【C语言篇】☞ 10. 数组、常见算法、模拟栈操作
数组
1. 概念:
一组具有相同数据类型的数据的有序集合。
数组名是一个地址(是常量),不可改变、不能赋值、不能做左值。
int a[3]; // 定义了一个名称叫做a的数组, 数组中可以存放3个int类型的数据
2. 初始化
1)int a[5]={1,2,3,4,5}; //常用
2)int a[5]={1,2,3}; //部分初始化,剩余的元素初始化为0,即{1,2,3,0,0}
3)int a[5]={[0]=1,[1]=2,[3]=4,5}; //指定初始化,即{1,2,0,4,5}
4)int a[5]={0}; //常用,初始化清零 {0,0,0,0,0}
5)int a[5]={}; //不推荐(可读性不好) {0,0,0,0,0}
6)int a[]={1,2,3,4,5}; //不推荐 省略数组的长度,可读性不好
3. 数组长度
数组的长度 = size(数组) / size(元素);
// 动态计算数组的元素个数
int a[5];
int length = sizeof(a) / sizeof(a[0]);
数组名a是空间的首地址: a == &a[0] == &a


- 问题一:为什么在函数形式参数的声明中*a与a[]是一样的?
上述两种形式都说明我们期望的实际参数是指针。在这两种情况下,对a可进行的运算是相同的。而且,可在函数体内给a本身赋予新的值。C语言要求数组名只能用作“常量指针”,但对于数组型形式参数的名字没有这一限制。
- 问题二:请问i[a]与a[i]是一样的吗?
是的,它们是一样的。对于编译器而言,i[a]等同于*(i+a),而*(i+a)也就是*(a+i),我们知道,*(a+i)等效于a[i]。虽然,i[a]与a[i]是等效的,但一般我们在编程中只使用a[i],很少使用到i[a]。
- 问题三:数组下标越界的后果是什么?
C语言中数组下标越界,编译器是不会检查出错误的,但是实际上后果可能会很严重,比如程序崩溃、程序的其他数据被改变等,所以在日常的编程中,程序员应当养成良好的编程习惯,避免这样的错误发生。
|
/** * 数组的拷贝 */ #include <stdio.h> int main() { int a[5] = {1, 2, 3, 4, 5}; int b[5]; for (int i = 0; i < 5; i++) { b[i] = a[i]; printf("%d ", b[i]); } printf("\n"); return 0; } |
二维数组
1. 概念
二维数组其实是数组的数组,可以将二维数组理解为一张几行几列的二维表。
二维数组: 数组中的每一个元素又是一个数组, 那么这个数组就称之为二维数组
元素类型 数组名称[一维数组的个数][每个一维数组的元素个数];
元素类型 数组名称[行数][列数];
//明确的告诉二维数组: 有2个一维数组,每个一维数组有3个元素
// {{1, 2, 3}, {4, 5, 6}};
int a[2][3] = {1, 2, 3, 4, 5, 6};
数组的名称就是数组的地址(首地址): &a == a == &a[0]
2. 初始化
int a[3][2]={{1,2},{3,4},{5,6}}; //对应元素内容
int b[3][2]={1,2,3,4,5,6}; //整体赋值
int c[3][2]={1,2,3,4}; //依次赋值,自动补零
注意点: 每个一维数组的元素个数不能省略!
char name[][2] = {'r', 'b', 'h', 'j'};//OK
// 搞不清楚应该分配多大的存储空间, 以及搞不清楚应该把哪些数据赋值给第一个数组, 以及哪些数据赋值给第二个数组
char name1[2][] = {'r', 'b', 'h', 'j'};//ERROR
char name2[2][2] = {'r', 'b', 'h', 'j'};//OK
return;结束当前函数!
exit(0);退出整个程序。(包含<stdlib.h>头文件)

注:数组作为函数的参数传递(是地址传递), 在函数内部修改形参的值会影响到函数外部的实参值。
常见的一些算法
选择排序、冒泡排序、折半查询(二分查找)、查表法(转进制)
三种排序算法可以总结为如下:
- 都将数组分为已排序部分和未排序部分。
- 选择排序将已排序部分定义在左端,然后选择未排序部分的最小元素和未排序部分的第一个元素交换。
- 冒泡排序将已排序部分定义在右端,在遍历未排序部分的过程执行交换,将最大元素交换到最右端。
- 插入排序将已排序部分定义在左端,将未排序部分元的第一个元素插入到已排序部分合适的位置。
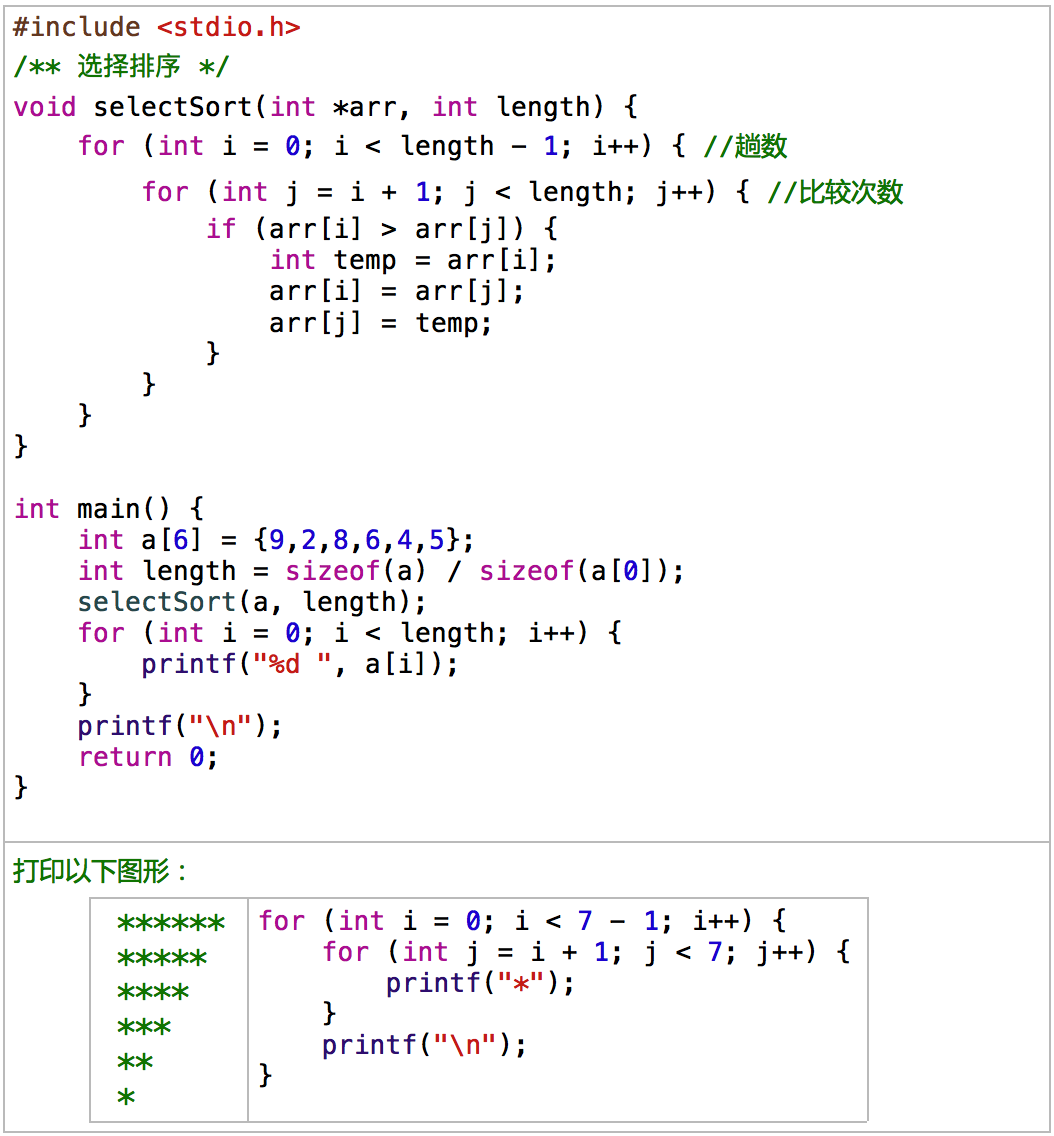
1. 选择排序
第1趟:在n个数中找到最小(大)数与第一个数交换位置
第2趟:在剩下n-1个数中找到最小(大)数与第二个数交换位置
重复这样的操作...依次与第三个、第四个...数交换位置
第n-1趟,最终可实现数据的升序(降序)排列。
选择排序的特点:最值出现在起始端
2. 冒泡排序
第1趟:依次比较相邻的两个数,不断交换(小数放前,大数放后)逐个推进,最值最后出现在第n个元素位置(两两比较n-1次)
第2趟:依次比较相邻的两个数,不断交换(小数放前,大数放后)逐个推进,最值最后出现在第n-1个元素位置(两两比较n-2次)
…… ……
第n-1趟:依次比较相邻的两个数,不断交换(小数放前,大数放后)逐个推进,最值最后出现在第2个元素位置(两两比较1次)
冒泡排序的特点:相邻元素两两比较,比较完一趟,最值出现在末尾

3. 折半查找
优化查找时间(不用遍历全部数据)
折半查找的原理:
1> 数组必须是有序的
2> 必须已知min和max(知道范围)
3> 动态计算mid的值,取出mid对应的值进行比较
4> 如果mid对应的值大于要查找的值,那么max要变小为mid-1
5> 如果mid对应的值小于要查找的值,那么min要变大为mid+1
|
/** * 已知一个有序数组, 和一个key, 要求从数组中找到key对应的索引位置 */ #include <stdio.h> #include <time.h> //法1:遍历数组逐个查找 int findKey(int *arr, int length, int key) { for (int i = 0; i < length; i++) { if (arr[i] == key) { return i; } } return -1; } //法2:折半查找 int findKey1(int *arr, int length,int key) { int min = 0, max = length - 1, mid; while (min <= max) { mid = (min + max) / 2; //计算中间值 if (key > arr[mid]) { min = mid + 1; } else if (key < arr[mid]) { max = mid - 1; } else { return mid; } } return -1; } int main() { int arr[10000] = {0, [9995] = 1, 3, 6, 10, 12}; int key = 3; int length = sizeof(arr) / sizeof(arr[0]); clock_t startTime = clock(); // int index = findKey(arr, length, key);//共消耗了27毫秒! int index = findKey1(arr, length, key); //共消耗了1毫秒! clock_t endTime = clock(); printf("共消耗了%lu毫秒!\n", endTime - startTime); printf("key对应的下标位置: %d\n", index); // 9996 return 0; } |
|
/** * 已知一个有序的数组, 要求给定一个数字, 将该数字插入到数组中, 使数组还是有序的 * 分析:其实就是找到需要插入数字的位置(min的位置) */ #include <stdio.h>
int insertValue(int *arr, int length,int key) { int min = 0, max = length - 1, mid; while (min <= max) { mid = (min + max) / 2; //计算中间值 if (key > arr[mid]) { min = mid + 1; } if (key < arr[mid]) { max = mid - 1; } } return min; } int main() { int a[5] = {1, 3, 5, 7, 9}; int key = 4; int length = sizeof(a) / sizeof(a[0]); int insertIndex = insertValue(a, length, key); printf("需要插入的位置是: %i\n", insertIndex); return 0; } |
4. 进制查表法
可以打印输出任意进制
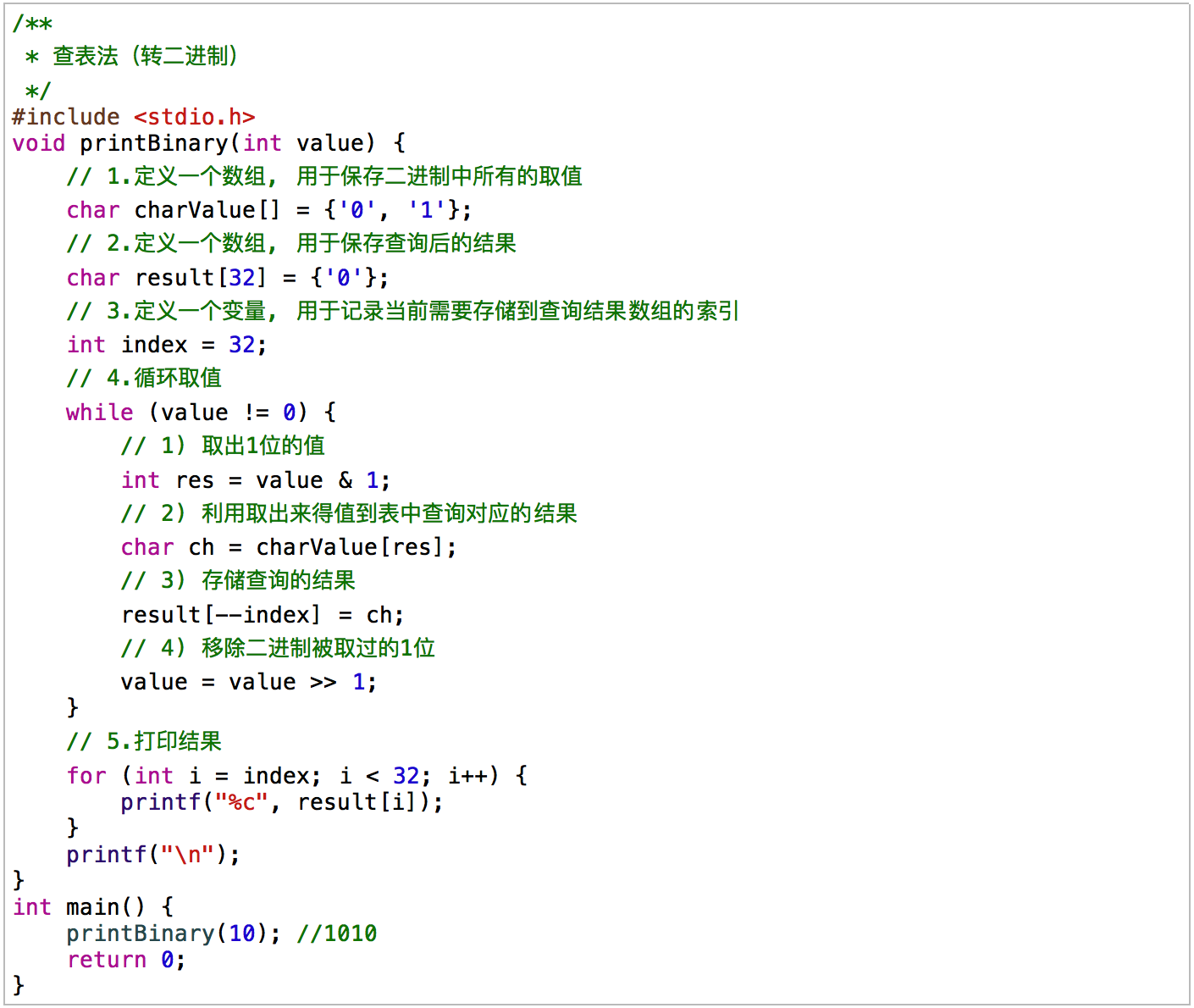


封装优化 进制查表法:
|
/** * 查表法(封装优化) */ #include <stdio.h> /** * 转换所有的进制 * value: 就是需要转换的数值 * base: 就是需要&上的数 * offset: 就是需要右移的位数 */ void total(int value, int base, int offset) { // 1.定义一个数组, 用于保存十六进制中所有的取值 char charValue[] = {'0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f'}; // 2.定义一个数组, 用于保存查询后的结果 char result[32] = {'0'}; // 3.定义一个变量, 用于记录当前需要存储到查询结果数组的索引 int index = sizeof(result) / sizeof(result[0]); // 4.循环取值 while (value != 0) { // 1) 取出1位的值 int res = value & base;// base: 1 7 15 // 2) 利用取出来得值到表中查询对应的结果 char ch = charValue[res]; // 3) 存储查询的结果 result[--index] = ch; // 4) 移除二进制被取过的1位 value = value >> offset;// offset: 1 3 4 } // 5.打印结果 for (int i = index; i < 32; i++) { printf("%c", result[i]); } printf("\n"); } /** 转二进制 */ void printBinary(int num) { total(num, 1, 1); } /** 转八进制 */ void printOct(int num) { total(num, 7, 3); } /** 转十六进制 */ void printHex(int num) { total(num, 15, 4); } int main() { printBinary(10); //1010 printOct(23); //27 printHex(1004); //3ec return 0; } |


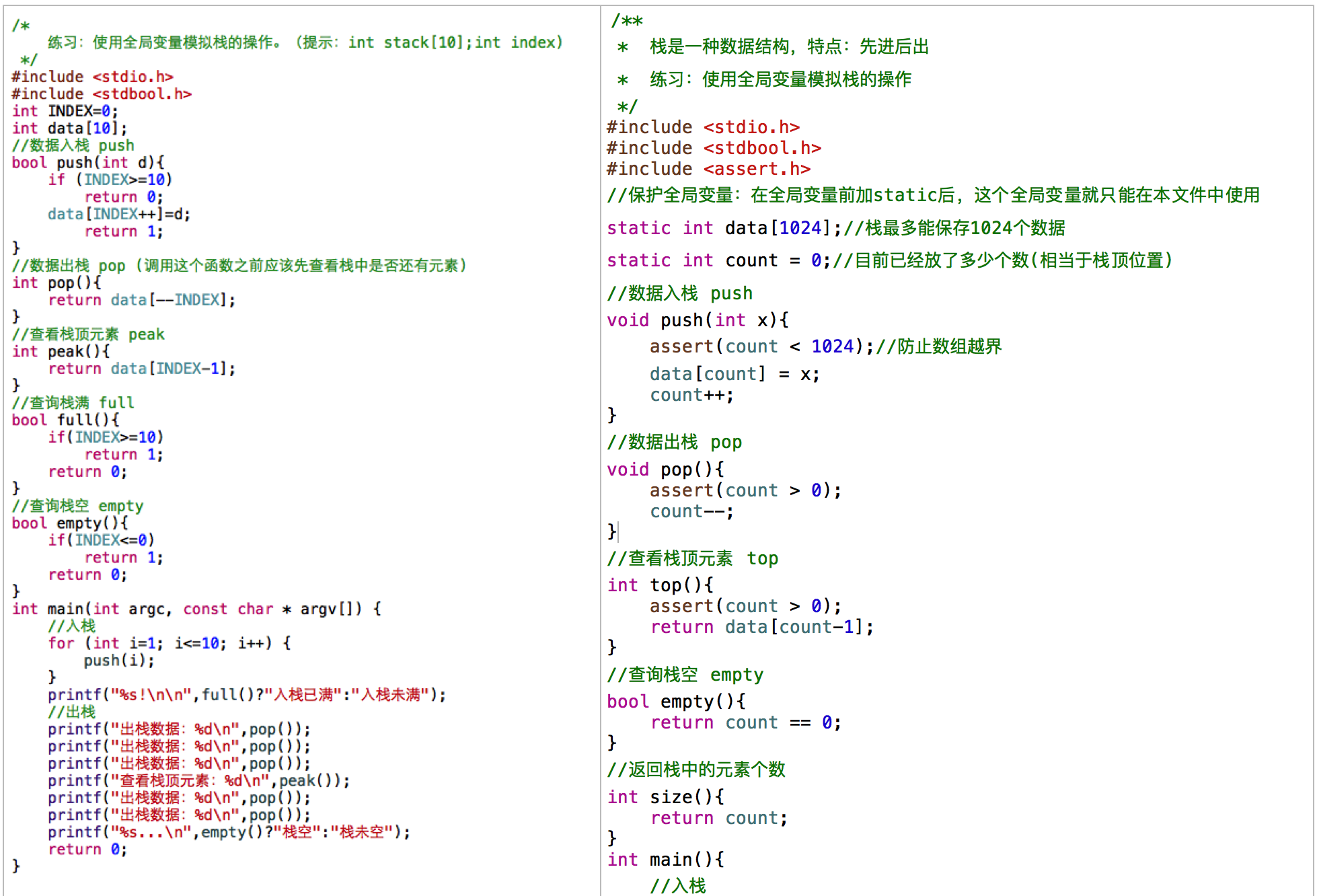
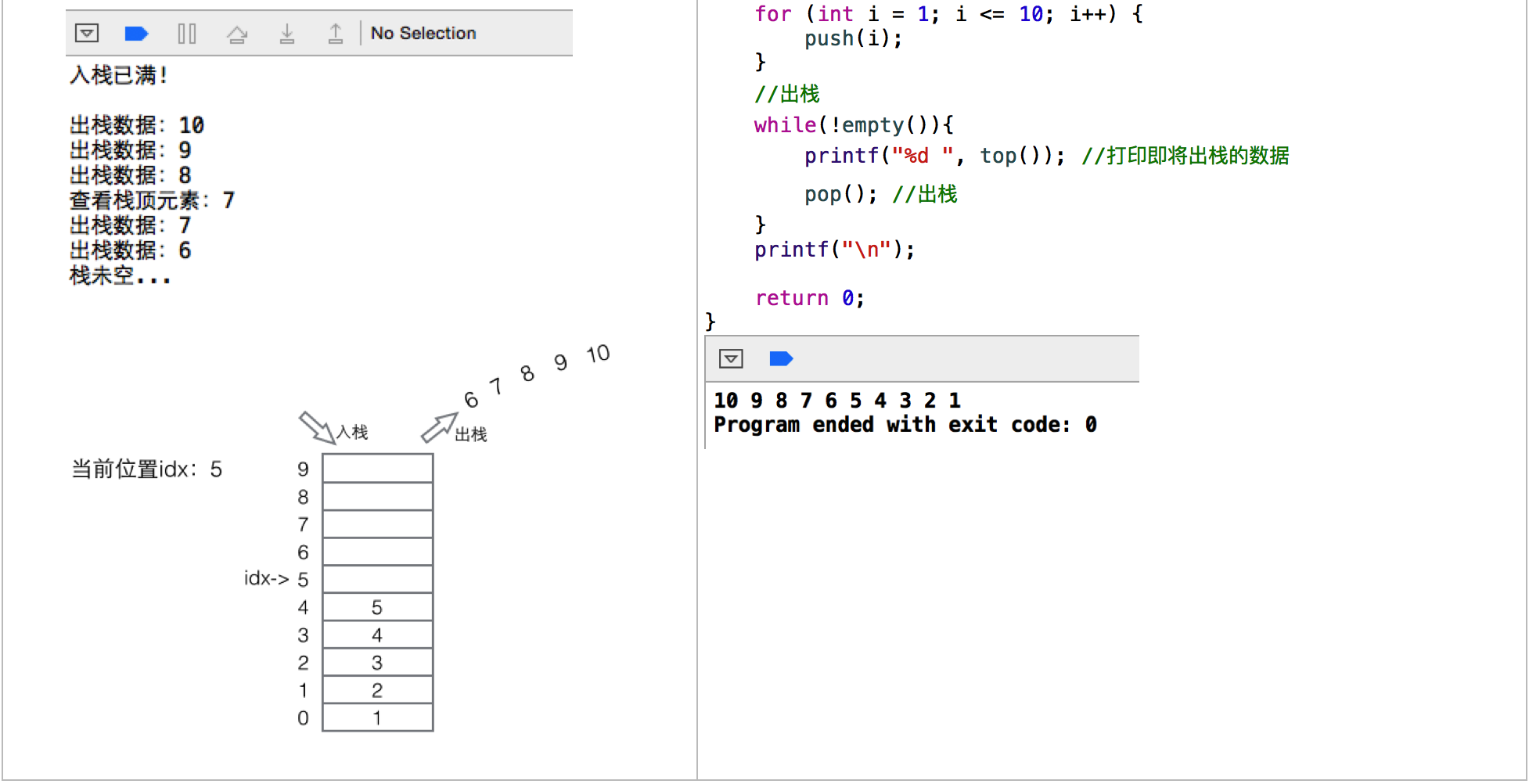
模拟栈的操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号