

Synchronized总结及底层原理分析#网易微专业# #Java#
一,了解synchronized底层所需要的基础知识:
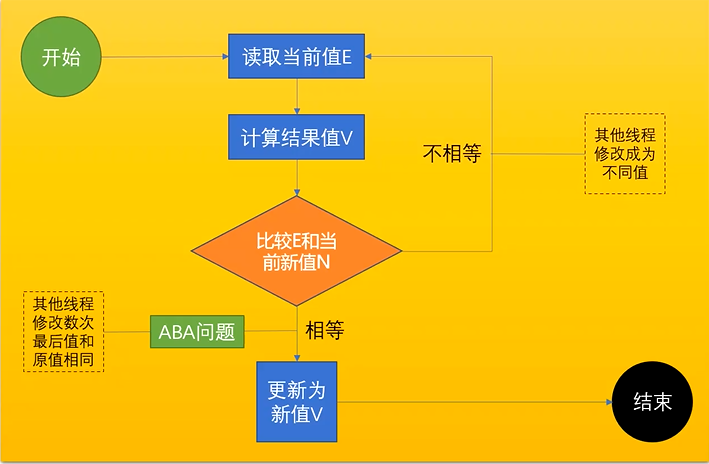
①CAS:compare and swap。
首先读取当前值E,然后把此值放在线程里计算结果,把计算结果往回写的时候比较之前读取的值和当前新值是否一样,如果一样,说明并没有被其他线程修改过,所以直接把计算结果写入即可,不需要上锁。(无锁,自旋锁)
补充说明:比较结果一样的情况中,有可能是出现了ABA问题。ABA问题产生原因分析:假设要取出内存某时刻的value值为A,线程1读取值为A想要写入B值,结果在往内存中写入C值的时候,线程2将A改成了B,随后线程3又将B改为了A,但对线程1来说,并不知道value发生了变化。
解决ABA问题:通过版本号的方式。
②CAS底层实现。
如果采取m++方式,为了多线程安全性,需要加锁,但如果采用autoInteger的incrementAndGet()方法,不用加锁。是因为此方法用了unsafe类的 compareAndSwapInt()方法,native表明是C/C++写的底层实现(hot spot)。追踪源码发现,其最终实现是lock cmpxchg指令,cmpxchg=cas修改变量值。
(追踪过程)硬件上实现是lock指令在执行后面指令的时候锁定一个北桥信号(不采用锁总线的方式),但这条指令不是原子的,即它拿到值往回写的过程中,依然有可能被别的线程打断,所以在cmpxchg指令前加了lock指令,即在当前指令在操作内存时,其他线程不得干扰。

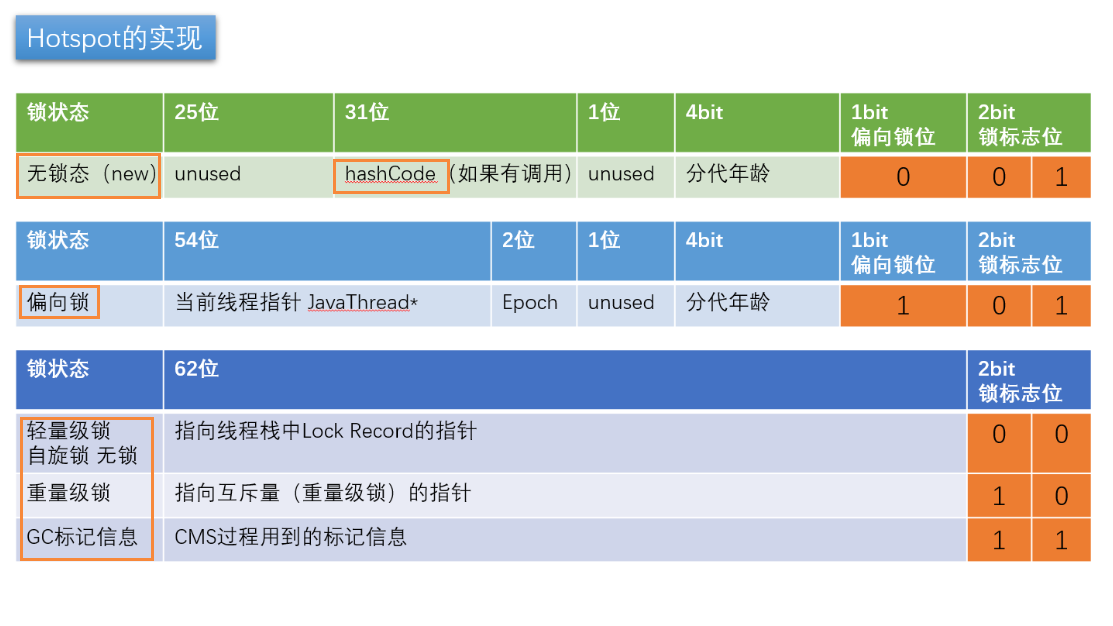
③对象的内存布局,markword细节
markword里面有三部分内容:锁信息,GC信息,hashcode。加锁即修改markword里面的内容。早期,synchronized叫做重量级锁,因为申请锁资源必须通过kernel,系统调用,而CAS不需要额外的内核态,为轻量级锁。

用markword中最低的三位代表锁状态 其中1位是偏向锁位 两位是普通锁位。
二,synchronized的底层实现:
(一)锁升级的过程:C++代码和汇编
①首先为什么会有偏向锁呢?
多数Sychronized方法,在很多情况下,其实只有一个线程运行,例如:StringBuffer中的一些sync方法(append()方法),Vector中的一些sync方法
②偏向锁:和自旋锁一样,是用户空间完成的,具体操作是markword上记录当前线程指针,下次同一个线程加锁的时候,不需要争用,只用判断线程指针是否是同一个,所以,偏向锁,偏向的是加锁的第一个线程,hashCode备份在线程栈上,线程销毁,锁降级为无锁。
一旦有其他线程竞争,偏向锁就会升级为轻量级锁,每个线程有自己的LockRecord在自己的线程栈上,用CAS去争用markword的LR的指针,指针指向哪个线程的LR,哪个线程就拥有锁。如果自旋次数超过十次,升级为重量级锁。或者有多个线程在等待,即超过1/2cpu核数,升级为重量级锁。以前通过参数可以调,现在JVM做了优化,自适应自旋,合适的时候自己升级为重量锁。
③为什么有了轻量级锁还要有重量级锁?轻量级锁的应用场景?
轻量级锁的应用场景往往是锁执行的时间短,自旋少次就能拿到锁,或线程数少,竞争数少。自旋锁是需要占用CPU资源的(while循环),而重量级锁有等待队列,所有拿不到锁的进入等待队列,不需要消耗CPU资源。
④偏向锁默认是启动的,但会默认延迟4秒钟。因为JVM虚拟机自己有一些默认启动的线程,里面有好多sync代码,这些sync代码启动时就知道肯定会有竞争,如果使用偏向锁,就会造成偏向锁不断的进行锁撤销,锁升级的操作,效率较低。
⑤偏向锁效率一定会比自旋锁效率高吗?
不一定。JVM启动过程,会有很多线程竞争(明确),所以默认情况启动时不打开偏向锁,过一段儿时间再打开。
所以,当创建对象实例时,如果偏向锁未启动,则创建的是普通对象实例,如果偏向锁已启动,则为匿名偏向。

(二)锁消除
(三)锁粗化
JIT运行时优化。

