






软工实践寒假作业(2/2)
软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 班级的链接 |
|---|---|
| 这个作业要求在哪里 | 作业要求的链接 |
| 这个作业的目标 | 阅读《构建之法》、学习GitHub使用、学习单元测试与性能分析 |
| 其他参考文献 | 百度教程GitHub,CSDN博客 |
GitHub项目链接:https://github.com/Tom-502/PersonalProject-Java
构建之法
- 作者有在书中提过这么一句话,“简单的说,软件的行为和用户的期望值不一样,就叫Bug,是否是Bug,取决于用户、开发者的不同角度。”这句话值得思考,在之前的理解,Bug指的是程序中没有被开发人员发现的问题,但这里给出了不一样的概念,开发人员有必要给用户最好的体验,而用户也对体验需求慢慢的有新要求,但如果用户得寸进尺,给开发人员难以接受的需求,这时这个Bug应该由谁负责。在下得出,应该是不同角度有不同的结果谁更合理谁获胜。
- 团队合作,这是一个在任何时候都不过时的话题,在软件工程中,是尤其重要,每个人能力不同,角度不同,风格不同。导致了团队不能友好有效的运行,在之前,在下就有几次不好的团队合作,工作分配不均,有的人不做事,拖到最后大家帮他擦屁股,书中也用猪,鸡举了一个生动形象的例子,若是一群猪组队,就不能是一个好团队了嘛。团队的成功到底如何定义。
- 这次老师让咱们写了一个PSP表格,这个表格在下个人认为,可能用处不是很大,若一个项目庞大复杂,这种表格还有使用价值嘛,还是说,他只是衡量学生工作的一个对照表。
- 这个可能扯到别的去了,"16-8图:高科技被炒作的规律"与"16-9图:股票泡沫的几个阶段"这两个图给了在下震撼,在下的舍友有买股票的,经常听他讲一些关于股票的东西,图中这些什么5G,芯片什么的,听舍友讲这几年都是热门,大涨的那种,但图中却是涨了再暴跌,难道舍友错了?这些并不是热点?还是涨幅太快,泡沫过多导致最后崩盘了。这些高新技术产业理应是热门,可能是发展到了瓶颈阶段。还是幕后操盘,割韭菜?这些目前不得而知。
- 小强地狱讲:开发人员可以忽视一定量的bug,优先保证核心功能的实现。但是这种开发模式真的好吗,前期忽视一定量的BUG,能保证后期核心功能不会有Bug么,如果能,则挺好的,若不能,后期BUG连环,处理是一件很麻烦的事情,就像前期地基不牢,后期建筑有不足,甚至要倒,重新从地基开始重建,真的合理吗。在下觉得可能可以边写边改,保证后期,但是在下只写过轻量级项目,不懂重量级是否适合小强。
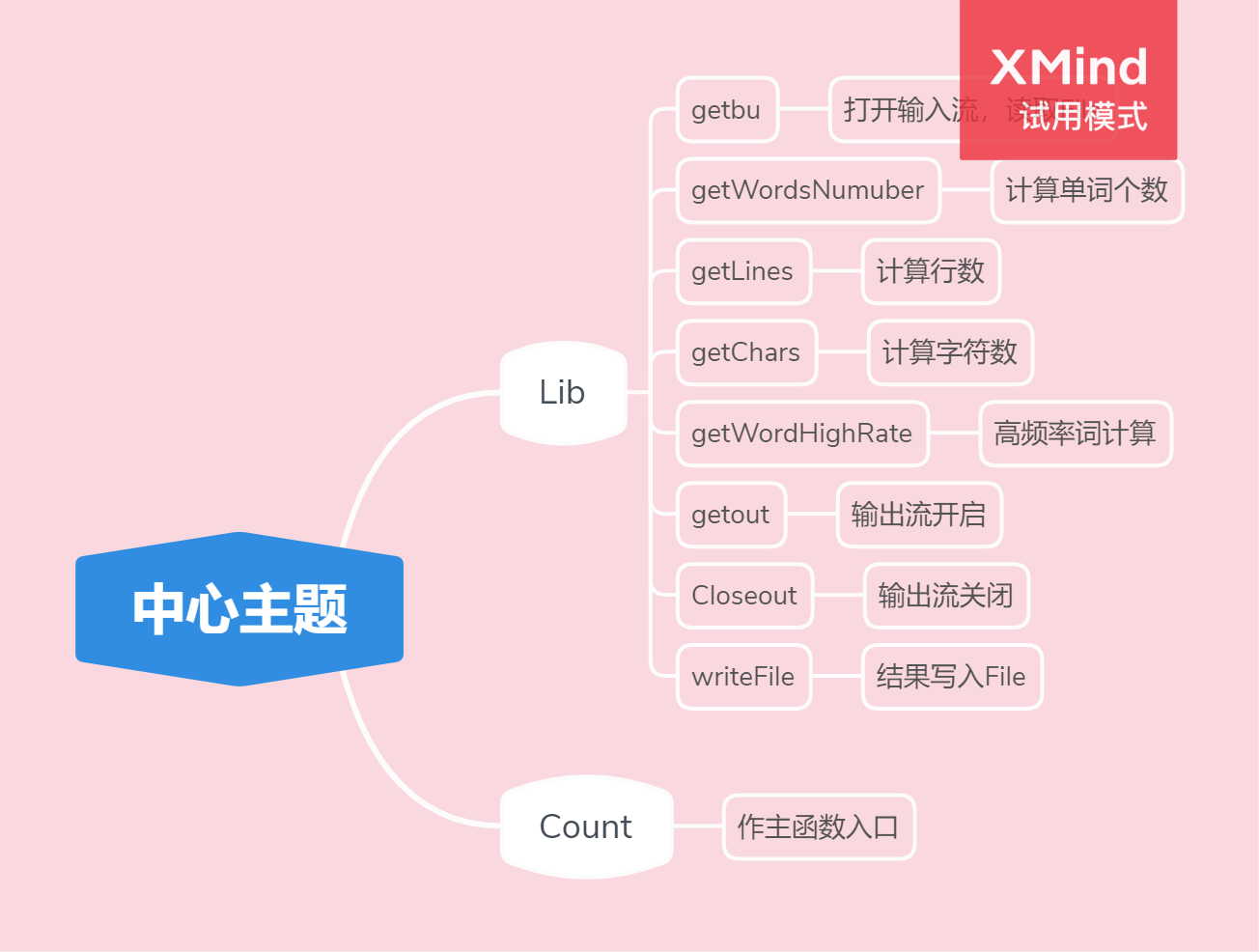
词频统计程序
1.PSP表格
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| • Estimate | • 估计这个任务需要多少时间 | 40 | 50 |
| Development | • 开发 | 500 | 500 |
| • Analysis | • 需求分析 (包括学习新技术) | 100 | 110 |
| • Design Spec | • 生成设计文档 | 20 | 30 |
| • Design Review | • 设计复审 | 30 | 20 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 100 | 60 |
| • Design | • 具体设计 | 60 | 50 |
| • Coding | • 具体编码 | 60 | 40 |
| • Code Review | • 代码复审 | 40 | 80 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 200 |
| Reporting | 报告 | 120 | 101 |
| • Test Repor | • 测试报告 | 90 | 100 |
| • Size Measurement | • 计算工作量 | 10 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 |
2.设计思路
- 一开始看到题,有点小懵,有些功能以前没写过,但是静下心来,打算一个一个逐一破解,遇到不会的先思考,超出一定的时间度,那只好求助与百度,b站等平台了。其实功能也并不多,5个,在下认真思考后,画出了大概的功能类图,函数图

3.代码规范
https://github.com/Tom-502/PersonalProject-Java/tree/main/221801324
4.代码展示
public void getWordsNumuber() throws FileNotFoundException //计算文件中单词个数
{
getbu();
String words;
try {
while ((words = bu.readLine()) != null)
{
String[] strs=words.split("[^a-zA-Z0-9]");
String zz = "^[a-zA-Z]{4,}.*"; //正则表达式筛选单词
for(int i=0;i<strs.length;i++)
{ if(strs[i].matches(zz))
{
CountWord++;
}
else ;
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
在这个函数中当读取的bu输入流不是空时,就进入功能,读取一行的字符,利用zz这个正则表达式,筛选符合规则的单词,如果符合,则CountWord(计算单词数的变量)加一。
public void getLines() throws FileNotFoundException
{ //计算文件有效行数
getbu();
try {
String line;
while ((line = bu.readLine()) != null)
{
char[] c=line.toCharArray();
for (int i=0;i<c.length;i++)
{ if (c[i]='\n') //计算行数
{
CountLine++;
break;
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
在这个函数中当读取的bu输入流不是空时,就进入功能,逐个读取字符,通过判断是否是换行符来使CountLine加一
public void getChars() throws FileNotFoundException
{ //计算文件字符数
getbu();
try {
char ch;
while((ch=(char)bu.read())!=(char)-1)
{ if(ch<=127) //确保读取的字符为ASCLL码
{
CountChar++;
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
在这个函数中当读取的bu输入流不是空时,就进入功能,逐个读取字符,判断是否是ASCLL码,是则CountChar加一
public void getWordHighRate() throws IOException
{
//输出高频次
getbu();
String words;
list = new ArrayList<Map.Entry<String, Integer>>(map.entrySet());
while ((words = bu.readLine()) != null)
{
String[] strs = words.split("[^a-zA-Z0-9]"); //正则选取单词
String zz = "^[a-zA-Z]{4,}.*";
for (int i = 0; i < strs.length; i++)
{
if (strs[i].matches(zz)) {
if (!map.containsKey(strs[i].toLowerCase()))
{ //删除重复出现在map中的单词
map.put(strs[i].toLowerCase(), 1);
} else {
int num = map.get(strs[i].toLowerCase()); //单词修改小写
map.put(strs[i].toLowerCase(), num + 1);
}
}
}
}
list.sort(new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> a, Map.Entry<String, Integer> b)
{
if(a.getValue().equals(b.getValue())) { //若频率一样,这可以使其按字母表排序
return a.getKey().compareTo(b.getKey());
}
else
return a.getValue().compareTo(b.getValue()); //频率排序
}
});
}
在这个函数中当读取的bu输入流不是空时,就进入功能,利用正则表达式读取单词,存入map中,map键值对一个是单词,一个是单词出现的次数,读取出来的单词在map中匹配,使得单词出现次数可以得到更新,利用map.containsKey函数删除重复出现的键值对,再利用map.get(strs[i].toLowerCase())函数把map中的单词全部改成小写。重写了map.sort排序函数,使其在按照单词出现次数高到低排序的同时,若出现的次数相同,则按字母表排序
- 思路:File肯定是转化成字符串逐一操作,计算字符数好说,直接遍历加一,换行数,在下一开始懵了,回来发现计算/n即可,或者readline();搞定。单词数,这个百度发现用正则可以搞定。高频词,一开始想用直接一个数组,数组下标和值分别表示词汇和出现次数,后来发现map好用多了,转而使用map存储。
5.性能改进
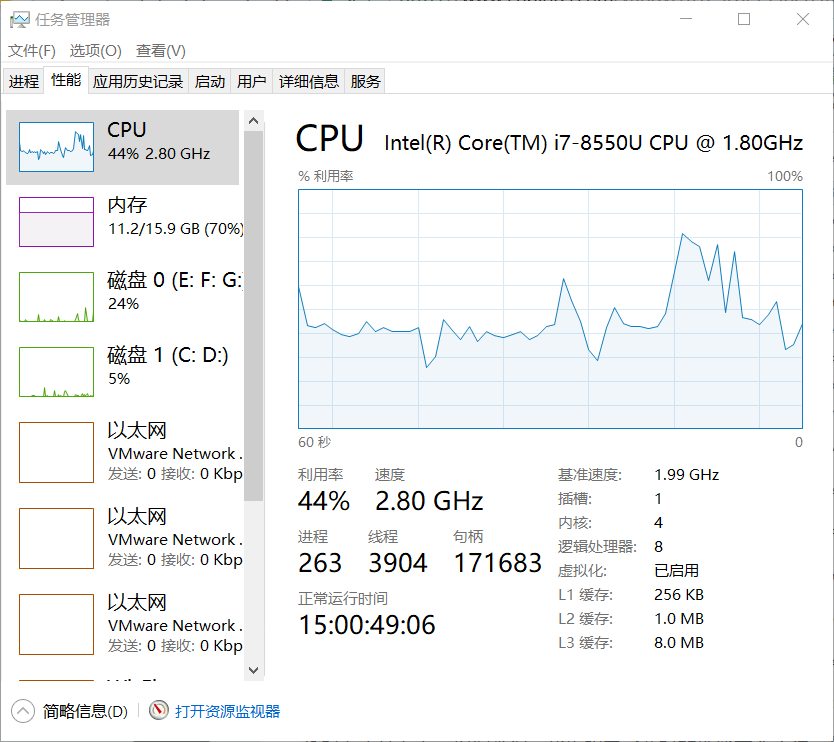
使用200M的File测试,发现电脑差点卡死,360球99%(肯是电脑太辣鸡),肯定得改进读取File改进,之前用String快炸了,然后百度,改用append()方法进行拼接,效果不错
其他的没有 什么太大的卡顿,优化了部分语句,使得处理字符串的速度有了小提升,有人建议在下使用多线程来解决,这个是个办法,可惜知道的太迟了,日后再实践。
6.单元测试
随机生成测试测试一下,发现不错
函数测试也不错
3.jpg
7.异常
在每个函数里都有异常处理,处理File不存在的情况。
体会
这次的作业不是非常难,静下心来3天基本就可以解决了,收货蛮多的。第一次体验到了一次又一次的优化程序,使其跑的速度越来越快,这是一件挺有成就感的事。也知道了不同的函数处理读取方式,真的在运行速度上有很大的差异。以后一定要多去处理这些,让自己写的程序可以运行的越来越快。

