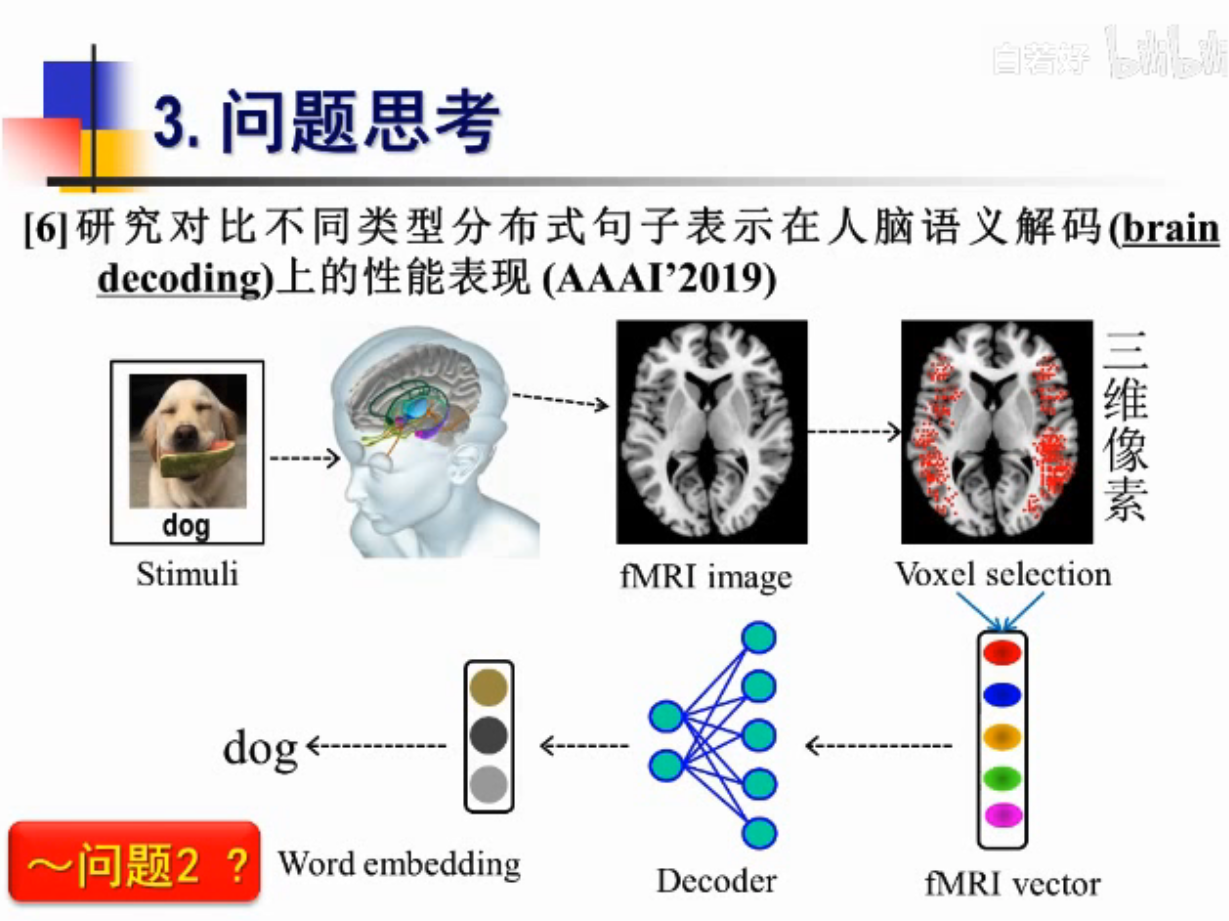
怎么从大脑图像中重构语义信息?
三种方式
1.给一张图片观察fMRI核磁图像
2.给一句句子观察
3.给一张词图观察图像

有的时候会造一些相同的句子去理解一些说的话
所有论文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号