

【Coursera课程笔记】Web智能和大数据Week3_MapReduce
本文目的
到今天为止,Coursera上的课程Web Intelligence and Big Data[5]已经上到Week 3(从0开始计数,实际上是4周)。前几周讲了一些机器学习的算法,如LHS,PageRank,朴素贝叶斯分类器等。但是光有这些算法还不够,特别是在当前这种海量数据(Big Data)盛行的年代。所以,Week 3就聊到了一种通用的大数据处理解决方法 —— Map Reduce(后面简称MR)。此方法最初来自Google的一篇论文[1],现在用来指代一种编程方式,主要作用与大规模数据集(通常在1T以上)的并行计算(很多算法都可以用MR方式实现)。本周课程主要内容介绍了MR的编程模型(结合Mincemeat[2]和Octopy[3]),运作原理和计算效率。在这里简单记录本周内容,作为备忘,对后面的工作会有帮助。
MapReduce编程方式
MR是一种编程模式。基于这种编程模式,可以有多种实现,鼎鼎大名的Hadoop就是其中之一。在MR的世界中,你只需要实现两个方法:map和reduce,剩下的所有事情交给MR框架,比如消息处理,中间数据存储,数据合并,容错等。
上千个廉价PC机并行处理,难免会出现服务器故障,至少出现一台服务器出错的概率为1-Pk,也就意味着随着机器数量K的增加,概率会趋近于1
Map函数的输入可以是任意序列,但输出必须是一个键值对{K,V},这一点很重要,因为MR框架会根据K,将不同K对应的V合并成一个列表,得到{K,V–List},然后将其作为reduce函数的输入,reduce的输出可以是任意数据。举个例子,有下列map和输出:
map1 –> {‘one’,1}, {‘two’,1}, {‘three’,1}
map2 –> {‘two’,1}, {‘world,1}
map3 –>{‘three,1}
那么经过合并后,得到中结果:
{‘one’, [1]}, {‘two’, [1,1]}, {‘three’, [1,1]}, {‘world’, [1]}
最后,MR框架会均匀的将上面的键值对分发给不同的Reduce函数。
由于Hadoop的环境搭建相对困难,如果想体验MR的编程方式,可以使用轻量级的MR框架Mincemeat[2](需要注意,在自定义map和reduce函数中,如果要引用外部函数或对象,需要在函数定义中import,否则会报错)或Octopy[3]。
Mincemeat代码学习
Mincemeat的源代码十分小,去掉注释,只有不到350行(是不是有点震精!)。但是麻雀虽小五脏俱全,具有MR的基本特性:
l 并行计算
l 容错
l 安全
Mincemeat运行原理
Mincemeat主要分两块:Server和Client。Server只有一个进程,用于调度,确保安全和执行容错的逻辑。Client就是真正做计算的进程(其他资料也称为Worker进程)。Mincemeat的网络通讯(Server与Client之间)采用的是Python内置的异步数据通讯框架asynchat(Python对本地Select和Poll的封装)。异步框架相对于多线程有个优点,不用处理线程间数据同步。这一点很重要,因为Mincemeat主要处理大数据并行计算,这样可以省去不少数据同步的开销。
Server启动后会监听端口11235,等待处理数据的Client进程。一旦有Client主动与Server连接,Server会与Client进行一些交互,大致如下,
1. 鉴权 根据预先设定的密码,确保次client的“合法性”
2. 传递方法 由于map,reduce和collect(可选)方法只在Server端定义,所以Server会将这些方法传递给Client。数据传递通过Python内置的marshal模块,对函数定义进行编码和解码。
3. Map阶段 Server会传递部分原始数据给Client并等待其处理结果。这里Mincemeat引入了collect环节,可以理解为一个mini reduce过程,其输入是一个局部的{K, V-List},该数据从当前Map处理的原始数据计算得到。
4. Reduce阶段 server会将map阶段的结果融合,然后将每一个{K,V -list}作为此阶段的输入
5. 结束 Server会将所有Reduce返回的结果合并,返回最后结果
Tips:Client可以在计算的任何时候(map阶段或reduce阶段均可以)加入计算,比如一开始只有1个Work计算,发现时间仍然很久,那么可以在其它计算机上启动client连接server,一起参与计算。或者,如果本机有多核,也可以同时启动多个进程,最大限度的利用多核计算能力。
Mincemeat有Client容错能力。重源代码中,不难发现在map阶段(reduce阶段类似),Mincemeat会标记每个Client处理的数据,标记使用原始输入的key。那么,Mincemeat就可以追踪每一块数据处理的状态,比如某个服务器宕机了,那么它当前处理的数据必然无法正确返回给Server,Server会在后面的某个时候将同样的数据分给其他的Client。但是没有Server容错,所以一旦Server挂掉,整个计算无法完成。
Mincemeat的优点和不足
个人能认为,Mincemeat适合MR学习和科学研究。如果使用在商业环境下会有下面的不足:1)没有Server容错,不稳定。2)计算结果放在内存中,所以一旦输出结果超过内存限制,那么Mincemeat无能为力。3)缺少自动化部署和执行client很局限,目前只能手动添加client,而且每个client的状态也不能事实显示。
虽然这样,我觉得Mincemeat还是很优秀的:1)比起同类的Octopy而言,效率要高很多;2)科研环境中,如果只做一两次MR并行计算,跑跑数据,写论文,整几台服务器,用Mincemeat跑跑成本还是很低的。3)简单,门槛低,为后面使用Hadoop等商业的MR框架打下基础。
MapReduce效率
MR框架会生成许多中间结果,这些中间结果的量级往往和输入数据相当,所以MR框架往往与分布式文件系统(DFS)是一对好基友。HDFS就是构建在Hadoop框架之上的分布式文件系统。这里,想用一种直观的方法讨论一下MapReduce的计算效率。
假设需要处理的数据量D,MR产生的中间结果为σD,σ是一个系数。ωD为单机处理D所需要做的计算量。P为MR框架可以并行的个数,那么效率公式如下:
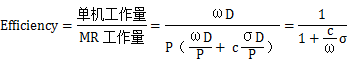
其中c是常量,MR的工作量等于每个处理器需要处理的实际工作量,在加上需要传输的中间结果。可以看到,MR的工作效率与处理器的数目(map+reduce的数目)没有关系,只与
σ有关,也就是与中间数据的比例有关。在使用MR框架计算时,需要尽可能的减少σ,提高MR的工作效率。
希望这篇文章对你理解MR有帮助!
参考资料
[1] MapReduce Simplified Data Processing on Large Clusters
[2] Mincemeat Project on Github
[3] Octopy: Easy MapReduce for Python
