利用Hadoop自带example实现wordCount
上次虽然把环境搭好了,但是实际运行起来一堆错误,下面简述一下踩的坑。
1、hadoop fs -put上传文件失败,WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: master:8020
解决方案:https://www.cnblogs.com/BoqianLiu/p/10183535.html
2、NodeManager运行一段时间后自行消失
解决方案:同上,第1个问题解决了这个问题也消失了,亏我还给他准备了好几种解决方案。
具体过程:
1、开启hdfs与yarn集群
start-dfs.sh
start-yarn.sh
我这里测试图省事就直接start-all了,正常工作还是按照人家的建议来,分别开启好一点哈
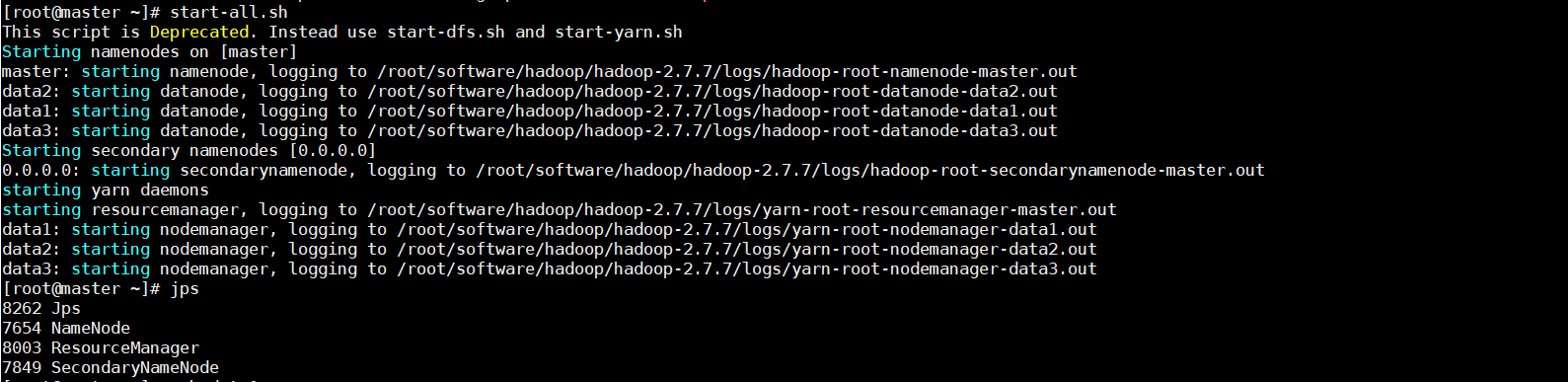
2、确认hadoop已经成功运行
ps -ef|grep hadoop

3、在hdfs新建test目录并测试
hadoop fs -mkdir /test
hadoop fs -ls -R /

4、从本地向test目录上传文件
*.txt表示当前终端目录下所有txt类型的文件
hadoop fs -put *.txt /test
5、运行hadoop自带example里面的wordcount程序
hadoop jar /root/software/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /test /output
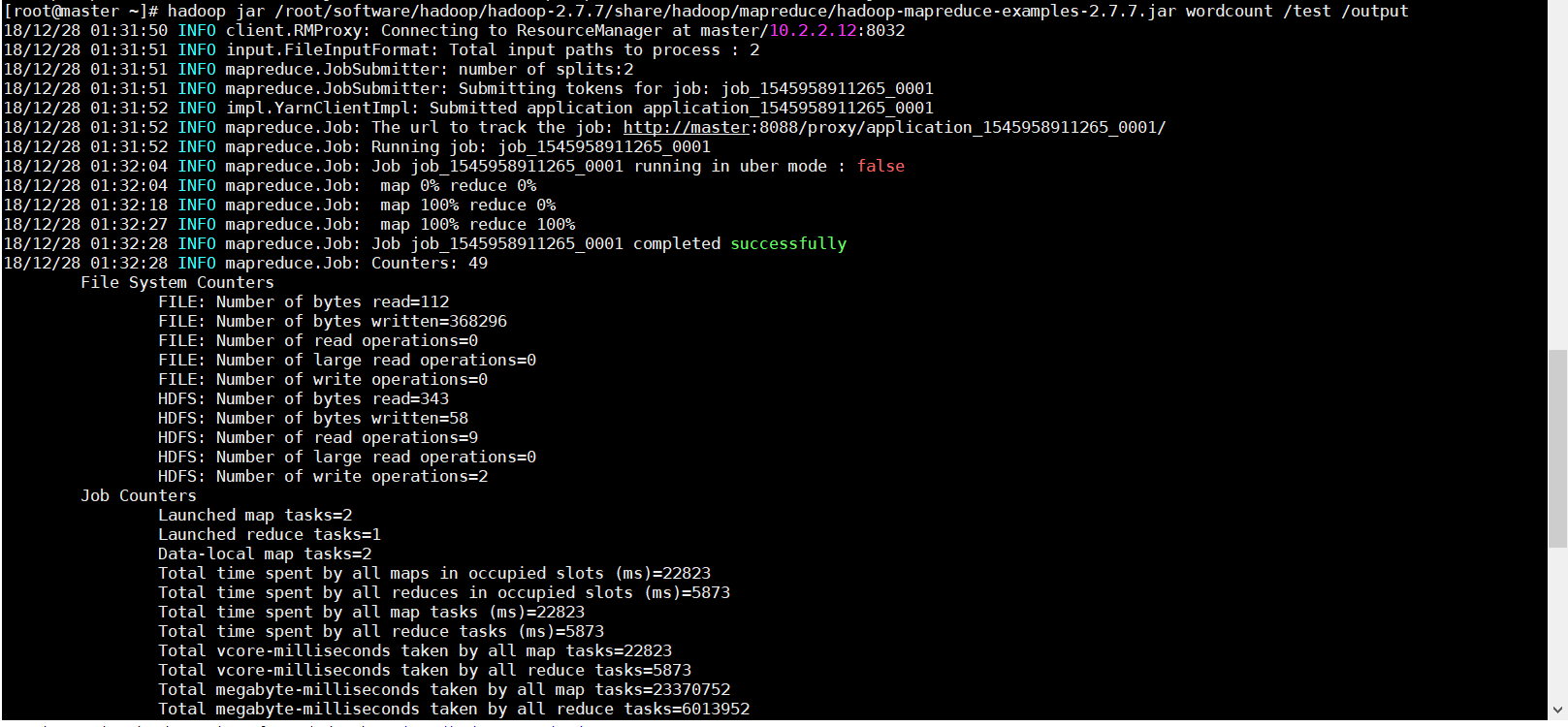
这个地方要注意的就是output必须是事先不存在的,如果已经存在会报错FileAlreadyExistsException,即便提前把里面的文件清空也是不可以的。

6、打印/output结果
hadoop fs -cat /output/part-r-00000


