

Hash( 哈希表 哈希查找 )
Hash表:
定义:
1.哈希表,也称散列表,是一种高效的数据结构。它的最大优点就是把数据存储和查找所消耗的时间
大大降低,几乎可以看成是 O(1)的,而代价是消耗比较多的内存。在当前竞赛可利用内存空间越
来越多、程序运行时间控制的越来越紧的情况下,“以空间换时间”的做法还是值得的。
tips:
1.哈希冲突,不能保证每个元素的关键字与函数值是一 一对应的,这样就产生了“冲突”。
Hash查找:
定义:
1.哈希是hash的音译,也称散列.
2. 哈希查找是一种按关键字编址的快速检索方法.
优势:
1.哈希查找是通过对记录的关键字值进行某种运算,直接求出记录的地址.
2. 快——关键字到地址直接转换,无需反复比较.
3. 核心不在于如何“比较”,而在于如何“计算”.
4. 最能体现计算机科学精髓的查找方法.
基本思想:
举个例子:
假如说我们需要将1~13存放到拥有5个区间的哈希表里,那么如果画成图就应该是这样的.(用mod对数进行取余(5)进行存放).
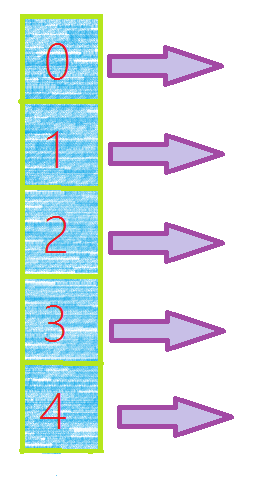
大概就是这样一个表,我们只需将1~13依次%填到相应位置就可以了。
但到了这里,同学们就会疑惑:
1~5正常%就行了,但是6%5=1,而前面1%5也=1,但是一个区间不是只能存放一个数值吗?
这就是“哈希冲突”.
这里许多人可能想到我们之前讲的——链表.
tips:
我们可以在这里创建链表,随后依次往后填写就可以了.
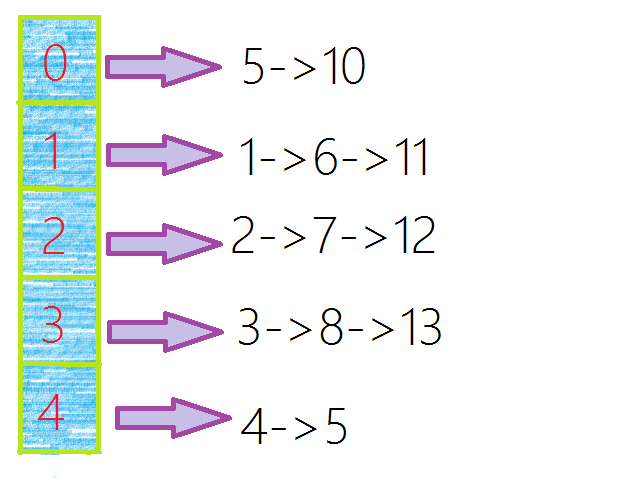
填好之后就是这样的.
hash查找代码实现:
构造:
1.哈希函数的构造 ·通常情况下,我们用除余法来构造哈希函数.
2.即选择一个适当的正整数b,用其对取模的余数作为哈希值。 ·其关键是b的选取,为了尽量避免.
冲突,一般选为能够存储下并且尽量大的素数(一般情况下我们根据空间取106左右的素数).
3.一般地说,如果b的约数越多,那么冲突.
例题:
模板题:
哈希构造的链表中查询方式比较快。已知存在一个随机的数据表(表中数字均为正整数,
没有重复),数据个数n≤50000;现在给定一些整数,查询在表中是否存在。
输入格式:
第一行,1个正整数n表示随机数字个数.
第二行,n个随机数字.
第三行,要查询的数字个数m(m≤10000) 第四行,要查询的m个数,空格隔开.
输入样例1:
10
23 45 8 9 100 12 5 2 88 21
3
34 21 7
输出样例1:
no
yes
no

#include<bits/stdc++.h> using namespace std; const int b=10000,H=10000;//哈希取模%数字. int t,a[10000],ne[10000],aus[10000]; int pop,st[10000]; void init(){ //初始化哈希表. t=0; while(pop) //我们用一个栈存储下出现过的哈希值. a[st[pop--]]=0; } void insert(int key){ //将一个数字插入哈希表. int h=key%b; //除余法. for(int e=a[h];e;e=ne[e]) if(aus[e]==key) return; //诺链表中已存在当前数字则不再存. if(!a[h]) st[++pop]=h; //把第1次出现的哈希值入栈. ne[++t]=a[h],a[h]=t; //建立链表. aus[t]=key; //建立链接表,存储值等于key的数字. } bool query(int key){//数组模拟链表. int h=key%b; for(int e=a[h];e;e=ne[e]) //查询链接. if(aus[e]==key) return true; return false; } int main(){ int a[10000]; init();//初始化. int n,m; cin>>n; for(int i=1;i<=n;++i) { cin>>a[i]; insert(a[i]); } cin>>m; int num; for(int i=1;i<=m;++i){ cin>>num; if(query(num)) printf("yes\n"); else printf("no\n"); } }
字符串hash:
给出一个长度为n的字符串,进行m次询问,每次询问字符串的序列[a,b]和序列[c,d]是否相等 .
输入格式:
第一行1个整数n,为字符串长度.
第二行1个长度为n的字符串.
第三行1个整数m 接下来m行,每行4个以空格分隔的整数a,b,c,d.
输出格式: 对于每个询问,输出一行答案 yes或no.
数据范围:1e4< n,m ≤1e6.
输入样例:
7
asasaaa
4
1 2 3 4
1 2 2 3
1 5 3 7
1 1 7 7
输出样例:
yes
no
no
yes
#include<iostream> #include<algorithm> #include<cstring> using namespace std; const int N=1e3+5,MD=1000000007,D=27; string s; int f[N],g[N]; // f 为前缀和,g[i] 为 D 的 i 次方 void prehash(int n){ f[0] =0; // f 前缀和预处理 for(int i=1;i<=n;i++) f[i]=(1LL*f[i-1]*D+s[i-1])%MD; g[0]=1; for(int i=1;i<=n;i++) g[i]=1LL*g[i-1]*D%MD; } int hash1(int l, int r){ int a=f[r]; int b=1LL*f[l-1]*g[r-l+1]%MD; return (a - b + MD) % MD; // 前缀和相减 } int main(){ int n; cin>>n>>s; prehash(n); //预处理hash表 int m; cin>>m; int a,b,c,d; for(int i=1;i<=m;++i){//进行数字判断 cin>>a>>b>>c>>d; if(hash1(a,b)==hash1(c,d)) printf("yes\n"); else printf("no\n"); } return 0; }
再见!!!
Hash Hash Hash Hash Hash Hash Hash Hash Hash Hash Hash Hash Hash Hash Hash Hash Hash Hash Hash Hash Hash Hash Hash Hash


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现