

Part 6.系统编程之线程--1(创建,全局变量访问,与进程对比)
(一)简介
之前我们介绍了进程,他是资源分配的基本单位,比如我们的一段代码,写完保存后是一个程序,当他运行起来,占用一定内存空间后就是一个进程,此时程序开始一行一行的执行,在这个进程里面会有线程的存在,他们各自完成自己的任务,但可以在整个进程的空间内实现资源共享,我们用如下一个实例来演示:
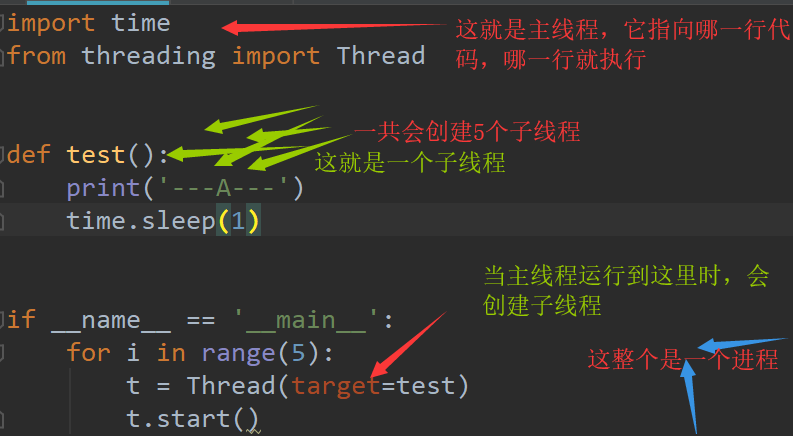
说明:
1.多个线程到同一个函数中执行,不会相互冲突,个人是个人的。
2.主线程会等待所有的子线程结束后才结束,目的就是为了给子进程收尸,收回子进程分配的资源空间等,这里就会引出两个概念,僵尸进程和孤儿进程。
- 孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
- 僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。
(二)线程的封装--类实现
为了让每个线程的封装性更完美,我们会定义一个新的子类继承threading.Thread并重写其run方法即可:
1 from threading import Thread 2 3 4 class MyThreading(Thread): 5 def run(self): 6 for i in range(3): 7 print("I'm " + self.name + ' @ ' + str(i)) 8 9 10 if __name__ == '__main__': 11 thread = MyThreading() 12 thread.start() 13 14 15 》》》输出: 16 I'm Thread-1 @ 0 17 I'm Thread-1 @ 1 18 I'm Thread-1 @ 2
(三)线程执行顺序
之前在学习进程时,有说到主进程和子进程谁先执行是由操作系统调度算法决定的,那么线程的执行顺序呢?我们先看一个如下例子:
import threading import time class MyThread(threading.Thread): def run(self): for i in range(3): time.sleep(1) msg = "I'm "+self.name+' @ '+str(i) print(msg) def test(): for i in range(5): t = MyThread() t.start() if __name__ == '__main__': test() 》》》输出: I'm Thread-1 @ 0 I'm Thread-2 @ 0 I'm Thread-5 @ 0 I'm Thread-3 @ 0 I'm Thread-4 @ 0 I'm Thread-3 @ 1 I'm Thread-4 @ 1 I'm Thread-5 @ 1 I'm Thread-1 @ 1 I'm Thread-2 @ 1 I'm Thread-4 @ 2 I'm Thread-5 @ 2 I'm Thread-2 @ 2 I'm Thread-1 @ 2 I'm Thread-3 @ 2
说明:
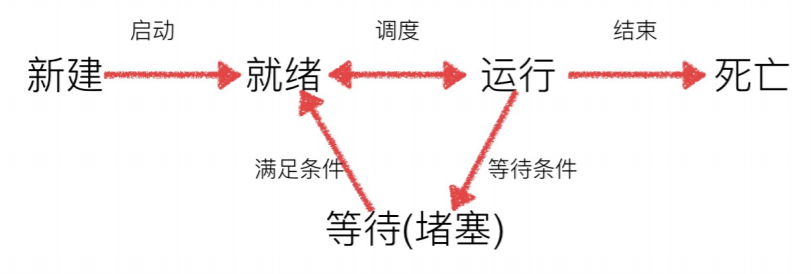
从代码和执⾏结果我们可以看出,多线程程序的执⾏顺序是不确定的。当执⾏到sleep语句时,线程将被阻塞(Blocked),到sleep结束后,线程进⼊就绪(Runnable)状态,等待调度。⽽线程调度将⾃⾏选择⼀个线程执⾏。上⾯的代码中只能保证每个线程都运⾏完整个run函数,但是线程的启动顺序、 run函数中每次循环的执⾏顺序都不能确定。
线程的几种状态:
(四)访问全局变量
对于多线程而言,全局变量是共享的,线程之间共享全局变量,而进程是隔离的。
1 from threading import Thread 2 import time 3 4 num = 100 5 6 7 def work1(): 8 global num 9 for i in range(3): 10 num += i 11 print("在work1中unm为:%d" % num) 12 13 14 def work2(): 15 global num 16 print("在work2中unm为:%d" % num) 17 18 print("创建线程之前为:%d" % num) 19 20 if __name__ == "__main__": 21 t1 = Thread(target=work1) 22 t1.start() 23 24 time.sleep(1) 25 26 t2 = Thread(target=work2) 27 t2.start() 28 29 30 》》》输出: 31 创建线程之前为:100 32 在work1中unm为:103 33 在work2中unm为:103
所以实际上原因如下:
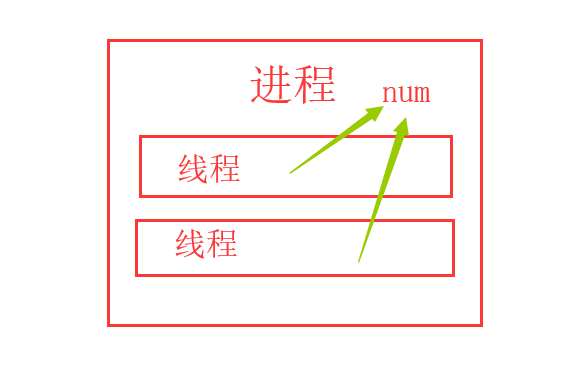
虽然共享全局变量带来了便捷,不用像进程中通信时需要设置队列,但也有问题比如线程是对全局变量随意遂改可能造成多线程之间对全局变量的混乱的问题:
from threading import Thread import time num = 100 def work1(): global num for i in range(100000): num += 1 print("在work1中unm为:%d" % num) def work2(): global num for i in range(100000): num += 1 print("在work2中unm为:%d" % num) if __name__ == "__main__": t1 = Thread(target=work1) t1.start() #time.sleep(3) 当我们把这行运行时,会出现正确结果 t2 = Thread(target=work2) t2.start() 》》》输出: 在work1中unm为:103166 在work2中unm为:128451
根据结果可说明确实存在同时竞争的交叉处,即线程1的一条语句不一定被cpu完全执行完,可能是当线程1的加1操作还没结束时,即还没有把新的值赋给num,cpu把线程1踢出去,然后把线程2的加1操作运行了(此时仍然是原num),但还没有传给num,此时cpu又把线程1提进来运行,然后更新num,然后cpu把线程2提进来更新num,但最后结果是只加了一次。所以我们需要保证不让多线程在运行上重叠,例如加上上附代码的注释行即可。
(五)进程VS线程
- 功能:
进程,能够完成多任务,⽐如在⼀台电脑上能够同时运⾏多个QQ;
线程,能够完成多任务,⽐如在⼀个QQ中的多个聊天窗⼝。
- 定义的不同:
进程是系统进⾏资源分配和调度的⼀个独⽴单位;
线程是进程的⼀个实体,是CPU调度和分派的基本单位,它是⽐进程更⼩的能独⽴运⾏的基本单位.线程⾃⼰基本上不拥有系统资源,只拥有⼀点在运⾏中必不可少的资源(如程序计数器,⼀组寄存器和栈),但是它可与同属⼀ 个进程的其他的线程共享进程所拥有的全部资源。
- 区别:
⼀个程序⾄少有⼀个进程,⼀个进程⾄少有⼀个线程;
线程的划分尺度⼩于进程(资源⽐进程少),使得多线程程序的并发性⾼;
进程在执⾏过程中拥有独⽴的内存单元,⽽多个线程共享内存,从⽽极⼤地提⾼了程序的运⾏效率;
线程不能够独⽴执⾏,必须依存在进程中。
- 优缺点:
线程和进程在使⽤上各有优缺点:线程执⾏开销⼩,但不利于资源的管理和 保护;⽽进程正相反。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号