
PRML-1.5.4 推断和决策


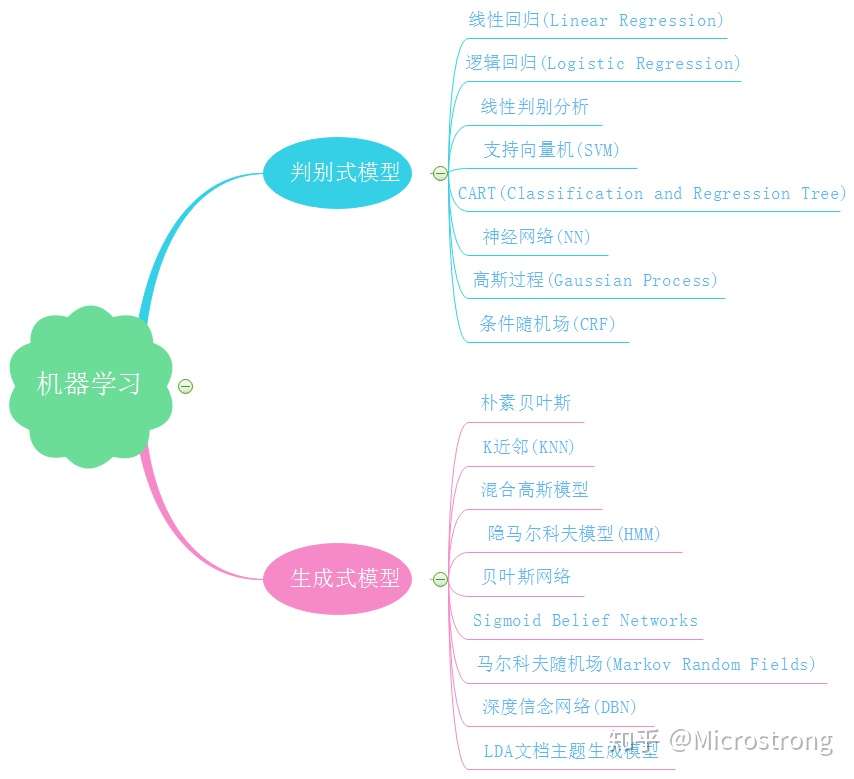
判别式 和 生成式
简单点说,生成式算出的是概率,哪个概率大,属于哪个分类
判别式就是输出具体的类别,没有概率
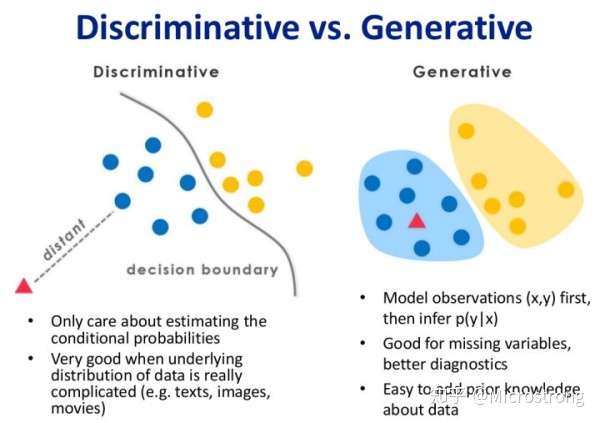
上图左边为判别式模型而右边为生成式模型,可以很清晰地看到差别,判别式模型是在寻找一个决策边界,通过该边界来将样本划分到对应类别。而生成式模型则不同,它学习了每个类别的边界,它包含了更多信息,可以用来生成样本。
判别式模型特点:
判别式模型直接学习决策函数或者条件概率,不能反映训练数据本身的特性,但它寻找不同类别之间的最优分裂面,反映的是异类数据之间的差异,直接面对预测往往学习准确度更高。具体来说有以下特点:
*对条件概率建模,学习不同类别之间的最优边界。
*捕捉不同类别特征的差异信息,不学习本身分布信息,无法反应数据本身特性。
*学习成本较低,需要的计算资源较少。
*需要的样本数可以较少,少样本也能很好学习。
*预测时拥有较好性能。
*无法转换成生成式。
生成式模型的特点:
生成式模型学习的是联合概率密度分布或者 ,可以从统计的角度表示分布的情况,能够反映同类数据本身的相似度,它不关心到底划分不同类的边界在哪里。生成式模型的学习收敛速度更快,当样本容量增加时,学习到的模型可以更快的收敛到真实模型,当存在隐变量时,依旧可以用生成式模型,此时判别式方法就不行了。具体来说,有以下特点:
*对联合概率建模,学习所有分类数据的分布。
*学习到的数据本身信息更多,能反应数据本身特性。
*学习成本较高,需要更多的计算资源。
*需要的样本数更多,样本较少时学习效果较差。
*推断时性能较差。
*一定条件下能转换成判别式。
总之,判别式模型和生成式模型都是使后验概率最大化,判别式是直接对后验概率建模,而生成式模型通过贝叶斯定理这一“桥梁”使问题转化为求联合概率。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· .NET10 - 预览版1新功能体验(一)