

Udacity DL Style Transfer
Style Transfer 的要点:
1. CNN不是用来传统的分类训练:网络训练的是target image,而不是网络的parameters (当然这里的网络是已经trained好的)。
2. target image由content image 和 style image组成。
3. image的style 由每一层layer中的feature maps之间的correlation得到(用Gram Matrix),转置矩阵相乘使得其content (object & shape)被忽略了。
4. 利用Bp使得content loss & style loss最小。
5. Udacity和李宏毅的说法不太一样:前者是用同一个网络,让style和content image作为固定输入,然后再让target image作为调整输入,然后使得style loss和image loss最大;而后者是直接把style和content image的风格作为网络参数,然后把target image调整输入,使得activation最大
6. 实际做法:将style和content image输入到一个trained network中,指定哪几层的输出代表style(Gram Matrix),哪几层的输出代表content,这些layer的输出作为update的target值,然后再输入一张target image(一般是白板或者Content image),通过与相应层的比较求loss function最优。。
7. content loss操作的是layer output的feature map每一个值;style loss操作的是gram 矩阵的每个值
I. Introduction
Style Transfer compose images based on CNN layer activations and extracted features.
Style can be thought of as traits that might be found in the brush strokes of a painting, its texture, colors, curvature(曲率), and so on.
The key to this technique is using a trained CNN to separate the content from the style of an image.
How to extract image content? When a CNN is trained to classify images, its :
- Convolutional layers:
- learn to extract more and more complex features from a given image.
- Max pooling layers:
- Discard detailed spatial information that's increasingly irrelevant to the task of classification.
- As deeper into a CNN, the input image is transformed into feature maps that increasingly care about the content of the image rather than any detail about the texture and color of pixels.
Later layers of a network are even sometimes referred to as a content representation of an image. (In this way, a trained CNN has already learned to represent the content of an image.)
- Convolutional layers:
How about style? To represent the style of an input image, a feature space designed to capture texture and color information is used. This space essentially looks at feature maps spatial correlations within a layer of a network. (Gram Matrix)
For example, for each feature map in an individual layer, we can measure how strongly its detected features relate to the other feature maps in that layer. Is a certain color detected in one map similar to a color in another map? What about the differences between detected edges and corners, and so on? See which colors and shapes in a set of feature maps are related and which are not.
E.g., we detect that mini-feature maps in the first convolutional layer have similar pink edge features. If there are common colors and shapes among the feature maps, then this can be thought of as part of that image's style.
So, the similarities and differences between features in a layer should give us some information about the style (texture and color) information found in an image. But at the same time, it should leave out information about the actual arrangement and identity of different objects in that image.
VGG19 In-between the five pooling layers, there are stacks of two or four convolutional layers. The depth of these layers is standard within each stack, but increases after each pooling layer.
To create target image, the VGG19 will first pass both the content and style images through this VGG network.
First, when the network sees the content image, it will go through the feed-forward process until it gets to a convolutional layer that is deep in the network. The output of this layer will be the content representation of the input image.
Next, when it sees the style image, it will extract different features from multiple layers that represent the style of that image. Finally, it will use both the content and style representations to inform the creation of the target image.
II. How to separate the style in an image?
要点:
1.每一层(stack)卷积层由多层(layer)卷积层组成。
2.stack的大小是multi-scale的,为了capture不同size的style feature。
3.style由Gram Matrix表示(non-localized information),忽略了图片的object和shape的arrangement, placement信息。
4.定义了一个style loss.
5.CNN不是用来传统的分类训练:网络训练的是target image。
a) Style Gram Matrix: the correlation of feature maps
The style representation of an image relies on looking at correlations between features in individual layer of the VGG19 network, in other words, how similar the features in a single layer are. Similarities includes general feature and colors found in that layer.
We typically found the similarities between features in multiple layers in that network. By including the correlations between multiple layers of different sizes, we can obtain a multi-scale style representation of that input image, which can capture large and small style features.
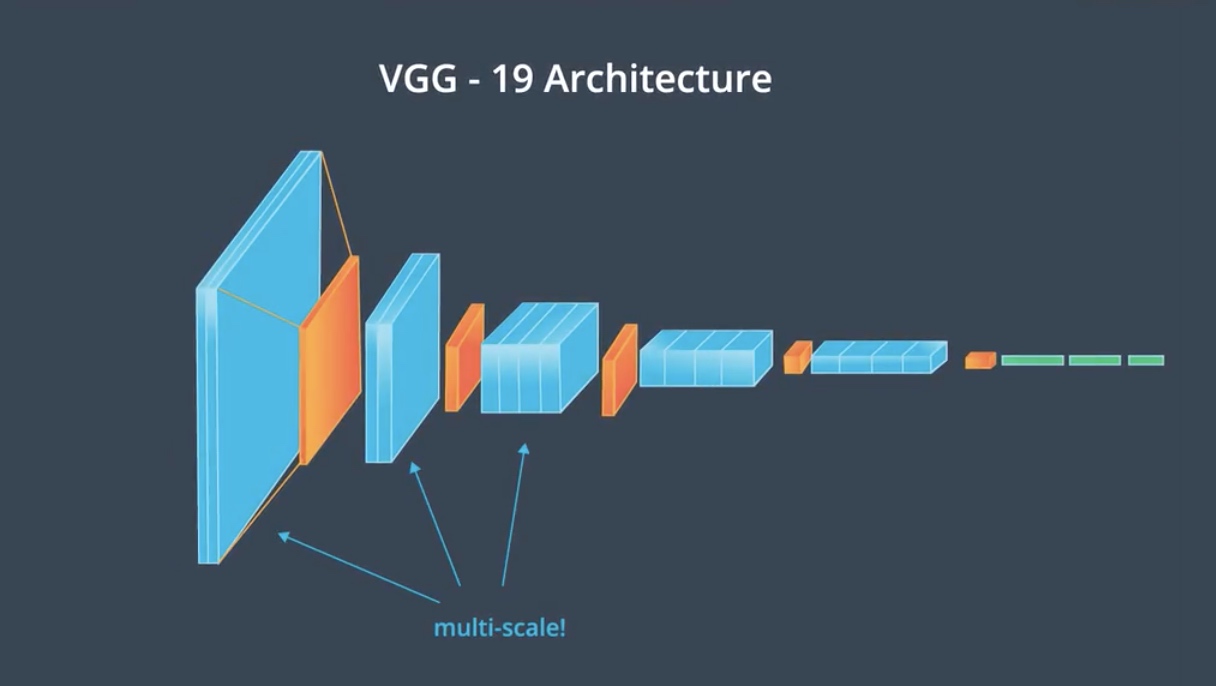 

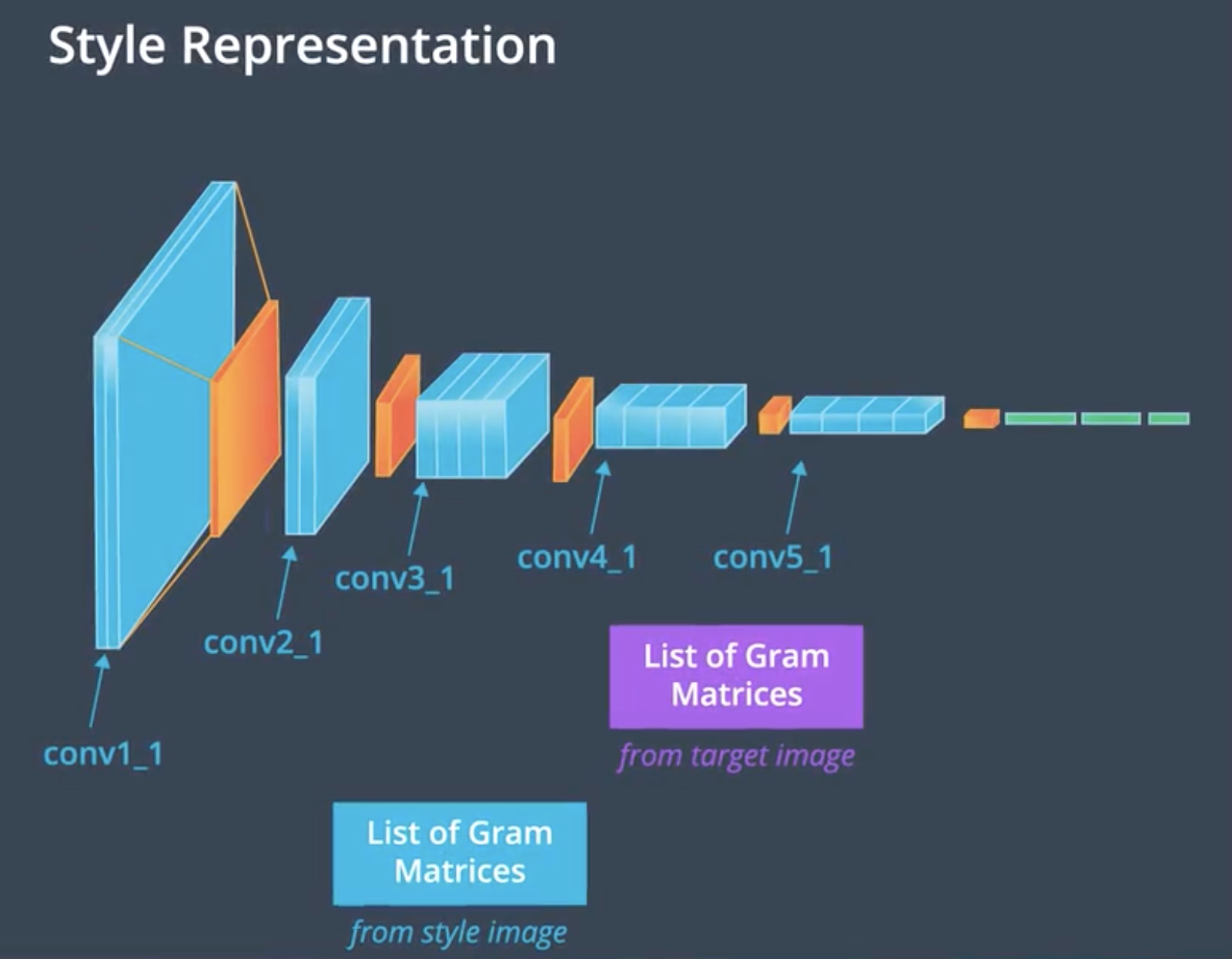
The style representation is calculated as an image passes through the network at the first convolutional layer in all five stacks, conv1_1, conv2_1 up to conv5_1. The correlations of each layer are given by a Gram matrix. The matrix is a result of couple operations.
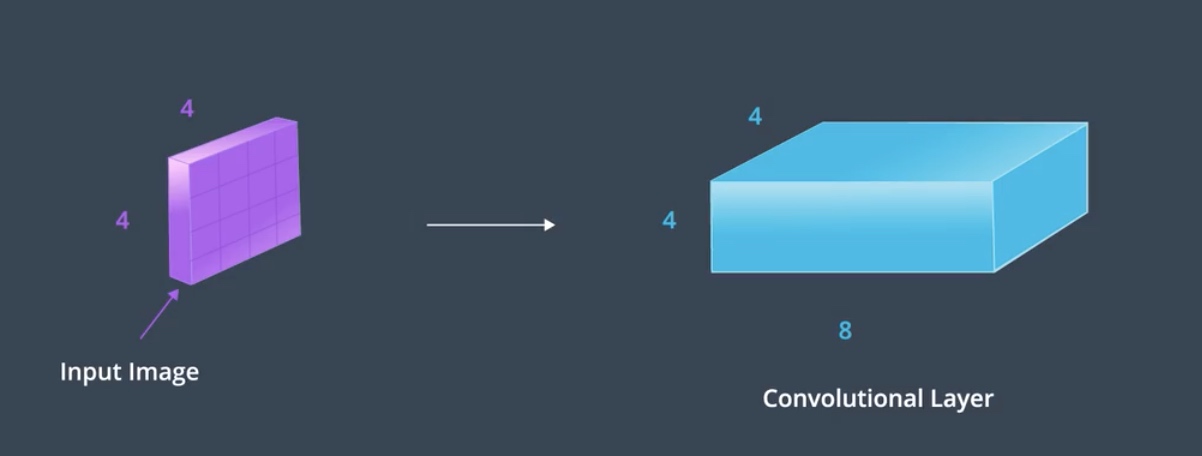
For e.g., Say we start up by 4 by 4 image, and we convolve it with 8 different filters to create a convolutional layer, this layer is 4 by 4 by 8. Thinking about the style representation for this layer, we can say this layer has 8 feature maps that we want to find the relationships between. (找出同一层layer的八个feature maps之间的关系)

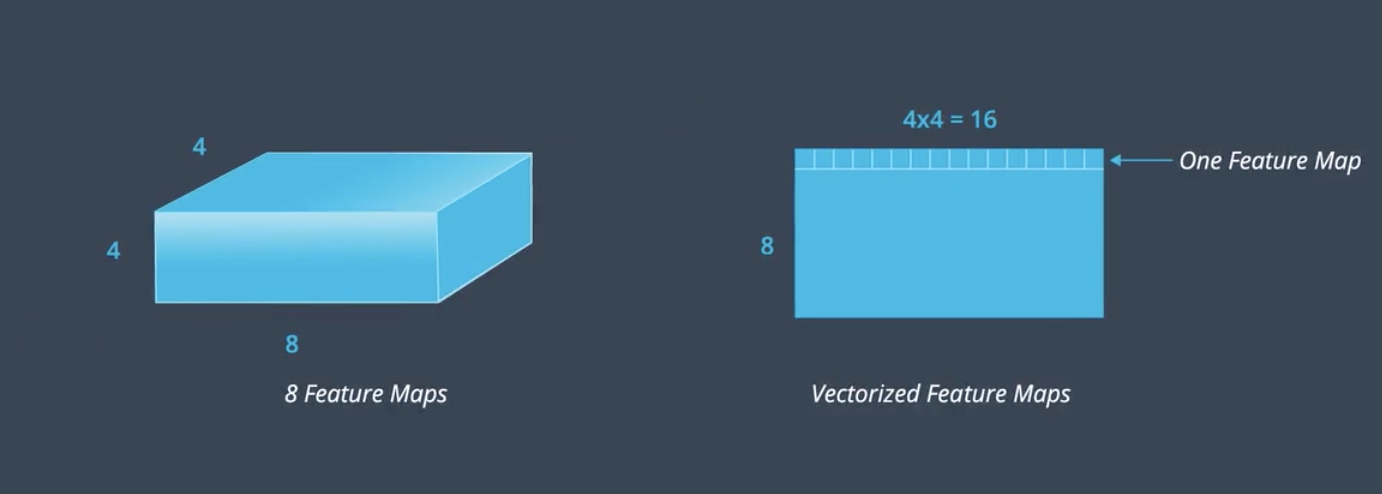
The first step in calculating the Gram matrix will be the vectorized the feature maps value in this layer.
 

By flattening, we transform the convolutional layer from 3D to 2D.

The next step is to multiply this matrix by its transpose. Essentially multiplying the features in each map to get Gram matrixes. This operation treats each value in the feature map as an individual sample, unrelated in space to other values(使feature map中的每一个值独立). And so the resultant Gram matrix contains non-localized information about the layer. Non-localized information is information that would still be there the image was shuffled around in space (non-localized 信息指即使所有像素的位置被打乱了,仍然能保留的图片信息,比如style:color & texture). For example, even a content of a filter image is not identifiable, you should still be able to see the prominent(突出的)color and the texture(style), finally we get the square 8 by 8 matrixes whose value indicates the similarity between the layer.
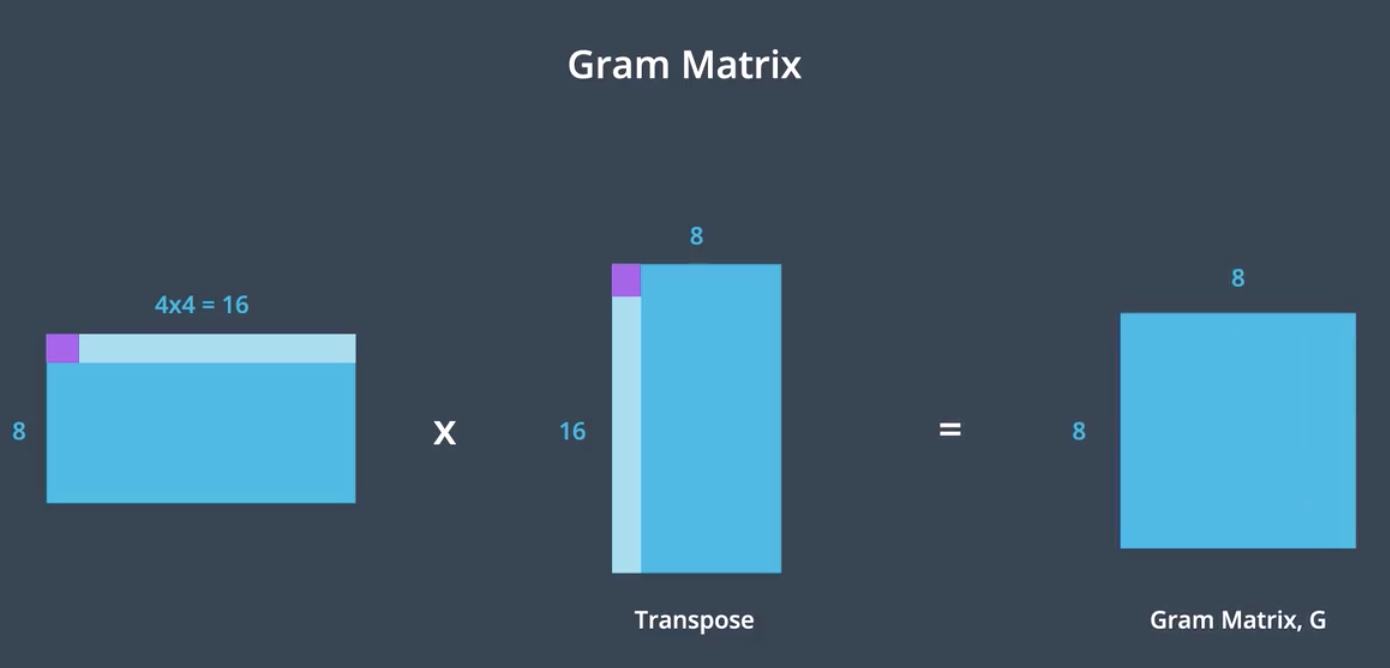 

So row 4 column 2 will hold the value that indicates the similarity between the 4th and 2nd feature maps in that layer. And importantly, the dimensions of the matrixes are only related to the number of feature maps in the convolutional layer, it does not depend on the input image dimension.
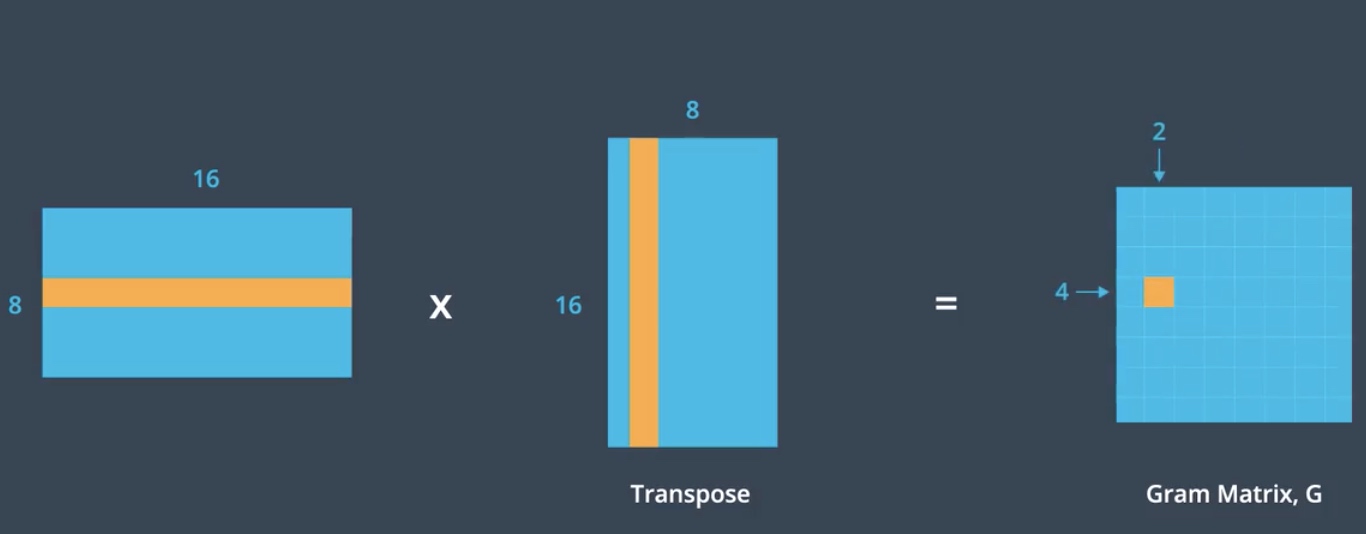 

Gram matrix is just one mathematical way to represent the idea of shared prominent(突出的) style. Style itself is an abstract idea but the Gram matrix is the most widely used in practice. Now we defined the gram matrix that has the information of the style of a given layer, then we can calculate the style loss that compared the target image and style image.
b) Style Loss
To calculate the style loss between a target and style image, we find the mean squared distance between the style and target image gram matrices, all five pairs that are computed at each layer in our predefined list, conv1_1 up to conv5_1. These lists, I'll call Ss and Ts, and ‘a’ is a constant that accounts for the number of values in each layer. We'll multiply these five calculated distances by some style weights W that we specify, changing how much effect each layer style representation will have on our final target image.

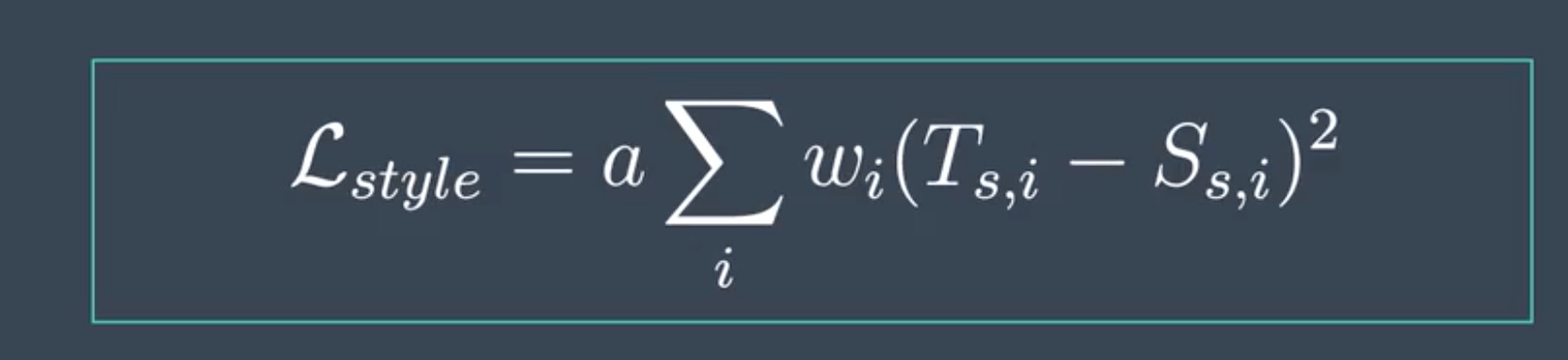 

(计算的是元素相减之后的均值)
III. How to separate the content in an image?
要点:
1. 定义了一个content loss
1. CNN不是用来传统的分类训练:网络训练的是target image。
In the VGG19, the content representation for an image is taken as the output from the fourth convolutional stack, conv four, two.
 

As we form our new target image, we'll compare it's content representation with that of our content image. These two representations should be close to the same even as our target image changes it's style. To formalize this comparison, we'll define a content loss, a loss that calculates the difference between the content and target image representations. Content loss measures how far away these two representations are from one another.
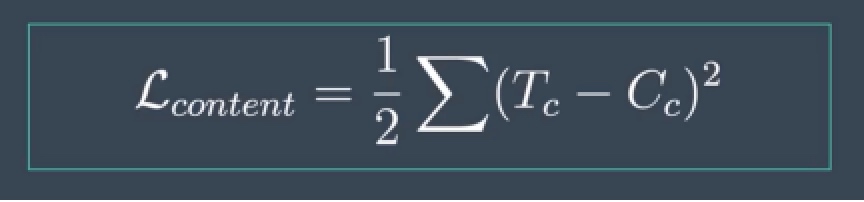 

(计算的是矩阵元素相减之后的均值)
As we try to create the best target image, our aim will be to minimize this loss. This is similar to how we used loss and optimization to determine the weights of a CNN during training. But this time, our aim is not to minimize classification error. In fact, we're not training the CNN at all. Rather, our goal is to change only the target image, updating it's appearance until the target image’s content representation matches that of our content image. So, we're not using the VGG19 network in a traditional sense: not training it to produce a specific output. But we are using it as a feature extractor, and using back propagation to minimize a defined loss function between our target and content images.
posted on 2019-02-16 16:20 bourne_lin 阅读(309) 评论(0) 编辑 收藏 举报

