

爬虫基本原理讲解
(一)简介
今天,我们将对爬虫的基础知识做一个基本的梳理,以便大家掌握爬虫的基本思路,爬虫即为网络资源数据获取,用一句话概括就是:
请求网站并提取数据的自动化程序
爬虫的基本流程分为四步:

在第一二步Request和Response是爬虫的获取阶段比较重要的两个概念,我们来仔细看一下:

(二)Request是什么
request包含四个部分,如下图所示:

1.首先,请求方式中Get和Post是比较常用的两种类型,我们打开百度图片网页查看后台可找到:
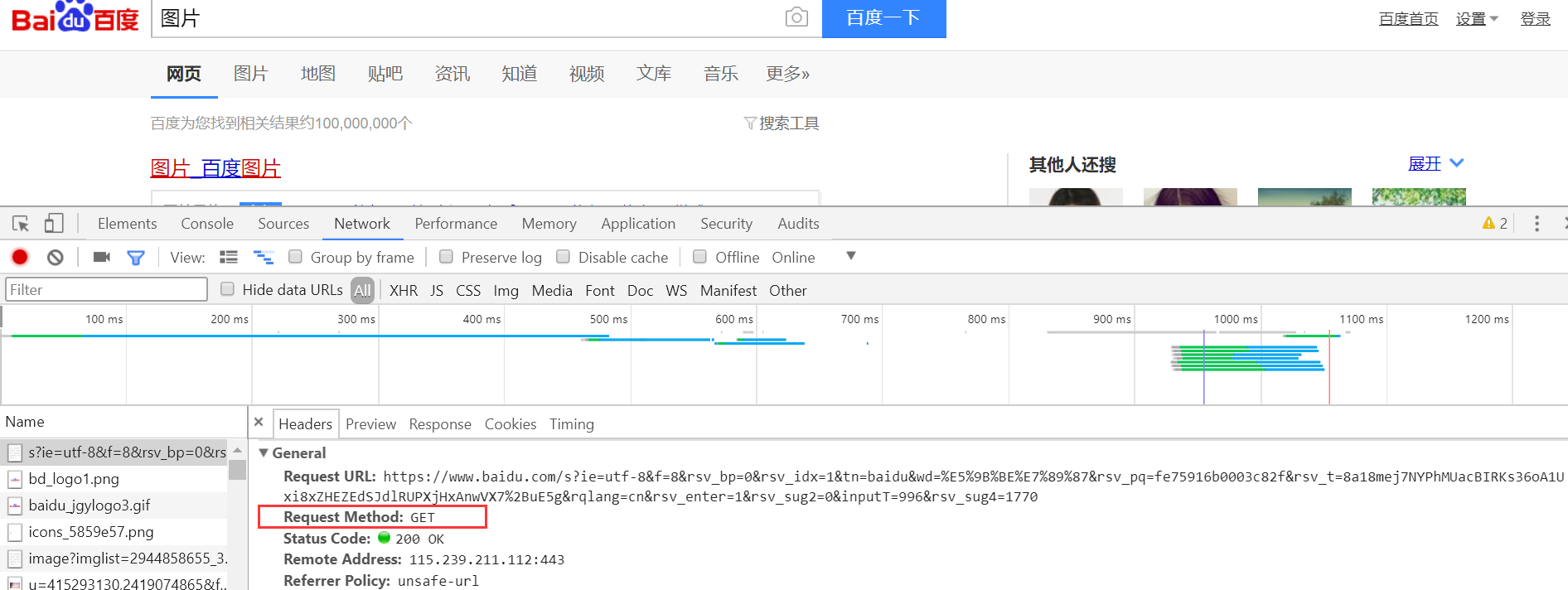
2.其次,URL是什么呢:
介于上面已经展示了全部页面,接下来我们将视野缩小:
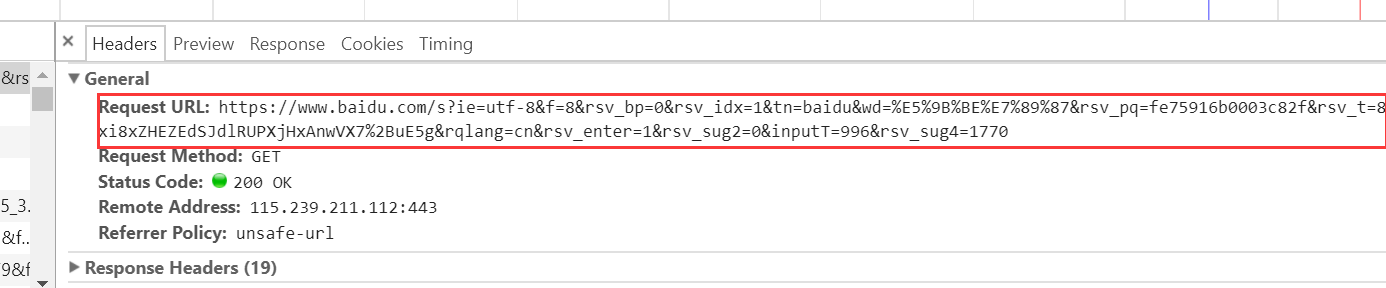
3.再接下来,请求头也就是我们所说的Headers:
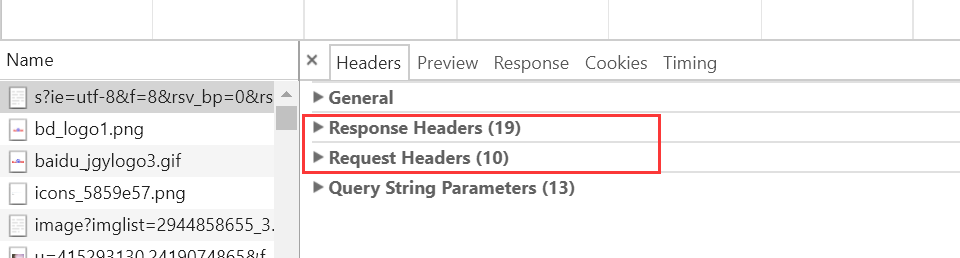
其中,所有信息以键值对的形式出现

4.请求体即是包含在其中的内容
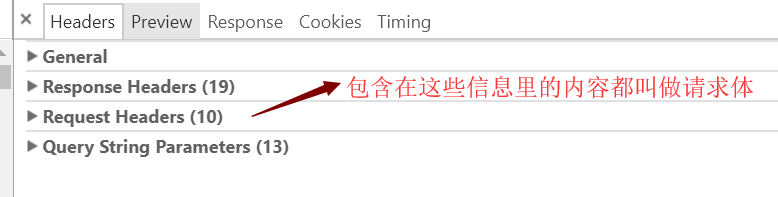
(三)Response包含什么:

这三个东西在网页后台也很好找到:
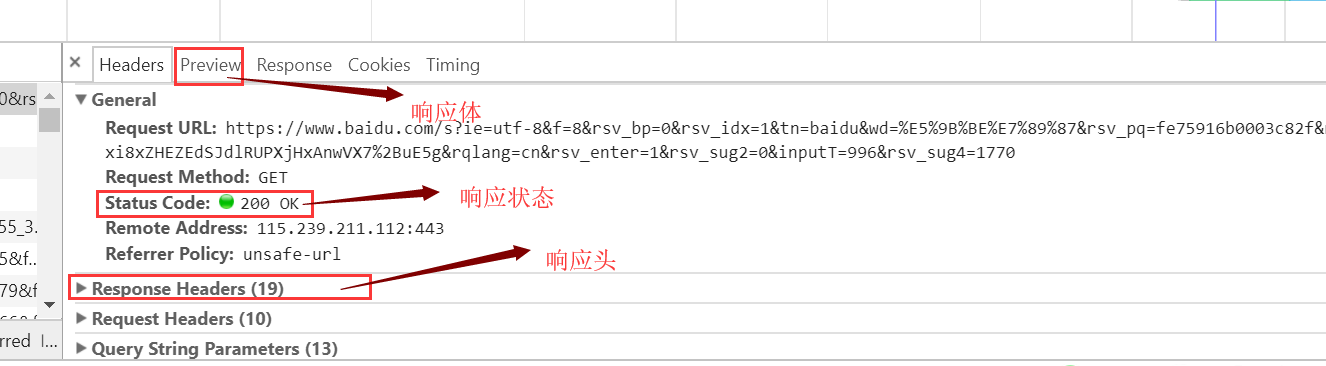
接下来,我们用一个小小的代码演示如何在py中获取这些信息:
1 import requests 2 3 response = requests.get('https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=0&rsv_idx=1&tn=baidu&wd=%E5%9B%BE%E7%89%87&rsv_pq=fe75916b0003c82f&rsv_t=8a18mej7NYPhMUacBIRKs36oA1Uxi8xZHEZEdSJdlRUPXjHxAnwVX7%2BuE5g&rqlang=cn&rsv_enter=1&rsv_sug2=0&inputT=996&rsv_sug4=1770') 4 5 print(response.text) 6 print('-----华丽的分割线-----') 7 print(response.status_code) 8 9 》》》输出: 10 <html> 11 <head> 12 <script> 13 location.replace(location.href.replace("https://","http://")); 14 </script> 15 </head> 16 <body> 17 <noscript><meta http-equiv="refresh" content="0;url=http://www.baidu.com/"></noscript> 18 </body> 19 </html> 20 -----华丽的分割线----- 21 200
那我们能抓取一些怎样的数据呢?其实只要能请求到的,我们都能获取,只是如何去再解析他而已。
像网页文本,如HTML文档,Json格式文本等;
像图片,我们获取到的是二进制文件,保存为图片格式;
像视频,同样为二进制文件,保存为视频格式即可。
那接下来的问题就是怎样来进行网页的解析:
(四)如何解析与保存
我们可以直接处理,也可以Json解析,或者正则表达式解析HTML标签,或者用一些解析库如BeautifulSoup,PyQuery,XPath。
当我们获取数据后如何保存呢,我们可以有如下几种方式保存:
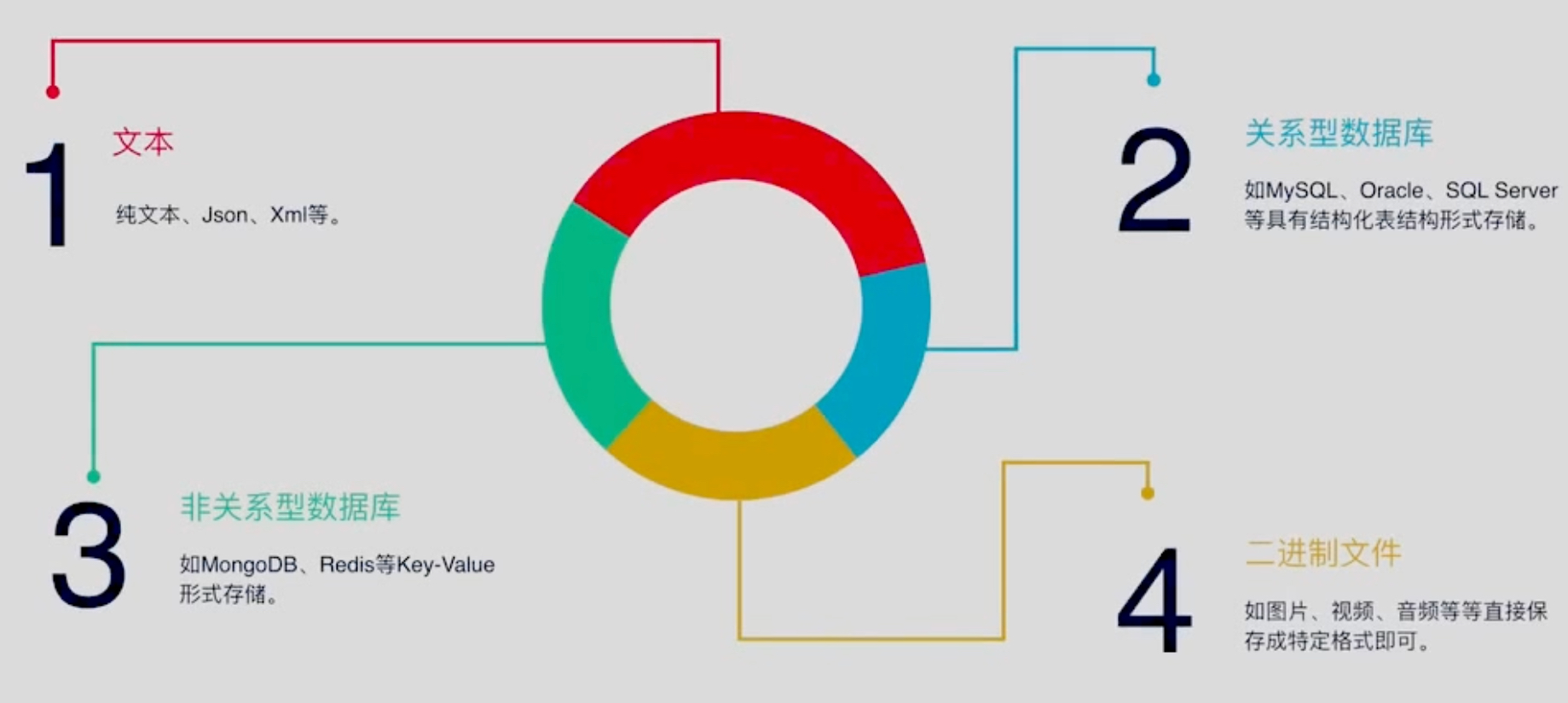
以上就是对爬虫的一个基本框架的解释,感谢阅读,后续再见!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号