自定义字符串匹配度函数 解决字符串相似
因为日志项目名称不同格式(如.xlsx .csv .txt)匹配需要,最近看到一篇比较老的博客
据此 给出了一个很不错的匹配字符串的思路
// str1= "算法证明" , str2= "个人算法证明复印件"
//这里手动分词 ,可以考虑用第三方库 或者自定义分词方法
ArrayList<String> strs1 = new ArrayList<>();
strs1.add("身份");
strs1.add("证明");
ArrayList<String> strs2 = new ArrayList<>();
strs2.add("个人");
strs2.add("身份");
strs2.add("证明");
strs2.add("复印件");
T1 并 T2 ,并附加分数
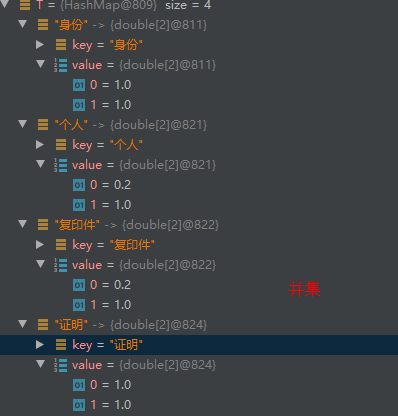
*
定义如下函数定义T1和T2的相似度 ,可以感知如果交集大、相似的成分多,则最后字符串匹配度高
while (it.hasNext()) {
double[] c = T.get(it.next());
Ssum += c[0] * c[1];
s1 += c[0] * c[0];
s2 += c[1] * c[1];
}
//自定义的字符串匹配度
return Ssum / Math.sqrt(s1 * s2);
//// 相似度: 0.8320502943378436
完整代码
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Stack;
public class Test1 {
public static double YUZHI = 0.2;
public static double getSimilarity(ArrayList<String> T1, ArrayList<String> T2) {
int size = 0, size2 = 0;
Map<String, double[]> T = new HashMap<String, double[]>();
//在T1 不在T2的 分数标记为 [1,0.2]
String index = null;
for (int i = 0; i < T1.size(); i++) {
index = T1.get(i);
double[] c = new double[2];
c[0] = 1; //T1的语义分数Ci
c[1] = YUZHI;//T2的语义分数Ci
T.put(index, c);
}
//遍历T2
for (int i = 0; i < T2.size(); i++) {
index = T2.get(i);
double[] c = T.get(index);
if (c != null) {
c[1] = 1; //T2中也存在,T2的语义分数=1
} else {
c = new double[2]; //说明是T2独有
c[0] = YUZHI; //T1的语义分数Ci
c[1] = 1; //T2的语义分数Ci
T.put(index, c);
}
}
//开始计算,百分比
Iterator<String> it = T.keySet().iterator();
double s1 = 0, s2 = 0, Ssum = 0; //S1、S2
while (it.hasNext()) {
double[] c = T.get(it.next());
Ssum += c[0] * c[1];
s1 += c[0] * c[0];
s2 += c[1] * c[1];
}
//百分比
return Ssum / Math.sqrt(s1 * s2);
// } else {
// throw new Exception("传入参数有问题!");
// }
}
public static void main(String[] args) {
//dd
ArrayList<String> strs1 = new ArrayList<>();
strs1.add("身份");
strs1.add("证明");
ArrayList<String> strs2 = new ArrayList<>();
strs2.add("个人");
strs2.add("身份");
strs2.add("证明");
strs2.add("复印件");
//根据分词返回相似度
double same = 0;
same = getSimilarity(strs1, strs2);
// 相似度: 0.8320502943378436
System.out.println("相似度:" + same);
//end dd
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号