
df.shift
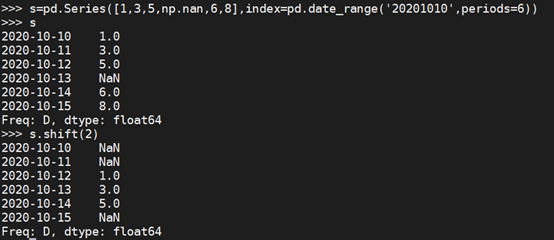
s=pd.Series([1,3,5,np.nan,6,8],index=pd.date_range('20201010',periods=6)) s.shift(2) #将前2行变为NaN
df.stack
#将列索引变成行索引 tuples = list(zip(*[['bar','bar','baz','baz','foo','foo'],['one','two','one','two','one','two']])) index = pd.MultiIndex.from_tuples(tuples,names=['first','second']) df = pd.DataFrame(np.random.randn(6,2),index = index,columns=['A','B']) stack = df.stack() #将列索引变成行索引 stack.reset_index() #重新索引 stack.unstack() #还原

 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号