python实战===用python识别图片中的中文
需要安装的模块
PIL
pytesseract
需要下载的工具:
http://download.csdn.net/download/bo_mask/10196285
因为之前百度云的链接总失效,所以上传到了csdn,如果csdn没有积分的朋友可以到qq群中下载
下载解压后,安装到默认的路径下,安装完成后如下图1:
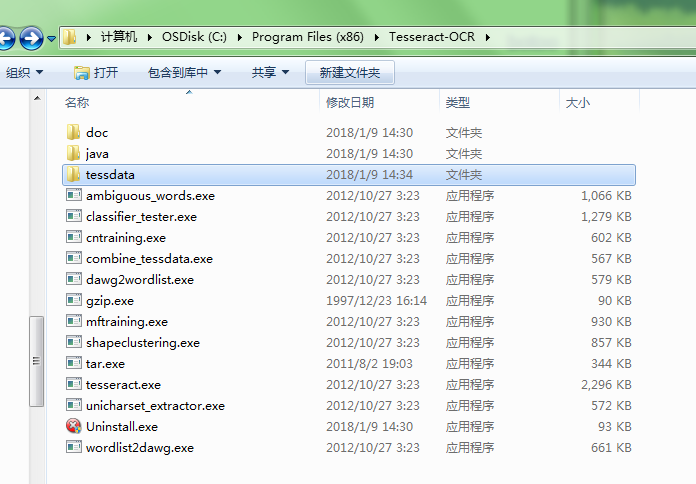
并且复制解压文件的chi_sim.traineddata 文件到安装路径 C:\Program Files (x86)\Tesseract-OCR\tessdata 下图2,图3:
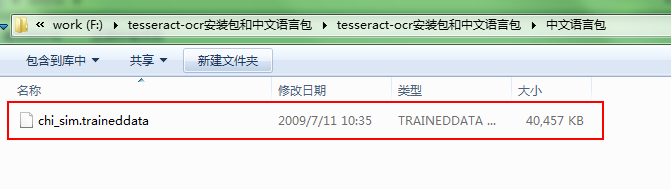
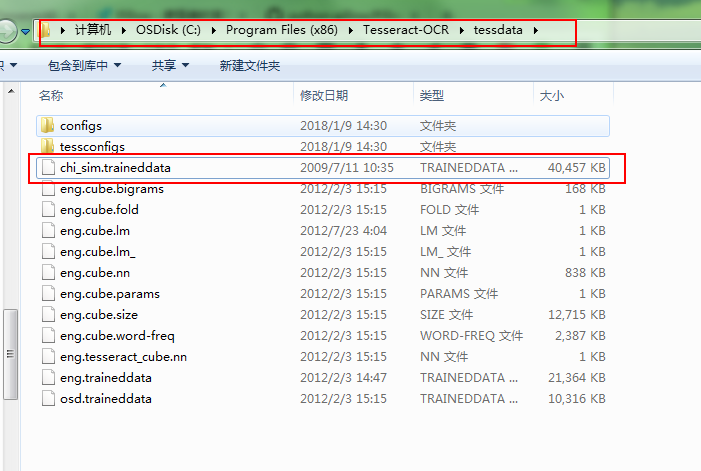
好的,如果你上面所有安装完了,那么还有最后一步,更改配置文件,位置如下图4:
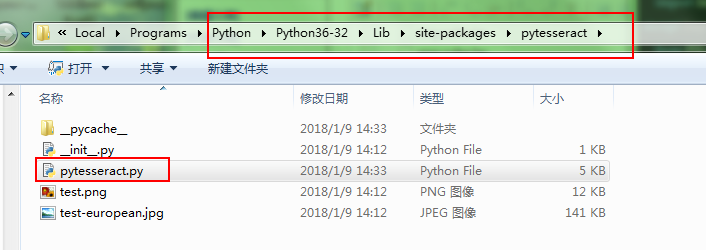
打开后将原来的注释掉,新增:
# CHANGE THIS IF TESSERACT IS NOT IN YOUR PATH, OR IS NAMED DIFFERENTLY
# tesseract_cmd = 'tesseract'
tesseract_cmd = u'C:/Program Files (x86)/Tesseract-OCR/tesseract.exe' #此路径是你安装后的路径,对应的是图1的路径
保存!环境配置结束~
如下图,保存为111.png:

#test.py
from PIL import Image
import pytesseract
text=pytesseract.image_to_string(Image.open('111.png'),lang='chi_sim')
print(text)
执行结果:

(─.─||| 。。。 。。。。
顺便提一下
如果有任何问题,你可以在这里找到我 ,软件测试交流qq群,209092584
纸上得来终觉浅,绝知此事要躬行!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号