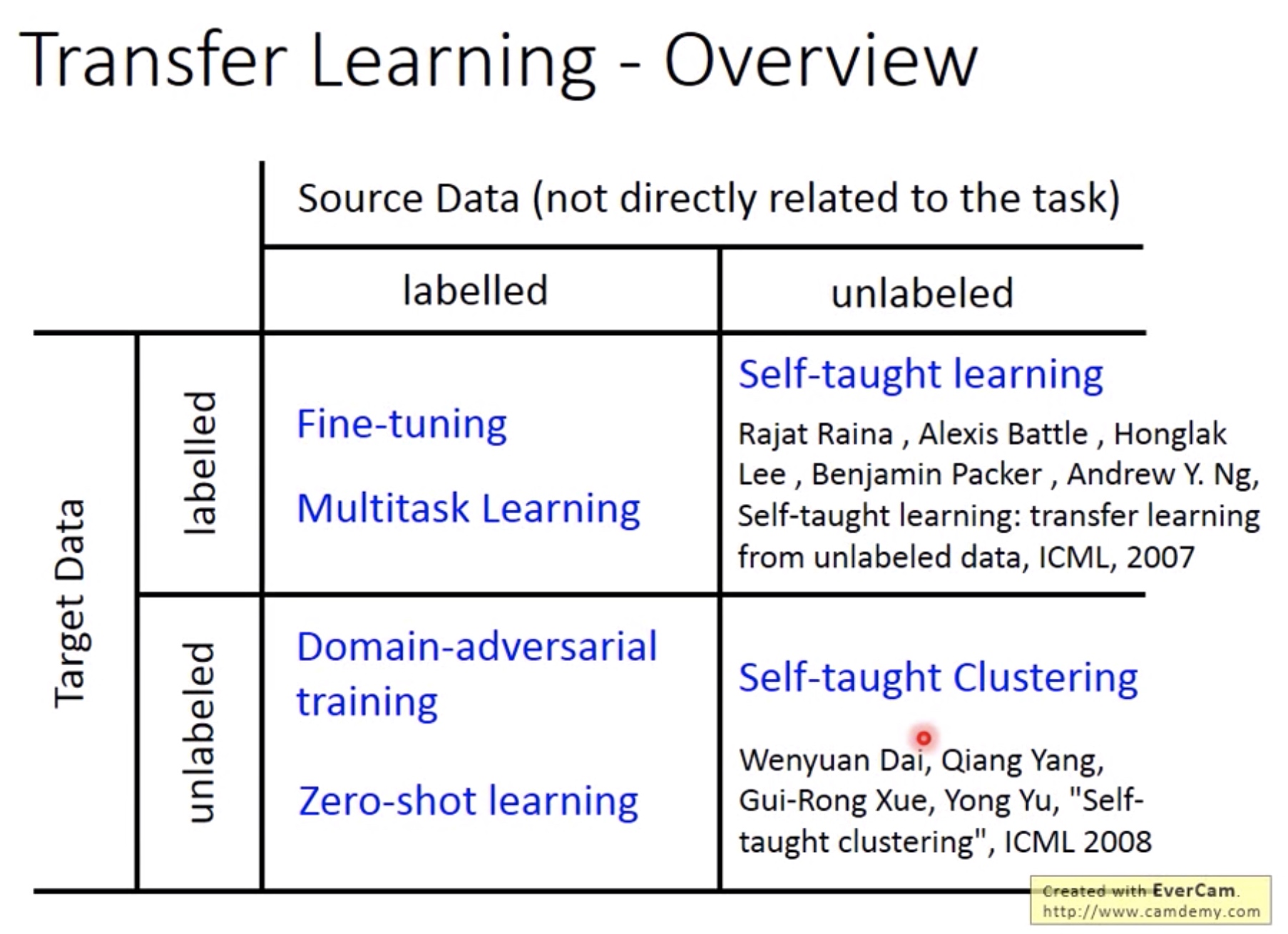
Transfer Learning
本文中的source data 和target data分别是有大量的非当前任务数据集和少量的当前任务数据集。

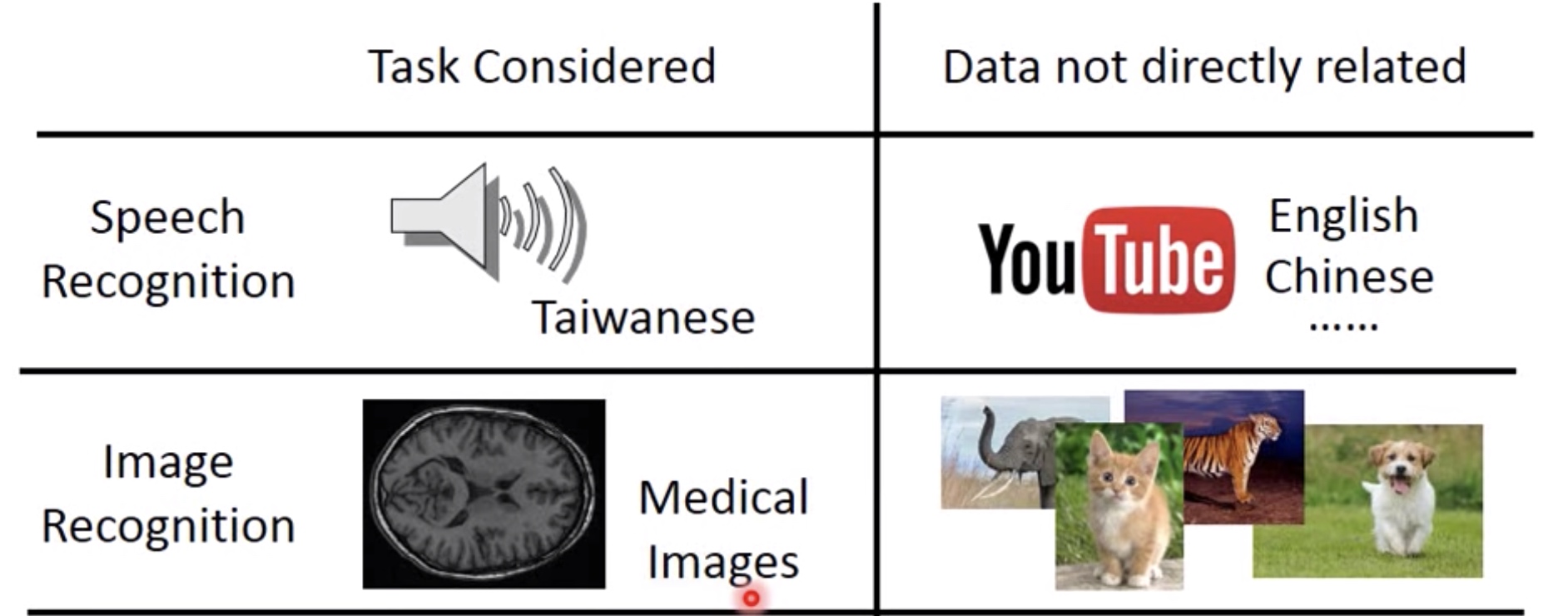
2 examples:

Both Labeled
1. Model Fine Tuning
 

-
当target data的量很少的时候,称为one-shot learning。
-
Fine Tuning: 将在source data中训练好的model作为target data的初始model继续训练。
-
Overtraining: 当target data的数量实在太少,在source 的 model一直训练就会出现overfitting.两种方法解决:
-
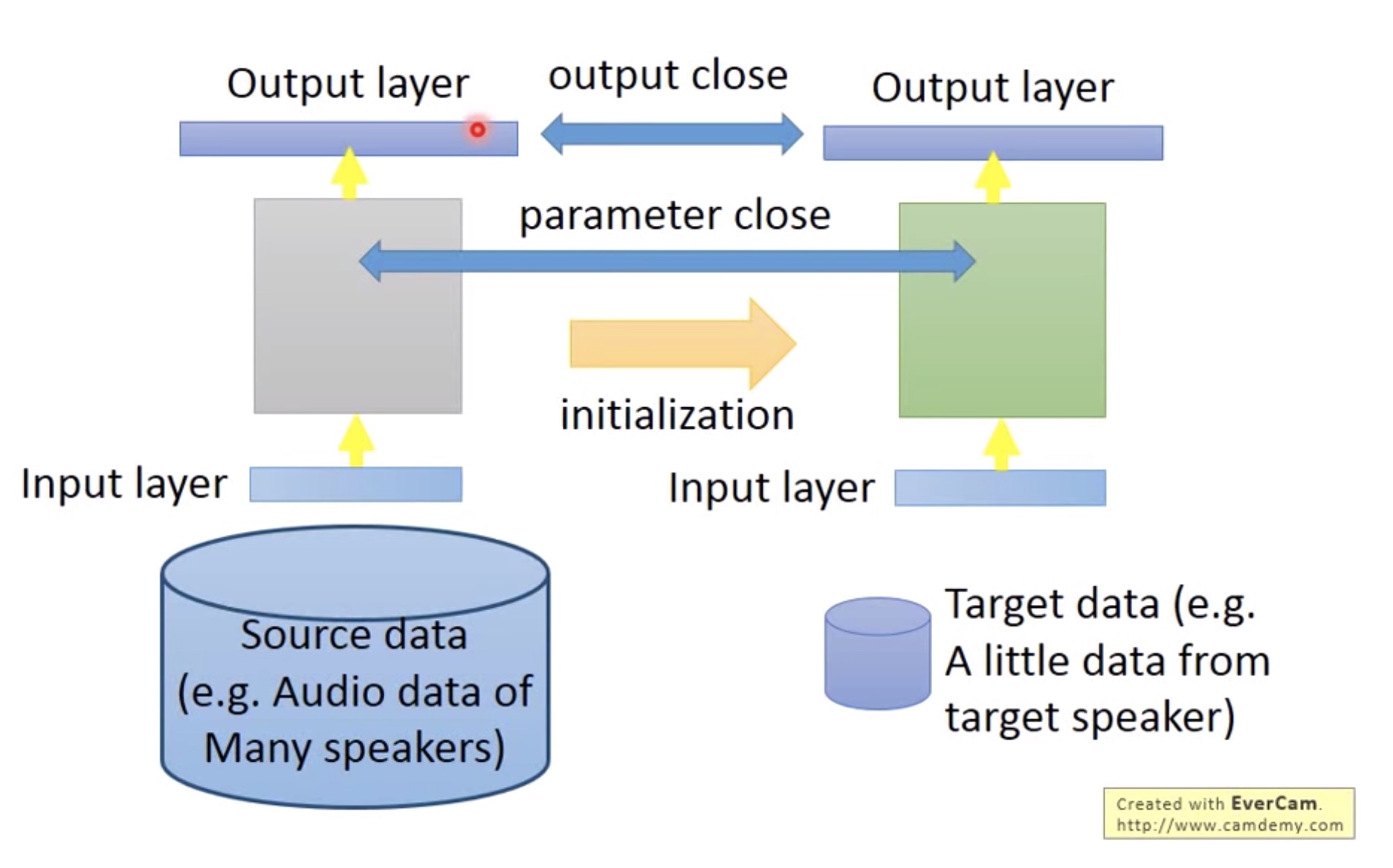
Conservative Training:
![]() 

做一些constraint:限制两个网络对于同一个输入的输出尽量接近,或者两个网络的参数尽量接近。 -
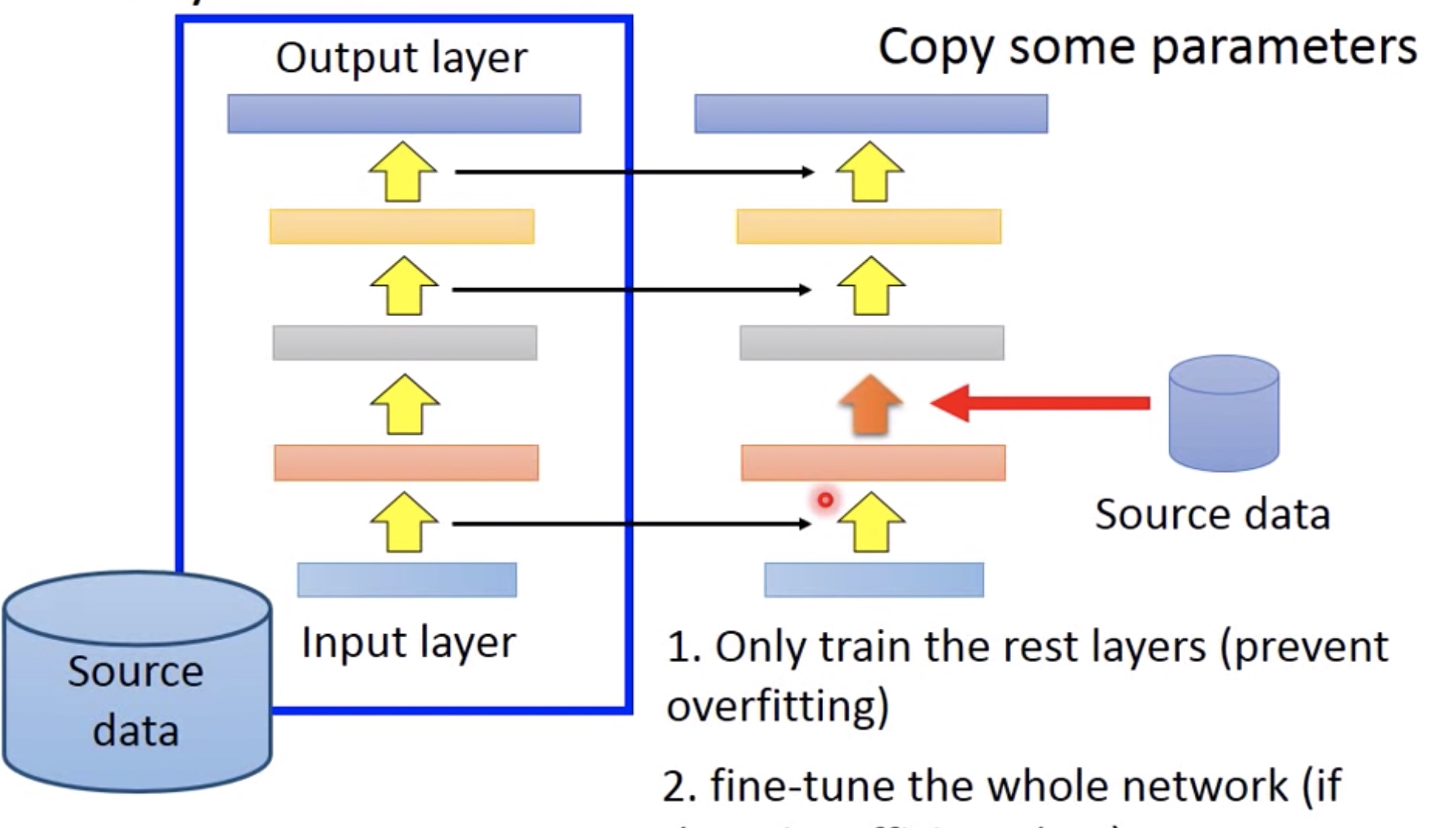
Layer Transfer:
![]() 

只训练source data网络其中的几层,其他层固定(直接copy)。那到底哪些layer需要训练,哪些可以固定?
不同的任务有对应不同的layer选择:
对于语音,因为每个人发音的生理结构不太一样,但每个词是一样的,因此需要训练前面几层,而后面几层直接copy。
对于图像,一些基本的轮廓是可以共享的,但最后图像的分类是不一样的,所以训练后面几层,而前面几层直接copy。
![]() 

-
 
2. Multitask Learning
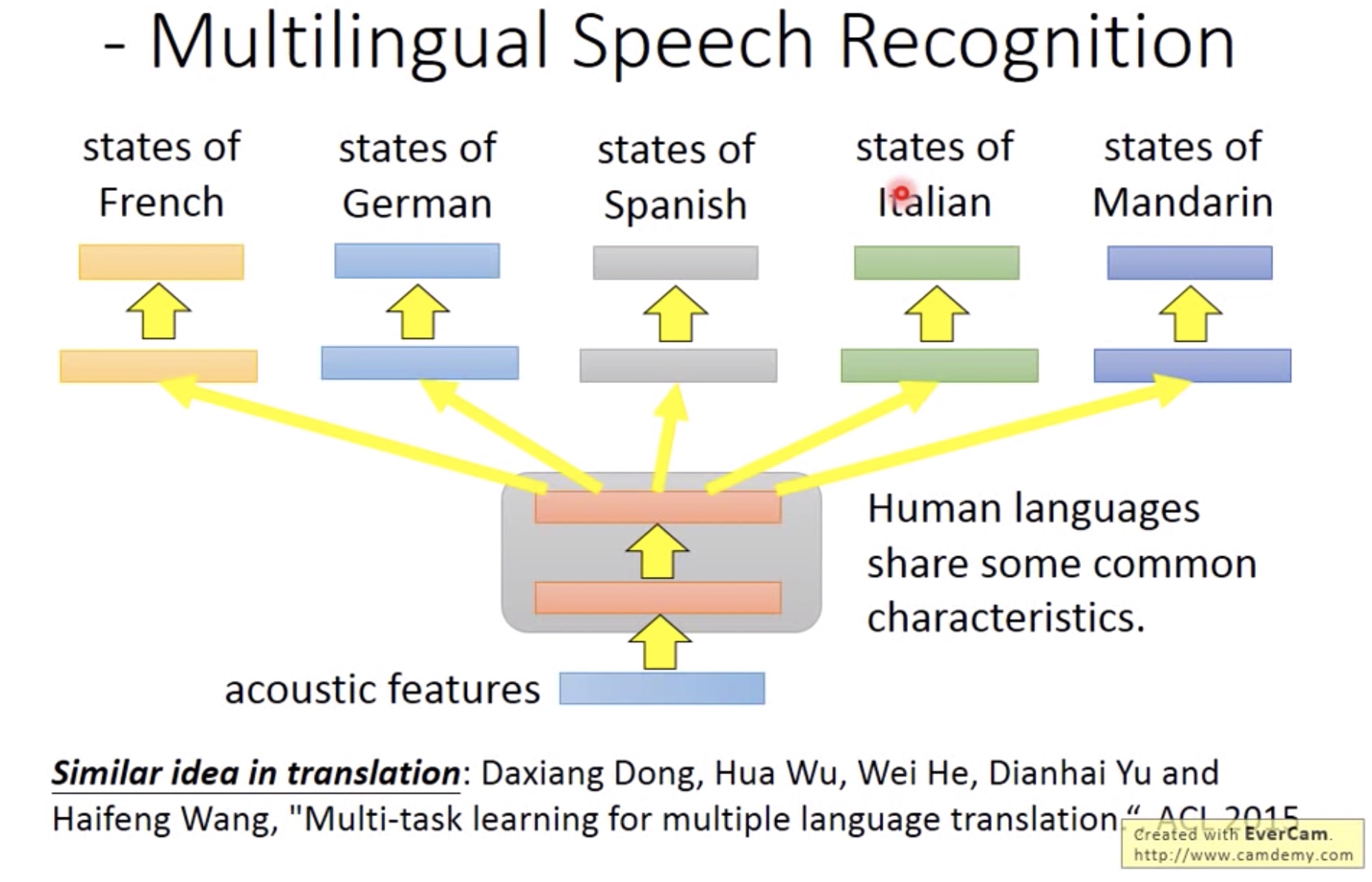 

下图橙线:用欧洲语言来帮助中文训练网络
蓝线:单纯用中文训练网络
 

3. Progressive Neural Network
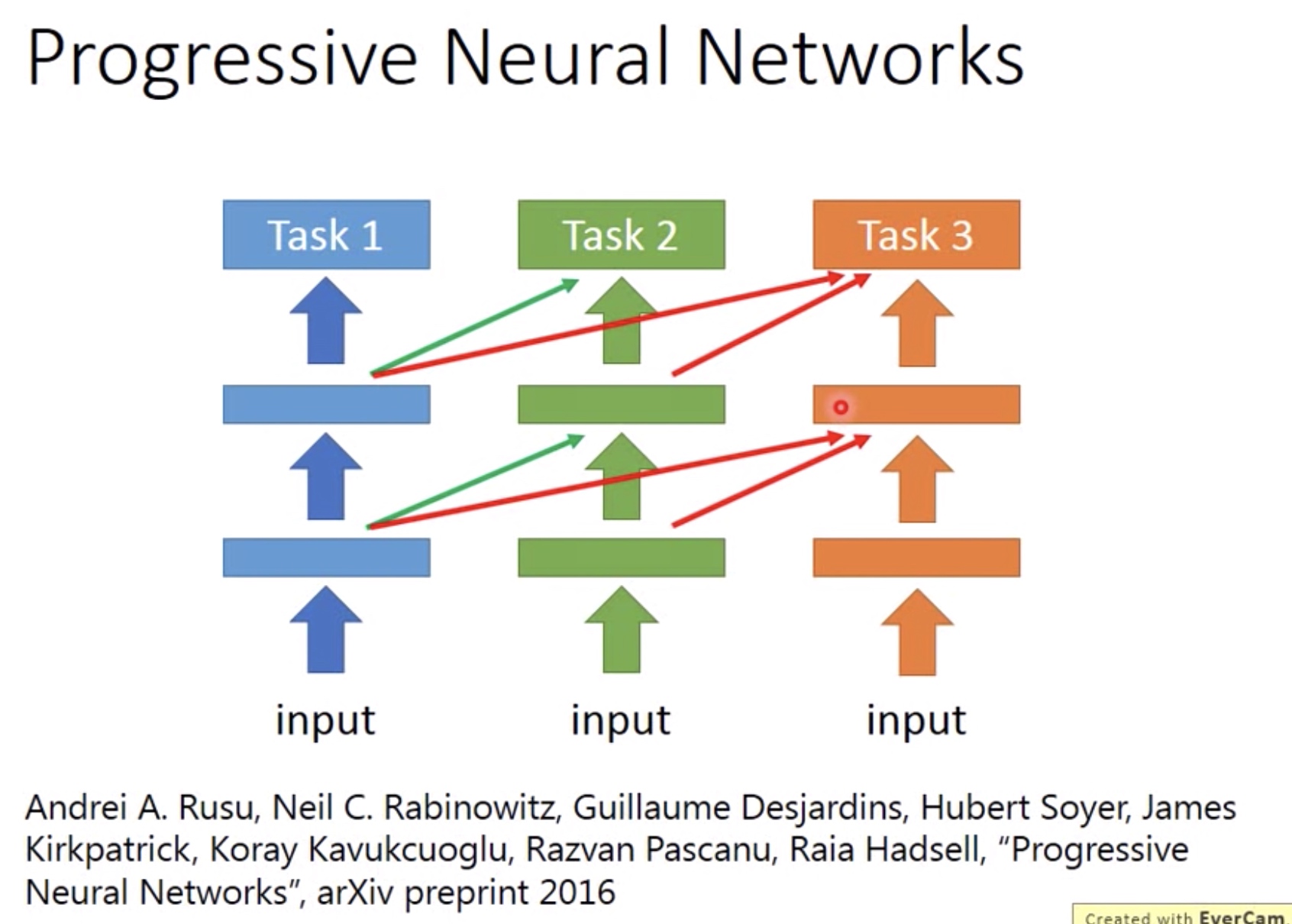 

Source Labeled Only
1. Domain Adversarail Training
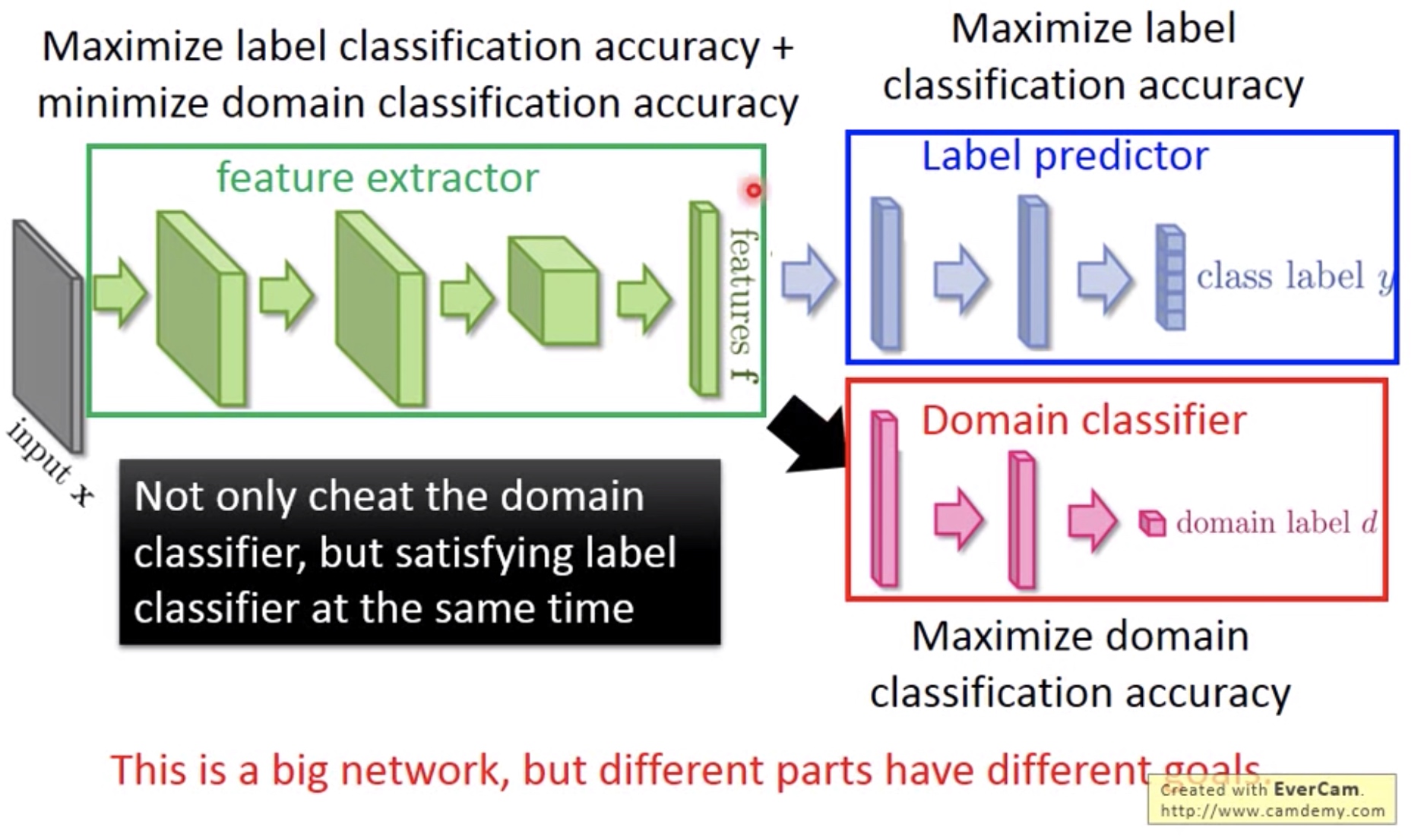
蓝色点表示feature extractor提取出来的source domain数据的特征,红点表示target domain,可以看到都是不一样的,所以后面的classifier只能分类出蓝色点的。因此我们希望经过transfer之后,蓝红点能有一样的特征分布。
思路:
增加一个Domain classifier,输出的是判断input是属于source 还是target domian. 这个Domain classifier的目标是提高判断的正确率。
而feature extractor要做的是降低Domain classifier的判断正确率。 这样可以使得feature extractor最终不懂得如何分辨红蓝数据,这样就可以把红蓝数据都混在一起之后,也就可以去掉feature extractor只识别source domain的特性。
但是feature extractor同时也要满足提高label predictor的正确率。
 

这里feature网络的目标有两个,一个与label网络一致,一个与domian网络相反,这样的training就能让feature网络把两类domain(source domain和target domain)输出后能混在一起。

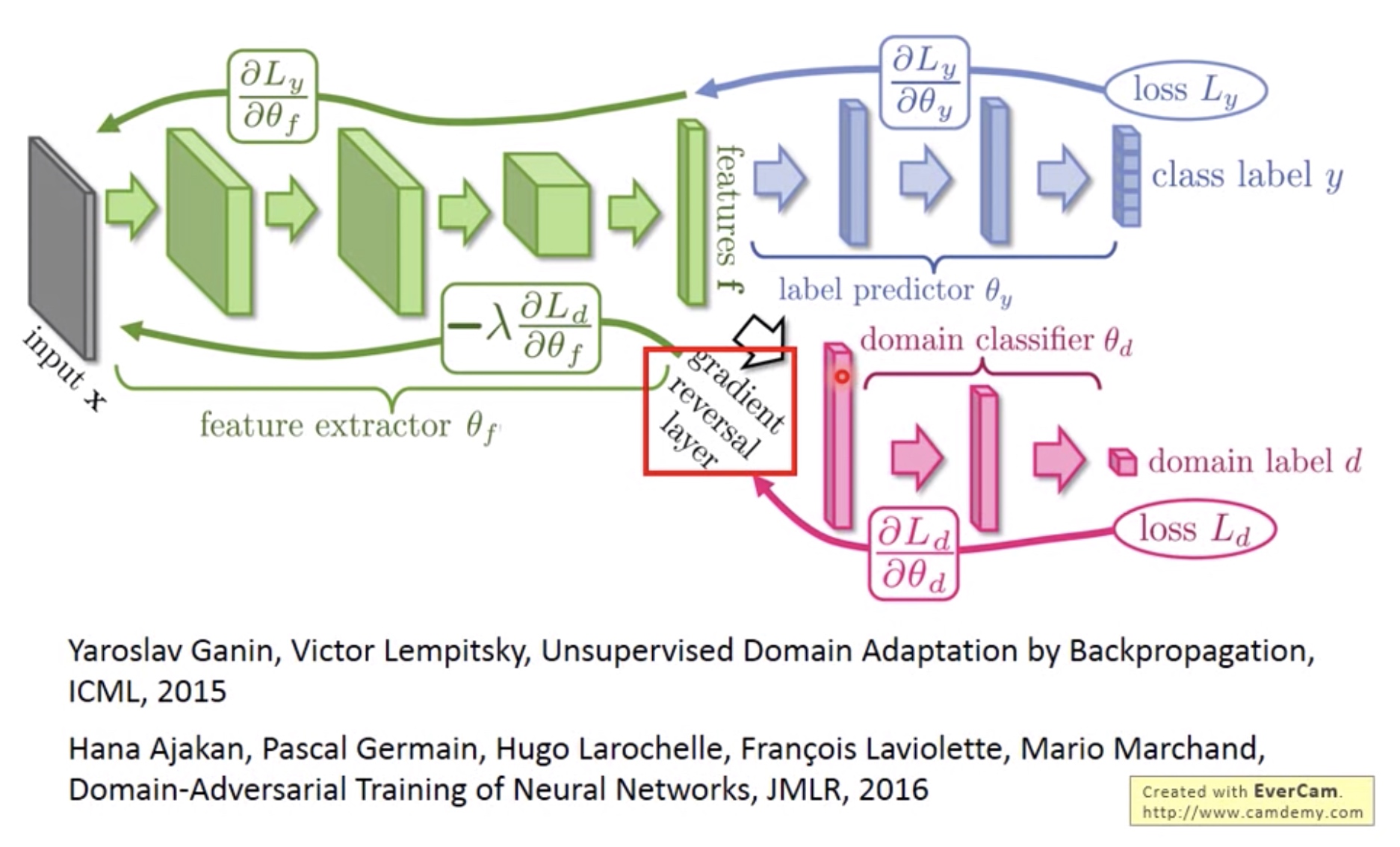 

要使得feature extractor层降低domain classifier正确率,可以求导loss之后取反方向更新参数即可。
2. Zero Shot Learning
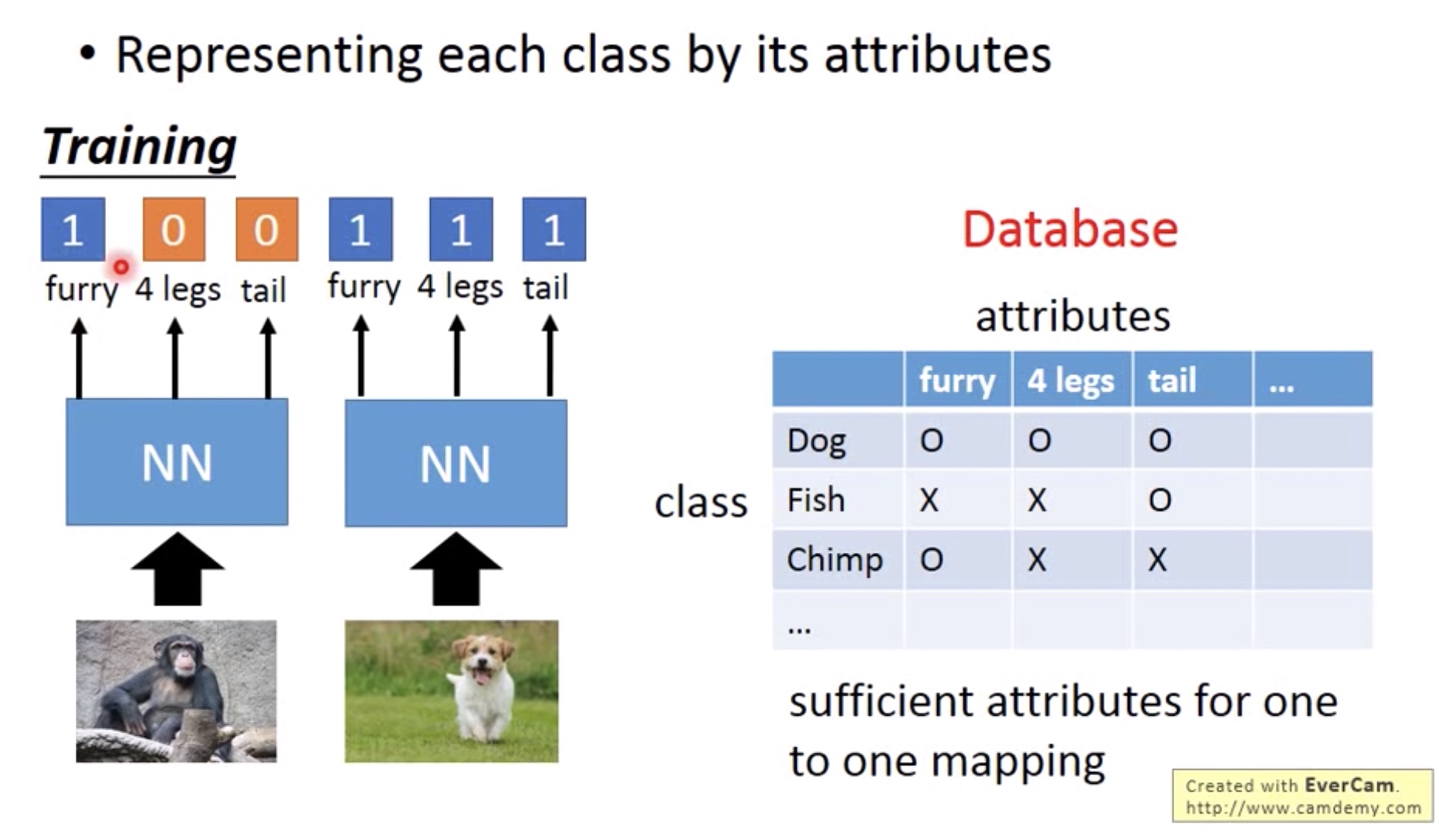
当我们的source date中没有出现target data时,我们可以提取两个domain的共同特征(Attribute) 作为训练对象。
比如:在语音的单词识别处理上,因为单词有很多个,所以有些单词在训练的时候没有出现过。因此可以找出单词的共同特征:音标(phoneme). 然后辨识出每个单词的phoneme, 再通过phoneme的组成查表找出对于的单词。

-
Attribute Embedding + Word Embedding
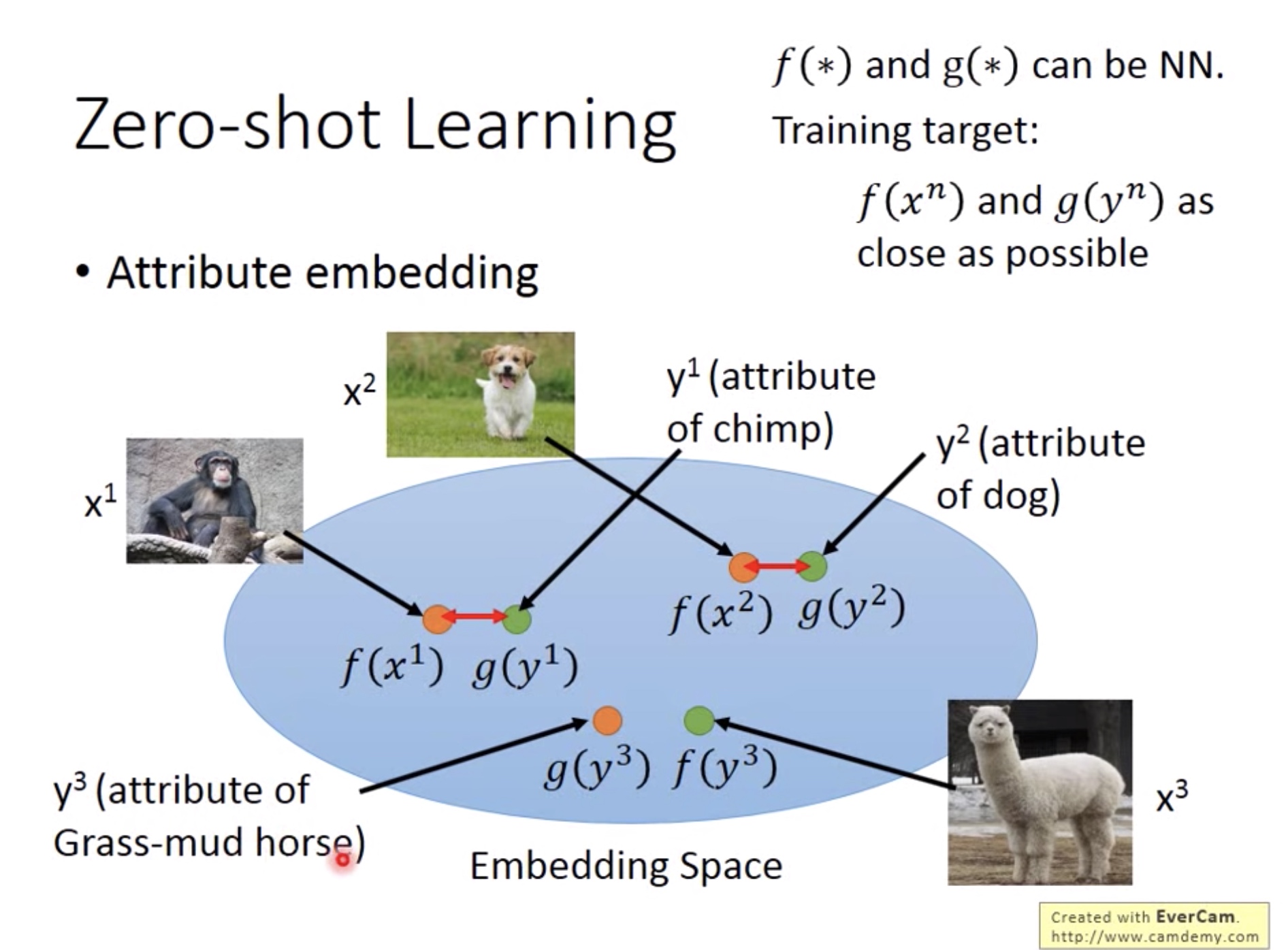
- Attribute Embedding:
当我们的特征(attribute) 具有太大的维度,或者难以提取特征的时候,我们可以通过一个transform/mapping g(x) 把特征embedding到一个空间中,同时在另一个transform/mapping f(x) 输入 input(在这里是image),input被embedding到同一个空间中。对应的input和attribute投影到空间中点的距离很接近,以此作为g和f的训练目标(将image和attribute都转为vector输入到transform中)。 - 这样当我们输入一个该网络没见过的input,网络也能自动找到对应最接近的attribute。
- Attribute Embedding:

-
-
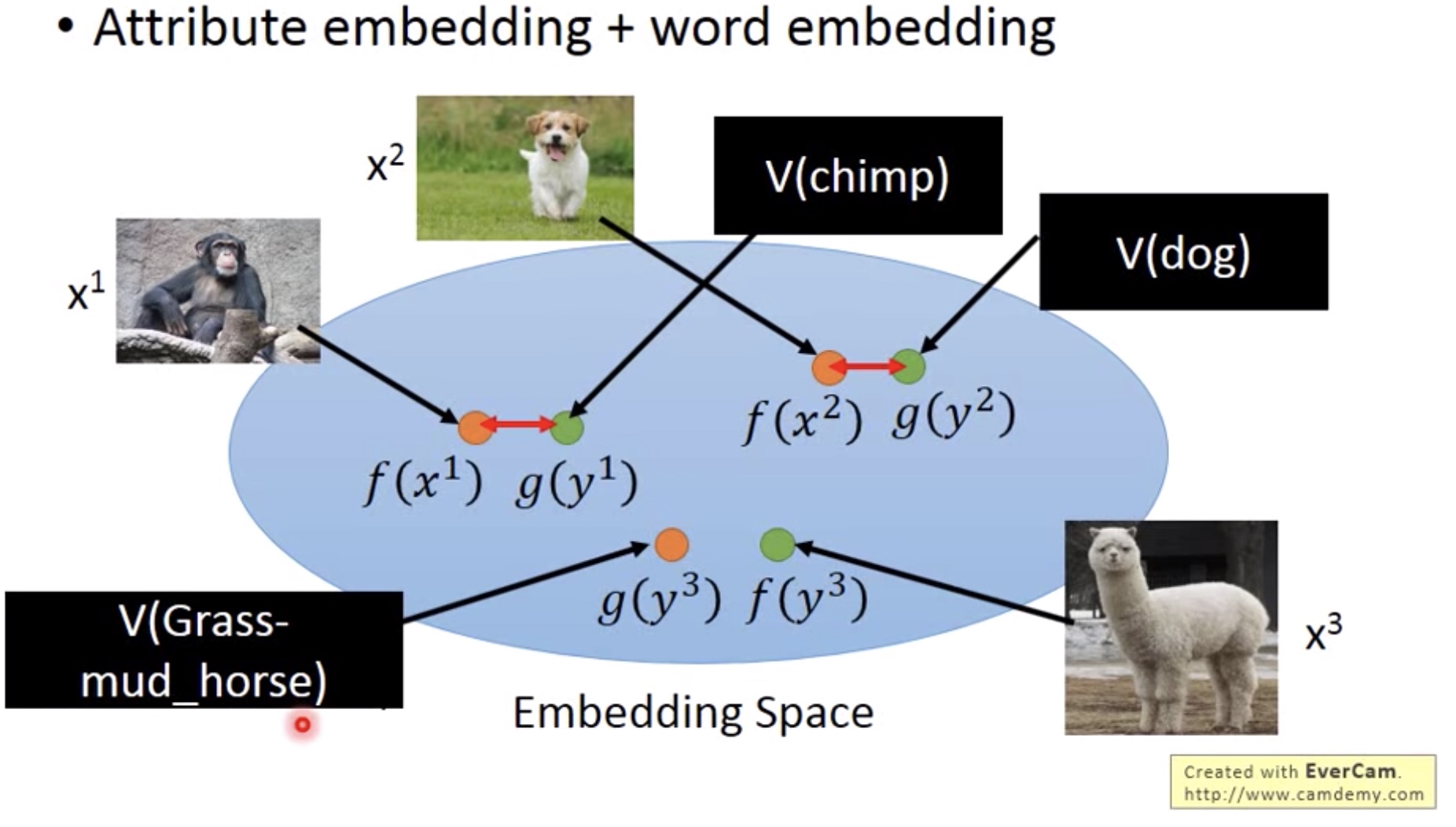
Word Embedding:
有时候我们可能无法找出每种动物的attribute (没有database),那么我们可以直接用动物的名称作为attribute。 -
![]() 
 -
Loss Function:如果只设为f和g的最短距离,会存在问题,因为只考虑了对应input和attribute的最短距离,而没有考虑非对应的input和attribute的距离应该尽可能远。因此在这里还要加入非对应距离的max项。
从下面的图可以倒推:对应的距离应该比所有非对应距离的最大值还要大于k(hyperparam),但因为欧氏距离没有赋值,所顺数第二式子需要一个0作为最小值。![]() 

-
 

posted on 2019-02-16 16:18 bourne_lin 阅读(503) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号