简单Hadoop集群环境搭建
最近大数据课程需要我们熟悉分布式环境,每组分配了四台服务器,正好熟悉一下hadoop相关的操作。
注:以下带有(master)字样为只需在master机器进行,(ALL)则表示需要在所有master和slave机器进行配置。
一、更改各主机名称并配置免密登陆
1、将各台主机的ip与hostname的映射添加到hosts文件中上。(ALL)
vi /etc/hosts
在末尾加上 xx.xx.xx.xx <hostname> 的映射,以后直接 ssh <hostname>就可以访问,不必再输前边一大串数字。
不过这样只是登录的时候方便,连接上后显示的hostname还是原有的hostname,下一步我们更改各台主机显示的hostname。
2、ssh登录各台主机,并修改hostname
sudo hostnamectl set-hostname <newhostname>
修改完成后并不会马上效,可以exit再重新进入看一看。
下图可以看到,原有的hostname slave-3已经被修改成了data1

3、配置master免密登陆其他几台主机(master)
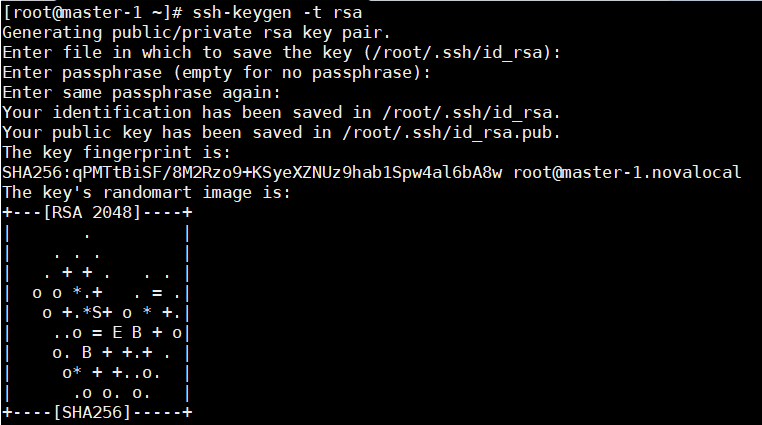
在master生成RSA密钥,出现以下界面即成功。
ssh-keygen -t rsa
将密钥分发到其他几台主机上,这个过程会需要我们输入各台主机的密码。
ssh-copy-id -i ~/.ssh/id_rsa.pub <hostname>
出现下图即为成功,但我们目前仍位于master主机上,接下来可以 ssh <hostname> 试一下能否免密登陆。

二、配置jdk与Hadoop集群环境
我这里是直接scp从服务器拉取的压缩包(需要输入密码),其实也可以从官网下载以及本地上传等方式。
scp root@xx.xx.xx.xx:/root/jdk-7u80-linux-x64.tar.gz /root
scp root@xx.xx.xx.xx:/root/hadoop-2.7.7.tar.gz /root
1、解压并安装jdk,并移动到新目录(ALL)
tar -zxvf jdk-7u80-linux-x64.tar.gz mv jdk1.7.0_80/ /root/software/jdk
2、解压并安装Hadoop,并移动到新目录(ALL)
tar -zxvf hadoop-2.7.7.tar.gz mv hadoop-2.7.7 /root/software/hadoop
3、配置java与Hadoop的环境变量(ALL)
关于java配置可以看我另一篇Spring部署的帖子,上面也有相关的操作。
vi ~/.bashrc
加入如下内容
#更改于2018年12月26日 #操作者:XXX #添加java与hadoop环境变量 export JAVA_HOME=/root/software/jdk/jdk1.7.0_80 export PATH=$PATH:$JAVA_HOME/bin export HADOOP_HOME=/root/software/hadoop/hadoop-2.7.7 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
source命令让修改立刻生效。
source ~/.bashrc
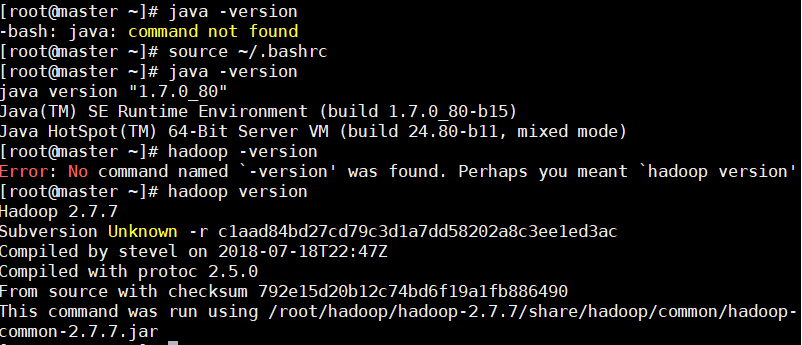
可以使用java与hadoop命令查看版本号,验证是否安装成功。
java -version
hadoop version
4、进一步修改hadoop相关配置文件(ALL)
下面的配置文件都是位于该文件位于software/hadoop/hadoop-2.7.7/etc/hadoop/文件夹下的。
4.1修改hadoop-env.sh文件,配置JDK的路径
使用vi找到 export JAVA_HOME=${JAVA_HOME} 的一行,修改为绝对地址,而非JAVA_HOME
export JAVA_HOME=/root/software/jdk/jdk1.7.0_80
4.2修改core-site.xml文件
在<configuration></configuration>中添加如下内容(hadooptmp文件夹需要在root/software下创建)
<!--XXX于2018年12月26日修改configuration-->
<!--HDFS Web UI监听端口配置-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<!--更改hadoop缓存目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/root/software/hadooptmp</value>
</property>
4.3修改hdfs-site.xml文件
在<configuration></configuration>中添加如下内容(同理,namenode和datanode也需要相应创建)
<!--每个block存几份-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--namenode数据目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/software/hadooptmp/namenode</value>
</property>
<!--datanode数据目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/software/hadooptmp/datanode</value>
</property>
4.4从mapred-site.xml.template使用cp命令生成mapred-site.xml文件,并修改mapred-site.xml文件
cp mapred-site.xml.template mapred-site.xml
在<configuration></configuration>中添加如下内容
<!--设置MapReduce运行于yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
4.5修改yarn-site.xml文件
在<configuration></configuration>中添加如下内容
<!--如果使用spark等其他分布式计算框架,需要相应修改-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
4.6修改slaves文件,将已经映射的ip地址的主机名称追加到结尾即可。
同时还需要删除原有的loaclhost(伪分布式才会这么写)。
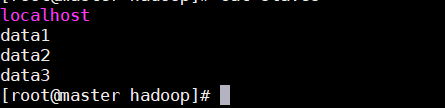
4.7slave机器按照4.1到4.6部署
重复操作很多,各位可以写个脚本自动执行,也可以直接把software文件夹压缩再scp拉过去。
master机器执行如下命令
tar -zcvf /root/software.tar.gz software/
slave机器执行如下命令
scp root@xx.xx.xx.xx:/root/software.tar.gz /root
tar -zxvf software.tar.gz
这样software里面大部分修改 都不需要再做,把剩余的工作重复一下就ok。
三、HDFS简单操作
1、启动HDFS(执行一次即可,不必每次都执行)
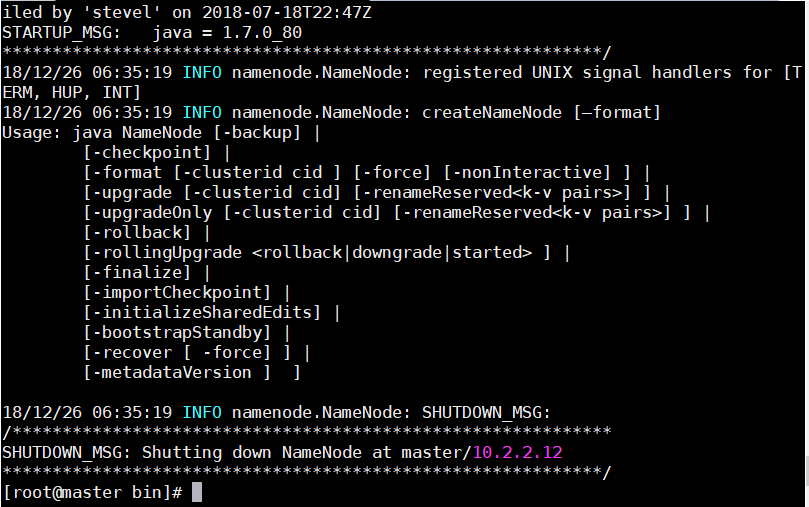
1.1执行如下命令,格式化文件系统(master)
这一步需要在所有服务器上进行,有一点要注意,就是执行命令的目录不能低于software,否则会出现找不到目录的情况。
./software/hadoop/hadoop-2.7.7/bin/hdfs namenode -format
成功截图:
1.2开启HDFS:运行 NameNode和 DataNode的守护进程(master)
执行如下命令,开启HDFS
bash /root/software/hadoop/hadoop-2.7.7/sbin/start-dfs.sh
1.3jps命令验证HDFS是否启动成功(ALL)
master服务器:
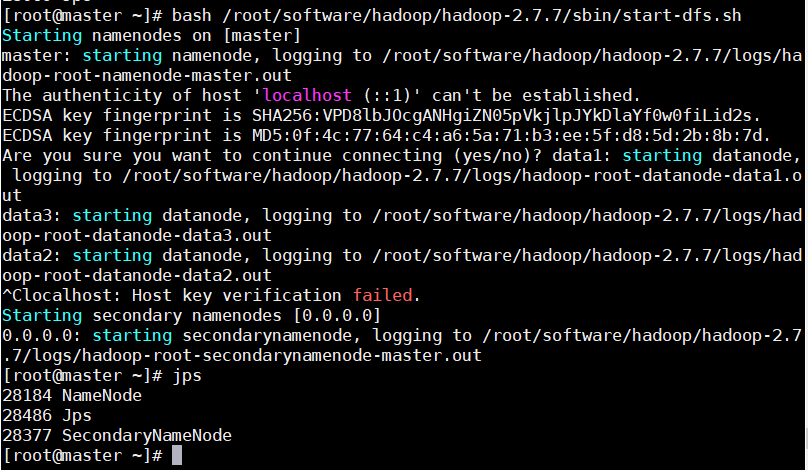
上面key验证失败是因为之前的slaves文件没有删除localhost,删除之后就可以顺利进行了。

slave服务器:

如果jps发现进程不对的话,可以去/root/software/hadoop/hadoop-2.7.7/logs目录下查看相关的log文件,定位到最后的错误,然后想办法解决就ok~
2、启动yarn
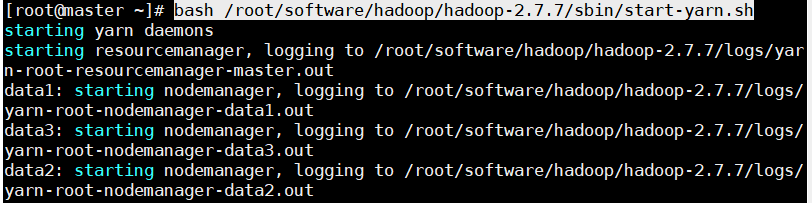
2.1启动运行ResourceManager和NodeManager守护进程(master)
bash /root/software/hadoop/hadoop-2.7.7/sbin/start-yarn.sh
执行效果如图:
2.2验证yarn是否开启成功(ALL)
master机器:

slave机器:

参考资料:
4、遇到问题---Hadoop---java.io.IOException: NameNode is not formatted

