
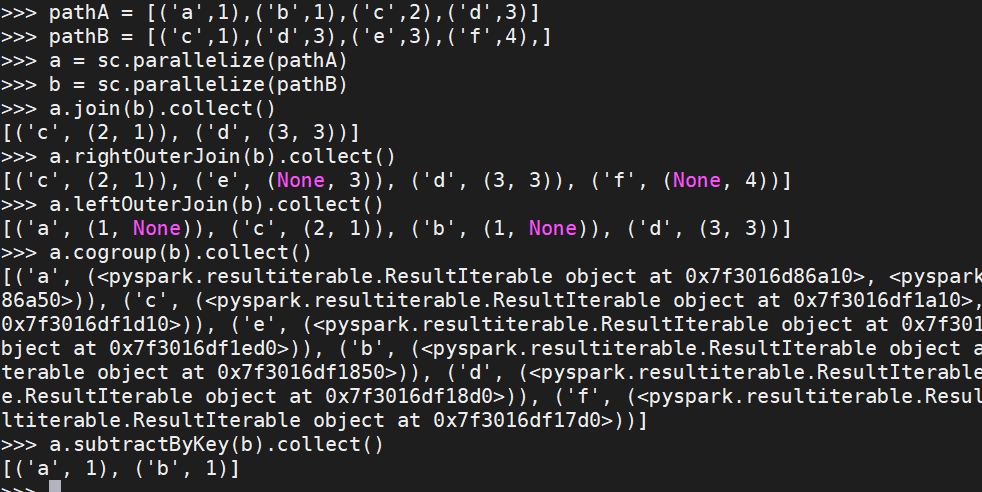
pathA = [('a',1),('b',1),('c',2),('d',3)]
pathB = [('c',1),('d',3),('e',3),('f',4),]
a = sc.parallelize(pathA)
b = sc.parallelize(pathB)
a.join(b).collect() # 内连接
a.rightOuterJoin(b).collect() # 右连接
a.leftOuterJoin(b).collect() # 左连接
a.cogroup(b).collect() # 全连接
a.subtractByKey(b).collect() # 减连接
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号