流畅的python--第十二章 序列的特殊方法
Vector 类第 1 版:与 Vector2d 类兼容
示例 12-2 vector_v1.py:从 vector2d_v1.py 衍生而来
from array import array
import reprlib
import math
class Vector:
typecode = 'd'
def __init__(self, components):
self._components = array(self.typecode, components)# ❶
def __iter__(self):
return iter(self._components) #❷
def __repr__(self):
components = reprlib.repr(self._components) #❸
components = components[components.find('['):-1] #❹
return f'Vector({components})'
def __str__(self):
return str(tuple(self))
def __bytes__(self):
return (bytes([ord(self.typecode)]) +
bytes(self._components)) #❺
def __eq__(self, other):
return tuple(self) == tuple(other)
def __abs__(self):
return math.hypot(*self) #❻
def __bool__(self):
return bool(abs(self))
@classmethod
def frombytes(cls, octets):
typecode = chr(octets[0])
memv = memoryview(octets[1:]).cast(typecode)
return cls(memv) #❼
❶ self._components 是“受保护”的实例属性,把 Vector 的分量保存在一个数组中。
❷ 为了迭代,使用 self._components 构建一个迭代器,作为返回值。
❸ 使用 reprlib.repr() 函数生成 self._components 的有限长度表
示形式(例如 array('d', [0.0, 1.0, 2.0, 3.0, 4.0,...]))。
❹ 把字符串插入 Vector 的构造函数调用之前,去掉前面的array('d', 和后面的 )。
❺ 直接使用 self._components 构建 bytes 对象。
❻ 从 Python 3.8 开始,math.hypot 接受 N 维坐标点。以前使用的表达式是 math.sqrt(sum(x * x for x in self))。
❼ 只需在 frombytes 方法的基础上改动最后一行:直接把memoryview 传给构造函数,不用像前面那样使用 * 拆包。
协议和鸭子类型
在面向对象编程中,协议是非正式的接口,只在文档中定义,不在代码
中定义。例如,Python 的序列协议只需要__len__和 __getitem__ 这
两个方法。任何类(例如 Spam),只要使用标准的签名和语义实现了
这两个方法,就能用在任何预期序列的地方。Spam 是不是哪个类的子
类无关紧要,只要提供了所需的方法即可。示例 1-1 就是一例,这里再
次给出代码,如示例 12-3 所示。
示例 12-3 示例 1-1 的代码,为了方便参考,再次给出
import collections
Card = collections.namedtuple('Card', ['rank', 'suit'])
class FrenchDeck:
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Card(rank, suit) for suit in self.suits
for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]
示例 12-3 中的 FrenchDeck 类能充分利用 Python 的很多功能,因为它
实现了序列协议,即使代码中并没有声明这一点。任何有经验的 Python
程序员只要看一眼就知道它是序列,即便它是 object 的子类也无妨。
我们说它是序列,因为它的行为像序列,这才是重点。
协议是非正式的,没有强制力,因此如果知道类的具体使用场景,那么
通常只需要实现协议的一部分。例如,为了支持迭代,只需实现
__getitem__ 方法,没必要提供__len__方法。
Vector 类第 2 版:可切片的序列
如 FrenchDeck 类所示,如果能委托给对象中的序列属性(例如
self._components 数组),则支持序列协议特别简单。下面只有一行
代码的__len__方法和 __getitem__ 方法是很好的开始。
class Vector:
typecode = 'd'
def __init__(self, components):
self._components = array(self.typecode, components)# ❶
def __iter__(self):
return iter(self._components) #❷
def __repr__(self):
components = reprlib.repr(self._components) #❸
components = components[components.find('['):-1] #❹
return f'Vector({components})'
def __str__(self):
return str(tuple(self))
def __bytes__(self):
return (bytes([ord(self.typecode)]) +
bytes(self._components)) #❺
def __eq__(self, other):
return tuple(self) == tuple(other)
def __abs__(self):
return math.hypot(*self) #❻
def __bool__(self):
return bool(abs(self))
@classmethod
def frombytes(cls, octets):
typecode = chr(octets[0])
memv = memoryview(octets[1:]).cast(typecode)
return cls(memv) #❼
def __len__(self):
return len(self._components)
def __getitem__(self, index):
return self._components[index]

可以看到,连切片都支持了,不过尚不完美。如果 Vector 实例的切片
也是 Vector 实例,而不是数组,那就更好了。前面那个 FrenchDeck
类也有类似的问题:切片得到的是列表。对 Vector 来说,如果切片生
成普通的数组,那么将会失去大量功能。
想想内置序列类型:切片得到的都是各自类型的新实例,而不是其他类型。
为了把 Vector 实例的切片也变成 Vector 实例,不能简单地把切片操作委托给数组。要分析传给 __getitem__ 方法的参数,做适当的处理。
切片原理
示例 12-4 观察 __getitem__ 和切片的行为
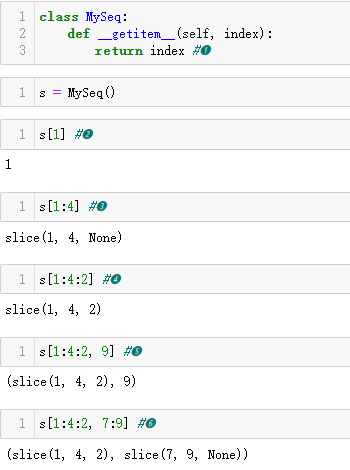
❶ 在这个示例中,__getitem__ 直接返回传给它的值。
❷ 单个索引,没什么新奇的。
❸ 1:4 表示法变成了 slice(1, 4, None)。
❹ slice(1, 4, 2) 的意思是从1开始,到 4 结束,步幅为 2。
❺ 神奇的事发生了:如果[]中有逗号,那么 __getitem__ 收到的就是元组。
❻ 元组中甚至可以有多个 slice 对象。
示例 12-5 查看slice类的属性
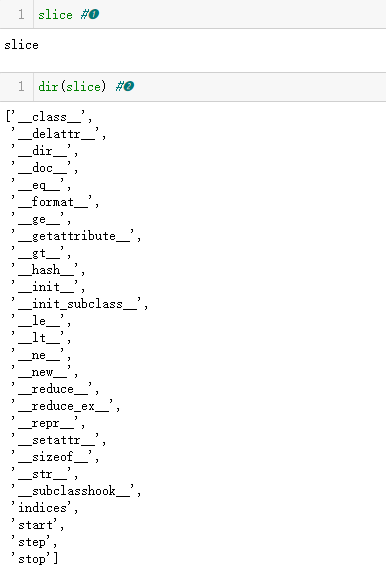
❶ slice 是内置的类型(首次出现于 2.7.2 节)。
❷ 查看 slice,我们发现它有 start、stop 和 step 这 3 种数据属
性,还有 indices 方法。
在示例 12-5 中,调用 dir(slice) 得到的结果中有个 indices 属性,
这是一个方法,作用很大,但是鲜为人知。help(slice.indices) 给
出的信息如下。

给定长度为 len 的序列,计算 S 表示的扩展切片的起始(start)
索引和结尾(stop)索引,以及步幅(stride)。超出边界的索引会
被截掉,就像常规切片一样。
换句话说,indices 方法开放了内置序列实现的棘手逻辑,可以优雅地
处理缺失索引和负数索引,以及长度超过目标序列的切片。这个方法
会“整顿”元组,把 start、stop 和 stride 都变成非负数,而且都落在
指定长度序列的边界内。
下面举几个例子。假设有一个长度为5的序列,例如 'ABCDE'。
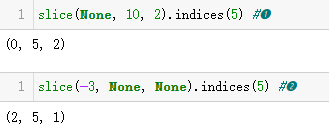
❶ 'ABCDE'[:10:2] 等同于 'ABCDE'[0:5:2]。
❷ 'ABCDE'[-3:] 等同于 'ABCDE'[2:5:1]。
在 Vector 类中无须使用 slice.indices() 方法,因为收到切片参数
时,我们委托 _components 数组处理。因此,如果没有底层序列类型
作为依靠,那么使用这个方法能节省大量时间。
能处理切片的 __getitem__ 方法
示例 12-6 列出了让 Vector 表现为序列所需的两个方法:__len__ 和__getitem__(后者现在能正确处理切片了)。
示例 12-6 vector_v2.py 的部分代码:为 vector_v1.py 中的 Vector
类(参见示例 12-2)添加 __len__ 方法和 __getitem__ 方法
def __len__(self):
return len(self._components)
def __getitem__(self, key):
if isinstance(key, slice): #❶
cls = type(self) #❷
return cls(self._components[key]) #❸
index = operator.index(key) #❹
return self._components[index] #❺
❶ 如果 key 参数的值是一个 slice 对象……
❷ ……就获取实例的类(Vector),然后……
❸ ……调用类的构造函数,使用 _components 数组的切片构建一个新
Vector 实例。
❹ 如果从 key 中得到的是单个索引……
❺ ……就返回 _components 中相应的元素。
🚩大量使用
isinstance可能表明面向对象设计得不好,不过
在__getitem__方法中使用它处理切片是合理的。
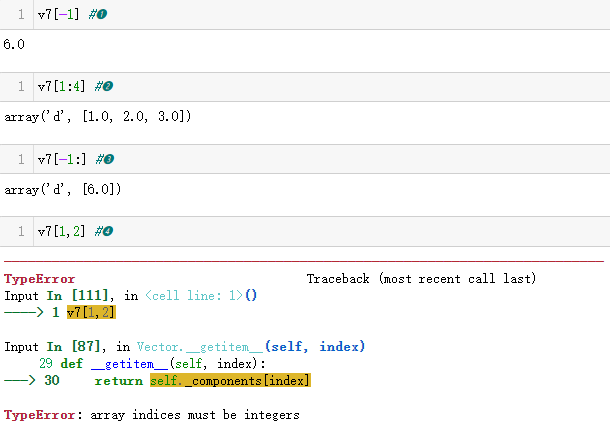
示例 12-7 测试示例 12-6 中改进的Vector.__getitem__方法
❶ 单个整数索引只获取一个分量,值为浮点数。
❷ 切片索引创建一个新Vector实例。
❸ 长度为1的切片也创建一个Vector实例。
❹Vector不支持多维索引,因此索引元组或多个切片会抛出错误。
Vector 类第 3 版:动态存取属性
Vector2d 变成 Vector 之后,就无法通过名称访问向量的分量(例如
v.x 和 v.y)了。现在,我们处理的向量可能有大量分量。不过,如果
能通过单个字母访问前几个分量的话会比较方便。例如,用 x、y 和 z
代替 v[0]、v[1] 和 v[2]。
我们想额外提供以下句法,用于读取向量的前 4 个分量。
class Vector:
typecode = 'd'
def __init__(self, components):
self._components = array(self.typecode, components)# ❶
def __iter__(self):
return iter(self._components) #❷
def __repr__(self):
components = reprlib.repr(self._components) #❸
components = components[components.find('['):-1] #❹
return f'Vector({components})'
def __str__(self):
return str(tuple(self))
def __bytes__(self):
return (bytes([ord(self.typecode)]) +
bytes(self._components)) #❺
def __eq__(self, other):
return tuple(self) == tuple(other)
def __abs__(self):
return math.hypot(*self) #❻
def __bool__(self):
return bool(abs(self))
@classmethod
def frombytes(cls, octets):
typecode = chr(octets[0])
memv = memoryview(octets[1:]).cast(typecode)
return cls(memv) #❼
def __len__(self):
return len(self._components)
def __getitem__(self, index):
return self._components[index]
__match_args__ = ('x', 'y', 'z', 't') #new❶
def __getattr__(self, name):
cls = type(self) #new❷
try:
pos = cls.__match_args__.index(name) #new❸
except ValueError: #new❹
pos = -1
if 0 <= pos < len(self._components): #new❺
return self._components[pos]
msg = f'{cls.__name__!r} object has no attribute {name!r}' #new❻
raise AttributeError(msg)

new❶ 设定 __match_args__,让 __getattr__ 实现的动态属性支持位置模式匹配。
new❷ 获取 Vector 类,供后面使用。
new❸ 尝试获取 name 在 __match_args__ 中的位置。
new❹ 如果未找到 name,那么 .index(name) 就会抛出 ValueError。此
时,把 pos 设为 -1。(我也想在这里使用 str.find 之类的方法,可
惜 tuple 没有实现这样的方法。)
new❺ 如果 pos 落在分量长度范围内,就返回对应的分量。
new❻ 如果执行到这里,就抛出 AttributeError,输出一个标准消息。
__getattr__ 方法的实现不难,但是这样实现还不够。看看示例 12-9
中古怪的交互行为。
示例 12-9 不恰当的行为:为 v.x 赋值没有抛出错误,但是前后矛盾

❶ 使用 v.x 获取第一个元素(v[0])。
❷ 为 v.x 赋新值。这个操作应该抛出异常。
❸ 读取 v.x,得到的是新值 10。
❹ 可是,向量的分量没变。
示例 12-10 vector_v3.py 的部分代码:在 Vector 类中实现__setattr__ 方法
class Vector:
typecode = 'd'
def __init__(self, components):
self._components = array(self.typecode, components)# ❶
def __iter__(self):
return iter(self._components) #❷
def __repr__(self):
components = reprlib.repr(self._components) #❸
components = components[components.find('['):-1] #❹
return f'Vector({components})'
def __str__(self):
return str(tuple(self))
def __bytes__(self):
return (bytes([ord(self.typecode)]) +
bytes(self._components)) #❺
def __eq__(self, other):
return tuple(self) == tuple(other)
def __abs__(self):
return math.hypot(*self) #❻
def __bool__(self):
return bool(abs(self))
@classmethod
def frombytes(cls, octets):
typecode = chr(octets[0])
memv = memoryview(octets[1:]).cast(typecode)
return cls(memv) #❼
def __len__(self):
return len(self._components)
def __getitem__(self, index):
return self._components[index]
__match_args__ = ('x', 'y', 'z', 't') #new❶
def __getattr__(self, name):
cls = type(self) #new❷
try:
pos = cls.__match_args__.index(name) #new❸
except ValueError: #new❹
pos = -1
if 0 <= pos < len(self._components): #new❺
return self._components[pos]
msg = f'{cls.__name__!r} object has no attribute {name!r}' #new❻
raise AttributeError(msg)
def __setattr__(self, name, value):
cls = type(self)
if len(name) == 1: #❶
if name in cls.__match_args__: #❷
error = 'readonly attribute {attr_name!r}'
elif name.islower(): #❸
error = "can't set attributes 'a' to 'z' in {cls_name!r}"
else:
error = '' #❹
if error: #❺
msg = error.format(cls_name=cls.__name__, attr_name=name)
raise AttributeError(msg)
super().__setattr__(name, value) #❻
❶ 特别处理名称是单个字符的属性。
❷ 如果 name 在__match_args__ 中,就设置特殊的错误消息。
❸ 如果 name 是小写字母,就设置一个针对所有小写字母的错误消息。
❹ 否则,把错误消息设为空字符串。
❺ 如果错误消息不为空,就抛出 AttributeError。
❻ 默认情况:在超类上调用__setattr__方法,提供标准行为。
🚩
super()函数用于动态访问超类的方法,对Python这种支持
多重继承的动态语言来说,必须这么做。程序员经常使用这个函数
把子类方法的某些任务委托给超类中适当的方法,如示例 12-10 所示。
Vector 类第 4 版:哈希和快速等值测试
我们要再次实现 __hash__ 方法。加上现有的 __eq__ 方法,这会把
Vector 实例变成可哈希的对象。
归约函数(reduce、sum、any 和 all)把序列或有限的可
迭代对象聚合成一个结果。
我们已经知道,sum() 可以代替 functools.reduce(),下面说说它的
原理。reduce() 的关键思想是,把一系列值归约成单个值。reduce()
函数的第一个参数是一个接受两个参数的函数,第二个参数是一个可迭
代对象。假如有一个接受两个参数的函数 fn 和一个列表 lst。调用
reduce(fn, lst) 时,fn 首先会被应用到第一对元素上,即
fn(lst[0], lst[1]),生成第一个结果 r1。然后,fn 会被应用到 r1
和下一个元素上,即 fn(r1, lst[2]),生成第二个结果 r2。接着,
调用 fn(r2, lst[3]),生成 r3……直到最后一个元素,返回最后得
到的结果 rN。
使用 reduce 函数可以计算 5!(5 的阶乘)。
示例 12-11 计算整数 0~5 的累计异或的 3 种方式
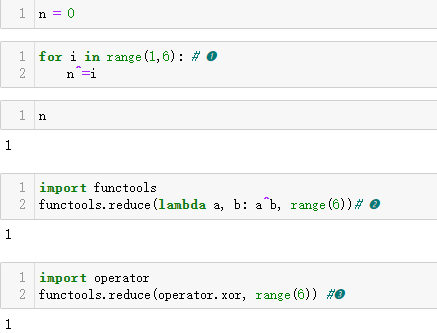
❶ 使用 for 循环和累加器变量计算聚合异或。
❷ 使用 functools.reduce函数,传入匿名函数。
❸ 使用 functools.reduce 函数,把 lambda 表达式换成operator.xor。
示例 12-12 vector_v4.py 的部分代码:在 vector_v3.py 中的
Vector 类的基础上导入两个模块,并添加 __hash__ 方法
from array import array
import reprlib
import math
import functools #❶
import operator #❷
class Vector:
typecode = 'd'
def __init__(self, components):
self._components = array(self.typecode, components)
def __iter__(self):
return iter(self._components)
def __repr__(self):
components = reprlib.repr(self._components)
components = components[components.find('['):-1]
return f'Vector({components})'
def __str__(self):
return str(tuple(self))
def __bytes__(self):
return (bytes([ord(self.typecode)]) +
bytes(self._components))
def __eq__(self, other): # ❸
return tuple(self) == tuple(other)
def __hash__(self):
hashes = (hash(x) for x in self._components)# ❹
return functools.reduce(operator.xor, hashes, 0) #❺
def __abs__(self):
return math.hypot(*self)
def __bool__(self):
return bool(abs(self))
@classmethod
def frombytes(cls, octets):
typecode = chr(octets[0])
memv = memoryview(octets[1:]).cast(typecode)
return cls(memv)
def __len__(self):
return len(self._components)
def __getitem__(self, index):
return self._components[index]
__match_args__ = ('x', 'y', 'z', 't')
def __getattr__(self, name):
cls = type(self)
try:
pos = cls.__match_args__.index(name)
except ValueError:
pos = -1
if 0 <= pos < len(self._components):
return self._components[pos]
msg = f'{cls.__name__!r} object has no attribute {name!r}'
raise AttributeError(msg)
def __setattr__(self, name, value):
cls = type(self)
if len(name) == 1:
if name in cls.__match_args__:
error = 'readonly attribute {attr_name!r}'
elif name.islower():
error = "can't set attributes 'a' to 'z' in {cls_name!r}"
else:
error = ''
if error:
msg = error.format(cls_name=cls.__name__, attr_name=name)
raise AttributeError(msg)
super().__setattr__(name, value)
❶ 为了使用 reduce 函数,导入 functools 模块。
❷ 为了使用xor函数,导入 operator 模块。
❸__eq__方法没有变化。这里把它列出来是为了将其和 __hash__ 方
法放在一起,因为它们要结合在一起使用。
❹ 创建一个生成器表达式,惰性计算各个分量的哈希值。
❺ 把 hashes 提供给 reduce 函数,使用 xor 函数计算聚合的哈希值。
第三个参数(0)是初始值(参见下面的“警告栏”)。
示例 12-12 实现的 __hash__ 方法是一种完美的映射归约(map-reduce)计算
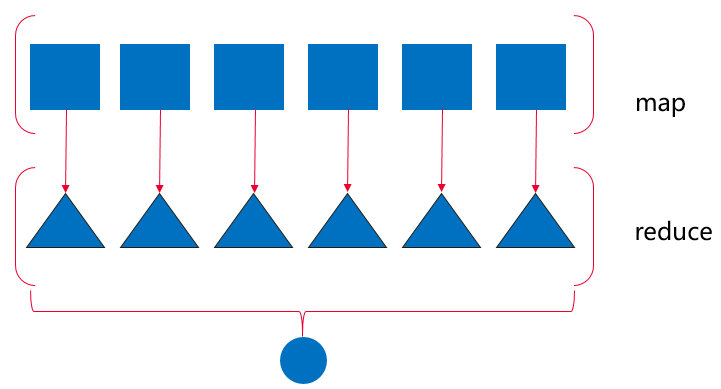
图 12-2:映射归约:把函数应用到各个元素上,生成一个新序列(映射),然后计算聚合值(归约)
示例 12-15 内置函数 zip 的使用示例

❶ zip 函数返回一个生成器,按需生成元组。
❷ 为了输出,构建一个列表。通常,我们会迭代生成器。
❸ 当一个可迭代对象耗尽后,zip 不发出警告就停止。
❹ itertools.zip_longest 函数的行为有所不同,它使用可选的
fillvalue(默认值为 None)来填充缺失的值,因此可以继续生
成元组,直到最后一个可迭代对象耗尽。
zip 函数还可以转置以嵌套的可迭代对象表示的矩阵。

为了避免在 for 循环中直接处理索引变量,还经常使用内置生成器
函数 enumerate。如果不熟悉这个函数,那么一定要阅读“Built-in functions”文档。
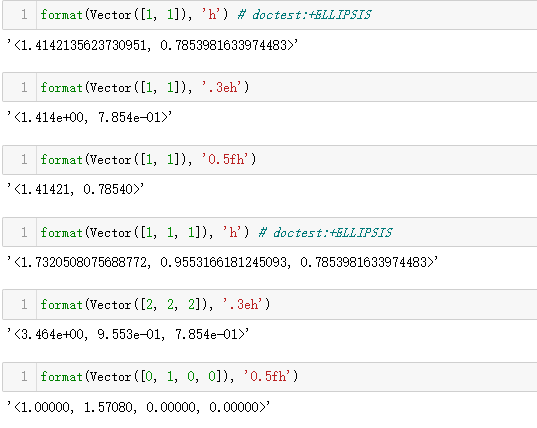
Vector 类第 5 版:格式化
Vector 类的 __format__ 方法类似于 Vector2d 类的方法,但是不使
用极坐标,而使用球面坐标(也叫“超球面”坐标),因为 Vector 类支
持 n 个维度,而超过四维后,球体变成了“超球体”。 因此,我们将把
自定义的格式后缀由 'p' 改成 'h'。
例如,对四维空间(len(v) == 4)中的 Vector 对象来说,'h' 代码
得到的结果如下:<r, Φ₁, Φ₂, Φ₃>,其中 r 是模(abs(v)),余下
3 个数是角坐标 Φ₁、Φ₂ 和 Φ₃。
示例 12-16 vector_v5.py:Vector 类最终版的 doctest 和全部代
码,带标号那几行是为了支持 __format__ 方法而添加的代码
示例 12-16 vector_v5.py:Vector 类最终版的 doctest 和全部代
码,带标号那几行是为了支持 __format__ 方法而添加的代码
一个多维Vector类,第5版
Vector实例使用数值可迭代对象构建::

测试二维向量(结果与vector2d_v1.py一样)::
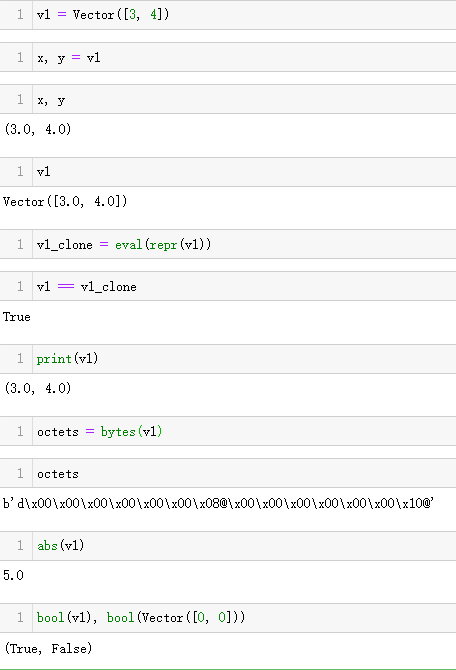
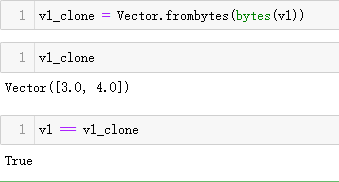
测试类方法.frombytes()::
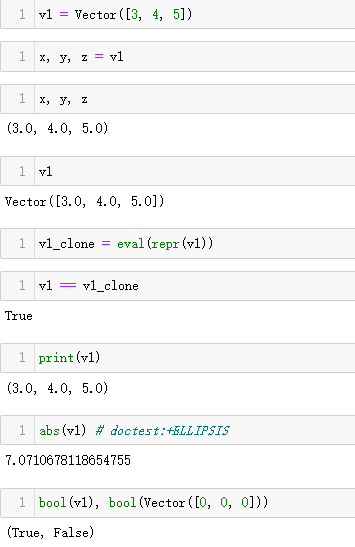
测试三维向量::
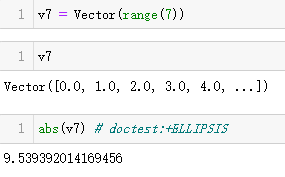
测试多维向量::
测试.__bytes__和.frombytes()方法::

测试序列行为::

测试切片::
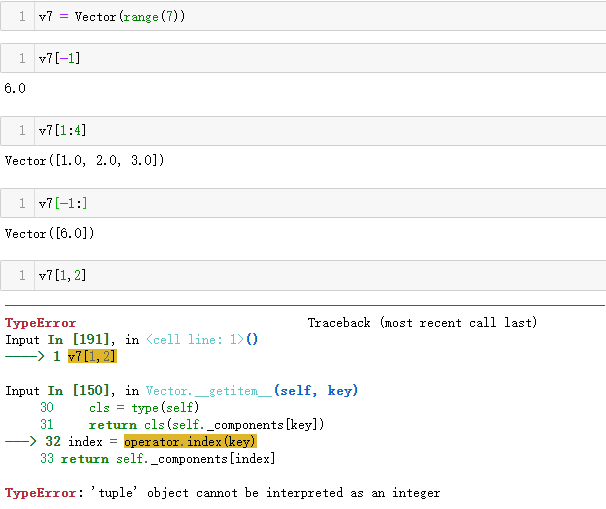
测试动态属性访问::

动态属性查找失败情况::
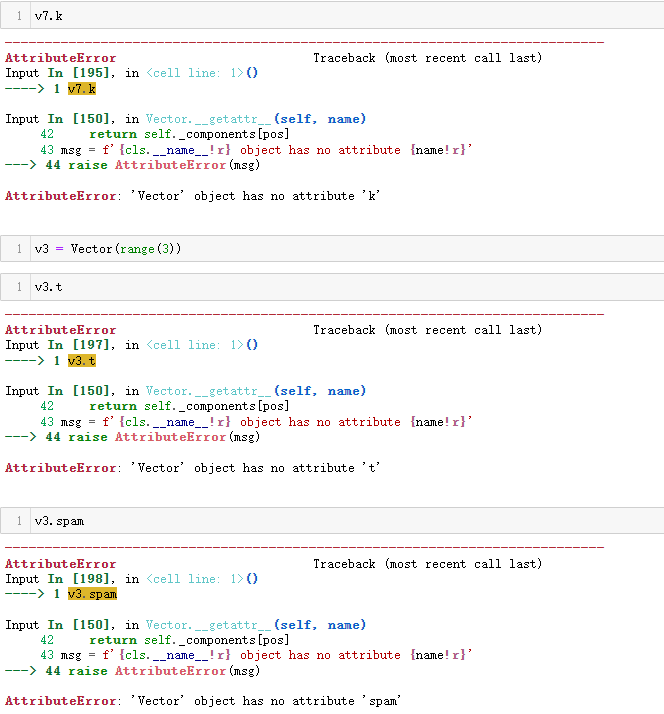
测试哈希::

大多数非整数的哈希码在32位和64位CPython中不一样::
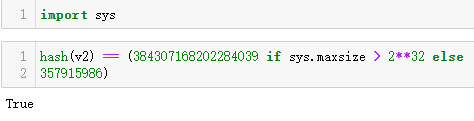
测试使用format()格式化二维笛卡儿坐标::

测试使用format()格式化三维和七维笛卡儿坐标::

测试使用format()格式化二维、三维和四维球面坐标::