第4周小组作业:WordCount优化
项目地址:https://github.com/chaseMengdi/wcPro
stage1:代码编写+单元测试
PSP表格
| PSP2.1 | PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 25 | 30 |
| Estimate | 估计任务需要多少时间 | 25 | 30 |
| Development | 开发 | 270 | 275 |
| Analysis | 需求分析 | 20 | 20 |
| Design Spec | 生成设计文档 | 20 | 15 |
| Design Review | 设计复审 | 20 | 15 |
| Coding Standard | 代码规范 | 20 | 15 |
| Design | 具体设计 | 20 | 25 |
| Coding | 具体编码 | 90 | 80 |
| Code Review | 代码复审 | 20 | 30 |
| Test | 测试 | 60 | 80 |
| Reporting | 报告 | 80 | 95 |
| Test Report | 测试报告 | 30 | 50 |
| Size Measurement | 计算工作量 | 30 | 25 |
| Postmortem | 总结 | 20 | 20 |
| 合计 | 375 | 400 |
接口设计
public static ArrayList<String> sort(HashMap<String, Integer> map)
统计后的单词和词频进行排序
public static void show()
打开图形界面
接口实现
sort()函数传入的是一个HashMap,key是单词,value是该单词出现的次数。先利用TreeMap对key排序(原理就是红黑二叉树算法),然后将HashMap转化成ArrayList,再按value创建比较器来实现value降序排列。排列后的Map存放的结果符合项目要求。
因为个人技术水平所限,无法对Map.Entry<String, Integer>进行初始化进而编写单元测试,所以小组讨论后将sort()返回值修改成了ArrayList<String>,单词和词频依次存放。
// 词频排序 public static ArrayList<String> sort(HashMap<String, Integer> map) { // 以Key进行排序 TreeMap treemap = new TreeMap(map); // 以value进行排序 ArrayList<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>( treemap.entrySet()); Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() { public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { // 降序 return o2.getValue() - o1.getValue(); // 升序 o1.getValue() - o2.getValue()) } }); ArrayList<String> str = new ArrayList<String>(); int i = 0; for (Map.Entry<String, Integer> string : list) { // 排除-与空格 if (!(string.getKey().equals("")) && !(string.getKey().equals("-"))) { str.add(string.getKey()); str.add(string.getValue().toString()); // 输出前100个单词 if (i > 100) break; i++; } } return str; }
show函数主要思想就是利用JFileChooser类打开窗口选择文件,随后将文件类型限制为txt类型,之后将选择的文件路径传入main()函数进行操作。
// 图形界面 public static String show() { // 默认的打开路径为“我的文档” JFileChooser fcDlg = new JFileChooser(new File( System.getProperty("user.dir"))); // 设置默认目录为得到工程的路径 fcDlg.setDialogTitle("请选择文件"); FileNameExtensionFilter filter = new FileNameExtensionFilter( "文本文件(*.txt)", "txt"); fcDlg.setFileFilter(filter); int returnVal = fcDlg.showOpenDialog(null); if (returnVal == JFileChooser.APPROVE_OPTION) { String[] filepath = new String[1]; filepath[0] = fcDlg.getSelectedFile().getPath(); main(filepath); return "图形界面打开成功\n"; } else { return "图形界面打开失败\n"; } }
测试设计
sort()函数的测试设计应以黑盒设计为主,白盒设计为辅,首先创建并初始化一个HashMap,随后传入sort()函数,将实际输出与期望输出利用断言进行对比。由于HashMap的特殊性,元素的实际位置与传入顺序并无关联,所以主要测试多种顺序和高词频的输入是否可以得到正确的结果。从最开始单词种类和词频量都比较小,顺序也较简单,随后逐渐加大数据量和复杂程度。
show()函数的话,我目前只想到了肉眼观察,再加上为show()函数设置返回值,利用断言进行比较。
21个测试用例设计如下:
|
Test Case ID 测试用例编号 |
Test Item 测试项(即功能模块或函数) |
Test Case Title 测试用例标题 |
Test Criticality 重要级别 |
Pre-condition 预置条件 |
Input 输入 |
Procedure 操作步骤 |
Output 预期结果 |
Result 实际结果 |
Status 是否通过 |
Remark 备注 |
| sort_01 | 词频排序 |
种类<=5 词频<=10 升序 |
L |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_02 | 词频排序 |
种类<=5 词频<=10 升序 |
L |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_03 | 词频排序 |
种类<=5 词频<=10 降序 |
L |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_04 | 词频排序 |
种类<=5 词频<=10 降序 |
L |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_05 | 词频排序 |
种类<=5 词频<=10 降序 |
L |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_06 | 词频排序 |
种类>=6 词频不定 升序 |
M |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_07 | 词频排序 |
种类>=6 词频不定 升序 |
M |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_08 | 词频排序 |
种类>=6 词频不定 升序 |
M |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_09 | 词频排序 |
种类>=6 词频不定 降序 |
M |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_10 | 词频排序 |
种类>=6 词频不定 降序 |
M |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_11 | 词频排序 |
种类<=5 词频<=10 乱序 |
M |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_12 | 词频排序 |
种类<=5 词频<=10 乱序 |
M |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_13 | 词频排序 |
种类<=5 词频<=10 乱序 |
M |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_14 | 词频排序 |
种类<=5 词频<=10 乱序 |
M |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_15 | 词频排序 |
种类<=5 词频<=10 乱序 |
M |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_16 | 词频排序 |
种类>=6 词频不定 乱序 |
H |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_17 | 词频排序 |
种类>=6 词频不定 乱序 |
H |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_18 | 词频排序 |
种类>=6 词频不定 乱序 |
H |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_19 | 词频排序 |
种类>=6 词频不定 乱序 |
H |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| sort_20 | 词频排序 |
种类>=6 词频不定 乱序 |
H |
单词与词频 统计完成 |
HashMap | 无 | 单词与词频降序 | 单词与词频降序 | OK | 黑盒测试 |
| show_21 | 图形界面 | 图形界面测试 | M | 输入参数为-x | -x | 选取txt文件 | 返回成功结果 | 返回成功结果 | OK | 白盒测试 |
测试结果
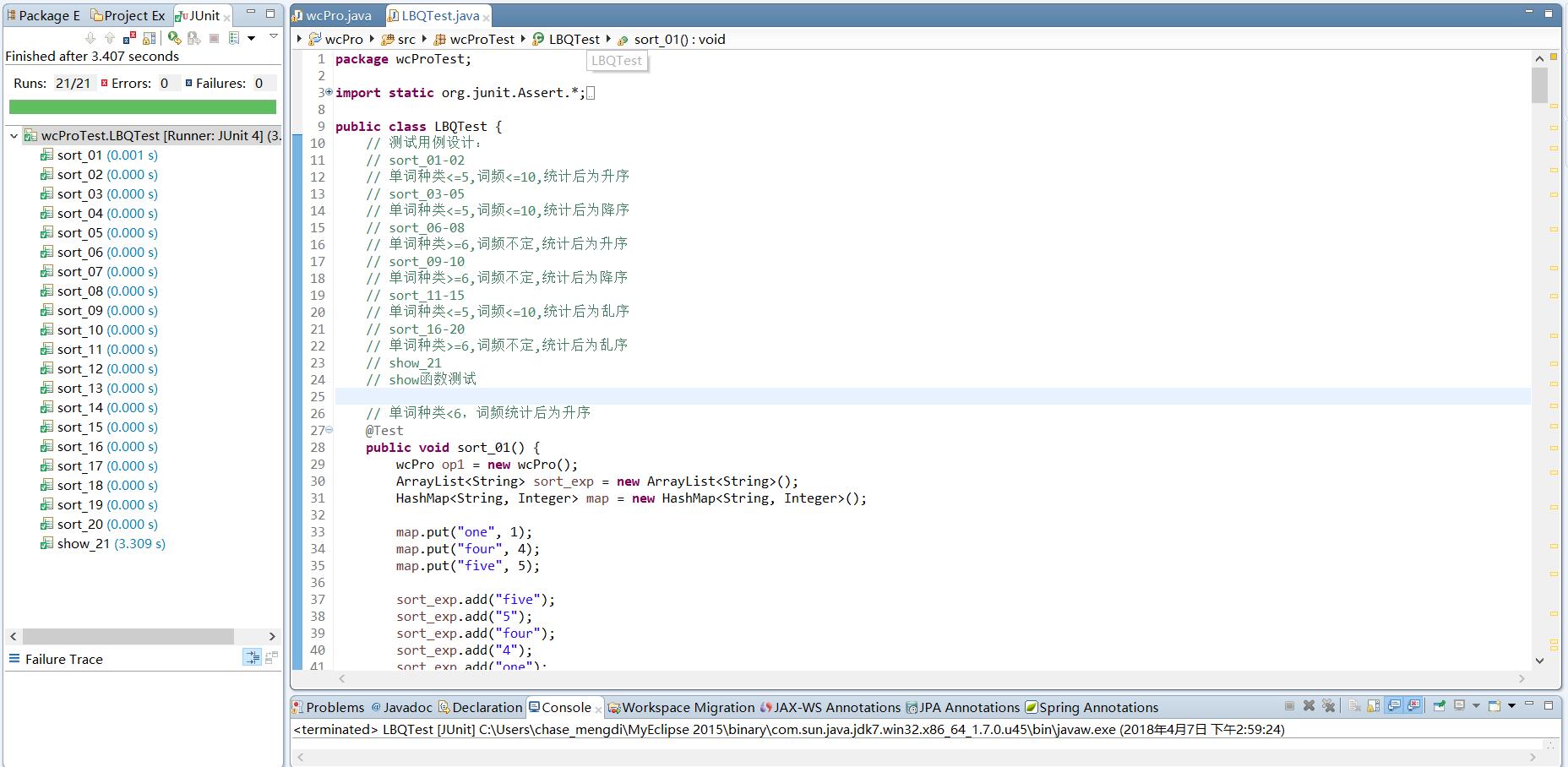
测试评价
sort()和show()的所有单元测试均通过,sort()函数质量水平较高,可以正常处理单词和词频的排序工作。
由于show()函数的单元测试数量和复杂度均不够,所以无法做出有效评价。
小组贡献
我负责的是图形化界面和单词词频排序,排序这部分是关乎性能质量的重要部分,所以比较重要。
刚开始只想做一个简单的快速排序,查阅了一些资料,再三考虑之后,还是换成了二叉树排序,这样即使数据量很大,程序也可以以稳定的状态运行,不至于崩溃。
我个人的代码行数只占了0.28,但我觉得应该还是完成的挺不错的,如果满分是5分,我给自己打4分。
stage2:静态测试
开发规范理解
《阿里巴巴Java开发手册》中指出:
4. 【强制】方法名、参数名、成员变量、局部变量都统一使用lowerCamelCase风格,必须遵从驼峰形式。 正例: localValue / getHttpMessage() / inputUserId
其实我自己平时写代码挺喜欢这么写的,因为看着舒服,更重要的是,这样的方法参数容易让人读懂,同行评审或者测试代码的时候,不需要阅读过多的前后文代码即可明白方法变量的意思。
至于应用,本次作业的wcPro.java中:public static ArrayList<String> sort(HashMap<String, Integer> map) 和public static void show()这两个方法里面的变量和参数部分都是这么命名的,有的地方做的还是不够规范,只是简单的使用了单词缩写,不符合“驼峰形式”的要求,需要继续改进。
组员代码评价
选择组员侯岱(17083)的代码进行分析
// 控制输出 public static String print(ArrayList<String> str) { String message = ""; int i = 0; try { // 打开一个写文件器,构造函数中的第二个参数true表示以追加形式写文件 FileWriter writer = new FileWriter("result.txt", true); for (i = 0; i < str.size() - 1; i++) { writer.write((str.get(i) + " " + str.get(i + 1) + "\r\n") .toCharArray()); message += (str.get(i) + " " + str.get(i + 1) + "\r\n"); // 输出前100个单词 if (i > 100) break; i++; } writer.write(("-------------------\r\n").toCharArray()); writer.close(); } catch (IOException e) { System.out.print("文件读写错误" + e + "\n"); } return message; }
侯岱的代码完全没有遵守上一项提到的“驼峰规约”,函数名、参数、局部变量全部是短单词,这一点需要继续改进。
静态代码检查
选择工具:FindBugs 3.0.1
下载链接:http://findbugs.sourceforge.net/
检查结果如下:
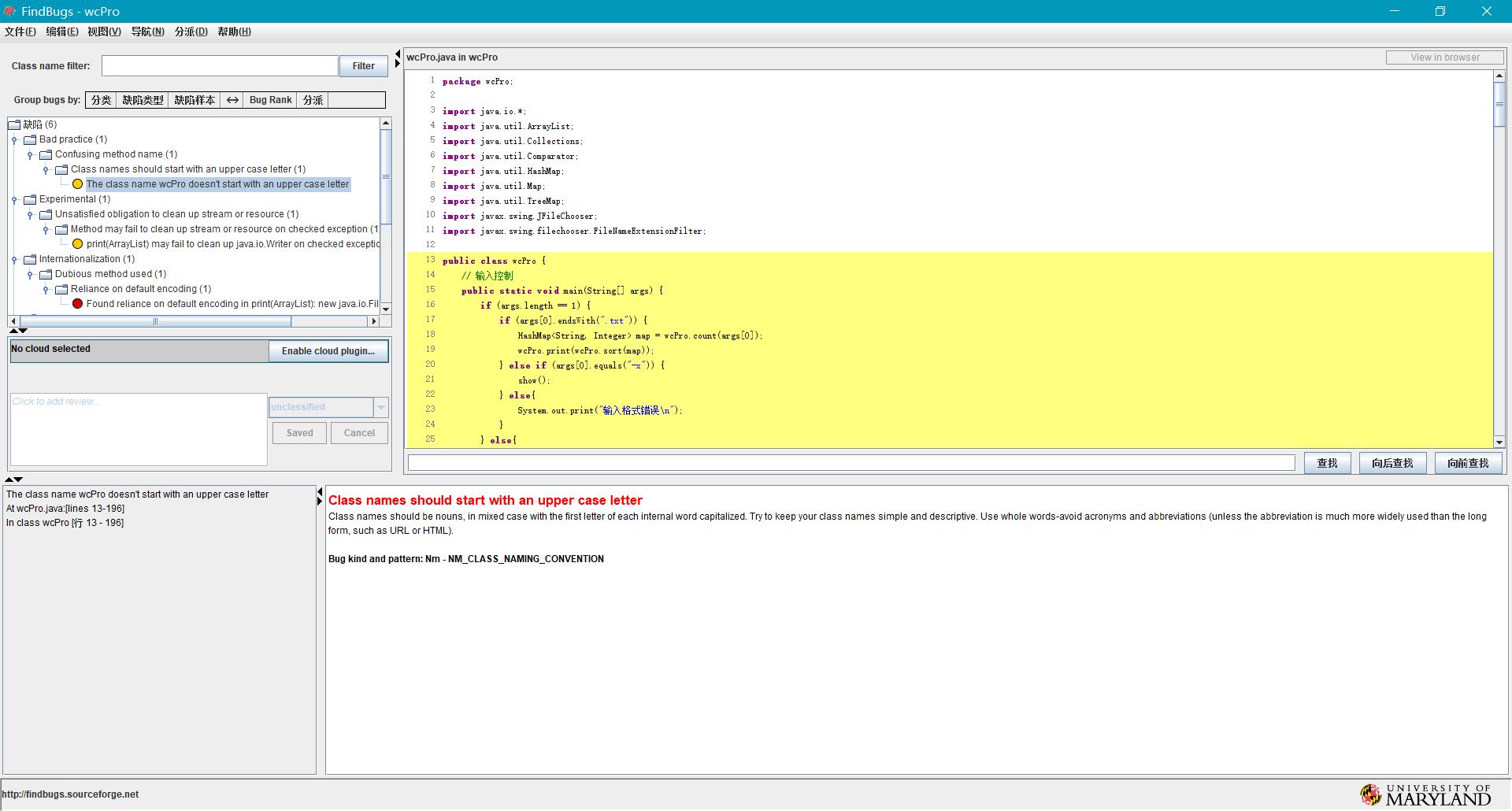
Class names should start with an upper case letter
Class names should be nouns, in mixed case with the first letter of each internal word capitalized. Try to keep your class names simple and descriptive. Use whole words-avoid acronyms and abbreviations (unless the abbreviation is much more widely used than the long form, such as URL or HTML).
Bug kind and pattern: Nm - NM_CLASS_NAMING_CONVENTION
分析:我设计的类名是wcPro,开头字母是小写,不符合JAVA规范,这个属于习惯问题,以后在编码时应该注意这些细节。
个人代码改进
类名修改为WCPro,函数名、参数、局部变量全部修改为《阿里巴巴Java开发手册》所规定的“驼峰形式”。
修改后代码如下:
// 词频排序 public static ArrayList<String> sortList(HashMap<String, Integer> hashMap) { // 以Key进行排序 TreeMap treeMap = new TreeMap(hashMap); // 以value进行排序 ArrayList<Map.Entry<String, Integer>> sortList = new ArrayList<Map.Entry<String, Integer>>( treeMap.entrySet()); Collections.sort(sortList, new Comparator<Map.Entry<String, Integer>>() { public int compare(Map.Entry<String, Integer> mapEntry_1, Map.Entry<String, Integer> mapEntry_2) { // 降序 return mapEntry_2.getValue() - mapEntry_1.getValue(); // 升序 mapEntry_1.getValue() - mapEntry_2.getValue()) } }); ArrayList<String> strSort = new ArrayList<String>(); int loopNum = 0; for (Map.Entry<String, Integer> mapString : sortList) { // 排除-与空格 if (!(mapString.getKey().equals("")) && !(mapString.getKey().equals("-"))) { strSort.add(mapString.getKey()); strSort.add(mapString.getValue().toString()); // 输出前100个单词 if (loopNum > 100) break; loopNum++; } } return strSort; }
// 图形界面 public static String imgShow() { // 默认的打开路径为“我的文档” JFileChooser fileChooser = new JFileChooser(new File( System.getProperty("user.dir"))); // 设置默认目录为得到工程的路径 fileChooser.setDialogTitle("请选择文件"); FileNameExtensionFilter nameFilter = new FileNameExtensionFilter( "文本文件(*.txt)", "txt"); fileChooser.setFileFilter(nameFilter); int returnVal = fileChooser.showOpenDialog(null); if (returnVal == JFileChooser.APPROVE_OPTION) { String[] filePath = new String[1]; filePath[0] = fileChooser.getSelectedFile().getPath(); main(filePath); return "图形界面打开成功\n"; } else { return "图形界面打开失败\n"; } }
再次运行单元测试,结果无改变。
至于代码缩进格式的问题,除了必要的空行之外,其他的交给编译器来自动校正缩进格式,这样就不会给阅读代码的人带来太多的不便。
小组代码分析
(此部分由本人与成建伟(17091)共同完成)
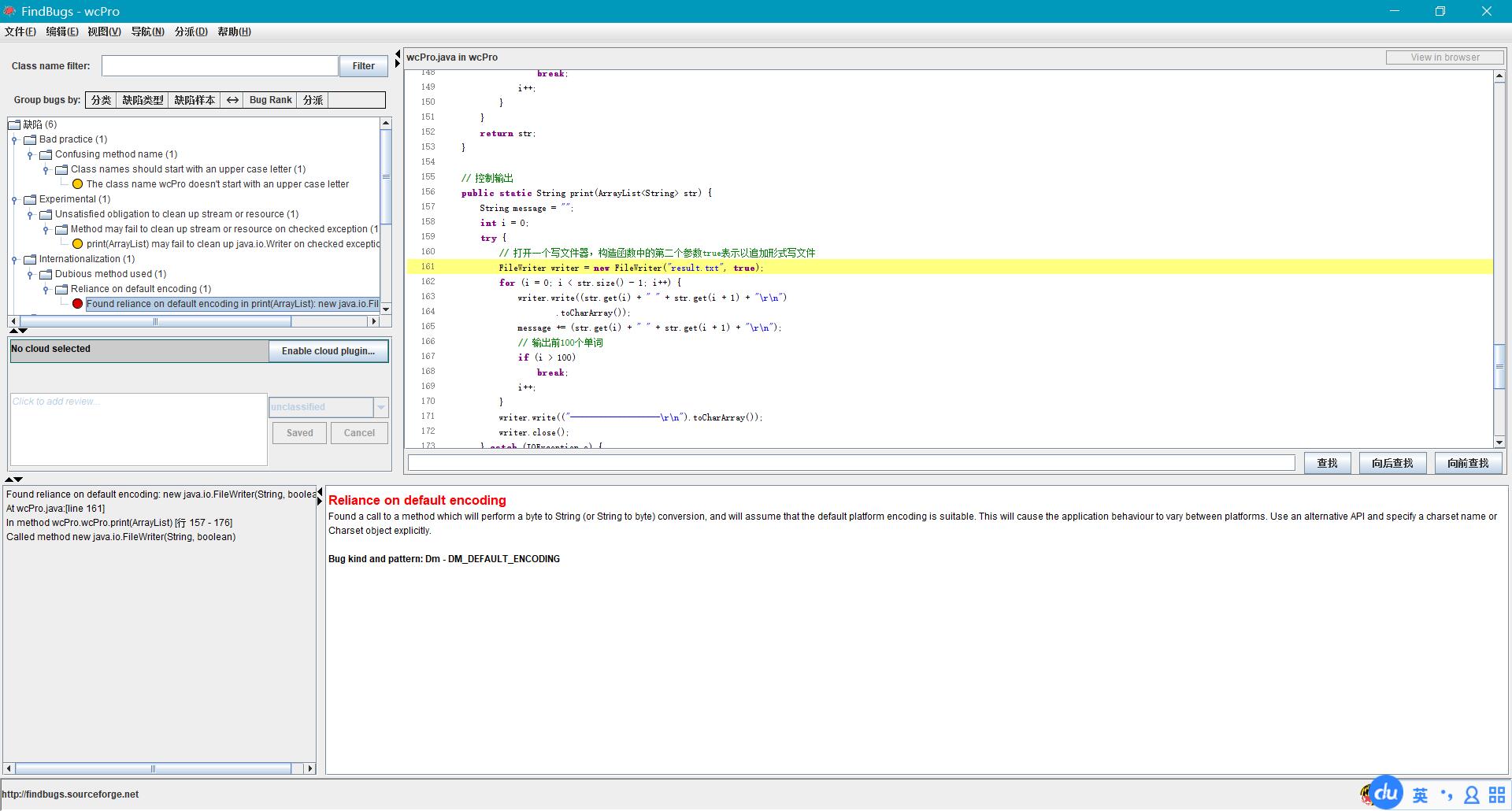
1、FileWriter writer = new FileWriter("result.txt", true);
写文件流可能关闭异常,应该使用try/finally来确保写文件流会被成功关闭。
原有代码中使用了try/catch,但是并未使用finally语句,这就导致如果出现错误跳到catch,程序继续执行的话,写文件流一直会被占用,从而可能引发程序崩溃。
建议添加finally块来关闭写文件流。
2、FileWriter writer = new FileWriter("result.txt", true);
此行语句需要依赖默认编码来正常工作,为防止隐藏bug,应该指定一个编码,考虑到程序需求,指定UTF-8编码。
3、String line = new String("");
new String("")构造函数效率低,直接line=""即可。
4、message += (str.get(i) + " " + str.get(i + 1) + "\r\n");
循环中使用+来连接字符串,时间开销为二次方,建议修改使用StringBUffer.append(String)方法来提高效率。
参考资料
3、Java文件选择对话框(文件选择器JFileChooser)的使用:以一个文件加密器为例

