

07 2023 档案
hadoop安装
摘要:# hadoop安装 ## 零、hadoop启动命令 ```shell start-all.sh start-dfs start-yarn hadoop-deamons.sh yarn-deamons.sh hadoop-deamon.sh yarn-deamon.sh mr-jobhistorys
阅读全文
第五章 搭建maven工程及测试
摘要:# 搭建maven工程及测试 ## 5.1 准备pom文件 ```xml 4.0.0 com.atguigu.flink flink 1.0-SNAPSHOT org.apache.flink flink-scala_2.11 1.7.0 org.apache.flink flink-streami
阅读全文
Hive分区/分桶
摘要:# 分区 hive的分区的是针对于数据库的分区,将原来的数据(有规律的数据)分为多个区域,数据和表的信息是不会有变化的,但是会增加namenode的压力 分区的目的是提升查询效率,将原来的文件进行多层次的管理 分区有三种,静态分区,动态分区,混合分区 关键字:**partitioned by(字段)
阅读全文
第三章 Flink 集群搭建
摘要:# Flink集群搭建 ```text Flink 可以选择的部署方式有: Local、Standalone(资源利用率低)、Yarn、Mesos、Docker、Kubernetes、AWS。 我们主要对 Standalone 模式和 Yarn 模式下的 Flink 集群部署进行分析。 我们对sta
阅读全文
第四章 Flink 运行架构
摘要:# Flink 运行架构 ## 4.1 Yarn 模式任务提交流程 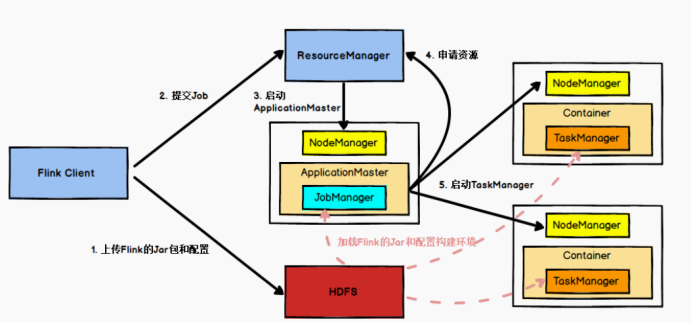 ``` text (1)Flink任
阅读全文
第二章 Flink之基本架构
摘要:# Flink基本架构 ## 2.1 JobManager 与 TaskManager Flink 运行时包含了两种类型的处理器: **JobManager 处理器**:也称之为 Master,用于协调分布式执行,它们用来调度 task,协调检查点,协调失败时恢复等。Flink 运行时至少存在一个
阅读全文
第一章 Flink之概述
摘要:# 概述 ## 1.1 流处理技术的演变 在开源世界里,Apache Storm 项目是流处理的先锋。Storm 最早由 Nathan Marz和创业公司 BackType 的一个团队开发,后来才被 Apache 基金会接纳。Storm 提供了低延迟的流处理,但是它为实时性付出了一些代价:**很难实
阅读全文
Linux下chkconfig命令详解(service)
摘要:# Linux下chkconfig命令详解(service) ## 一、释义 ```markdown chkconfig命令主要用来更新(启动或停止)和查询系统服务的运行级信息。谨记chkconfig不是立即自动禁止或激活一个服务,它只是简单的改变了符号连接。 ``` ## 二、使用语法 ```sh
阅读全文
k8s集群卸载
摘要:# k8s集群卸载 ```shell # 重置 kubeadm kubeadm reset rm -rf $HOME/kube rm -rf /etc/kubernetes/ rm -rf /etc/systemd/system/kubelet.service.d rm -rf /etc/syste
阅读全文
org.apache.spark.shuffle.FetchFailedException: The relative remote executor(Id: 21), which maintains the block data to fetch is dead.
摘要:# 问题描述 org.apache.spark.shuffle.FetchFailedException: The relative remote executor(Id: 21), which maintains the block data to fetch is dead. 最近在做Spark
阅读全文
