
程序简介
将9类新闻语料切割为训练集和数据集,对新闻进行分词、去停用词、句向量构建后,调用sklearn模块提供的朴素贝叶斯接口建模,对新闻分类,最终实现的接口为
输入:新闻字符串
输出:新闻分类
朴素贝叶斯分类(NBC)是以贝叶斯定理为基础并且假设特征条件之间相互独立的方法,先通过已给定的训练集,以特征词之间独立作为前提假设,学习从输入到输出的联合概率分布,再基于学习到的模型,输入X求出使得后验概率最大的输出Y。
程序/数据集下载

代码分析
导入模块、预设参数、路径
# -*- coding: utf-8 -*-
from sklearn.metrics import accuracy_score
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.externals import joblib
from sklearn.metrics import confusion_matrix
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import json
import pandas as pd
import jieba
import re
import os
topWordNum = 500#保留前n个高频词形成词典
testRate = 0.2#测试集比例
seed = 0#随机种子
#路径目录
baseDir = ''#根目录
staticDir = os.path.join(baseDir,'Static')#静态文件目录
resultDir = os.path.join(baseDir,'Result')#结果文件目录
载入、查看部分停用词
#载入停用词
with open(staticDir+'/中文停用词.txt','r',encoding='utf-8')as f:
stopWords = [line.strip('\n') for line in f.readlines()]
stopWords += '\n'
stopWords[300:305]
['乘', '乘势', '乘机', '乘胜', '乘虚']
载入、查看部分新闻语料
#载入语料
data = pd.read_excel(staticDir+'/新闻分类语料.xlsx')
print('载入语料,获得%d条语料'%data.shape[0])
data.head()
载入语料,获得18000条语料
| title | content | flag | |
|---|---|---|---|
| 0 | 根据口气可预知疾病! | 口气又称口臭、口腔异味,虽无生命危险,但令周围人难以忍受,患者自己也常感到窘迫、孤立,妨碍社... | health |
| 1 | 我国禁毒形势依然不容乐观 农民工易染毒 | 国家禁毒委员会常务副秘书长、公安部禁毒局局长杨凤瑞今天在北京表示,我国禁毒斗争在堵截毒品入境... | health |
| 2 | 马长生做客搜狐健康 | 6月22日15:00-16:00,首都医科大学附属北京安贞医院心内科副主任马长生教授做客搜狐... | health |
| 3 | 王勤环教授谈慢性乙肝的治疗目标 | 本期嘉宾1本┐笱У谝灰皆捍染疾病科M跚诨方淌邶K押健康特邀北京大学第一医院传染疾病科王勤环教... | health |
| 4 | 月经不调的预防和治疗 | 搜狐健康专家访谈间特邀北京军区总医院妇产科主任温凯辉教授做客,与网友们谈有关月经不调的预防和... | health |
清理段落,分词,删除停用词,查看效果
def clearpara(para):
'''
清理段落,分词,删除停用词
'''
words = jieba.cut(para)#分词
#过滤
words = [word for word in words if len(word)>1]
words = [word for word in words if word not in stopWords]
return words
print('正在对语料分词,请耐心...')
data['words'] = data['content'].apply(clearpara)
data.head()
Building prefix dict from the default dictionary ...
正在对语料分词,请耐心...
Dumping model to file cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 2.110 seconds.
Prefix dict has been built successfully.
| title | content | flag | words | |
|---|---|---|---|---|
| 0 | 根据口气可预知疾病! | 口气又称口臭、口腔异味,虽无生命危险,但令周围人难以忍受,患者自己也常感到窘迫、孤立,妨碍社... | health | [口气, 又称, 口臭, 口腔, 异味, 生命危险, 但令, 难以忍受, 患者, 感到, 窘... |
| 1 | 我国禁毒形势依然不容乐观 农民工易染毒 | 国家禁毒委员会常务副秘书长、公安部禁毒局局长杨凤瑞今天在北京表示,我国禁毒斗争在堵截毒品入境... | health | [国家禁毒委员会, 常务副, 秘书长, 公安部, 禁毒, 局局长, 杨凤瑞, 北京, 我国,... |
| 2 | 马长生做客搜狐健康 | 6月22日15:00-16:00,首都医科大学附属北京安贞医院心内科副主任马长生教授做客搜狐... | health | [首都医科大学, 附属, 北京安贞医院, 心内科, 主任, 长生, 教授, 做客, 搜狐, ... |
| 3 | 王勤环教授谈慢性乙肝的治疗目标 | 本期嘉宾1本┐笱У谝灰皆捍染疾病科M跚诨方淌邶K押健康特邀北京大学第一医院传染疾病科王勤环教... | health | [本期, 嘉宾, 捍染, 疾病, 方淌, 健康, 特邀, 北京大学第一医院, 传染, 疾病,... |
| 4 | 月经不调的预防和治疗 | 搜狐健康专家访谈间特邀北京军区总医院妇产科主任温凯辉教授做客,与网友们谈有关月经不调的预防和... | health | [搜狐, 健康, 专家, 访谈, 特邀, 北京军区总医院, 妇产科, 主任, 温凯辉, 教授... |
词频统计,保留top N个高频词
#词频统计,保留top N
print('正在进行词频统计')
items = data['words'].values.tolist()
words = []
for item in items:
words.extend(item)
wordCount = pd.Series(words).value_counts()[0:topWordNum]
wordCount = wordCount.index.values.tolist()
正在进行词频统计
将词组转为句向量,不过这里的向量值为高频词的出现次数,删除原内容查看效果
def wordsToVec(words):
'''将词组转为向量,此处向量的数为高频词出现次数'''
vec = map(lambda word:words.count(word),wordCount)
vec = list(vec)
return vec
print('正在将词组转为句向量,请耐心...')
data['vec'] = data['words'].apply(wordsToVec)
data = data.drop(['content'],axis=1)
data.head()
正在将词组转为句向量,请耐心...
| title | flag | words | vec | |
|---|---|---|---|---|
| 0 | 根据口气可预知疾病! | health | [口气, 又称, 口臭, 口腔, 异味, 生命危险, 但令, 难以忍受, 患者, 感到, 窘... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... |
| 1 | 我国禁毒形势依然不容乐观 农民工易染毒 | health | [国家禁毒委员会, 常务副, 秘书长, 公安部, 禁毒, 局局长, 杨凤瑞, 北京, 我国,... | [1, 0, 0, 1, 0, 2, 1, 3, 0, 0, 1, 0, 0, 0, 0, ... |
| 2 | 马长生做客搜狐健康 | health | [首都医科大学, 附属, 北京安贞医院, 心内科, 主任, 长生, 教授, 做客, 搜狐, ... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, ... |
| 3 | 王勤环教授谈慢性乙肝的治疗目标 | health | [本期, 嘉宾, 捍染, 疾病, 方淌, 健康, 特邀, 北京大学第一医院, 传染, 疾病,... | [0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... |
| 4 | 月经不调的预防和治疗 | health | [搜狐, 健康, 专家, 访谈, 特邀, 北京军区总医院, 妇产科, 主任, 温凯辉, 教授... | [0, 0, 0, 0, 0, 0, 0, 3, 0, 1, 4, 0, 0, 0, 0, ... |
将新闻类别即flag列转为数字
#输出字符转数字
flags = data['flag'].value_counts().index.values.tolist()
data['flag'] = data['flag'].apply(lambda x:flags.index(x))
data.head()
| title | flag | words | vec | |
|---|---|---|---|---|
| 0 | 根据口气可预知疾病! | 0 | [口气, 又称, 口臭, 口腔, 异味, 生命危险, 但令, 难以忍受, 患者, 感到, 窘... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... |
| 1 | 我国禁毒形势依然不容乐观 农民工易染毒 | 0 | [国家禁毒委员会, 常务副, 秘书长, 公安部, 禁毒, 局局长, 杨凤瑞, 北京, 我国,... | [1, 0, 0, 1, 0, 2, 1, 3, 0, 0, 1, 0, 0, 0, 0, ... |
| 2 | 马长生做客搜狐健康 | 0 | [首都医科大学, 附属, 北京安贞医院, 心内科, 主任, 长生, 教授, 做客, 搜狐, ... | [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, ... |
| 3 | 王勤环教授谈慢性乙肝的治疗目标 | 0 | [本期, 嘉宾, 捍染, 疾病, 方淌, 健康, 特邀, 北京大学第一医院, 传染, 疾病,... | [0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... |
| 4 | 月经不调的预防和治疗 | 0 | [搜狐, 健康, 专家, 访谈, 特邀, 北京军区总医院, 妇产科, 主任, 温凯辉, 教授... | [0, 0, 0, 0, 0, 0, 0, 3, 0, 1, 4, 0, 0, 0, 0, ... |
将处理好的数据分割为训练集和测试集,输入sklearn的朴素贝叶斯函数中,测试集准确率为79%,效果良好
#数据集分割
xTrain,xTest,yTrain,yTest = train_test_split(data['vec'].tolist(),data['flag'].tolist(),test_size=testRate,random_state=seed)
#建模
model = MultinomialNB()
model.fit(xTrain,yTrain)
#预测
yPred = model.predict(xTest)
yTest = np.array(yTest)
yPred = np.array(yPred)
print('模型测试集准确率:%.2f'%accuracy_score(yTest,yPred))
模型测试集准确率:0.79
可视化混淆矩阵
#用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
#用来正常显示负号
plt.rcParams['axes.unicode_minus']=False
#计算混淆矩阵
confusion = confusion_matrix(yTest,yPred)
plt.clf()
plt.title('分类混淆矩阵')
sns.heatmap(confusion, square=True, annot=True, fmt='d', cbar=False,
xticklabels=flags,
yticklabels=flags,
linewidths=0.1,cmap='YlGnBu_r')
plt.ylabel('观测')
plt.xlabel('预测')
plt.xticks(rotation=-13)
plt.savefig(resultDir+'/新闻分类混淆矩阵.png',dpi=100)
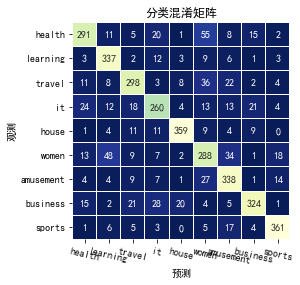
编写一个函数,输入为新闻内容,输出为分类,测试一下~
def predict(para):
'''输入文章,输出分类标签'''
words = clearpara(para)#分词
vec = wordsToVec(words)#句向量
vec = np.array(vec)[np.newaxis,:]
flagIndex = model.predict(vec)[0]
flag = flags[flagIndex]
return flag
#一则体育新闻
para = '明天凌晨,欧洲杯C组将展开第二轮的争夺。亨利在为国家队征战的100场比赛中攻入了44个进球,是法国队当仁不让的王牌前锋。而队长维埃拉是法国中场不可或缺的核心人物。媒体猜测在伯尔尼迎战荷兰队时,他们两人将取代阿内尔卡和图拉朗先发。另外两个需要调整的是左、右边后卫阿比达尔和萨尼奥尔,两人在首场比赛的。”'
print(para)
print('\n该则新闻分类为%s'%predict(para))
明天凌晨,欧洲杯C组将展开第二轮的争夺。亨利在为国家队征战的100场比赛中攻入了44个进球,是法国队当仁不让的王牌前锋。而队长维埃拉是法国中场不可或缺的核心人物。媒体猜测在伯尔尼迎战荷兰队时,他们两人将取代阿内尔卡和图拉朗先发。另外两个需要调整的是左、右边后卫阿比达尔和萨尼奥尔,两人在首场比赛的。”
该则新闻分类为sports

