

流畅的python--第十一章 符合 Python 风格的对象
一个库或框架是否符合 Python 风格,要看它能不能让 Python 程序
员以一种简单而自然的方式执行任务。—— Martijn Faassen Python 和 JavaScript 框架开发者
得益于 Python 数据模型,自定义类型的行为可以像内置类型那样自
然。实现如此自然的行为,靠的不是继承,而是鸭子类型:只需按照预
定行为实现对象所需的方法即可。
对象表示形式
每门面向对象语言至少都有一种获取对象字符串表示形式的标准方式。
Python提供了两种方式。
-
repr()
以便于开发者理解的方式返回对象的字符串表示形式。Python 控制
台或调试器在显示对象时采用这种方式。 -
str()
以便于用户理解的方式返回对象的字符串表示形式。使用print()
打印对象时采用这种方式。
除此之外,还有两个特殊方法(__bytes__和__format__)可为对象
提供其他表示形式。__bytes__方法与__str__方法类似,bytes()
函数调用它获取对象的字节序列表示形式。而__format__方法供f字
符串、内置函数format()和str.format()方法使用,通过调用
obj.__format__(format_spec)以特殊的格式化代码显示对象的字符
串表示形式。本章将先讨论__bytes__方法,随后再讨论__format__
方法。
再谈向量类
示例11-1 Vector2d 实例有多种表示形式, vector2d_v0.py文件
from array import array
import math
class Vector2d:
typecode = 'd' #❶
def __init__(self, x, y):
self.x = float(x) #❷
self.y = float(y)
def __iter__(self):
return (i for i in (self.x, self.y)) #❸
def __repr__(self):
class_name = type(self).__name__
return '{}({!r}, {!r})'.format(class_name, *self) #❹
def __str__(self):
return str(tuple(self)) #❺
def __bytes__(self):
return (bytes([ord(self.typecode)]) + #❻
bytes(array(self.typecode, self))) #❼
def __eq__(self, other):
return tuple(self) == tuple(other) #❽
def __abs__(self):
return math.hypot(self.x, self.y) #❾
def __bool__(self):
return bool(abs(self)) #❿
❶ typecode 是类属性,在 Vector2d 实例和字节序列之间转换时使用。
❷ 在 __init__ 方法中把 x 和 y 转换成浮点数,尽早捕获错误,以防
调用 Vector2d 构造函数时传入不当参数。
❸ 定义 __iter__ 方法,把 Vector2d 实例变成可迭代对象,这样才能
拆包(例如,x, y = my_vector)。这个方法的实现方式很简单,直
接调用生成器表达式依次产出分量。
❹ __repr__ 方法使用 {!r} 获取各个分量的表示形式,然后插值,构
成一个字符串。因为 Vector2d 实例是可迭代对象,所以 *self 会把 x
分量和 y 分量提供给 format 方法。
❺ 从可迭代的 Vector2d 实例中可以轻易得到一个元组,显示为有序对。
❻ 为了生成字节序列,把 typecode 转换成字节序列,然后……
❼ ……迭代 Vector2d 实例,得到一个数组,再把数组转换成字节序列。
❽ 为了快速比较所有分量,把运算对象转换成元组。对 Vector2d 实例
来说,虽然可以这样做,但仍有问题。参见下面的警告栏。
❾ 模是 x 分量和 y 分量构成的直角三角形的斜边长。
❿ __bool__ 方法使用 abs(self) 计算模,然后把结果转换成布尔
值,因此,0.0 是 False,非零值是 True。

❶ Vector2d 实例的分量可以直接通过属性访问(无须调用读值方法)。
❷ Vector2d 实例可以拆包成变量元组。
❸ Vector2d 实例的表示形式模拟源码构建实例的形式。
❹ 这里使用 eval 函数表明 Vector2d 实例的表示形式是对构造函数的准确表述。
❺ Vector2d 实例支持使用 == 比较,这样便于测试。
❻ print 函数调用 str 函数,对 Vector2d 来说,输出的是一个有序对。
❼ bytes 函数调用 __bytes__ 方法,输出实例的二进制表示形式。
❽ abs 函数调用 __abs__ 方法,返回 Vector2d 实例的模。
❾ bool 函数调用 __bool__ 方法,如果 Vector2d 实例的模为零,就
返回 False,否则返回 True。
备选构造函数
可以把 Vector2d 实例转换成字节序列了。同理,我们也希望能从
字节序列构建 Vector2d 实例。在标准库中探索一番之后,我们发现
array.array 有个类方法 .frombytes正好符合需求。
示例11-3 vector2d_v1.py 的一部分:这段代码只列出了
frombytes 类方法,要添加到 vector2d_v0.py(参见示例 11-2)定
义的 Vector2d 类中
@classmethod #❶
def frombytes(cls, octets): #❷
typecode = chr(octets[0]) #❸
memv = memoryview(octets[1:]).cast(typecode) #❹
return cls(*memv) #❺
❶ classmethod 装饰的方法可直接在类上调用。
❷ 第一个参数不是 self,而是类自身(习惯命名为 cls)。
❸ 从第一字节中读取 typecode。
❹ 使用传入的 octets 字节序列创建一个 memoryview,然后使用typecode 进行转换。
❺ 拆包转换后的 memoryview,得到构造函数所需的一对参数。
classmethod 与 staticmethod
先来看 classmethod。示例 11-3 展示了它的用法:定义操作类而不是
操作实例的方法。由于 classmethod 改变了调用方法的方式,因此接
收的第一个参数是类本身,而不是实例。classmethod 最常见的用途
是定义备选构造函数,例如示例 11-3 中的 frombytes。注
意,frombytes 的最后一行使用 cls 参数构建了一个新实例,即
cls(*memv)。
相比之下,staticmethod 装饰器也会改变方法的调用方式,使其接收
的第一个参数没什么特殊的。其实,静态方法就是普通的函数,只是碰
巧位于类的定义体中,而不是在模块层定义。示例 11-4 对
classmethod 和 staticmethod 的行为做了对比。
示例11-4 比较classmethod 和staticmethod的行为

❶ klassmeth 返回全部位置参数。
❷ statmeth 也返回全部位置参数。
❸ 不管怎样调用 Demo.klassmeth,它的第一个参数始终是 Demo 类。
❹ Demo.statmeth 的行为与普通的函数一样。
🚩
classmethod装饰器非常有用,但是我从未见过不得不使用
staticmethod的情况。有些函数即使不直接处理类,也与类联系
紧密,因此你会想把函数与类放在一起定义。对于这种情况,在类
的前面或后面定义函数,保持二者在同一个模块中基本上就可以了.
格式化显示
f 字符串、内置函数 format() 和 str.format() 方法会把各种类型的
格式化方式委托给相应的 .__format__(format_spec) 方
法。format_spec 是格式说明符,它是:
format(my_obj, format_spec)的第二个参数;{}内代换字段中冒号后面的部分,或者fmt.str.format()中的fmt。

❶ 格式说明符是'0.4f'。
❷ 格式说明符是'0.2f'。代换字段中的rate部分不属于格式说明
符,只用于决定把.format()的哪个关键字参数传给代换字段。
❸ 同样,格式说明符是'0.2f'。1 / brl表达式不属于格式说明符。
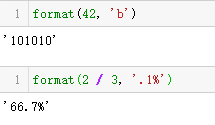
格式规范微语言为一些内置类型提供了专用的表示代码。例如,b和x
分别表示二进制和十六进制的int类型,f表示小数形式的float类
型,而%表示百分数形式。
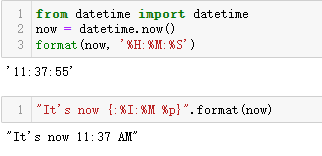
格式规范微语言是可扩展的,各个类可以自行决定如何解释
format_spec参数。例如,datetime模块中的类的__format__方法
所使用的格式代码与strftime()函数一样。下面是内置函数
format()和str.format()方法的几个示例。
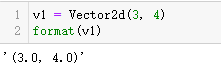
如果一个类没有定义__format__,那么该方法就会从object继承,
并返回str(my_object)。由于Vector2d类有__str__方法,因此可以这样做。
可哈希的Vector2d
按照定义,目前 Vector2d 实例不可哈希,因此不能放入集合中。
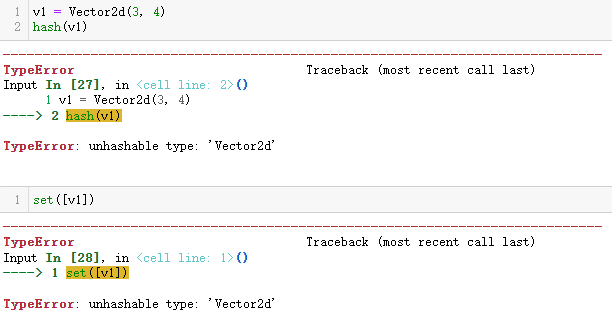
为了把 Vector2d 实例变成可哈希的,必须实现 __hash__ 方法(还需
要 __eq__ 方法,前面已经实现了)。此外,还要让向量实例不可变。
目前,可以为分量赋新值(例如 v1.x = 7),Vector2d 类的代码并
不阻止这么做。而我们想要的行为如下所示。

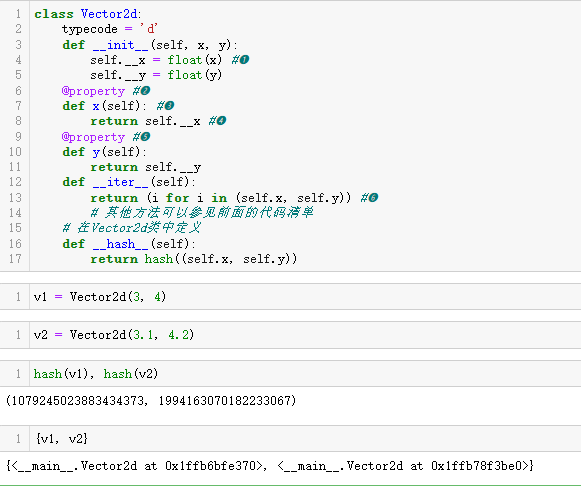
示例 11-7 vector2d_v3.py:这里只给出了让 Vector2d 不可变的代码,完整的代码清单见示例 11-11。
class Vector2d:
typecode = 'd'
def __init__(self, x, y):
self.__x = float(x) #❶
self.__y = float(y)
@property #❷
def x(self): #❸
return self.__x #❹
@property #❺
def y(self):
return self.__y
def __iter__(self):
return (i for i in (self.x, self.y)) #❻
# 其他方法可以参见前面的代码清单
❶ 使用两个前导下划线(尾部没有下划线或有一个下划线),把属性标记为私有的。
❷ @property 装饰器把读值方法标记为特性(property)。
❸ 读值方法与公开属性同名,都是 x。
❹ 直接返回 self. x。
❺ 以同样的方式处理 y 特性。
❻ 需要读取 x 分量和 y 分量的方法可以保持不变,仍然通过 self.x 和
self.y 读取公开特性,而不必读取私有属性,因此该代码清单省略了这个类余下的代码。
现在,向量不会被意外修改,有了一定的安全性,接下来可以实现
__hash__ 方法了。这个方法应该返回一个 int 值,理想情况下还要考
虑对象属性的哈希值(__eq__ 方法也是如此),因为相等的对象应该
具有相同的哈希值。特殊方法 __hash__ 的文档建议根据元组的分量计
算哈希值,如示例 11-8 所示。
示例 11-8 vector2d_v3.py:实现 __hash__ 方法
🚩为了创建可哈希的类型,不一定要实现特性,也不一定要保
护实例属性,正确实现__hash__方法和__eq__方法即可。但
是,可哈希对象的值绝不应该变化,因此我们借机提到了只读特性。
支持位置模式匹配
目前,Vector2d 实例兼容关键字类模式。在示例 11-9 中,所有关键字模式都能按预期匹配。
示例 11-9 匹配 Vector2d 对象的关键字模式
def keyword_pattern_demo(v: Vector2d) -> None:
match v:
case Vector2d(x=0, y=0):
print(f'{v!r} is null')
case Vector2d(x=0):
print(f'{v!r} is vertical')
case Vector2d(y=0):
print(f'{v!r} is horizontal')
case Vector2d(x=x, y=y) if x==y:
print(f'{v!r} is diagonal')
case _:
print(f'{v!r} is awesome')
case Vector2d(_, 0):
print(f'{v!r} is horizontal')
示例 11-10 匹配 Vector2d 对象的位置模式(需要在 Python 3.10中操作)
def positional_pattern_demo(v: Vector2d) -> None:
match v:
case Vector2d(0, 0):
print(f'{v!r} is null')
case Vector2d(0):
print(f'{v!r} is vertical')
case Vector2d(_, 0):
print(f'{v!r} is horizontal')
case Vector2d(x, y) if x==y:
print(f'{v!r} is diagonal')
case _:
print(f'{v!r} is awesome')
__match_args__ 类属性不一定要把所有公开的实例属性都列出来。如
果一个类的 __init__ 方法可能有全都赋值给实例属性的必需的参数和
可选的参数,那么 __match_args__ 应当列出必需的参数,而不必列出
可选的参数。
第 3 版 Vector2d 的完整代码
前面一直在定义 Vector2d 类,不过每次只给出了部分片段。示例 11-
11 是整理后的完整代码清单,保存在 vector2d_v3.py 文件中,包含我在
开发时编写的 doctest。
示例 11-11 vector2d_v3.py:完整版
"""
一个二维向量类
>>> v1 = Vector2d(3, 4)
>>> print(v1.x, v1.y)
3.0 4.0
>>> x, y = v1
>>> x, y
(3.0, 4.0)
>>> v1
Vector2d(3.0, 4.0)
>>> v1_clone = eval(repr(v1))
>>> v1 == v1_clone
True
>>> print(v1)
(3.0, 4.0)
>>> octets = bytes(v1)
>>> octets
b'd\\x00\\x00\\x00\\x00\\x00\\x00\\x08@\\x00\\x00\\x00\\x00\\x00\\x00\\x10@'
>>> abs(v1)
5.0
>>> bool(v1), bool(Vector2d(0, 0))
(True, False)
测试类方法``.frombytes()``::
>>> v1_clone = Vector2d.frombytes(bytes(v1))
>>> v1_clone
Vector2d(3.0, 4.0)
>>> v1 == v1_clone
True
使用笛卡儿坐标测试``format()``::
>>> format(v1)
'(3.0, 4.0)'
>>> format(v1, '.2f')
'(3.00, 4.00)'
>>> format(v1, '.3e')
'(3.000e+00, 4.000e+00)'
测试``angle``方法::
>>> Vector2d(0, 0).angle()
0.0
>>> Vector2d(1, 0).angle()
0.0
>>> epsilon = 10**-8
>>> abs(Vector2d(0, 1).angle() - math.pi/2) < epsilon
True
>>> abs(Vector2d(1, 1).angle() - math.pi/4) < epsilon
True
使用极坐标测试``format()``::
>>> format(Vector2d(1, 1), 'p') # doctest:+ELLIPSIS
'<1.414213..., 0.785398...>'
>>> format(Vector2d(1, 1), '.3ep')
'<1.414e+00, 7.854e-01>'
>>> format(Vector2d(1, 1), '0.5fp')
'<1.41421, 0.78540>'
测试只读特性`x`和`y`::
>>> v1.x, v1.y
(3.0, 4.0)
>>> v1.x = 123
Traceback (most recent call last):
...
AttributeError: can't set attribute 'x'
测试哈希::
>>> v1 = Vector2d(3, 4)
>>> v2 = Vector2d(3.1, 4.2)
>>> len({v1, v2})
2
"""
from array import array
import math
class Vector2d:
__match_args__ = ('x', 'y')
typecode = 'd'
def __init__(self, x, y):
self.__x = float(x)
self.__y = float(y)
@property
def x(self):
return self.__x
@property
def y(self):
return self.__y
def __iter__(self):
return (i for i in (self.x, self.y))
def __repr__(self):
class_name = type(self).__name__
return '{}({!r}, {!r})'.format(class_name, *self)
def __str__(self):
return str(tuple(self))
def __bytes__(self):
return (bytes([ord(self.typecode)]) +
bytes(array(self.typecode, self)))
def __eq__(self, other):
return tuple(self) == tuple(other)
def __hash__(self):
return hash((self.x, self.y))
def __abs__(self):
return math.hypot(self.x, self.y)
def __bool__(self):
return bool(abs(self))
def angle(self):
return math.atan2(self.y, self.x)
def __format__(self, fmt_spec=''):
if fmt_spec.endswith('p'):
fmt_spec = fmt_spec[:-1]
coords = (abs(self), self.angle())
outer_fmt = '<{}, {}>'
else:
coords = self
outer_fmt = '({}, {})'
components = (format(c, fmt_spec) for c in coords)
return outer_fmt.format(*components)
@classmethod
def frombytes(cls, octets):
typecode = chr(octets[0])
memv = memoryview(octets[1:]).cast(typecode)
return cls(*memv)
Python 私有属性和“受保护”的属性
Python 不能像 Java 那样使用 private 修饰符创建私有属性,但是它有
一个简单的机制,能避免子类意外覆盖“私有”属性。
举个例子。有人编写了一个名为 Dog 的类,内部用到了 mood 实例属
性,但是没有将其开放。现在,你创建了 Dog 类的子类 Beagle。如果
你在毫不知情的情况下又创建了名为 mood 的实例属性,那么在继承的
方法中就会把 Dog 类的 mood 属性覆盖。这是难以调试的问题。
为了避免这种情况,如果以 __mood 的形式(两个前导下划线,尾部没
有或最多有一个下划线)命名实例属性,那么 Python 就会把属性名存
入实例属性 __dict__ 中,而且会在前面加上一个下划线和类名。因
此,对 Dog 类来说,__mood 会变成 _Dog__mood;对 Beagle 类来
说,__mood 会变成 _Beagle__mood。这个语言功能叫名称改写(name mangling)。
示例11-12 私有属性的名称会被“改写”,在前面加上_和类名

名称改写是一种安全措施,不能保证万无一失:它的目的是避免意外访
问,不能防止故意做错事。
Python 文档的某些角落把使用一个下划线前缀标记的属性称为“受保
护”的属性。 使用 self._x 这种形式的“保护”属性的做法很常见,但
很少有人把这种属性叫作“受保护”的属性。有些人甚至将其称为“私有”属性。
总之,Vector2d 的分量都是“私有”的,而且 Vector2d 实例都是“不可
变”的。我用了两对引号,因为并不能真正实现私有和不可变。
使用 __slots__ 节省空间
默认情况下,Python 把各个实例的属性存储在一个名为 __dict__ 的字
典中。3.9 节讲过,字典消耗的内存很多——即使有一些优化措施。但
是,如果定义一个名为 __slots__ 的类属性,以序列的形式存储属性
名称,那么 Python 将使用其他模型存储实例属性:__slots__ 中的属
性名称存储在一个隐藏的引用数组中,消耗的内存比字典少。下面通过
几个简单的示例说明一下,先看示例 11-13。
示例 11-13 使用 __slots__ 的 Pixel 类
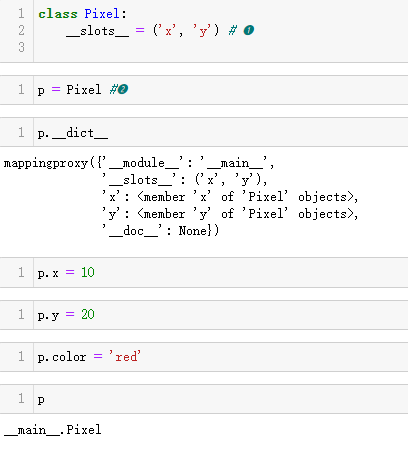
❶ __slots__ 必须在定义类时声明,之后再添加或修改均无效。属性
名称可以存储在一个元组或列表中,不过我喜欢使用元组,因为这可以
明确表明 __slots__ 无法修改。
❷ 创建一个 Pixel 实例,因为 __slots__ 的效果要通过实例体现。
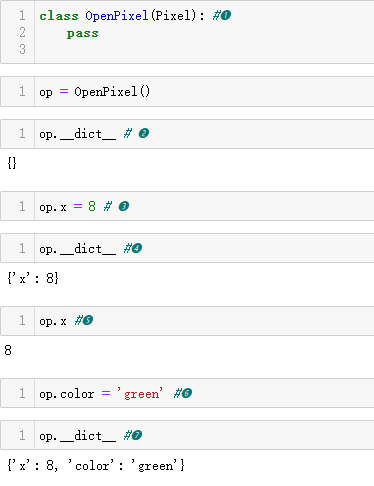
❶ OpenPixel 自身没有声明任何属性。
❷ 奇怪的事情发生了,OpenPixel 实例有__dict__ 属性。
❸ 即使设定属性 x(在基类 Pixel 的 __slots__ 属性中)……
❹ ……也不存入实例的 __dict__ 属性中……
❺ ……而是存入实例的一个隐藏的引用数组中。
❻ 设定不在 __slots__ 中的属性……
❼ ……存入实例的 __dict__ 属性中。
示例 11-14 表明,子类只继承 __slots__ 的部分效果。为了确保子类
的实例也没有 __dict__ 属性,必须在子类中再次声明 __slots__ 属性。
如果在子类中声明 __slots__ = ()(一个空元组),则子类的实例将
没有 __dict__ 属性,而且只接受基类的 __slots__ 属性列出的属性名称。如果子类需要额外属性,则在子类的 __slots__ 属性中列出来,如示
例 11-15 所示。
示例 11-15 ColorPixel 也是 Pixel 的子类
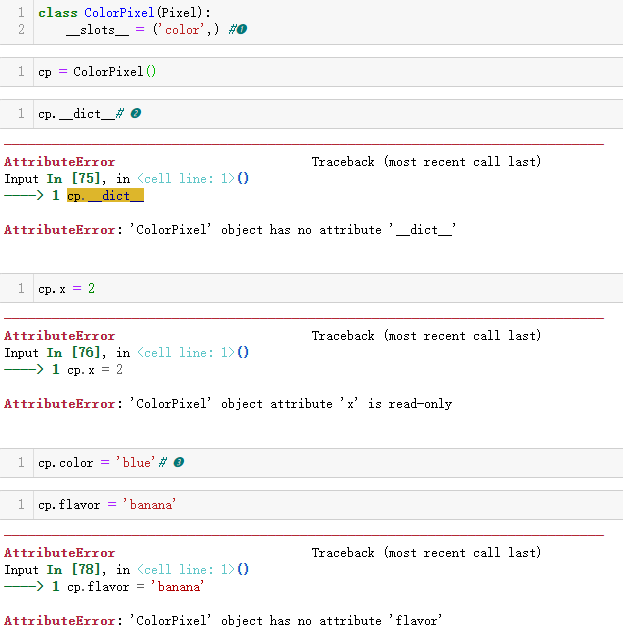
❶ 其实,超类的 __slots__ 属性会被添加到当前类的 __slots__ 属性
中。别忘了,只有一项的元组,因此在那一项后面要加上一个逗号。
❷ ColorPixel 实例没有 __dict__ 属性。
❸ 可以设定在当前类和超类的 __slots__ 中声明的属性,其他属性则不能设定。
简单衡量 __slots__ 节省的内存
示例 11-16 vector2d_v3_slots.py:只为 Vector2d 类增加
class Vector2d:
__match_args__ = ('x', 'y')# ❶
__slots__ = ('__x', '__y') #❷
typecode = 'd'
# 方法与前面的版本一样
❶ __match_args__ 列出位置模式匹配可用的公开属性名称。
❷ 而 __slots__ 列出的是实例属性名称。这里列出的是私有属性。
总结 __slots__ 的问题
如果使用得当,则类属性__slots__能显著节省内存,不过有几个问题需要注意。
- 每个子类都要重新声明
__slots__属性,以防止子类的实例有
__dict__属性。 - 实例只能拥有
__slots__列出的属性,除非把 'dict' 加入
__slots__中(但是这样做就失去了节省内存的功效)。 - 有
__slots__的类不能使用@cached_property装饰器,除非把
'dict' 加入__slots__中。 - 如果不把 'weakref' 加入
__slots__中,那么实例就不能作
为弱引用的目标。
覆盖类属性
Python 有一个很独特的功能:类属性可为实例属性提供默认
值。Vector2d 中有一个名为 typecode 的类属性。__bytes__ 方法两
次用到了这个属性,而且都故意使用 self.typecode 读取它的值。因
为 Vector2d 实例本身没有 typecode 属性,所以 self.typecode 默
认获取的是 Vector2d.typecode 类属性的值。
但是,如果为不存在的实例属性赋值,那么将创建一个新实例属性。假
如为 typecode 实例属性赋值,那么同名类属性将不受影响。然而,一
旦这样做,实例读取的 self.typecode 是实例属性 typecode,也就
是把同名类属性遮盖了。借助这个功能,可以为各个实例的 typecode
属性定制不同的值。
Vector2d.typecode 属性的默认值是 'd',即转换成字节序列时使用
8 字节双精度浮点数表示向量的各个分量。如果在转换之前把
Vector2d 实例的 typecode 属性设为 'f',那么将使用 4 字节单精度
浮点数表示各个分量,如示例 11-18 所示。
示例 11-18 设定原本从类中继承的 typecode 属性,自定义一个实例属性
>>> from vector2d_v3 import Vector2d
>>> v1 = Vector2d(1.1, 2.2)
>>> dumpd = bytes(v1)
>>> dumpd
b'd\x9a\x99\x99\x99\x99\x99\xf1?\x9a\x99\x99\x99\x99\x99\x01@'
>>> len(dumpd) ❶
17
>>> v1.typecode = 'f' ❷
>>> dumpf = bytes(v1)
>>> dumpf
b'f\xcd\xcc\x8c?\xcd\xcc\x0c@'
>>> len(dumpf) ❸
9
>>> Vector2d.typecode ❹
'd'
❶ 默认的字节序列长度为 17 字节。
❷ 把 v1 实例的 typecode 属性设为 'f'。
❸ 现在得到的字节序列是 9 字节长。
❹ Vector2d.typecode 属性的值不变,只有 v1 实例的 typecode 属性使用 'f'。
示例 11-19 ShortVector2d 是 Vector2d 的子类,只覆盖typecode 的默认值
>>> from vector2d_v3 import Vector2d
>>> class ShortVector2d(Vector2d): ❶
... typecode = 'f'
...
>>> sv = ShortVector2d(1/11, 1/27) ❷
>>> sv
ShortVector2d(0.09090909090909091, 0.037037037037037035) ❸
>>> len(bytes(sv)) ❹
9
❶ 把 ShortVector2d 定义为 Vector2d 的子类,只覆盖 typecode 类
属性。
❷ 为了演示,创建一个 ShortVector2d 实例,即 sv。
❸ 查看 sv 的表示形式。
❹ 确认得到的字节序列长度为 9 字节,而不是之前的 17 字节。
这也说明了在Vecto2d.__repr__方法中为什么没有硬编码
class_name 的值,而是使用 type(self).__name__ 获取,如下所
示。
# 在Vector2d类中定义:
def __repr__(self):
class_name = type(self).__name__
return '{}({!r}, {!r})'.format(class_name, *self)
如果硬编码 class_name 的值,那么仅为了修改 class_name 的
值,Vector2d 的子类(例如 ShortVector2d)就要覆盖 __repr__ 方
法。从实例的类型中读取类名,__repr__ 方法可以放心继承。
至此,本章通过一个简单的类说明了如何利用数据模型处理 Python 的
其他功能,包括提供不同的对象表示形式、实现自定义的格式代码、公
开只读属性,以及通过 hash() 函数支持集合和映射。
