数据结构(c)--哈夫曼树解码
哈夫曼树解码
题目:

哈夫曼树 图
(从网上找的一张图...)
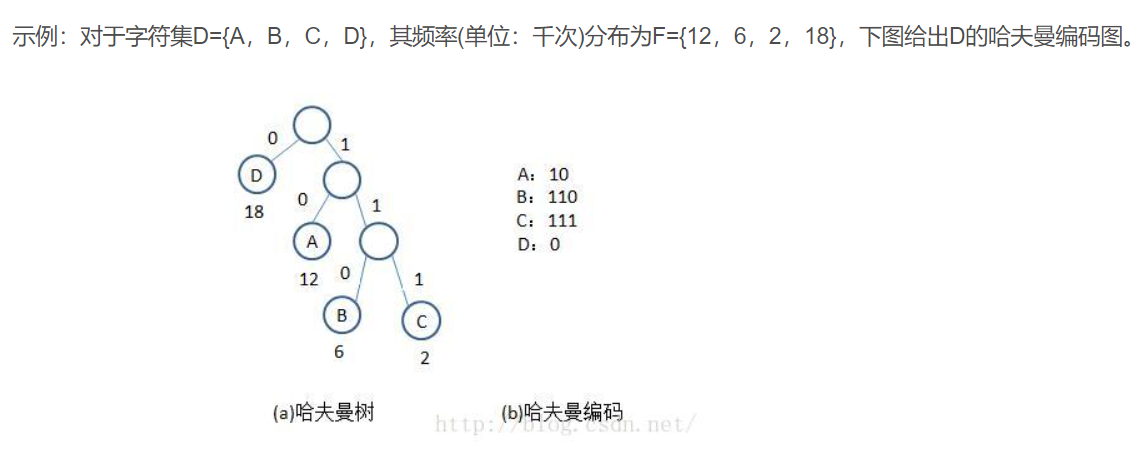
1.权重值越小的结点就在最下面 比如图中的B、C
2.图中的空结点 在我的代码中用'#'表示
完整代码
#include <stdio.h>
#define LeafCount 16
#define MaxWeight 100
typedef struct Node {
int weight;
char key;
struct Node* lChild;
struct Node* rChild;
}node;
typedef struct NodeArr {
struct Node* nodes[LeafCount];
int endIndex;
}nodeArr;
void AddNode(nodeArr*, node*);
nodeArr* InitNode(char chars[],float* weightArr) {
int len = strlen(chars);
nodeArr* arr = malloc(sizeof(nodeArr) * len);
if (arr) {
arr->endIndex = -1;
for (int i = 0; i < LeafCount; i++) {
node* tmp = malloc(sizeof(node));
if (tmp) {
tmp->key = chars[i];
tmp->weight =*(weightArr+i) * 40;
AddNode(arr,tmp);
}
}
}
return arr;
}
/// <summary>
/// 按照从大到小的顺序添加结点 最小的结点在最后 用于之后要取出
/// </summary>
/// <param name="arr"></param>
/// <param name="nod"></param>
void AddNode(nodeArr* arr,node* nod) {
node* tmp;
int i;
for (i = arr->endIndex; i >-1; i--) {
if (arr->nodes[i]->weight > nod->weight) {
break;
}
if (arr->endIndex >= LeafCount)
{
printf("添加失败,超出了索引范围");
return;
}
arr->nodes[i + 1] = arr->nodes[i];
}
arr->nodes[i + 1] = nod;
arr->endIndex += 1;
}
/// <summary>
/// 根据上面的添加 可得:权重值最小的结点在最后一个
/// </summary>
/// <param name="arr"></param>
/// <returns></returns>
node* PopMinNode(nodeArr* arr) {
return arr->nodes[arr->endIndex--];
}
/// <summary>
/// 构建哈夫曼树 取最小的两个结点 作为一个新结点的左孩子和右孩子
/// </summary>
/// <param name="arr"></param>
/// <returns></returns>
node* HuffmanTree(nodeArr* arr) {
node* newNod = malloc(sizeof(node));
while (arr->endIndex !=0) {
node* minNod = PopMinNode(arr);
node* minSecNod = PopMinNode(arr);
newNod = malloc(sizeof(node));
if (newNod) {
newNod->key = '#';//用于解码判断 当key=='#' 表示这是个不含【编码值】的结点
newNod->weight = minNod->weight + minSecNod->weight;
newNod->lChild = minNod;
newNod->rChild = minSecNod;
AddNode(arr, newNod);
}
}
return newNod;
}
void HuffmanDecode(node* root,char code[]) {
node* p = root;
int endIndex = strlen(code);
int startIndex = 0;
while (startIndex < endIndex) {
char direct=code[startIndex];
if (direct == '0') {//找左孩子 二进制编码中 0表示左孩子,1表示右孩子
p = p->lChild;
}
else {
p = p->rChild;
}
if (p->key != '#') {//不是空结点 表示是编码
printf("%c", p->key);
p = root;//继续下一个编码的匹配 重新从根节点继续解码
}
startIndex++;
}
}
int main() {
char character[] = { 'a','b','c','d','e','h','i','l','m','n','o','s','t','u','w','y'};
float weights[] = { 0.1,0.05,0.025,0.05,0.15,0.075,0.025,0.05,0.05,0.075,0.025,0.05,0.15,0.025,0.075,0.025 };
nodeArr* arr = InitNode(character, weights);
node* root=HuffmanTree(arr);
char* code = "0110000101011110011001001000010110000110011111110100110001011010001010000001011110010010111011111010010111101110001010000001111000110100101011001100000";
HuffmanDecode(root, code);
printf("\n");
system("Pause");
}
运行结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号