

流畅的python学习笔记--第一章/第二章
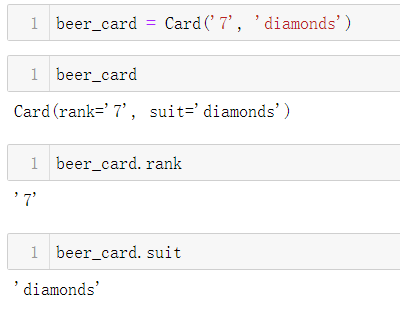
示例1-1 一摞有序的纸牌
知识点:
collections.namedtuple构建了一个简单的类,表示单张纸牌。
from collections import namedtuple
Card = namedtuple('Card', ['rank', 'suit'])
class FrenchDeck:
ranks = [str(n) for n in range(2,11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self): # 初始化
self._cards = [Card(rank,suit) for suit in self.suits for rank in self.ranks]
def __len__(self): # 总个数
return len(self._cards)
def __getitem__(self, position): # 获取元素
return self._cards[position]
- 使用
namedtuple构建只有属性而没有自定义方法的类对象。
- 实例化FrenchDeck类
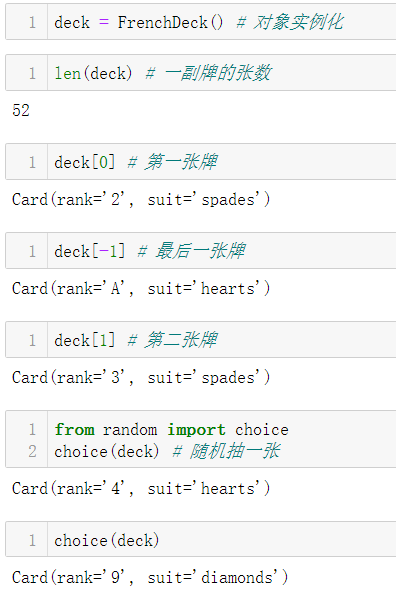
- 支持索引切片
由于__getitem__方法把操作委托给self._cards的[]运算符,一摞牌自动支持切片(slicing)。

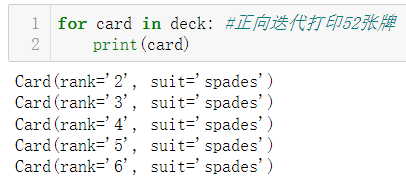
- 支持迭代索引

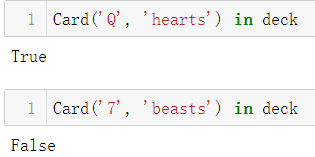
- 支持
in操作符
- 对牌进行排序
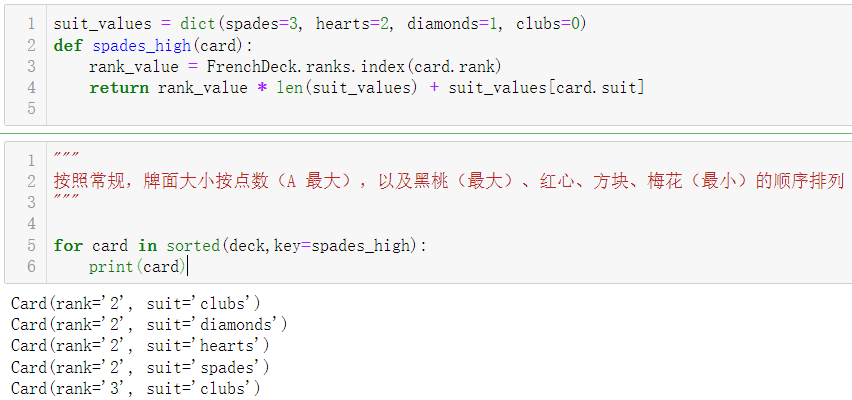
示例2-1 列表推导式和生成器表达式
使用列表推导式(目标是列表)或生成器表达式(目标是其他序列类型)可以快速构建一个序列。
很多python程序员把列表推导式简称为
listcomps,把生成器表达式简称为genexps。
2-1-1列表推导式
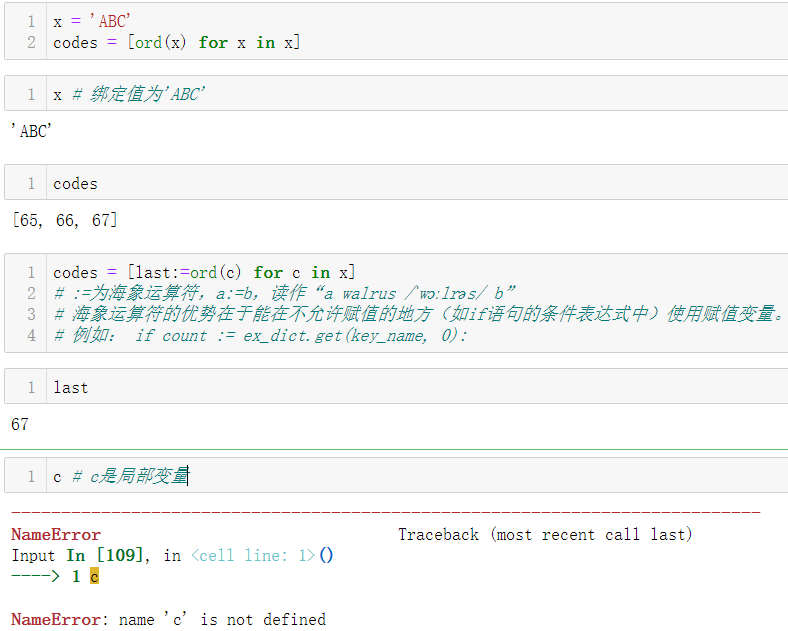
- 基于一个字符串构建一个Unicode码点列表(普通写法)

- 基于一个字符串构建Unicode码点列表(列表推导式写法)

python3中的列表推导式、生成器表达式,以及类似的集合推导式和字典推导式。for循环中赋值的变量在局部作用域内
2-1-2生成器表达式
虽然列表推导式也可以生成元组、数组或其他类型的序列,但是生成器表达式占用的内存更少,因为生成器表达式使用迭代器协议逐个产出项,而不是构建整个列表给其他构造函数。
生成器表达式的句法跟列表推导式几乎一样,只不过把方括号换成圆括号而已。
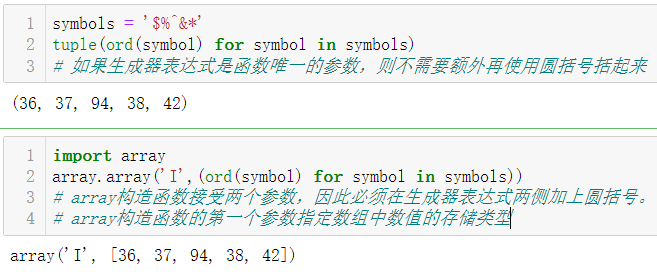
- 使用生成器表达式构建一个元组和一个数组
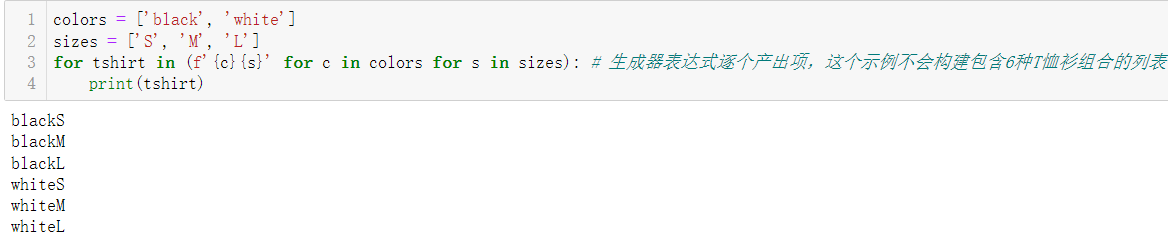
- 使用生成器表达式计算笛卡尔积
示例2-2 元组
元组不仅仅是不可变列表,还可以用作没有字段名称的记录。
2-2-1把元组当做记录使用
用元组存放记录,元组中的一项对应一个字段的数据,项的位置决定数据的意义。如果只把元组当做不可变列表,那么项数和项的顺序就变得可有可无。但是如果把元组当做容器使用,那么项数通常是固定的,顺序也变得十分重要。

2-2-2将元组用作不可变列表
python解释器和标准库经常把元组当做不可变列表使用,这么做主要有两个好处:
- 意图清晰
只要在源码中见到元组,就知道其长度不可变 - 性能优越
长度相同的元组和列表,元组占用内存更少
元组的不可变性仅针对元组中的引用而言。元组中的引用不可删除、不可替换。倘若引用的是可变对象,改动对象之后,元组的值也随之变化。
元组的内容自身是不可变的,但是这仅仅表明元组中存放的引用始终指向同一批对象。倘若引用的是可变对象,例如一个列表,那么元组的值就可能发生变化。
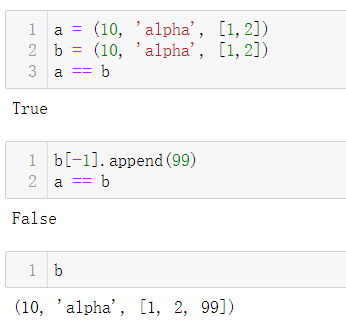
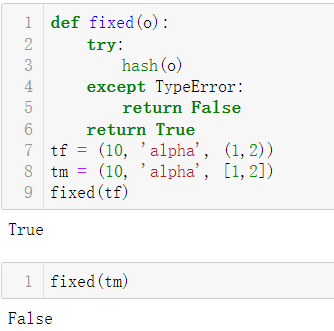
存放可变项的元组可能导致bug。只有值永不可变的对象才是可哈希的。不可哈希的元组不能作为字典的键,也不能作为集合的元素。
小结:
- python编译器求解元组字面量时,经过一次操作即可生成元组常量的字节码。求解列表字面量时,生成的字节码将每个元素当做独立的常量推入数据栈,然后构建列表
- 给定一个元组t,tuple(t)直接返回t的引用,不涉及复制。相比之下,给定一个列表l,list(l)创建l的副本
- tuple实例长度固定,分配的内存空间正好够用。而list实例的内存空间要富余一些,时刻准备追加元素
- 对元组中项的引用存储在元组结构体内的一个数组中,而列表把引用数组的指针存储在别处。二者不存储在同一个地方的原因是列表可以变长,一旦超出当前分配的空间,python就需要重新分配引用数组来腾出空间,而这会导致CPU缓存效率较低
示例2-3 序列和可迭代对象拆包
拆包的特点是不用我们自己动手通过索引从序列中提取元素,这样就减
少了出错的可能。拆包的目标可以是任何可迭代对象,包括不支持索引
表示法([])的迭代器。拆包对可迭代对象的唯一要求是,一次只能产
出一项,提供给接收端变量。不过也有例外,可以使用星号(*)捕获
余下的项。
最明显的拆包形式是并行赋值(parallel assignment),即把可迭代对象
中的项赋值给变量元组。
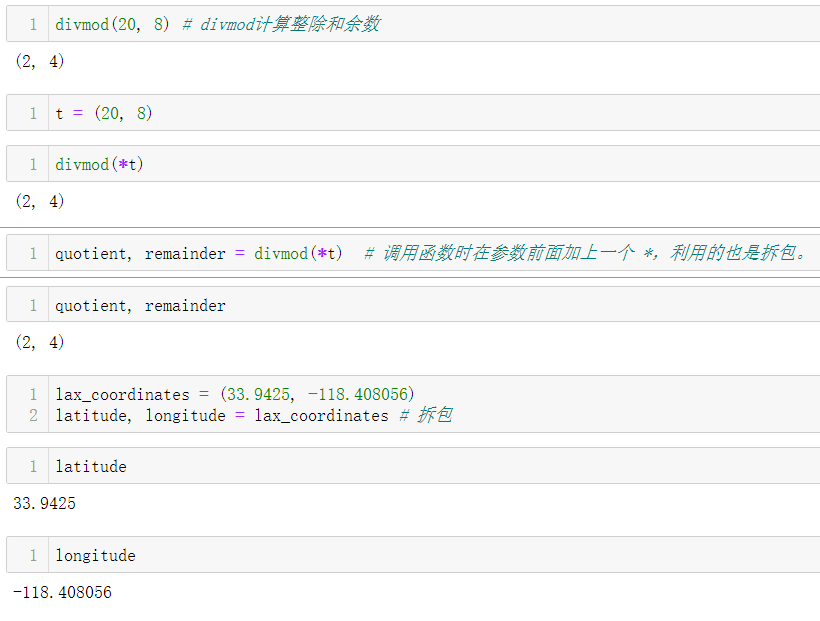
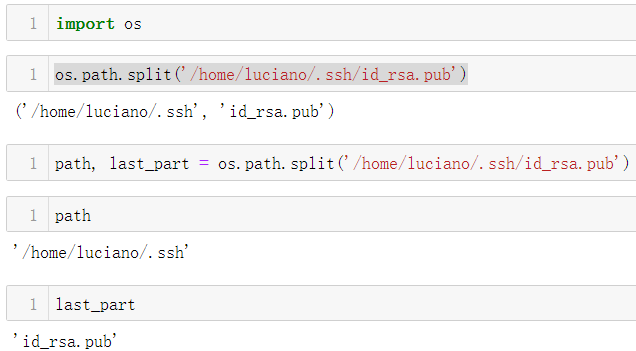
- 文件系统路径构成案例
2-3-1使用*获取余下的项
定义函数时可以使用 *args 捕获余下的任意数量的参数,这是 Python
的一个经典特性。
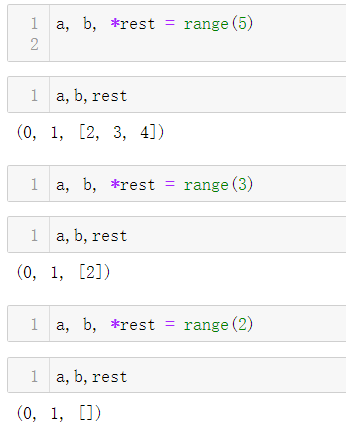

- 在函数调用和序列字面量中使用 *拆包
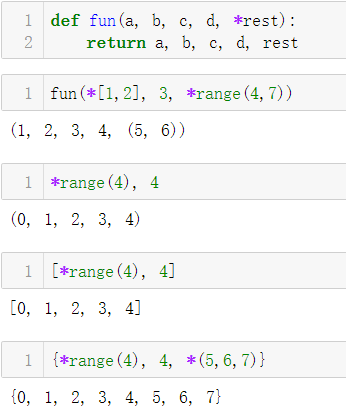
- 嵌套拆包
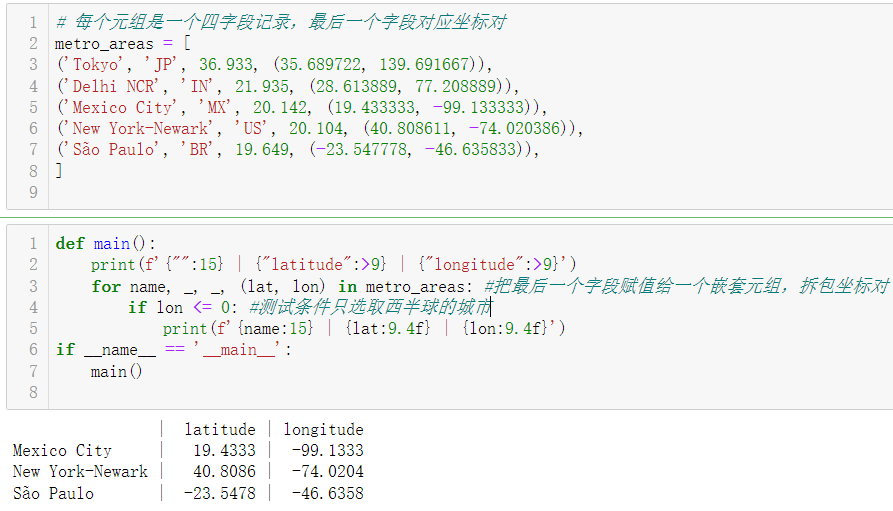
- 析构嵌套元组(要求python3.10及以上版本)

示例2-4 切片
切片和区间排除最后一项是一种python风格约定,这与python、C和很多其他语言索引从0开始相匹配。这样做的好处在于:
- 在仅指定停止位置时,容易判断切片或区间的长度。例如
range(3)和my_list[:3]都只产生3项。 - 同时指定起始和停止位置时,容易计算切片或区间的长度。做个减法即可:
stop - start。 - 方便在索引
x处把一个序列拆分成两部分而不产生重叠,直接使用my_list[:x]和my_list[x:]即可。

2-4-1切片对象
使用s[a:b:c]句法指定步长c,让切片操作跳过部分项。步距也可以是负数,反向返回项。

2-4-2为切片赋值
在赋值语句的左侧使用切片表示法,或者作为del语句的目标,可以就地移植、切除或以其他方式修改可变序列。

示例2-5 使用+和*处理序列
python程序员预期序列支持+和*操作。通常+的两个运算对象必须是同一种序列,而且都不可修改,拼接的结果是一个同类型的新序列。
如果想多次拼接同一个序列,可以乘以一个整数。同样,结果是一个新创建的序列。

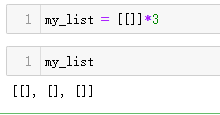
2-5-1构建嵌套列表
有时,我们需要初始化内部嵌套一定数量列表的列表,例如把学生分配到团队列表中,或者表示棋盘游戏中的方块。

2-5-2不能在一个列表3次引用同一个列表

2-5-3 使用增量赋值运算符处理序列
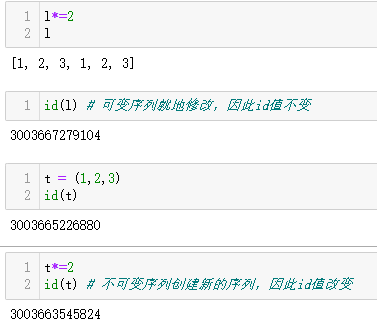
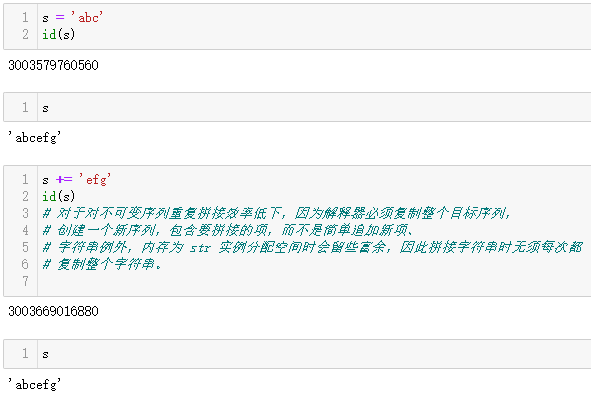
2-5-4 一个+=运算符赋值谜题
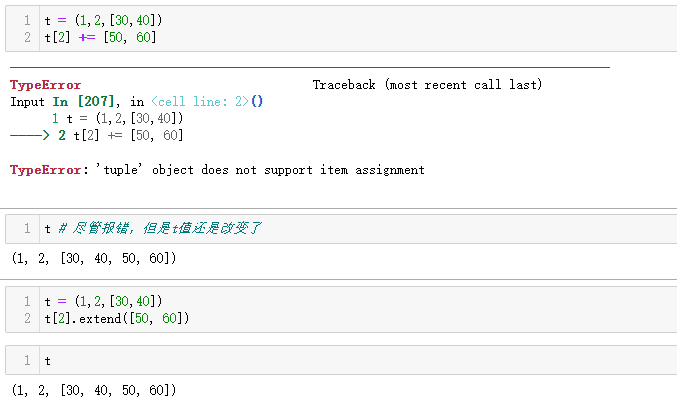
3个教训:
- 不要在元组中存放可变的项
- 增利赋值不是原子操作
- 检查python字节码可以看到背后操作
示例2-6 list.sort与内置函数
list.sort方法就地排序列表,不创建副本。返回值为None,目的是更改接收者,没有创建新列表。这是python API的一个重要约定:就地更改对象的函数或方法应该返回None,让调用方清楚地
知道接收者已被更改,没有创建新对象。例如:random.shuffle(s)函数混洗可变序列s,返回None。相比之下,
内置函数sorted返回创建的新列表。该函数接受任何可迭代对象作为参数,包括不可变序列和生成器。
list.sort和sorted均接受两个可选的关键字参数:
reverse
值为True时,降序返回项。默认是False,即升序key
一个只接受一个参数的函数,应用到每一项上,作为排序依据,例如,排序字符串时,key=str.lower执行不区分大小写排序,而key=len按字符长度排序各个字符串。默认值是恒等函数(即比较项本身).

使用
key参数,针对于掺杂数值和类似数值的字符串,也可以排序。只需要决定把所有项全都视为整数还是字符串。

示例2-7 数组
如果一个列表只包含数值,那么使用array.array会更加高效。数组支持所有可变序列操作(包括.pop、.insert、.extend),此外还有快速加载项和保存项的方法,例如.frombytes和.tofile。
Python数组像C语言数组一样精简。一个由float值构成的数组,存放的并不是完整的float实例,而是表示相应机器值的压缩字节,与C语言中由double值构成的数组如出一辙。创建array对象时要提供类型代码,它是一个字母
,用来确定底层使用什么C类型存储数组中各项。例如,类型代码b对应C语言中的signed char类型,即取值范围是-128~127的整数。如果使用array('b')创建一个数组,那么这个数组中的每一项都使用一个字节存储,而且均被
解释为整数。对于大型数值序列,这样做可以节省大量内存。另外python不允许向数组中添加与指定类型不同的值。
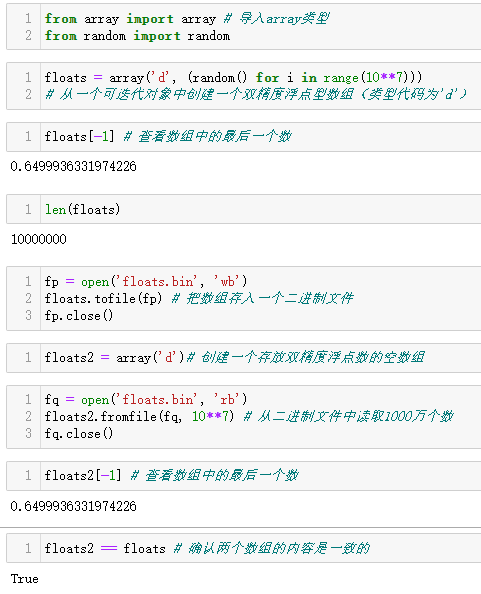
创建一个含有1000万个随机浮点数的数组,把这些浮点数存
入文件,再从文件中读取出来。
2-7-1 memoryview
内置的memoryview类是一种共享内存的序列类型,可在不复制字节的情况下处理数组的切片。memoryview是Numpy中一种普遍使用的结构,本质上就是Python中的数组(除去数学功能)。memoryview在数据结构(例如PIL图像、SQLite数据库、Numpy数组)
之间共享内存,而不是失陷复制。这对大型数据集来说非常重要。
memoryview.cast方法使用的表示法与array模块类似,作用是改变读写多字节单元的方式,无须移动位。memoryview.cast方法返回另一个memoryview对象,而且始终共享内存。
示例:分别以16、23、3*2矩阵的视图处理6字节内存。
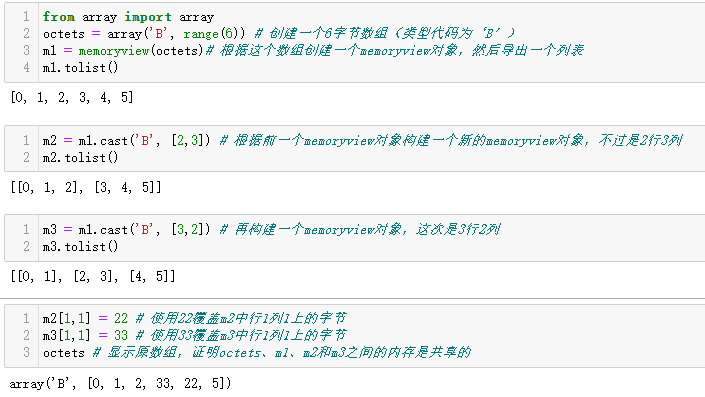
memoryview的强大功能也可用于搞破坏。
示例:如何修改一个16位整数数组中某一项的一个字节。

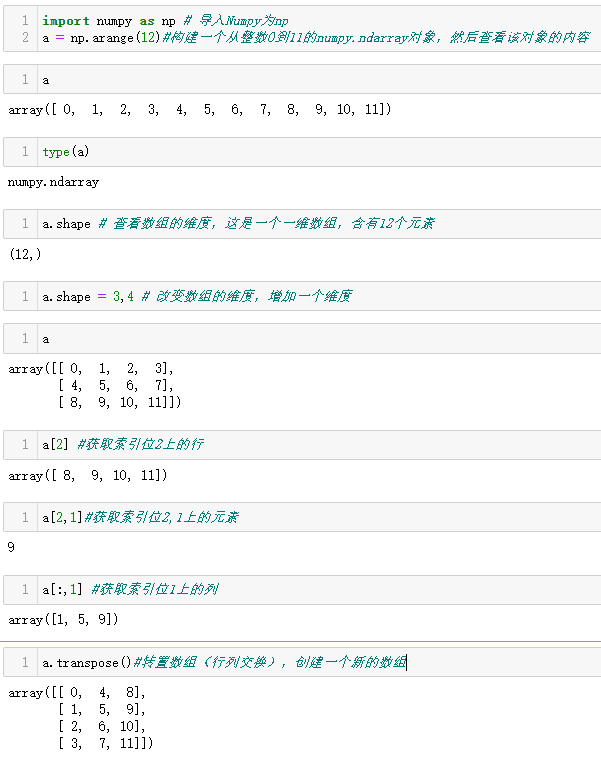
2-7-2 Numpy
科学计算经常需要做一些高级数组和矩阵运算,得益于Numpy,Python称为这一领域的主流语言。Numpy实现了多维同构数组和矩阵类型,除了存放数值之外,还可以存放用户定义的记录,而且提供了高效的元素层面操作。
在Numpy基础之上编写的Scipy库提供了许多科学计算算法,从线性代数到数值微积分和统计学,不一而足。Scipy速度快、运算可靠,因为它大量沿用了Netlib Repository的C语言和Fortran基准代码。换句话说,
Scipy为科学家提供了
两全其美的工具,既有交互式提示符,又有高级Python API,另外还通过了C语言和Fortran优化了工业级数值运算函数。

2-7-3 双端队列和其他队列
借助.append和.pop方法,列表可以当做栈或队列使用(.append和.pop(0)实现的是先进先出行为)。但是,在列表头部(索引位为0)插入和删除项有一定开销,因为整个列表必须在内存中移动。
collections.deque类实现一种线程安全的双端队列,旨在快速在两端插入和删除项。如果需要保留“最后几项”,或者实现类似的行为,则双端队列是唯一选择,因为deque对象可以有界,即长度固定。有界的deque对象填满之后,从一端添加新项,将从另一端丢弃一项。

注意:deque实现了多数list方法,另外增加了一些专用方法,例如popleft和rotate。不过这里隐藏了一个不太高效的操作:从deque对象中部删除项的速度不快。双端队列优化的是在两端增减项的操作。
append和popleft是原子操作(原子操作(atomic operation),指不会被线程调度机制打断的操作,这种操作一旦开始,就一直运行到结束,中间不会切换到其他线程。),
因此你可以放心地在多线程应用中把deque作为先进先出队列使用,无须加锁。

