OCR 文字识别
安装OCR 开源库 Tesseract
- Tesseract 相比百度等在线库,最大优势是可以在本地运行
- 在这个页面下载最新的binary ,习惯用最新的安装包,
tesseract-ocr-w64-setup-v5.0.0-alpha.20201127.exe
- 双击安装 并勾选需要的语言支持包,主要是一些训练好的类似eng.traineddata的文件
- 如果再安装过程中报错,不用管它,点OK即可,因为网络连接问题会导致语言包安装不到位
- 可以在如下页面下载语言包
https://github.com/tesseract-ocr/tessdata/ -->
https://codeload.github.com/tesseract-ocr/tessdata/zip/refs/heads/master
- 将语言包中的.traineddata放入tesseract安装目录的tessdata目录下
测试Tesseract
- 显示版本
"C:\Program Files\Tesseract-OCR\tesseract.exe" -v
tesseract v5.0.0-alpha.20201127
leptonica-1.78.0
libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.3.0
Found AVX2
Found AVX
Found FMA
Found SSE
Found libarchive 3.3.2 zlib/1.2.11 liblzma/5.2.3 bz2lib/1.0.6 liblz4/1.7.5
Found libcurl/7.59.0 OpenSSL/1.0.2o (WinSSL) zlib/1.2.11 WinIDN libssh2/1.7.0 nghttp2/1.31.0
- 显示已经支持的语言
"C:\Program Files\Tesseract-OCR\tesseract.exe" --list-langs
List of available languages (2):
eng
osd
命令行参数参考
https://github.com/tesseract-ocr/tesseract/blob/master/doc/tesseract.1.asc
测试一张简单图
- 原图: 图上右键存图 保存为03.png
- 结果

"C:\Program Files\Tesseract-OCR\tesseract.exe" 03.png 03 --dpi 300
Tesseract Open Source OCR Engine v5.0.0-alpha.20201127 with Leptonica
参考 pysource
https://pysource.com/2020/04/23/text-recognition-ocr-with-tesseract-and-opencv/
- 这是一位外国小哥的个人网站,专门讲解机器视觉相关内容,还有很详细的YouTube视频,练习英语听力也很好
- 他在他的课程介绍中说了这样一段话,我认为很好的说出来新技术学习过程中的痛点:
You want to work with COMPUTER VISION and
** you don’t know where to start? **
I know how it feels! When you look for ** “Object detection” on Google you get simply overwhelmed by the amount of information ** you find: YOLO, Tensorflow, Keras, OpenCV. And then Pytorch, Caffe, SSD, R-CNN just to name a few.
I’m sure you surfed through different sources about Computer Vision, Object Detection and Object Tracking, watched video tutorials on youtube about it, read blog posts, or even bought some books and courses but still you’re not able to build the Project you need because:
- On the articles you read there is TOO MUCH THEORY and not real-life applications
- Video tutorials gave you only partial information and you don’t know how to use it
- Courses are just too long and not straight too the point
- The information you found left you even more confused than when you started
- Books and Courses are hard to follow and you never get to read their end
** You need SIMPLE and EFFICIENT solutions **
Nowadays Time is one of your most valuable assets!
As a student, researcher, or professional ** you’re bound to tight deadlines ** . As a freelancer and business owner, each hour of your time is worth hundreds if not thousands of dollars.
And it’s exactly for this reason that I built this course for people like you in mind, for people who value their time and that are ready to invest in premium content.
This is how my course is different from the other sources you’ve gone through so far:
Build Projects Easily and Quickly
Complete tutorials with clear information about each single step to build your project
Straight to the point but with precise explanations so that you know what you’re doing
4 Stand-alone modules, get what you need withouth going through everything
Discussion section where you can ask me questions
tesseract 识别中文
- 参考 https://www.cnblogs.com/wj-1314/p/9454656.html
- 请先加入chiXX.traineddata 到tesseract安装目录
- 没有训练时候直接使用库自带的语言包,
原图:
- 贴上Python代码
def test2():
text = pytesseract.image_to_string(Image.open('07.png'),lang ='chi_sim')
print(text)
- 运行的结果
最新的v5的tesseract比wj-1314准确率提升不少,逗号也很好的识别了

tesseract 识别中文 自己训练
- jTessBoxEditor最新下载地址在图片中

-
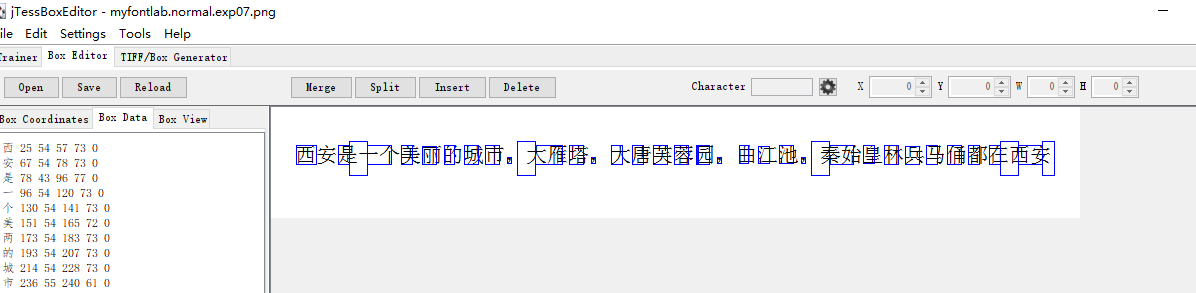
jTessBoxEditor直接打开PNG图也行,BOX文件如下,发现很多都没对齐的
-
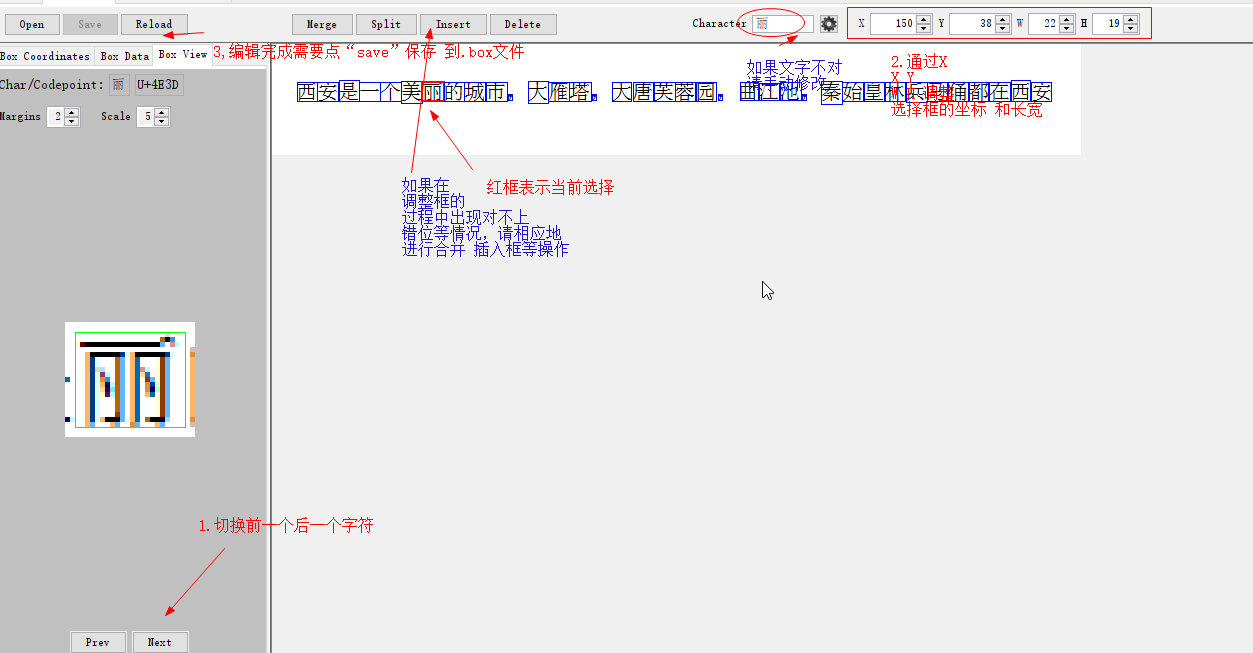
说明下jTessBoxEditor的用法
-
总结 关键命令如下,如有疑问,请对比参考wj-1314
tesseract myfontlab.normal.exp07.jpg myfontlab.normal.exp07 nobatch box.train
unicharset_extractor myfontlab.normal.exp07.box
shapeclustering -F font_properties.txt -U unicharset myfontlab.normal.exp07.tr
mftraining -F font_properties.txt -U unicharset -O unicharset myfontlab.normal.exp07.tr
cntraining myfontlab.normal.exp07.tr
combine_tessdata normal.
tesseract.exe myfontlab.normal.exp07.jpg out –l normal
- 成功应用训练的库,因为库中缺少空格等,用新训练的数据有错位的问题

完整的cmd日志如下
Microsoft Windows [版本 10.0.15063]
(c) 2017 Microsoft Corporation。保留所有权利。
C:\Users\admin>"C:\Program Files\Tesseract-OCR\tesseract.exe" -h
Usage:
C:\Program Files\Tesseract-OCR\tesseract.exe --help | --help-extra | --version
C:\Program Files\Tesseract-OCR\tesseract.exe --list-langs
C:\Program Files\Tesseract-OCR\tesseract.exe imagename outputbase [options...] [configfile...]
OCR options:
-l LANG[+LANG] Specify language(s) used for OCR.
NOTE: These options must occur before any configfile.
Single options:
--help Show this help message.
--help-extra Show extra help for advanced users.
--version Show version information.
--list-langs List available languages for tesseract engine.
C:\Users\admin>"C:\Program Files\Tesseract-OCR\tesseract.exe" -version
Usage:
C:\Program Files\Tesseract-OCR\tesseract.exe --help | --help-extra | --version
C:\Program Files\Tesseract-OCR\tesseract.exe --list-langs
C:\Program Files\Tesseract-OCR\tesseract.exe imagename outputbase [options...] [configfile...]
OCR options:
-l LANG[+LANG] Specify language(s) used for OCR.
NOTE: These options must occur before any configfile.
Single options:
--help Show this help message.
--help-extra Show extra help for advanced users.
--version Show version information.
--list-langs List available languages for tesseract engine.
C:\Users\admin>"C:\Program Files\Tesseract-OCR\tesseract.exe" --version
tesseract v5.0.0-alpha.20201127
leptonica-1.78.0
libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.3.0
Found AVX2
Found AVX
Found FMA
Found SSE
Found libarchive 3.3.2 zlib/1.2.11 liblzma/5.2.3 bz2lib/1.0.6 liblz4/1.7.5
Found libcurl/7.59.0 OpenSSL/1.0.2o (WinSSL) zlib/1.2.11 WinIDN libssh2/1.7.0 nghttp2/1.31.0
C:\Users\admin>tesseract
Usage:
tesseract --help | --help-extra | --version
tesseract --list-langs
tesseract imagename outputbase [options...] [configfile...]
OCR options:
-l LANG[+LANG] Specify language(s) used for OCR.
NOTE: These options must occur before any configfile.
Single options:
--help Show this help message.
--help-extra Show extra help for advanced users.
--version Show version information.
--list-langs List available languages for tesseract engine.
C:\Users\admin>D:
D:\>cd D:\\wj-1314_机器学习与OpenCV 博客园\PyOpenCVOCR
D:\\wj-1314_机器学习与OpenCV 博客园\PyOpenCVOCR>tesseract.exe myfontlab.normal.exp07.png myfontlab.normal.exp07 -l chi_sim batch.nochop makebox
Tesseract Open Source OCR Engine v5.0.0-alpha.20201127 with Leptonica
Warning: Invalid resolution 0 dpi. Using 70 instead.
Estimating resolution as 244
D:\\wj-1314_机器学习与OpenCV 博客园\PyOpenCVOCR>tesseract myfontlab.normal.exp07.png myfontlab.normal.exp07 nobatch box.train
Tesseract Open Source OCR Engine v5.0.0-alpha.20201127 with Leptonica
Warning: Invalid resolution 0 dpi. Using 70 instead.
Estimating resolution as 244
row xheight=9.5, but median xheight = 11.5
APPLY_BOXES:
Boxes read from boxfile: 36
APPLY_BOXES: Unlabelled word at :Bounding box=(425,54)->(427,73)
Found 36 good blobs.
1 remaining unlabelled words deleted.
Generated training data for 5 words
D:\\wj-1314_机器学习与OpenCV 博客园\PyOpenCVOCR>unicharset_extractor myfontlab.normal.exp07.box
Extracting unicharset from box file myfontlab.normal.exp07.box
Wrote unicharset file unicharset
D:\\wj-1314_机器学习与OpenCV 博客园\PyOpenCVOCR>shapeclustering -F font_properties.txt -U unicharset myfontlab.normal.exp07.tr
Failed to load font_properties from font_properties.txt
D:\\wj-1314_机器学习与OpenCV 博客园\PyOpenCVOCR>shapeclustering -F font_properties.txt -U unicharset myfontlab.normal.exp07.tr
Reading myfontlab.normal.exp07.tr ...
Building master shape table
Computing shape distances...
Stopped with 0 merged, min dist 999.000000
Computing shape distances...
Stopped with 0 merged, min dist 999.000000
Computing shape distances...
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances...
Stopped with 0 merged, min dist 999.000000
Computing shape distances...
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
Distance = 0.000000: Distance = 0.000000: Distance = 0.000000: Stopped with 3 merged, min dist 0.305882
Master shape_table:Number of shapes = 27 max unichars = 4 number with multiple unichars = 1
D:\\wj-1314_机器学习与OpenCV 博客园\PyOpenCVOCR>mftraining -F font_properties.txt -U unicharset -O unicharset myfontlab.normal.exp07.tr
Read shape table shapetable of 27 shapes
Reading myfontlab.normal.exp07.tr ...
Warning: no protos/configs for sh0024 in CreateIntTemplates()
Warning: no protos/configs for sh0025 in CreateIntTemplates()
Warning: no protos/configs for sh0026 in CreateIntTemplates()
Done!
D:\\wj-1314_机器学习与OpenCV 博客园\PyOpenCVOCR>cntraining myfontlab.normal.exp07.tr
Reading myfontlab.normal.exp07.tr ...
Clustering ...
Writing normproto ...
D:\\wj-1314_机器学习与OpenCV 博客园\PyOpenCVOCR>combine_tessdata normal
Combining tessdata files
Error: traineddata file must contain at least (a unicharset fileand inttemp) OR an lstm file.
Error combining tessdata files into normal.traineddata
Version string:v5.0.0-alpha.20201127
23:version:size=21, offset=192
D:\\wj-1314_机器学习与OpenCV 博客园\PyOpenCVOCR>combine_tessdata normal
Combining tessdata files
Error: traineddata file must contain at least (a unicharset fileand inttemp) OR an lstm file.
Error combining tessdata files into normal.traineddata
Version string:v5.0.0-alpha.20201127
23:version:size=21, offset=192
D:\\wj-1314_机器学习与OpenCV 博客园\PyOpenCVOCR>combine_tessdata inttemp
Combining tessdata files
Error: traineddata file must contain at least (a unicharset fileand inttemp) OR an lstm file.
Error combining tessdata files into inttemp.traineddata
Version string:v5.0.0-alpha.20201127
23:version:size=21, offset=192
D:\\wj-1314_机器学习与OpenCV 博客园\PyOpenCVOCR>combine_tessdata normal
Combining tessdata files
Error: traineddata file must contain at least (a unicharset fileand inttemp) OR an lstm file.
Error combining tessdata files into normal.traineddata
Version string:v5.0.0-alpha.20201127
23:version:size=21, offset=192
D:\\wj-1314_机器学习与OpenCV 博客园\PyOpenCVOCR>combine_tessdata normal
Combining tessdata files
Output normal.traineddata created successfully.
Version string:v5.0.0-alpha.20201127
1:unicharset:size=1988, offset=192
3:inttemp:size=175100, offset=2180
4:pffmtable:size=324, offset=177280
5:normproto:size=3965, offset=177604
13:shapetable:size=526, offset=181569
23:version:size=21, offset=182095
D:\\wj-1314_机器学习与OpenCV 博客园\PyOpenCVOCR>
试用百度AI OCR
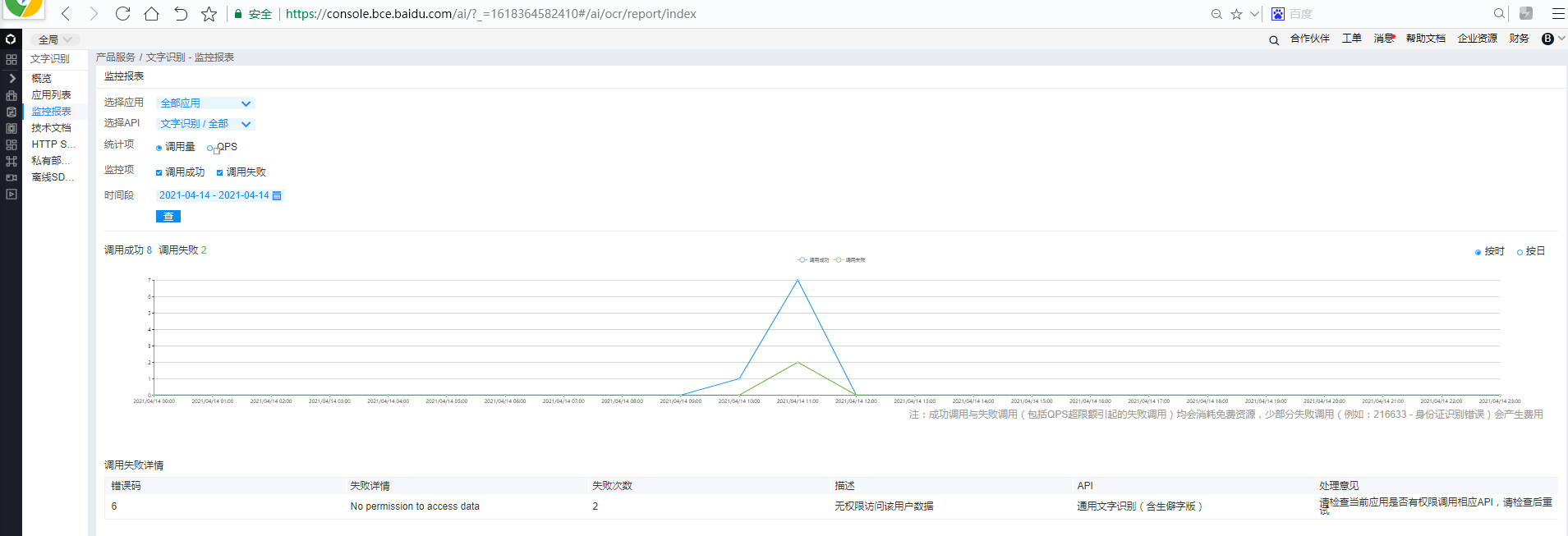
quickstart
- https://ai.baidu.com/ai-doc/OCR/dk3iqnq51
- quickstart 中有一段“小乐”写的Python代码 ,直接复制能用
- ** 代码过程分析 **
- download baidu ai kit
- get token by uisng your key
- send data to baiduapi ,HTTP GET
- see 接口说明
- https://ai.baidu.com/ai-doc/OCR/7kibizyfm
使用 AipOcr 类 client对象
- 贴上完整代码
# -*- coding: UTF-8 -*-
from aip import AipOcr
# 定义常量 这里修改为自己的KEY
APP_ID = 'abc'
API_KEY = 'abc'
SECRET_KEY = 'abc'
# 初始化AipFace对象
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
# 读取图片
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('07.png')
#image = get_file_content('binary_best2.png')
#image= get_file_content('qrcode.png')
# 调用通用文字识别, 图片为本地图片
res=client.accurate(image)
#res= client.qrcode(image)
print(res)
for item in res['words_result']:
print(item['words'])
pass
- 结果截图
确实比tesseract效果好很多,毕竟是国内开发的,对中文识别效果更好


 浙公网安备 33010602011771号
浙公网安备 33010602011771号