

流畅的python--第三章
字典
示例3-1-1字典推导式
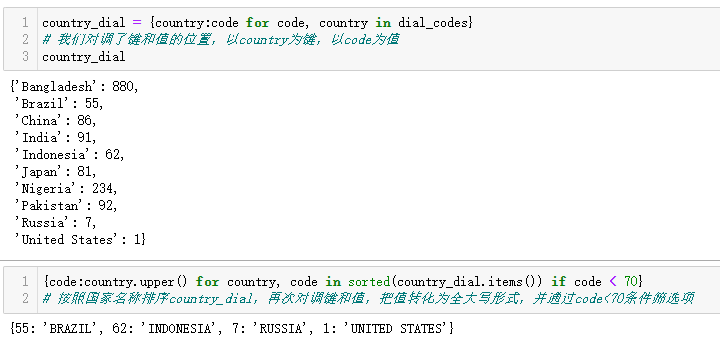
示例3-1-2映射拆包
在调用函数时,不止一个参数可以使用**。但是所有键都要是字符串,而且在所有参数中,是唯一的(因为关键字参数不可重复)。

示例3-1-3使用|合并映射
合并映射遵循重复键情况下后键覆盖前键的规律。

可哈希
如果一个对象的哈希码在整个生命周期内永不改变(依托__hash__()方法),而且可与其他对象比较(依托__eq__方法),那么这个对象就是可哈希的。
数值类型以及不可变的扁平类型str和bytes均是可哈希的。如果容器类型是不可变的,而且所含的对象全是可哈希的,那么容器类型自身也是可哈希的。 frozenset对象全部是可哈希的,因为按照定义,,每一个元素都必须是可哈希的。
仅当所有项均可哈希,tuple对象才是可哈希的。
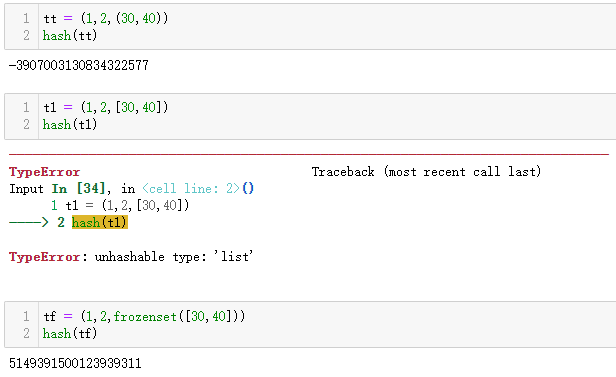
一个对象的哈希码根据所用的
Python版本和设备架构有所不同,如果出于安全考量而在哈希计算过程汇总加盐,那么哈希码也会发生变化。
插入或更新可变的值
根据python快速失败的原则,当键k不存在时,d[k]抛出错误。深谙python的人知道,如果觉得默认值比抛出KeyError更好,则可以使用d.get(k, default)。
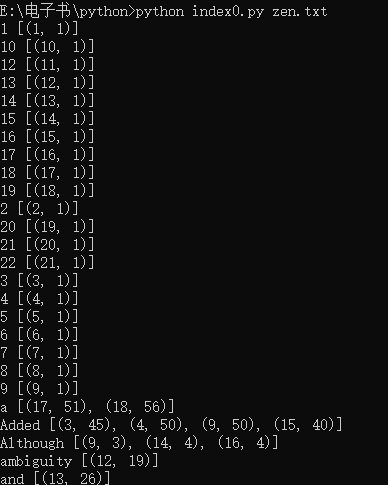
在目标目录编写脚本index0.py,即下面脚本。下载zen.txt放在目标目录。
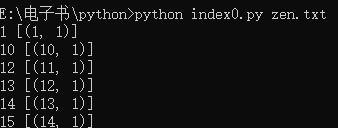
执行脚本:python index0.py zen.txt
import re
import sys
WORD_RE = re.compile(r'\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start() + 1
location = (line_no, column_no)
occurences = index.get(word, []) # 获取word出现的位置列表,如未找到,则返回[] ---1
occurences.append(location) # 把新找到的位置追加到occurrences ---2
index[word] = occurences # 把更新后的occurrences放入index字典 ---3
for word in sorted(index, key=str.upper): # sorted函数的key参数不是调用str.upper方法,而是传入那个方法的引用,供sorted函数排序各个词,规范化输出。
print(word, index[word])
结果显示:
注释1,2,3三行代码可以用一行替换
index.setdefault(word, []).append(location),获取word出现的位置列表,如未找到,则设为[],setdefault返回该列表,可以直接更新,不用再搜索一次。
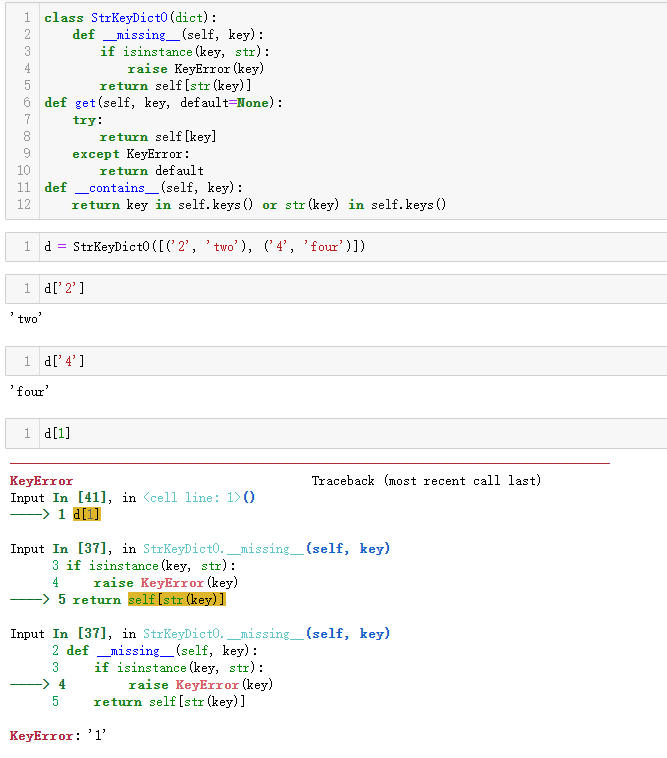
自动处理缺失的键
针对字典的键可能不存在,为了防止出现错误,会人为设置:第一种把普通的dict换为defaultdict;第二种是定义dict或其他映射类型的子类,实现__missing__方法。
import re
import sys
WORD_RE = re.compile(r'\w+')
index = collections.defaultdict(list) # 创建一个defaultdict对象,把default_factory设为list构造函数
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start() + 1
location = (line_no, column_no)
index[word].append(location) # 如果index中没有word键,则调用default_factory生成缺失的值。这里生成一个空列表,赋值给index[word
],然后返回空列表
# 按字母表顺序显示
for word in sorted(index, key=str.upper):
print(word, index[word])
__missing__方法
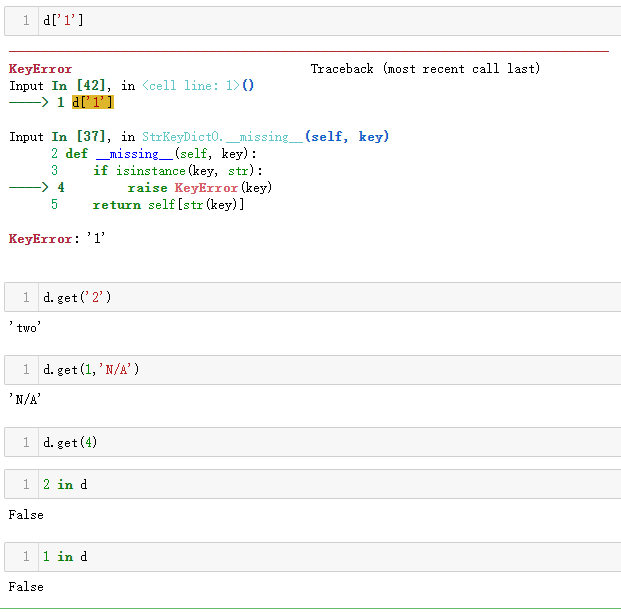
dict的变体
内置的dict也可以保留键的顺序。使用OrderedDict最主要原因是编写与早期Python版本兼容的代码。不过dict和OrderedDict之间还有一些差异。
OrderedDict的等值检查考虑顺序OrderedDict的popitem()方法签名不同,可通过一个可选参数指定移除哪一项。OrderedDict多了一个move_to_end()方法,便于把元素的位置移到某一端。- 常规的
dict主要用于执行映射操作,插入顺序是次要的 OrderedDict的目的是方便执行重新排序操作,空间利用率、迭代速度和更新操作的性能是次要的。- 从算法上看,
OrderedDict处理频繁重新排序操作的效果比dict好,因此适合用于跟踪近期存取情况(例如在LRU缓存中)
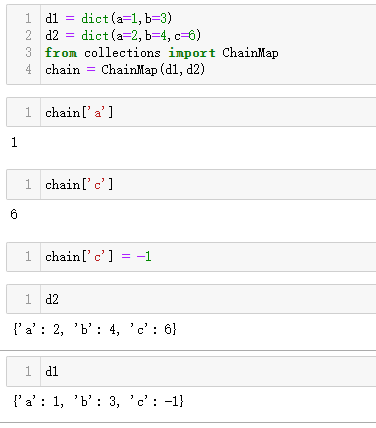
collections.ChainMap
ChainMap实例存放一组映射,可作为一个整体来搜索。查找操作按照输入映射在构造函数调用中出现的顺序执行,一旦在某个映射中找到指定的键,旋即结束。

ChainMap实例不复制输入映射,而是存放映射的引用。ChainMap的更新或插入操作只影响第一个输入映射。
collections.Counter
这是一种对键计数的映射。更新现有的键,计数随之增加。可用于统计
可哈希对象的实例数量.

不可变映射
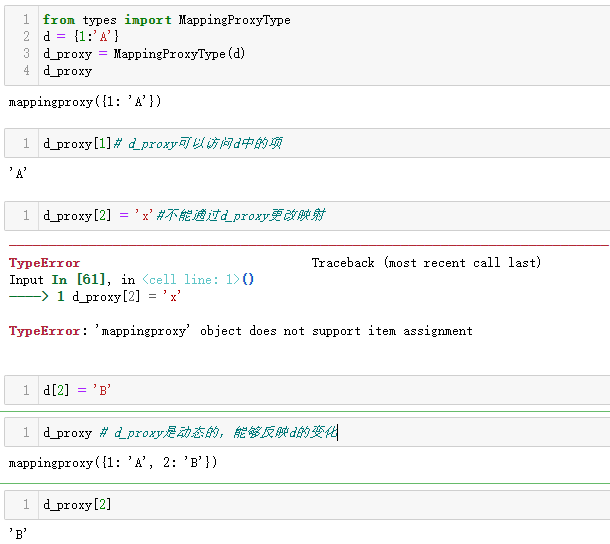
标准库提供的映射类型都是可变的,不过有时也需要防止用户意外更改映射。types模块提供的MappingProxyType是一个包装类,把传入的映射包装成一个mappingproxy实例,这是原映射的动态代理,只可读取。
这意味着,对原映射的更新将体现在mappingproxy实例身上,但是不能通过mappingproxy实例更改映射。
MappingProxyType根据dict对象构建只读的mappingproxy实例。
字典视图
dict的实例方法.keys()、.values()、和.items()分别返回dict_keys、dict_values和dict_items类的实例。这些字典视图是dict内部实现使用的数据结构的只读投影。
所有字典视图均支持的一些基本操作。

视图对象是动态代理。更新原dict对象后,现有视图立即就能看到变化。

集合论
集合是一组唯一的对象。集合的基本作用是去除重复项。

如果想去除重复项,同时保留每一项首次出现位置的顺序,那么现在使用dict即可.

集合元素必须是可哈希对象。set类型不可哈希,因此不能构建嵌套set实例的set对象。但是frozenset可以哈希,所以set对象可以包含frozenset元素。
除了强制唯一性之外,集合类型通过中缀运算符实现了许多集合运算。给定两个集合a和b,a|b计算并集,a&b计算交集,a-b计算差集,a^b计算对称差集。
set字面量
set字面量的句法与集合的数学表示法几乎一样,例如{1}、{1,2}等。唯一一点例外:空set没有字面量表示法,必须写作set()。

frozenset没有字面量句法,必须调用构造函数创建。

集合推导式
构建一个集合,元素为Unicode名称中带有“SIGN”一词的Latin-1字符。

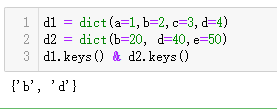
使用&运算符可以请以获取两个字典都有的键。
注意:
&运算符和|运算符均返回一个set

