22-Redis
Redis
一、简介
1. 快速了解
# 存储形式:
key: value对
# 存储位置:
内存
# 支持存储的类型:
string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)
# 支持的操作: (注意: 具有原子性, 要么同时成功, 要么同时失败回滚)
push/pop、add/remove及取交集并集和差集等
2. 深入了解
<1>. 使用Redis的好处
(1) 速度快: 因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
(2) 支持丰富数据类型: 支持string,list,set,sorted set,hash
(3) 支持事务: 操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
(4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
<2>. Redis相比memcached有哪些优势
(1) memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
(2) redis的速度比memcached快很多
(3) redis可以持久化其数据
<3>. Redis常见性问题和解决方案
(1) Master最好不要做任何持久化工作,如RDB内存快照和AOF日志文件
(2) 如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次
(3) 为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内
(4) 尽量避免在压力很大的主库上增加从库
(5) 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1 <- Slave2 <- Slave3...
这样的结构方便解决单点故障问题,实现Slave对Master的替换。如果Master挂了,可以立刻启用Slave1做Master,其他不变。
<4>. MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据
相关知识:redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。redis 提供 6种数据淘汰策略:
voltile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据
<5>. Memcache与Redis的区别都有哪些?
(1) 存储方式
Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。
Redis有部份存在硬盘上,这样能保证数据的持久性。
(2) 数据支持类型
Memcache对数据类型支持相对简单。
Redis有复杂的数据类型。
(3)value大小
redis最大可以达到1GB,而memcache只有1MB
<6>. Redis 常见的性能问题都有哪些?如何解决?
(1) Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照。
(2) Master AOF持久化,如果不重写AOF文件,这个持久化方式对性能的影响是最小的,但是AOF文件会不断增大,AOF文件过大会影响Master重启的恢复速度。Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化,如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
(3) Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
(4) Redis主从复制的性能问题,为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内
<7>. redis 最适合的场景
Redis最适合所有数据in-momory的场景,虽然Redis也提供持久化功能,但实际更多的是一个disk-backed的功能,跟传统意义上的持久化有比较大的差别,那么可能大家就会有疑问,似乎Redis更像一个加强版的Memcached,那么何时使用Memcached,何时使用Redis呢?
如果简单地比较Redis与Memcached的区别,大多数都会得到以下观点:
1 、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
2 、Redis支持数据的备份,即master-slave模式的数据备份。
3 、Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
# (1) 会话缓存(Session Cache)
最常用的一种使用Redis的情景是会话缓存(session cache)。用Redis缓存会话比其他存储(如Memcached)的优势在于:Redis提供持久化。当维护一个不是严格要求一致性的缓存时,如果用户的购物车信息全部丢失,大部分人都会不高兴的,现在,他们还会这样吗?
幸运的是,随着 Redis 这些年的改进,很容易找到怎么恰当的使用Redis来缓存会话的文档。甚至广为人知的商业平台Magento也提供Redis的插件。
# (2) 全页缓存(FPC)
除基本的会话token之外,Redis还提供很简便的FPC平台。回到一致性问题,即使重启了Redis实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似PHP本地FPC。
再次以Magento为例,Magento提供一个插件来使用Redis作为全页缓存后端。
此外,对WordPress的用户来说,Pantheon有一个非常好的插件 wp-redis,这个插件能帮助你以最快速度加载你曾浏览过的页面。
# (3) 队列
Reids在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得Redis能作为一个很好的消息队列平台来使用。Redis作为队列使用的操作,就类似于本地程序语言(如Python)对 list 的 push/pop 操作。
如果你快速的在Google中搜索“Redis queues”,你马上就能找到大量的开源项目,这些项目的目的就是利用Redis创建非常好的后端工具,以满足各种队列需求。例如,Celery有一个后台就是使用Redis作为broker,你可以从这里去查看。
# (4)排行榜/计数器
Redis在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单,Redis只是正好提供了这两种数据结构。所以,我们要从排序集合中获取到排名最靠前的10个用户–我们称之为“user_scores”,我们只需要像下面一样执行即可:
当然,这是假定你是根据你用户的分数做递增的排序。如果你想返回用户及用户的分数,你需要这样执行:
ZRANGE user_scores 0 10 WITHSCORES
Agora Games就是一个很好的例子,用Ruby实现的,它的排行榜就是使用Redis来存储数据的,你可以在这里看到。
# (5)发布/订阅
最后(但肯定不是最不重要的)是Redis的发布/订阅功能。发布/订阅的使用场景确实非常多。我已看见人们在社交网络连接中使用,还可作为基于发布/订阅的脚本触发器,甚至用Redis的发布/订阅功能来建立聊天系统!(不,这是真的,你可以去核实)。
Redis提供的所有特性中,我感觉这个是喜欢的人最少的一个,虽然它为用户提供如果此多功能。
3. 支持的数据类型(五大数据类型)
redis={
k1:'123', 字符串
k2:[1,2,3,4], 列表/数组
k3:{1,2,3,4} 集合
k4:{name:lqz,age:12} 字典/哈希表
k5:{('lqz',18),('egon',33)} 有序集合
}
二、Redis的安装
1. Linux下安装
wget http://download.redis.io/releases/redis-3.0.6.tar.gz
tar xzf redis-3.0.6.tar.gz
cd redis-3.0.6
make
启动服务器
src/redis-server
启动客户端
src/redis-cli
redis> set username jason
OK
redis> get username
jason
2. Windows下安装
三、Python操作Redis之安装
安装redis模块
pip install redis
四、Python操作Redis之普通连接
介绍: redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py
from redis import Redis
conn = Redis(host="127.0.0.1",port=6379)
conn.set('username','jason')
print(conn.get('username')) # b'jason'
五、Python操作Redis之连接池
1. 连接方式一:直接连接
import redis
pool = redis.ConnectionPool(
host='127.0.0.1',
port=6379, # 提示: 本次使用host, port可以不传值. 默认已经指定
db=1, # 指定库. 默认会有db0~db15库
decode_responses=True # 指定响应的编码是否解码. 默认不解码获取的数据是bytes类型
)
conn = redis.Redis(connection_pool=pool)
conn.set('username','jason')
print(conn.get('username')) # b'jason'
2. 连接方式二:使用类方法间接连接
'''
class Redis(object):
...
connection_pool = ConnectionPool.from_url(url, db=db, **kwargs)
return cls(connection_pool=connection_pool) # cls就是Redis类.
class ConnectionPool(object):
...
return cls(**kwargs) # cls就是ConnectionPool类
'''
from redis import Redis
conn = Redis.from_url(
# 提示: Redis类中默认调用的ConnectionPool类中的from_url类方法.
# scheme:[//[user:password@]host[:port]][/]path[?query-string][#anchor]
url='redis://127.0.0.1:6379/1', # 后面的1表示链接db1库. 下面的db=1也可以指定
# db=1,
decode_responses=True,
)
conn.set('username','jason')
print(conn.get('username')) # b'jason'
3. 单例实现连接池
<1>. 定义类方法实现连接池的单例
from redis import Redis
class SingleConnectionPool(Redis):
"""使用单例模式实现连接池"""
_POOL = None
@classmethod
def single(cls, url, db=None, **kwargs):
if not cls._POOL:
cls._POOL = cls.from_url(url, db=db, **kwargs)
return cls._POOL
conn = SingleConnectionPool.single(
url='redis://127.0.0.1:6379/1',
decode_responses=True,
)
conn1 = SingleConnectionPool.single(
url='redis://127.0.0.1:6379/1',
decode_responses=True,
)
print(conn is conn1) # True -> 单例
print(conn.get('username')) # b'jason'
<2>. 使用导入模块实现连接池的单例
# redis_conn.py
'''
from redis import Redis
conn = Redis.from_url(
url='redis://127.0.0.1:6379/1',
decode_responses=True,
max_connections=100, # 连接池中连接大小. 如果不指定默认是2**31次方最大
)
'''
from redis_conn import conn
from redis_conn import conn as conn1
print(conn is conn1) # True -> 单例
print(conn.get('username')) # b'jason'
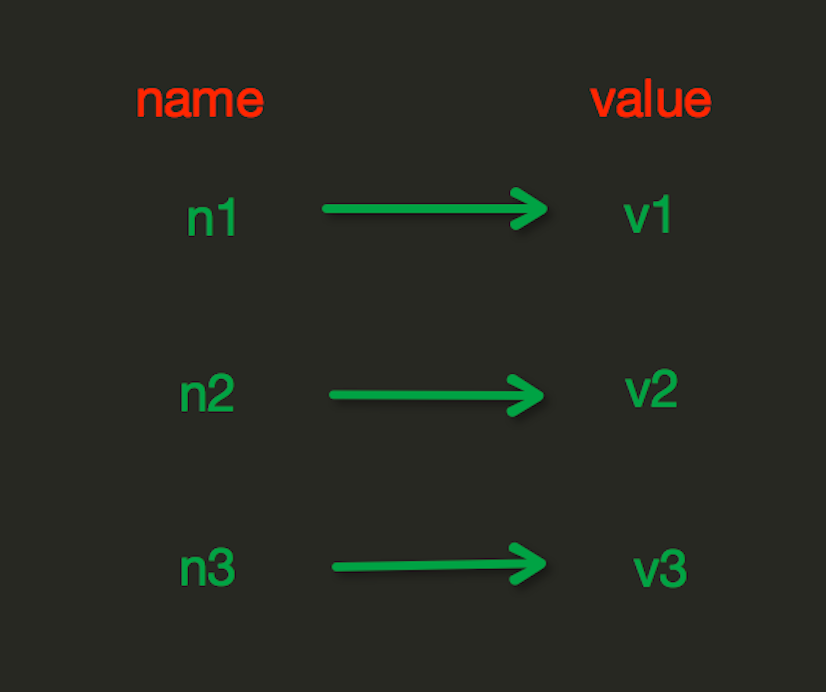
六、操作之String类型
String操作,redis中的String在在内存中按照一个name对应一个value来存储。如图:
1. 常用方法
<1>. set(self, name, value, ex=None, px=None, nx=False, xx=False, keepttl=False)
'''
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex: 过期时间(秒)
px: 过期时间(毫秒)
nx: 操作不存在的值.
nx=True时: name这个键不存在, 当前set操作生效. 否则不生效.
xx: 操作存在的值
xx=True时: name这个键存在, 当前set操作生效. 否则不生效
keepttl: 如果为真,则保留与密钥相关的生存时间。(自redis6.0开始提供)
'''
redis_obj.set('height', 180)
redis_obj.set('height', '190', ex=2)
redis_obj.set('height', '200', px=2000)
res = redis_obj.set('height', '200', nx=True) # 不存在操作
print(res) # True(值不存在) None(值存在)
res = redis_obj.set('height', '210', xx=True) # 存在操作
print(res) # True(值存在) None(值不存在)
<2>. get(self,name)
'''
使用: 通过name键获取对应的value值
name键存在: 返回对应name的value值
name键不存在: 返回None
'''
res = redis_obj.get('name')
print(res) # b'180'
res = redis_obj.get('name1')
print(res) # None
<3>. mset(self, mapping)
"""
使用: 传字典类型实现批量添加数据.
通过字典的键设置对应redis中的键.
通过字典的value值设置对应redis中的value值
"""
redis_obj.mset({'name': 'yang', 'name1': 'yang1'})
<4>. mget(self, keys, *args)
'''
使用: 通过传多个keys键获取多个键对应的value值. 返回列表
传迭代器类型:
mget(('name', 'age', 'sex'))
mget(['name', 'age', 'sex'])
不传迭代器类型:
mget('name', 'age', 'sex')
源码分析: 内部封装了如下的方法可以支持一下的三种写法
def list_or_args(keys, args):
# returns a single new list combining keys and args
try:
# 如果传的是可迭代对象: keys=(name, name1) 则会走这里
iter(keys)
if isinstance(keys, (basestring, bytes)):
keys = [keys]
else:
keys = list(keys)
except TypeError:
# 如果传的不是可迭代对象: keys=name, args=name1 则会走下面
keys = [keys]
if args:
keys.extend(args)
return keys
'''
res = redis_obj.mget('name', 'name1')
print(res) # [b'yang', b'yang1']
res = redis_obj.mget(('name', 'name1'))
print(res) # [b'yang', b'yang1']
res = redis_obj.mget(['name', 'name1'])
print(res) # [b'yang', b'yang1']
<5>. incr(self, name, amount=1)
'''
作用: 统计网站访问量,页面访问量,接口访问量
使用: 通过指定name键, 让其对应的value值, 增加 或 减少
name键存在时: 在name对应的value值之前的基础之前加上amount
name键不存在: amount作为name对应的value初始化到数据库中.
拓展: amount可以为负数
注意: name对应的value必须为整型类型, amount才能对value进行加 或者 减
'''
redis_obj.mset({'height': 180, 'width': '190'})
redis_obj.incr('height') # 存在 height: 181
redis_obj.incr('WIDTH') # 不存在 WIDTH: 1
redis_obj.incr('height', amount=10) # height: 191
redis_obj.incr('width', amount=-10) # width: 180
# 注意1: 如果不是数值类型则会抛出异常
# redis_obj.incr('name', amount=10) # redis.exceptions.ResponseError: value is not an integer or out of range
# 注意2: 如果是浮点数的形式也会抛出异常
# redis_obj.incr('height', amount=1.1) # redis.exceptions.ResponseError: value is not an integer or out of range
<6>. append(self, key, value)
'''
注意: 单个多次运行不会重复执行
使用: 通过key键在key对应的value基础之后附加新的value值
key键存在时: value附加到之前key对应value的末尾
key键不存在: value作为新的值
'''
res = redis_obj.mget('name', 'name3')
print(res) # [b'yang', None]
res = redis_obj.append('name', 'yang') # key存在时
print(res) # 8 name: yangyang
res = redis_obj.append('name3', 'yang') # key存在时
print(res) # 4 name3: yang
<7>. 总结
set: 为指定键设置值
1. ex, px: 可以控制过期事件. 秒, 毫秒
2. nx: 可以对不存在的键操作, 对存在的键不操作.
3. xx: 可以对存在的键操作, 对不存在的键不操作
get: 获取指定键值. 没有返回None
mset: 传入格式字典. 字典的key对应redis中的key. 字典的value对应redis中的value
mget: 传入1个 或 多个值, 或者传入可迭代类型. 获取传入的键批量获取对应的值. 返回列表.
incr: 传入键为其值 自增 或者 自减 指定的amount. 如果键不存在就以amount作为初始化的值.
append: 为传入的键后面的附加指定的值. 提示: 单个多次运行不会重复执行
2. 不常用方法
<1>. getrange(self, key, start, end)
'''
使用: 通过索引起始和结束位置获取key键对应value值
'''
redis_obj.set('name', 'yang', px=200)
res = redis_obj.getrange('name', 1, 3)
print(res) # b'ang'
<2>. setrange(self, name, offset, value)
'''
使用: 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)
offset: 字符串的索引,字节(一个汉字三个字节)
value: 要设置的值
'''
redis_obj.set('name', 'yang', px=200)
redis_obj.setrange('name', 1, 'A')
res = redis_obj.get('name')
print(res) # b'yAng'
<3>. setex(self, name, time, value)
'''
使用: 等同于 set(self, name, value, ex=None)
time: 传入过期时间(数字秒 或 timedelta对象
'''
redis_obj.setex('name', 3, 'yang')
<4>. setnx(self, name, value)
'''
使用: 等同于 set(self, name, value, nx=True)
nx=True时: name这个键不存在, 当前set操作生效. 否则不生效.
'''
redis_obj.setnx('name', 'yang')
<5>. psetex(self, name, time_ms, value)
'''
使用: 等同于 set(self, name, value, px=None)
time_ms: 传入过期时间(数字毫秒) 或 timedelta对象
'''
redis_obj.psetex('name', 3000, 'yang')
<6>. setbit(self, name, offset, value)
'''
使用: 对name键对应value值的二进制表示的位进行操作
offset: 位的索引(将值变换成二进制后再进行索引)
valu: 值只能是 1 或 0
如果在Redis中有一个对应: n1 = "foo",
那么字符串foo的二进制表示为:01100110 01101111 01101111
所以,如果执行 setbit('n1', 7, 1),则就会将第7位设置为1,
那么最终二进制则变成 01100111 01101111 01101111,即:"goo"
'''
redis_obj.setex('name', 1, 'foo')
redis_obj.setbit('name', 7, 1)
res = redis_obj.mget('name')
print(res) # [b'goo']
<7>. getbit(self, name, offset)
'''
使用: 获取name对应的值的二进制表示中的某位的值 (0或1)
如: 1的二进制是 00000001
'''
redis_obj.psetex('name', 20, 1)
res = redis_obj.getbit('name', 7)
print(res) # 1
<8>. bitcount(self, key, start=None, end=None)
'''
使用: 获取name对应的值的二进制表示中 1 的个数
key: Redis的name
start: 位起始位置
end: 位结束位置
'''
<9>. bitop(self, operation, dest, *keys)
'''
使用: 获取多个值,并将值做位运算,将最后的结果保存至新的name对应的值
参数:
operation,AND(并) 、 OR(或) 、 NOT(非) 、 XOR(异或)
dest: 新的Redis的name
*keys: 要查找的Redis的name
如:
bitop("AND", 'new_name', 'n1', 'n2', 'n3')
获取Redis中n1,n2,n3对应的值,然后讲所有的值做位运算(求并集),然后将结果保存 new_name 对应的值中
'''
redis_obj.mset({'name': 'yang', 'name1': 'yang1'})
redis_obj.bitop('AND', 'new_name', 'name1', 'name2')
res = redis_obj.getrange('new_name', 0, 10)
print(res) # b'\x00\x00\x00\x00\x00'
<10>. strlen(self, name)
'''
使用: 返回name对应值的字节长度(一个汉字3个字节)
'''
redis_obj.set('name', 'yang', nx=True)
res = redis_obj.strlen('name')
print(res) # 4
<11>. incrbyfloat(self, name, amount=1.0)
'''
使用: 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
参数:
name: Redis的name
amount: 自增数(浮点型)
'''
redis_obj.set('name', '99', xx=True)
redis_obj.incrbyfloat('name', amount=1.11)
redis_obj.incrbyfloat('xxxx', amount=1.11)
res = redis_obj.mget('name', 'xxxx')
print(res) # [b'100.11', b'1.11']
<12>. decr(self,name,amount=1)
'''
使用: 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。
name: Redis的name
amount: 自减数(整数)
'''
redis_obj.set('name', '100', px=1)
res = redis_obj.decr('name', amount=20)
print(res) # 80
res = redis_obj.decr('name', amount=-20)
print(res) # 100
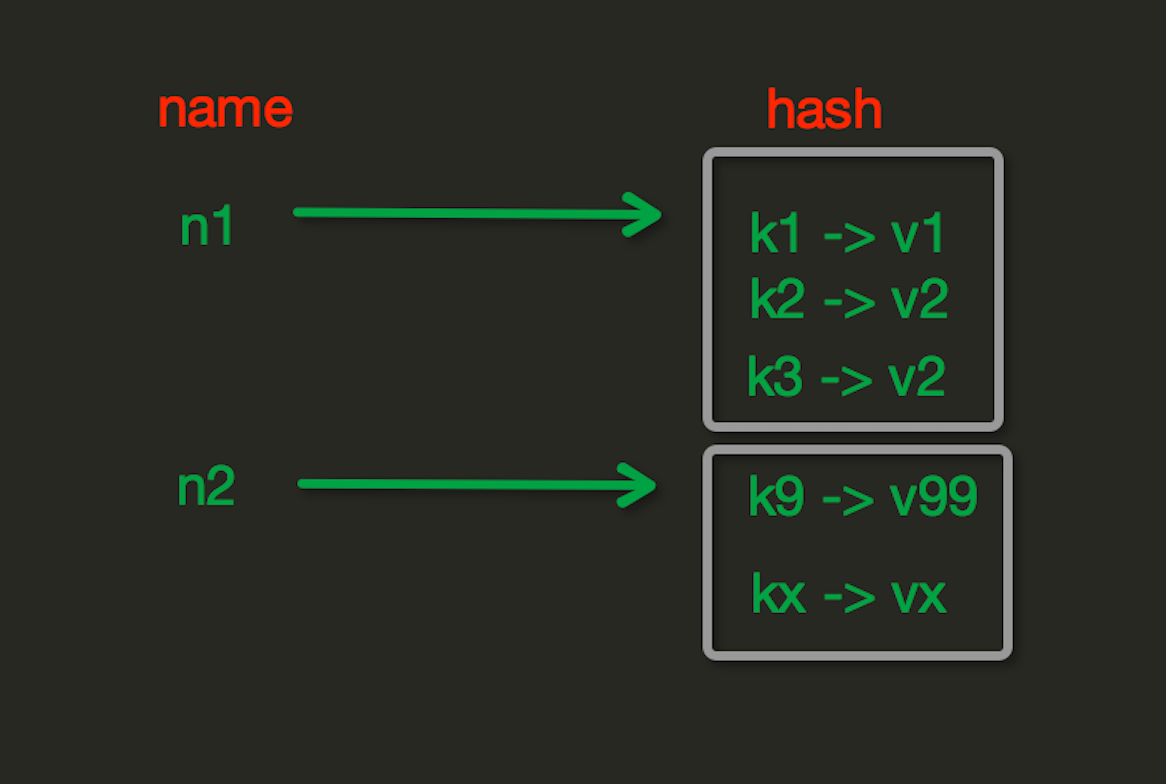
七、操作之Hash类型
Hash操作,redis中Hash在内存中的存储格式如下图:
1. 常用方法
<1>. hset(self, name, key=None, value=None, mapping=None)
'''
使用: name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
如: python中的字典结构 dic = {'key': 'value'}
其中redis中的name就对应着dic. key就对应的字典的key, value就对应的字典的value.
不同的是:redis中的name必须是唯一的.
'''
# 1. 设置单个方式一:
redis_obj.hset('info', 'name', 'yang')
# 注意: 值不能是列表. 只支持bytes, string, int, float类型
# redis_obj.hset('info', 'hobbies', ['play', 'run']) # Invalid input of type: 'list'. Convert to a bytes, string, int or float first.
redis_obj.hset('info', 'name', b'yang')
redis_obj.hset('info', 'sex', '男')
redis_obj.hset('info', 'height', 180)
redis_obj.hset('info', 'salaries', 10000.1)
# 2. 设置单个方式二: 不常用
redis_obj.hset('info', mapping={'weight': 125})
# 注意: 值不能有多个
# redis_obj.hset('info', mapping={'sex': '男', 'age': 18}) # wrong number of arguments for 'hset' command
<2>. hget(self, name, key)
'''
使用: 在name对应的hash中获取根据key获取value
'''
res = redis_obj.hget('info', 'name')
print(res) # b'yang'
res = redis_obj.hget('info', 'age')
print(res) # None
<3>. hmset(self, name, mapping)
'''
使用: 在name对应的hash中批量设置键值对
mapping: 字典. 如:{'k1':'v1', 'k2': 'v2'}.
'''
redis_obj.hmset('info', {'name': b'yang', 'age': 18, 'salaries': 18.8, 'sex': "男"})
# 注意: 传入的字典value只可以传bytes, string, int, float类型
# redis_obj.hmset('info', {'name': 'yang', 'hobbies': ['play', 'run']}) # Invalid input of type: 'list'. Convert to a bytes, string, int or float first.
<4>. hmget(self, name, keys, *args)
'''
使用: 在name对应的hash中获取多个key的值, 返回列表格式数据.
name: reids对应的name
key: 要获取key集合,如:['k1', 'k2', 'k3']
*arg: 要获取的key, 如:k1,k2,k3
提示: 内部集成了list_or_args方法. 该方法有如下作用.
不执行可迭代类型获取name中key对应的value值
指定可迭代类型获取name中key对应的value值
'''
res = redis_obj.hmget('info', 'name', 'age', 'sex')
print(res) # [b'yang', b'18', b'\xe7\x94\xb7']
res = redis_obj.hmget('info', ['name', 'age', 'sex'])
print(res) # [b'yang', b'18', b'\xe7\x94\xb7']
res = redis_obj.hmget('info', ('name', 'age', 'sex'))
print(res) # [b'yang', b'18', b'\xe7\x94\xb7']
# 提示: sex对应的value值是一个中文. 中文会有编码问题. 如果想要避免Redis类实例化时指定decode_responses=True参数
redis_obj = Redis(decode_responses=True)
res = redis_obj.hmget('info', 'name', 'age', 'sex')
print(res) # ['yang', '18', '男']
<5>. hincrby(self, name, key, amount=1)
'''
使用: 自增name对应的hash中的指定key的值,不存在则创建key=amount
name: redis中的name
key: hash对应的key
amount: 自增数(整数)
'''
# key存在
redis_obj.hincrby('info', 'age', amount=10)
res = redis_obj.hget('info', 'age')
print(res) # b'28'
redis_obj.hincrby('info', 'age', amount=-10)
res = redis_obj.hmget('info', 'age')
print(res) # [b'18']
# key不存在
redis_obj.hincrby('info', 'xxx', amount=10)
res = redis_obj.hmget('info', 'xxx')
print(res) # [b'10']
<6>. hgetall(self, name)
'''
使用: 获取name对应hash的所有键值. 返回字典格式数据.
注意: 以后想取出hash类型内所有的数据,不建议用hgetall,建议用hscan_iter
'''
res = redis_obj.hgetall('info')
print(res) # {b'name': b'yang', ... b'xxx': b'10'}
<7>. hscan(self, name, cursor=0, match=None, count=None)
'''
使用: 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆
name: redis的name
cursor: 游标(基于游标分批取获取数据)
match: 匹配指定key,默认None 表示所有的key
count: 指定每次分片最少获取个数,默认None表示获取所有.
'''
res = redis_obj.hscan('info', 0)
print(res) # (0, {b'name': b'yang',..., b'xxx': b'10'})
res = redis_obj.hscan('info', 0, match='age')
print(res) # (0, {b'age': b'18'})
res = redis_obj.hscan('info', count=3)
print(res) # (0, {b'name': b'yang',..., b'xxx': b'10'})
# 注意: name不存在返回空字典
res = redis_obj.hscan('xxx')
print(res) # (0, {})
<8>. hscan_iter(self, name, match=None, count=None)
'''
使用: 利用yield封装hscan创建生成器,实现分批去redis中获取数据
match: 匹配指定key,默认None 表示所有的key
count: 每次分片最少获取个数,默认None表示采用Redis的默认分片个数
'''
res = redis_obj.hscan_iter('info', count=10)
print(res) # <generator object Redis.hscan_iter at 0x000002294395C8E0>
for item in res:
print(item)
'''
(b'name', b'yang')
...
(b'xxx', b'10')
'''
<9>. 总结
hset: 通过指定hash名, 在hash名中以key, value键值对的方式存储数据.
注意: value值存储的范围. bytes, string, int, float.
hget: 通过指定hash名获取对应key下面的value值
hmset: 通过指定hash名, 传入一个字典实现批量增值. 字典的key就对应的redis中key, 字典的value就对应的redis中的value
注意: value值存储的范围. bytes, string, int, float.
hmget: 通过指定hash名, 通过hash名可以指定多个key值, 获取每个key对应的value值. 返回列表类型.
注意: 内部封装了list_or_args方法, 实现了如下的方式传多个key名
hmget('info', 'name', 'age)
hmget('info', ('name', 'age))
hmget('info', ['name', 'age])
hincrby: 通过指定hash名, 为hash名下的key中的value进行 自增 或者 自减
注意: 只能正对value值是整数形式
补充: 如果指定key不存在, 那么就会以amount初始化, 作为key的value值.
hscan:
hsan_inter: 内部调用hscan, 通过while循环, 批量将数据库中的数据分批次取出做成了迭代器.
2. 不常用方法
<1>. hlen(self, name)
'''
使用: 获取name对应的hash中键值对的个数
'''
res = redis_obj.hlen('info')
print(res) # 7
<2>. hkeys(self, name)
'''
使用: 获取name对应的hash中所有的key的值
'''
res = redis_obj.hkeys('info')
print(res) # [b'name', ..., b'age', b'xxx']
<3>. hvals(self, name)
'''
使用: 获取name对应的hash中所有的key的值
'''
res = redis_obj.hvals('info')
print(res) # [b'yang', ..., b'10']
<4>. hexists(self, name, key)
'''
使用: 返回一个布尔值,指示“key”是否存在于散列“name”中
'''
res = redis_obj.hexists('info', 'jjj')
print(res) # False
res = redis_obj.hexists('info', 'name')
print(res) # True
<5>. hdel(self, name, keys, *args)
'''
使用: 将name对应的hash中指定key的键值对删除
'''
res = redis_obj.hmget('info', 'xxx')
print(res) # [b'10']
res = redis_obj.hdel('info', 'xxx')
print(res) # 1
res = redis_obj.hmget('info', 'xxx')
print(res) # [None]
<6>. hincrbyfloat(self, name, key, amount=1.0)
'''
使用: 自增name对应的hash中的指定key的值,不存在则创建key=amount
name: redis中的name
key: hash对应的key
amount: 自增数(浮点数)
注意: 自增name对应的hash中的指定key的值,不存在则创建key=amount
'''
res = redis_obj.hget('info', 'salaries')
print(res) # b'38.799999999999997'
redis_obj.hincrbyfloat('info', 'salaries', amount=10.1)
# redis_obj.hincrbyfloat('info', 'salaries', amount=-10.1)
res = redis_obj.hscan('info')[-1].get(b'salaries')
print(res) # b'48.799999999999997'
# 注意: 指定的key不存在时. 使用amount初始化该值
redis_obj.hincrbyfloat('info', 'xxx', amount=-10.1)
res = redis_obj.hmget('info', 'xxx')
print(res) # [b'-10.1']
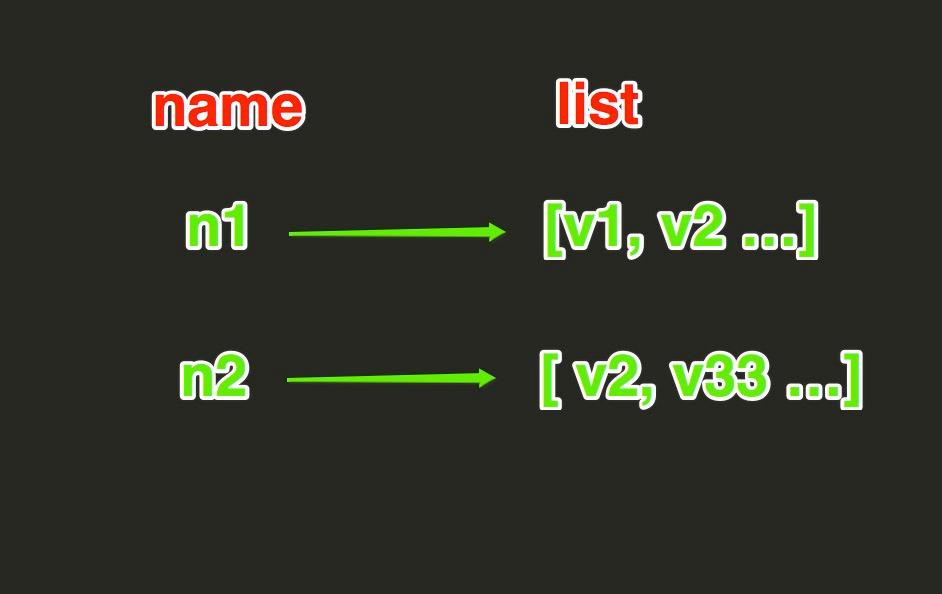
八、操作之List类型
List操作,redis中的List在在内存中按照一个name对应一个List来存储。如图:
1. 常用方法
<1>. lpush(self, name, *values) 和 rpush
'''
使用:
lpush: 将“values”推到列表“name”的顶部
rpush: 将“values”推到列表“name”的尾部
'''
# 保存顺序: 20, 19, 18
redis_obj.lpush('age', 18, 19, 20)
# 保存顺序: 18.1, 18.2, 18.3
redis_obj.rpush('salaries', 18.1, 18.2, 18.3)
<2>. lpop(self, name) 和 rpop(self, name)
'''
使用:
lpop: 删除并返回列表name的第一项
rpop: 删除并返回列表的最后一项“name”
'''
# lpop
redis_obj.rpush('age', 18, 19, 20)
res = redis_obj.lpop('age')
print(res) # 18
while True:
res = redis_obj.lpop('age')
if not res:
# 注意: 指定的键中的value被弹空了以后, 返回None
print(res) # None
break
# rpop
redis_obj.lpush('age', 18, 19, 20)
res = redis_obj.rpop('age') # 18
print(res)
<3>. blpop(self, keys, timeout=0) 和 brpop(self, keys, timeout=0)
'''
使用: 将多个列表排列,按照从左到右弹出对应列表的元素
keys: redis的name的集合
timeout: 超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
拓展: redis_obj.brpop(keys, timeout) 从右向左弹出数据.
爬虫实现简单分布式:多个url放到列表里,往里不停放URL,程序循环取值,
但是只能一台机器运行取值,可以把url放到redis中,多台机器从redis中取值,爬取数据,实现简单分布式
注意: 返回的是一个元组对象. 第一个值是键. 第二个值才是值
'''
# blpop
redis_obj.rpush('age', 18, 19, 20) # 20在前
redis_obj.lpush('age', 21, 22, 23) # 23在后
while True:
res = redis_obj.blpop('age', timeout=3)
print(res)
if not res:
# 注意: 指定key值被弹空以后, 会按照超时时间进行等待, 在时间之内还没有新的value数据, 那么该方结束. 返回None
print('再见!')
break
# 执行结果
'''
('age', '23')
('age', '22')
('age', '21')
('age', '18')
('age', '19')
('age', '20')
None
再见!
'''
# brpop
redis_obj.rpush('age', 18, 19, 20) # 20在前
redis_obj.lpush('age', 21, 22, 23) # 23在后
while True:
res = redis_obj.brpop('age', timeout=3)
print(res)
if not res:
# 注意: 指定key值被弹空以后, 会按照超时时间进行等待, 在时间之内还没有新的value数据, 那么该方结束. 返回None
print('再见!')
break
# 执行结果
'''
('age', '20')
('age', '19')
('age', '18')
('age', '21')
('age', '22')
('age', '23')
None
再见!
None
'''
<4>. lrange(self, name, start, end)
'''
使用: 在name对应的列表分片获取数据(注意: end是闭合区间)
name: redis的name
start: 索引的起始位置
end: 索引结束位置 print(re.lrange('aa',0,re.llen('aa')))
'''
redis_obj.lpush('age', 18, 19, 20)
res = redis_obj.lrange('age', 0, 1)
print(res) # ['20', '19']
<5>. llen(self, name)
'''
使用: name对应的list元素的个数
'''
res = redis_obj.llen('age')
print(res)
# 获取所有
res = redis_obj.lrange('age', 0, redis_obj.llen('age'))
print(res)
2. 不常用方法
<1>. lpushx(self, name, value) 和 rpushx(self, name, value)
'''
使用:
lpushx: 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
rpushx: 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最右边
注意:
1. 只能往key存在的列表中附加值
2. 只能附加一个值.
'''
# lpushx
'''
redis_obj.lpushx('age', 18) # 指定的键不存在时, 操作失效
res = redis_obj.lrange('age', 0, redis_obj.llen('age'))
print(res) # []
redis_obj.lpush('age', 18)
redis_obj.lpushx('age', 19) # 指定的键存在时, 操作生效
res = redis_obj.lrange('age', 0, redis_obj.llen('age'))
print(res) # ['19', '18']
'''
'''
redis_obj.rpushx('salaries', 19.1) # 指定的键不存在时, 操作失效
res = redis_obj.lrange('salaries', 0, redis_obj.llen('salaries'))
print(res) # []
redis_obj.rpush('salaries', 17.1, 18.1)
redis_obj.rpushx('salaries', 19.1) # 指定的键存在时, 操作生效
res = redis_obj.lrange('salaries', 0, redis_obj.llen('salaries'))
print(res) # ['17.1', '18.1', '19.1']
<2>. linsert(self, name, where, refvalue, value)
'''
使用: 更具传入的name键, 由指定where往前 还是 往后插入的顺序, 基于指定的refvalue值前 或者 后插入指定的value值
name: redis的name
where: BEFORE或AFTER(小写也可以)
refvalue: 标杆值,即:在它前后插入数据(如果存在多个标杆值,以找到的第一个为准)
value: 要插入的数据
提示: 如果成功返回列表的新长度,如果refvalue不在名单中。 返回-1
'''
redis_obj.rpush('age', 18, 19, 20)
print(redis_obj.lrange('age', 0, redis_obj.llen('age'))) # ['18', '19', '20']
# 往指定的refvalue前插入
new_len = redis_obj.linsert('age', 'before', '18', 1000)
print(redis_obj.lrange('age', 0, redis_obj.llen('age')), new_len) # ['1000', '18', '19', '20'] 4
# 往指定的refvalue之后插入
new_len = redis_obj.linsert('age', 'after', '1000', 9999)
print(redis_obj.lrange('age', 0, redis_obj.llen('age')), new_len) # ['1000', '9999', '18', '19', '20'] 5
# 如果refvalue不在名单中。 返回-1
res = redis_obj.linsert('age', 'before', 'xxx', 'xxxx')
print(res) # -1
<3>. lset(self, name, index, value)
'''
使用: 更具传入的name键, 由值定该键中索引的位置, 将该位置的值替换成传入的value值
name: redis的name
index: list的索引位置
value: 要设置的值
'''
redis_obj.lpush('age', 19, 18)
redis_obj.lpushx('age', 17)
print(redis_obj.lrange('age', 0, redis_obj.llen('age'))) # ['17', '18', '19']
# 对name对应的list中的某一个索引位置重新赋值
redis_obj.lset('age', 0, 9999)
print(redis_obj.lrange('age', 0, redis_obj.llen('age'))) # ['9999', '18', '19']
<4>. lrem(self, name, count, value)
'''
使用: 更具传入的name键指定删除对应value值的个数. 从前删除个数, 还是从后删除个数, 或者全删. 由count决定
count > 0: 删除等于从头到尾移动值的元素。
count < 0: 删除等于从尾部移动到头部的值的元素。
count = 0: 删除所有等于value的元素。
'''
# count > 0: 删除等于从头到尾移动值的元素。
redis_obj.rpush('age', 17, 18, 18, 19, 18)
redis_obj.rpushx('age', 19)
redis_obj.lpushx('age', 17)
print(redis_obj.lrange('age', 0, redis_obj.llen('age'))) # ['17', '17', '18', '18', '19', '18', '19']
redis_obj.lrem('age', count=2, value=18) # 删除操作
print(redis_obj.lrange('age', 0, redis_obj.llen('age'))) # ['17', '17', '19', '18', '19']
# count = 0: 删除所有等于value的元素。
redis_obj.lrem('age', count=0, value=18)
redis_obj.lrem('age', count=0, value=17)
redis_obj.lrem('age', count=0, value=19)
print(redis_obj.lrange('age', 0, redis_obj.llen('age'))) # []
# count < 0: 删除等于从尾部移动到头部的值的元素。
redis_obj.rpush('age', 17, 18, 18, 19, 18)
redis_obj.rpushx('age', 19)
redis_obj.lpushx('age', 17)
print(redis_obj.lrange('age', 0, redis_obj.llen('age'))) # ['17', '17', '18', '18', '19', '18', '19']
redis_obj.lrem('age', count=-2, value=18) # 删除操作
print(redis_obj.lrange('age', 0, redis_obj.llen('age'))) # ['17', '17', '18', '19', '19']
<5>. lindex(self, name, index)
'''
使用: 在name对应的列表中根据索引获取列表元素, 负索引将返回项名单的最后一个值.
'''
redis_obj.lpush('age', 18, 19)
print(redis_obj.lrange('age', 0, redis_obj.llen('age'))) # ['19', '18']
res = redis_obj.lindex('age', 0)
print(res) # 19
# 负索引将返回项名单的最后一个值
res = redis_obj.lindex('age', -1)
print(res) # 18
<6>. ltrim(self, name, start, end)
'''
使用: 在name对应的列表中移除没有在start-end索引之间的值
name: redis的name
start: 索引的起始位置
end: 索引结束位置(大于列表长度,则代表不移除任何)
提示: start和end可以和python中的切片符号一样可以是负数
'''
redis_obj.rpush('age', 18, 19, 20, 21)
redis_obj.rpop('age')
redis_obj.lpushx('age', 17)
print(redis_obj.lrange('age', 0, redis_obj.llen('age'))) # ['17', '19', '18', '18', '19', '20']
redis_obj.ltrim('age', 0, 2)
print(redis_obj.lrange('age', 0, redis_obj.llen('age'))) # ['17', '18', '19']
# start和end指定负数的形式
redis_obj.ltrim('age', -2, -1)
print(redis_obj.lrange('age', 0, redis_obj.llen('age'))) # ['18', '19']
<7>. rpoplpush(self, src, dst)
'''
使用: 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
src: 要取数据的列表的name
dst: 要添加数据的列表的name
'''
redis_obj.lpush('age', 18, 19, 19)
redis_obj.lrem('age', count=1, value=19)
print(redis_obj.lrange('age', 0, redis_obj.llen('age'))) # ['19', '18']
redis_obj.rpoplpush('age', 'age')
print(redis_obj.lrange('age', 0, redis_obj.llen('age'))) # ['18', '19']
<8>. brpoplpush(self, src, dst, timeout=0)
'''
使用: 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
src: 取出并要移除元素的列表对应的name
dst: 要插入元素的列表对应的name
timeout: 当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
'''
# 准备数
redis_obj.rpush('age', 18, 19)
# 有数据时
print(redis_obj.lrange('age', 0, redis_obj.llen('age'))) # ['18', '19']
redis_obj.brpoplpush('age', 'age')
print(redis_obj.lrange('age', 0, redis_obj.llen('age'))) # ['19', '18']
# 没数据时
redis_obj.lrem('age', 0, 18)
redis_obj.lrem('age', 0, 19)
print(redis_obj.lrange('age', 0, redis_obj.llen('age'))) # []
# timeout指定超时时间
res = redis_obj.brpoplpush('age', 'age', timeout=60)
print(res) # age不存在时等待了10秒打印了None
# 在别的文件中指定一下代码让阻塞时新增age键往其中插数据
res = redis_obj.rpush('age', 18, 19)
print(res)
3. 自定义增量迭代器
from redis import Redis
conn = Redis.from_url(
url='redis://127.0.0.1:6379/0',
decode_responses=True
)
# 准备数据
conn.rpush('test', *[1, 2, 3, 4, 45, 5, 6, 7, 7, 8, 43, 5, 6, 768, 89, 9, 65, 4, 23, 54, 6757, 8, 68])
def lscan_iter(name, count=10):
index = 0
while True:
data_list = conn.lrange(name, index, index + count - 1)
if not data_list:
return
# print(data_list, '\n-----')
index += count
for item in data_list:
yield item
res = lscan_iter('test')
print(res) # <generator object lscan_iter at 0x000001FF742B5410>
for value in res:
print(value)
4. 总结
lpush: 对指定的name键, 新增多个value值, 每一个值都新增到列表的左边
rpush: 对指定的name键, 新增多个value值, 每一个值都新增到列表的右边
lpop: 对指定的name键中, 从左边开始查找, 弹出指定的value值. 返回结果就可以拿到弹出的value值
rpop: 对指定的name键中, 从右边开始查找, 弹出指定的value值, 返回结果就可以拿到弹出的value值.
blpop: 对指定的name键中, 从左边开始查找, 弹出指定的value值, 如果没有那么根据指定的timeout来进行等待. 如果指定为0, 表示一直等待.
brpop: 对指定的name键中, 从右边开始查找, 弹出指定的value值, 如果没有那么根据指定的timeout来进行等待. 如果指定为0, 表示一直等待.
lrange: 对指定的name键中, 根据指定的start, end进行切片(前闭后闭), 将获取到的value值, 保存到列表中作为返回值返回.
提示: 其中切片可以同python一样可以指定负数
llen: 获取指定的name键中的value值的个数.
提示: 一般和lrange连用, 获取所有.
redis_obj.lrange('name', 0, .llen('name'))
自定义增量迭代:
def lscan_iter(name, count=10):
index = 0
while True:
data_list = conn.lrange(name, index, index + count - 1)
if not data_list:
return
index += count
for item in data_list:
yield item
九、操作之Set类型
1. 常用方法
<1>.
<2>.
<3>.
<4>. MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据
<5>.
<6>.
2. 不常用方法
<1>.
<2>.
<3>.
<4>.
<5>.
<6>.
十、其他操作
1. 准备数据
from redis import Redis
redis_obj = Redis(decode_responses=True)
# 准备数据
redis_obj.rpush('age', 18, 19, 20)
redis_obj.hmset('info', {'name': 'yang', 'age': 18})
redis_obj.set('cache_data', 'This is zcDSB!')
2. exists(self,*names)
'''
使用: 返回存在的“名称”的数量.
'''
res = redis_obj.exists('age', 'info', 'xxxx')
print(res) # 2
3. keys(self,pattern='*')
'''
使用: 返回与“模式”匹配的键列表
KEYS * 匹配数据库中所有 key 。
KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
KEYS h*llo 匹配 hllo 和 heeeeello 等。
KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
'''
# 不指定默认查找所有
res = redis_obj.keys()
print(res) # ['cache_data', 'info', 'age']
res = redis_obj.keys('*a*')
print(res) # ['cache_data', 'age']
4. delete(self, *names)
'''
使用: 删除名称中指定的一个或多个键
返回删除个数
'''
res = redis_obj.delete('age', 'cache_data')
print(res) # 2
# 删除当然库中所有(慎用)
res = redis_obj.delete(*redis_obj.keys())
print(res) # 3
5. expire(self, name, time)
'''
使用: 在键 name 上为 time 秒设置一个过期标志。
提示: 时间可以用整数或Python时间增量对象表示。
'''
import time
import datetime
redis_obj.expire('age', datetime.timedelta(seconds=3))
time.sleep(3)
res = redis_obj.exists('age')
print(res) # 0
6. rename(self,src,dst)
'''
使用: 将key“src”重命名为“dst”
'''
res = redis_obj.keys()
print(res) # ['age', 'cache_data', 'info']
redis_obj.rename('age', 'AGE')
res = redis_obj.keys()
print(res) # ['cache_data', 'info', 'AGE']
7. move(self,name,db)
'''
使用: 将键 name 移动到另一个Redis数据库 db
'''
res = redis_obj.keys()
print(res) # ['cache_data', 'info', 'age']
redis_obj.move('age', db=1)
res = redis_obj.keys()
print(res) # ['cache_data', 'info']
redis_obj = Redis(db=1, decode_responses=True)
res = redis_obj.keys()
print(res) # ['age']
8. randomkey(self)
'''
使用: 返回随机键的名称
'''
res = redis_obj.randomkey()
print(res) # age
9. type(self,name)
'''
使用: 返回键 name '的类型
'''
for name in redis_obj.keys():
res = redis_obj.type(name)
print(f'{name}: res')
# 执行结果
'''
age: res
cache_data: res
info: res
'''
十一、利用管道实现事务
from redis import Redis
redis_obj = Redis(decode_responses=True)
pipe = redis_obj.pipeline(transaction=True)
pipe.multi() # 启动事务
redis_obj.rpush('age', '18', 19)
# raise TypeError('抛出异常!')
redis_obj.rpush('age', 20)
pipe.execute() # 提交
res = redis_obj.lrange('age', 0, redis_obj.llen('age'))
print(res)
十二、Django中使用Redis
0. Django中的6种缓存方式
<1>. 开发调试(此模式为开发调试使用,实际上不执行任何操作)
settings.py配置文件
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.dummy.DummyCache', # 缓存后台使用的引擎
'TIMEOUT': 300, # 缓存超时时间(默认300秒,None表示永不过期,0表示立即过期)
'OPTIONS': {
'MAX_ENTRIES': 300, # 最大缓存记录的数量(默认300)
'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3)
},
}
}
<2>. 内存缓存(将缓存内容保存至内存区域中)
settings.py配置文件
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache', # 指定缓存使用的引擎
'LOCATION': 'unique-snowflake', # 写在内存中的变量的唯一值
'TIMEOUT': 300, # 缓存超时时间(默认为300秒,None表示永不过期)
'OPTIONS': {
'MAX_ENTRIES': 300, # 最大缓存记录的数量(默认300)
'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3)
}
}
}
<3>. 文件缓存(把缓存数据存储在文件中)
settings.py配置文件
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache', # 指定缓存使用的引擎
'LOCATION': '/var/tmp/django_cache', # 指定缓存的路径
'TIMEOUT': 300, # 缓存超时时间(默认为300秒,None表示永不过期)
'OPTIONS': {
'MAX_ENTRIES': 300, # 最大缓存记录的数量(默认300)
'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3)
}
}
}
<4>. 数据库缓存(把缓存数据存储在数据库中)
settings.py配置文件
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.db.DatabaseCache', # 指定缓存使用的引擎
'LOCATION': 'cache_table', # 数据库表
'OPTIONS': {
'MAX_ENTRIES': 300, # 最大缓存记录的数量(默认300)
'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3)
}
}
}
注意,创建缓存的数据库表使用的语句:
python manage.py createcachetable
<5>. Memcache缓存(使用python-memcached模块连接memcache)
Memcached是Django原生支持的缓存系统.要使用Memcached,需要下载Memcached的支持库python-memcached或pylibmc.
settings.py文件配置
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache', # 指定缓存使用的引擎
'LOCATION': '192.168.10.100:11211', # 指定Memcache缓存服务器的IP地址和端口
'OPTIONS': {
'MAX_ENTRIES': 300, # 最大缓存记录的数量(默认300)
'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3)
}
}
}
LOCATION也可以配置成如下:
'LOCATION': 'unix:/tmp/memcached.sock', # 指定局域网内的主机名加socket套接字为Memcache缓存服务器
'LOCATION': [ # 指定一台或多台其他主机ip地址加端口为Memcache缓存服务器
'192.168.10.100:11211',
'192.168.10.101:11211',
'192.168.10.102:11211',
]
<6>. Memcache缓存(使用pylibmc模块连接memcache)
settings.py文件配置
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.PyLibMCCache', # 指定缓存使用的引擎
'LOCATION': '192.168.10.100:11211', # 指定本机的11211端口为Memcache缓存服务器
'OPTIONS': {
'MAX_ENTRIES': 300, # 最大缓存记录的数量(默认300)
'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3)
},
}
}
LOCATION也可以配置成如下:
'LOCATION': '/tmp/memcached.sock', # 指定某个路径为缓存目录
'LOCATION': [ # 分布式缓存,在多台服务器上运行Memcached进程,程序会把多台服务器当作一个单独的缓存,而不会在每台服务器上复制缓存值
'192.168.10.100:11211',
'192.168.10.101:11211',
'192.168.10.102:11211',
]
Memcached是基于内存的缓存,数据存储在内存中.所以如果服务器死机的话,数据就会丢失,所以Memcached一般与其他缓存配合使用
1. 通用方式
utils/redis_pool.py
from redis import Redis
conn = Redis.from_url(
url='redis://127.0.0.1:6379/0',
decode_responses=True
)
使用
from utils.redis_pool import conn
telephone_key = settings.PHONE_CODE_KEY % telephone
# 设置
conn.set(telephone_key, code, ex=60 * 10)
# 获取
conn.get(telephone_key)
2. 专用方式(配置好了,直接用cache就行)
下载django-redsi模块
pip install django-redis
配置文件中配置(就是第0步的那些配置)
# redis配置: 配置了以后django中的cache的操作方法, 就会保存到redis中.
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"CONNECTION_POOL_KWARGS": {"max_connections": 100}
# "PASSWORD": "123",
}
}
}
使用
from django.core.cache import cache
telephone_key = settings.PHONE_CODE_KEY % telephone
# 设置
cache.set(telephone_key, code, 60 * 10)
# 获取
cache_code = cache.get(telephone_key)
3. 使用django-redis也可以实现redis的操作
from django_redis import get_redis_connection
conn = get_redis_connection()
conn.hmset('info',{'name':'jason','age':18})
res = conn.hgetall('info')
print(res) # {b'name':b'jason','age':b'18'}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号