
第一章 Flink之概述
概述
1.1 流处理技术的演变
在开源世界里,Apache Storm 项目是流处理的先锋。Storm 最早由 Nathan Marz和创业公司 BackType 的一个团队开发,后来才被 Apache 基金会接纳。Storm 提供了低延迟的流处理,但是它为实时性付出了一些代价:很难实现高吞吐,并且其正确性没能达到通常所需的水平,换句话说,它并不能保证 exactly-once,即便是它能够保证的正确性级别,其开销也相当大。
在低延迟和高吞吐的流处理系统中维持良好的容错性是非常困难的,但是为了得到有保障的准确状态,人们想到了一种替代方法:将连续时间中的流数据分割成一系列微小的批量作业。如果分割得足够小(即所谓的微批处理作业),计算就几乎可以实现真正的流处理。因为存在延迟,所以不可能做到完全实时,但是每个简单的应用程序都可以实现仅有几秒甚至几亚秒的延迟。这就是在 Spark 批处理引擎上运行的 Spark Streaming 所使用的方法。
更重要的是,使用微批处理方法,可以实现 exactly-once 语义,从而保障状态的一致性。如果一个微批处理失败了,它可以重新运行,这比连续的流处理方法更容易。Storm Trident 是对 Storm 的延伸,它的底层流处理引擎就是基于微批处理方法来进行计算的,从而实现了 exactly-once 语义,但是在延迟性方面付出了很大的代价。
对于 Storm Trident 以及 Spark Streaming 等微批处理策略,只能根据批量作业时间的倍数进行分割,无法根据实际情况分割事件数据,并且,对于一些对延迟比较敏感的作业,往往需要开发者在写业务代码时花费大量精力来提升性能。这些灵活性和表现力方面的缺陷,使得这些微批处理策略开发速度变慢,运维成本变高。
于是,Flink 出现了,这一技术框架可以避免上述弊端,并且拥有所需的诸多功能,还能按照连续事件高效地处理数据,Flink 的部分特性如下图所示:
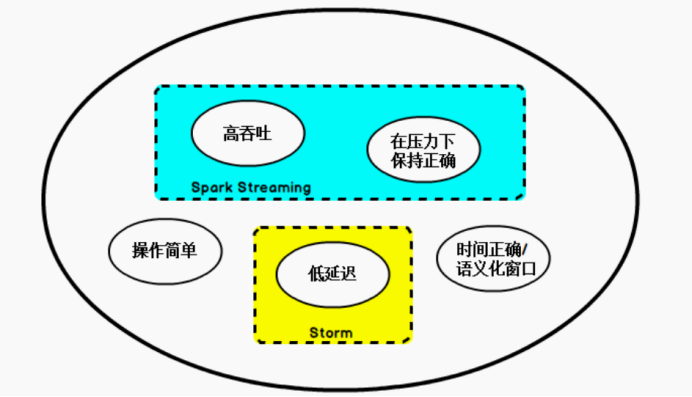
图 Flink 的部分特性
1.2 初识 Flink
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
Flink起源于Stratosphere项目,Stratosphere是在2010~2014年由3所地处柏林的大学和欧洲的一些其他的大学共同进行的研究项目,2014年4月Stratosphere 的代码被复制并捐赠给Apache软件基金会,参加这个孵化项目的初始成员是Stratosphere 系统的核心开发人员,2014年12月,Flink一跃成为Apache软件基金会的顶级项目。

在德语中,Flink 一词表示快速和灵巧,项目采用一只松鼠的彩色图案作为 logo,这不仅是因为松鼠具有快速和灵巧的特点,还因为柏林的松鼠有一种迷人的红棕色,而 Flink 的松鼠 logo 拥有可爱的尾巴,尾巴的颜色与 Apache 软件基金会的 logo 颜色相呼应,也就是说,这是一只 Apache 风格的松鼠。

图 Flink Logo
Flink 主页在其顶部展示了该项目的理念:“Apache Flink 是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架”。
Flink虽然诞生的早(2010年),但是其实是起大早赶晚集,直到2015年才开始突然爆发热度。
在Flink被apache提升为顶级项目之后,阿里实时计算团队决定在阿里内部建立一个 Flink 分支 Blink,并对 Flink 进行大量的修改和完善,让其适应阿里巴巴这种超大规模的业务场景。

年上线,服务于阿里集团内部搜索、推荐、广告和蚂蚁等大量核心实时业务。与2019年1月Blink正式开源,目前阿里70%的技术部门都有使用该版本。
Blink比起Flink的优势就是对SQL语法的更完善的支持以及执行SQL的性能提升。

1.3 Flink核心计算框架
Flink 的核心计算架构是下图中的 Flink Runtime 执行引擎,它是一个分布式系统,能够接受数据流程序并在一台或多台机器上以容错方式执行。Flink Runtime 执行引擎可以作为 YARN(Yet Another Resource Negotiator)的应用程序在集群上运行,也可以在 Mesos 集群上运行,还可以在单机上运行(这对于调试 Flink 应用程序来说非常有用)。
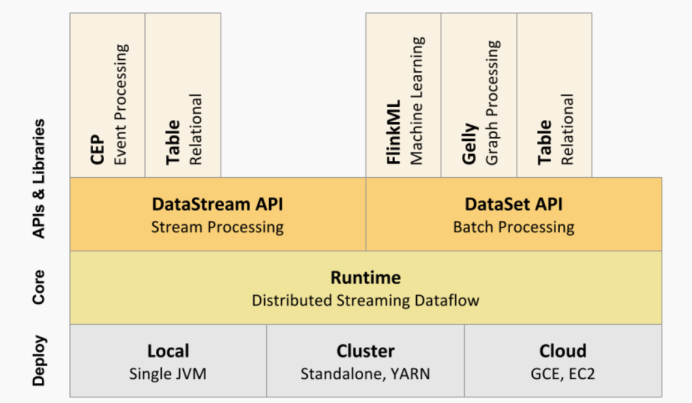
图 Flink 计算架构
上图为 Flink 技术栈的核心组成部分,值得一提的是,Flink 分别提供了面向流式处理的接口(DataStream API)和面向批处理的接口(DataSet API)。因此,Flink既可以完成流处理,也可以完成批处理。 Flink 支持的拓展库涉及机器学习(FlinkML)、复杂事件处理(CEP)、以及图计算(Gelly),还有分别针对流处理和批处理的 Table API。
能被 Flink Runtime 执行引擎接受的程序很强大,但是这样的程序有着冗长的代码,编写起来也很费力,基于这个原因,Flink 提供了封装在 Runtime 执行引擎之上的API,以帮助用户方便地生成流式计算程序 。Flink 提供了用于流处理的DataStream API 和用于批处理的 DataSet API。值得注意的是,尽管 Flink Runtime执行引擎是基于流处理的,但是 DataSet API 先于 DataStream API 被开发出来,这是因为工业界对无限流处理的需求在 Flink 诞生之初并不大。
DataStream API 可以流畅地分析无限数据流,并且可以用 Java 或者 Scala 来实现。开发人员需要基于一个叫 DataStream 的数据结构来开发,这个数据结构用于表示永不停止的分布式数据流。
Flink 的分布式特点体现在它能够在成百上千台机器上运行,它将大型的计算任务分成许多小的部分,每个机器执行一部分。Flink 能够自动地确保发生机故障或者其他错误时计算能够持续进行,或者在修复 bug 或进行版本升级后有计划地再执行一次。这种能力使得开发人员不需要担心运行失败。Flink 本质上使用容错性数据流,这使得开发人员可以分析持续生成且永远不结束的数据(即流处理)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号