概率图模型:原理与技术-3.2 贝叶斯网络
贝叶斯网络的定义
\(\color{red}{贝叶斯网络是一个有向无圈图(DAG)\mathcal{G}}\)

因子分解-基础

\(\color{red}{简单说,贝叶斯网络的因子分解=每个节点的条件概率(已知所有父节点的情况下)之积}\)
概率图
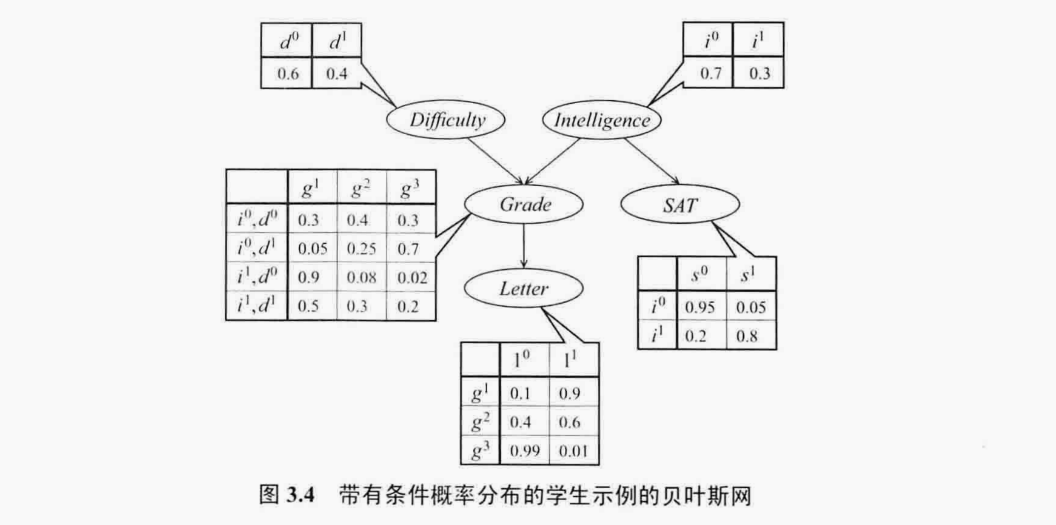
推理模式
拿到一封好的推荐信的概率为
\(P(L=1)=\sum_{G}P(L=1|G)P(G)\)
\(=\sum_{G}P(L=1|G)P(G|D,I)P(I)P(D)\)
\(=0.9\times 0.3\times 0.7 \times 0.6\)
\(+0.9\times 0.05\times 0.7 \times 0.4\)
\(+0.9\times 0.9\times 0.3 \times 0.6\)
\(+0.9\times 0.5\times 0.3 \times 0.4\)
\(+0.6\times 0.4\times 0.7 \times 0.6\)
\(+0.6\times 0.25\times 0.7 \times 0.4\)
\(+0.6\times 0.08\times 0.3 \times 0.6\)
\(+0.6\times 0.3\times 0.3 \times 0.4\)
\(+0.01\times 0.3\times 0.7 \times 0.6\)
\(+0.01\times 0.7\times 0.7 \times 0.4\)
\(+0.01\times 0.02\times 0.3 \times 0.6\)
\(+0.01\times 0.2\times 0.3 \times 0.4\)
\(=0.502336\)


课程困难程度上升的计算
\(P(D|G)=\frac{P(D,G)}{P(G)}\)
\(P(D=1|G=3)=\frac{P(D=1,G=3)}{P(G=3)}\)
\(P(D=1,G=3)=P(D=1,G=3,I=1)+P(D=1,G=3,I=0)\)
\(P(D=1,G=3)=P(G=3|D=1,I=1)P(D=1)P(I=1)+P(G=3,D=1,I=0)P(D=1)P(I=0)\)
\(=0.2*0.4*0.3+0.7*0.4*0.7\)
\(P(G=3)=P(G=3,D=0,I=0)+P(G=3,D=1,I=0)+P(G=3,D=0,I=1)+P(G=3,D=1,I=1)\)
\(=0.3*0.6*0.7+0.7*0.4*0.7+0.02*0.6*0.3+0.2*0.4*0.3\)
\(P(D=1|G=3)=(0.2*0.4*0.3+0.7*0.4*0.7)/(0.3*0.6*0.7+0.7*0.4*0.7+0.02*0.6*0.3+0.2*0.4*0.3)=0.6292906178489702\)



上面这个案例很有意思,值得多读几遍,和我们人脑的思考过程几乎无二


贝叶斯网络的基本独立性




简单说就是父亲节点如果被观测了,那么所有子节点之间就被截断了,就变成条件独立了,当然这里仅仅指子节点,不是孙子,或者后辈节点

儿子节点和其他兄弟节点(包括后代)都是独立的
可以通过遗传学的角度来解释

因子分解-高阶

贝叶斯网络所需的参数个数

关于隐变量

敏感性分析

I-map
\(一个概率分布 P 包含有一堆条件独立关系,把这个条件独立关系的集合称为 I(P);一张 Graph G 也包含了一堆条件独立关系,把这堆条件独立关系的集合称为 I(G)。如果 I(G) 包含于 I(P),那么就把这张 Graph G 叫做这个概率分布的 I-map (Independence-map)。\)
这个I指的是 independency map,对应还有D-map,dependency map
\(显而易见,只要是 I(P) 的 子集,其对应的 Graph 就是概率分布 P 的 I-map,所以 I-map 可以有很多。只有 I(G) = I(P) 时,对应的 Graph 才可以等价地表示这个概率分布,也叫做 P 的 P-map (Perfect-map)。\)
详细的定义,还是上面几句通俗易懂


 浙公网安备 33010602011771号
浙公网安备 33010602011771号