

python语言编程能力
python语言编程能力
函数默认参数
实例1:
class Test(object):
def process(self,data=[]):
data.sort()
data.append("end")
return data
test1 = Test()
print(test1.process())//不会重新创建
test2 = Test()
print(test2.process())//不会重新创建
test3 = Test()
print(test3.process(data=["23","ew"]))//非空则重新创建
test4 = Test()
print(test4.process())//不会重新创建
结果输出:

等同于在
Test类第一次声明的时候,创建了Test.process.__defaults__对象,这个对象在类声明时候创建,创建后指向一个固定的ref。使用这个类创建对象,不会重新生成这个对象。如果参数是[],不会重新创建,如果非空则重新创建,
同时,默认参数不使用的时候不写成None违反编程规范8.1。
实例2:
def exten_list(val, List=[]):
print(f'info:{List},id:{id(List)}')
List.append(val)
return List
list1 = exten_list(10)
list2 = exten_list(20)
list3 = exten_list("a")
list4 = exten_list(14, [3])
list5 = exten_list("b")
print(f'info:{list1},id:{id(list1)}')
print(f'info:{list2},id:{id(list2)}')
print(f'info:{list3},id:{id(list3)}')
print(f'info:{list4},id:{id(list4)}')
结果输出:
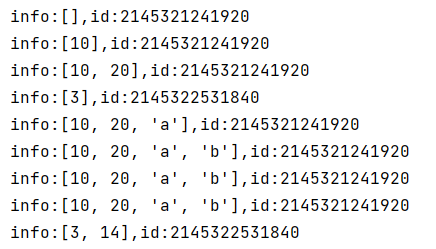
函数的参数默认值:只会在函数声明时初始化一次,之后不会再变;注意,函数声明,只有参数个数相同时,才是同一个声明,所以那些传入参数的调用,不是同一个函数声明了;只有缺省第二个参数的,才是同一类调用
装饰器(作用域)
函数装饰器的工作原理如下:
假设用funA()函数装饰器去装饰funB()函数,如下所示:
#funA 作为装饰器函数
def funA(fn):
#...
fn() # 执行传入的fn参数
#...
return '...'
@funA
def funB():
#...
等同于:
def funA(fn):
#...
fn() # 执行传入的fn参数
#...
return '...'
def funB():
#...
funB = funA(funB)
实例0:
#funA 作为装饰器函数
def funA(fn):
print("C语言中文网")
fn() # 执行传入的fn参数
print("http://c.biancheng.net")
return "装饰器函数的返回值"
@funA
def funB()://相当于funB = funA(funB)
print("学习 Python")
结果输出:

实例1:
def outer(f):
def inner(*arg, **kargs):
inner.co += 1
return f(*arg, **kargs)
inner.co = 0
return inner
@outer
def cu():
pass
if __name__ == "__main__":
cu()
cu()
cu()
print(cu.co)
结果输出:

return inner不等于return inner(),返回的是函数名,因此cu已经被inner替代了,最终cu.co=inner.co;万物皆对象,函数也是一个对象,因此函数这个对象本身可以访问属性,而且赋值时可以增加一个属性。不过实际意义不大
实例2:
#coding:gbk
def A(func):
def inner():
inner.i += 1
print("i加1,i={0}".format(inner.i))
inner.i = 0
print("i赋值")
return inner
@A
def B():
pass
@A
def C():
pass
B()//等价于B() = A(B()),执行inner():
B()
B()
C()
C()
print(id(B), id(B.i))
print(id(C), id(C.i))
结果输出:

B和C分别是俩对象,所以有两个id。(先是装饰器执行,有几个装饰器就执行几遍“i赋值”)
多层装饰器
实例1:
def dec_a(function):
print("aaa")//步骤4
def inner_func():
print("bbb")//步骤5
function()
return inner_func
def dec_b(function):
print("ccc") //步骤2
def inner_func():
function()
print("ddd")//步骤7
return inner_func
@dec_a //步骤3
@dec_b //步骤1
def test():
print("wegwrtegw")//步骤6
test()
结果输出:

装饰器
@等同于函数名从test变成了dec_a(dec_b(test)),执行test等同于执行dec_a.注意即便不执行test()方法,ccc/aaa还是会打印,因为先执行装饰器,从下向上,所以先打印ccc再打印aaa,说明装饰器是在解释器加载函数的时候就完成的。
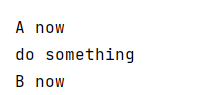
实例2:
def A(func):
def _A():
print ("A now")
func()
return _A
def B(func):
def _B():
func()
print ("B now")
return _B
@A
@B
def test1():
print ("do something")
test1()
结果输出:
re.match和re.search
实例1:
import re
result_sum = 0
pattern = 'back'
if re.match(pattern, 'backup.txt'):
result_sum += 1
if re.match(pattern, 'text.txt'):
result_sum += 2
if re.match(pattern, 'backup.txt'):
result_sum += 4
if re.match(pattern, 'backup.txt'):
result_sum += 8
print (result_sum)
结果输出:

实例2:
import re
sentence = 'we are humans'
matched = re.match(r'(.*)(.*)(.*)', sentence)
print (matched.group())
print (type(matched.group()))
结果输出:

实例3:
import re
p = re.compile('O')
s1 = ' OOOOOGood good study, day day up!OOOO '
a = re.sub(" ", 'i', s1, 3)
b = re.sub("O", 'i', s1, 6)
c = p.sub('i', s1, 6)
print(a)
print(b)
print(c)
结果输出:

实例4:
import re
a = "we are student"
a = re.match('(.*)(.*)(.*)', a)
print(a.groups())
print(a.group())
print(a.group(1))
结果输出:

python正则的几个重要函数
re.match(pattern, string, flag=0)从第一个字符开始比较re.search(pattern, string, flag=0)在字符串中查找,第一个字符可以不满足,等同于在re.match的正则表达式前加^.*?,匹配任意的开头re.sub(pattern, repl, string, count=0, flags=0),pattern表示正则表达式的模式字符串;repl被替换的字符串(既是字符串,也可以是函数);string要被替换的原字符串count匹配的次数matchObj.group()返回匹配的全部字符串matchObj.groups()返回匹配的字符串组m.group() == m.group(0) == 所有匹配的字符;m.groups() == (m.group(1), m.group(2) ...)
类的继承
继承用于类的创建上,新创建的叫子类,而被继承的叫做父类。子类可以使用父类属性,继承是描述类与类之间的关系。为什么要用继承呢?因为继承可以减少代码的冗余以及提高代码的重用性。在工作中,用到继承的地方很多。python里继承总共有单继承、多继承和多层继承。
- 单类继承:单继承指的是子类只继承一个父类
class A():
def __init__(self):
self.a = 'a'
def test_a(self):
print("aaaa")
class B(A):
def __init__(self):
self.b = 'b'
def test_b(self):
self.test_a()
print("bbbb")
obj = B()
obj.test_b()
结果输出:

B类只继承A类的方法。在B类中用self.test_a()即可调用A类的test_a()方法
- 多继承:多继承指的是子类继承了多个父类。
class A():
def __init__(self):
self.a = 'a'
def test_a(self):
print("aaaa")
class B():
def __init__(self):
self.b = 'b'
def test_b(self):
print("bbbb")
class C(A, B):
def __init__(self):
self.c = 'c'
def test_c(self):
self.test_a()
self.test_b()
obj = C()
obj.test_a()
obj.test_b()
obj.test_c()
结果输出:

C类就分别继承了A类和B类的方法。 多层继承就是指子类继承的父类也有继承别的类
- 子类重写父类方法
在某些场景下,子类继承了父类的属性和方法,但子类有同名的方法,这时候就需要重写子类的方法了。
class A():
def __init__(self):
self.a = 'a'
def test(self):
print("aaaa")
class B(A):
def __init__(self):
self.b = 'b'
super().__init__()
def test(self):
print("bbbb")
obj = B()
obj.test()
结果输出:
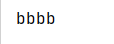
B类继承A类的属性和test()方法,但B也有test方法,那么只需要在B类中重新定义个test()方法即可
- 继承的注意事项及常见运用
- 子类如果重写了__init__方法,子类就不会自动继承父类__init__中的属性。如果要继承父类的属性,需要用到super方法,我们在B类的__init__方法中加上:
super(子类,self).__init__(参数0,参数1...) 父类名称.__init__(self,参数0,参数1...)
若继承父类的所有属性就直接用super().__init__()。
- 在调用基类方法时,需加上基类的类名前缀,并带上self参数变量。但在类中调用普通函数不需要带上self函数
实例:
class Demo:
def __check(self):
return "demo check"
def display(self):
print(self.__check())
class Demo1(Demo):
def __check(self):
return "deserv demo check"
Demo().display()
Demo1().display()
结果输出:

双下划线和单下划线区别:单下划线口头私有变量,双下划线真正私有,只有内部可以访问,外部不能访问
decimal四舍五入
import decimal
decimal.getcontext().rounding = decimal.ROUND_HALF_UP
a = decimal.Decimal('2.135').quantize(decimal.Decimal('0.00'))
b = decimal.Decimal('2.145').quantize(decimal.Decimal('0.00'))
print(a)
print(b)
结果输出:

考察python处理数字的decimal类,计算机的二进制无法精确表达十进制的小数,因此float类型保存的实际上是某个十进制小数的最接近的二进制表达。因此计算机保存的浮点数和人类看到的浮点数有巨大的误差。Decimal类可以按照人类10进制的习惯进行精确的浮点数运算,代价是使用字符串保存浮点数,性能比浮点降低很多。
decimal四舍五入
round四舍五入,而是四舍六入五成双(与python版本相关的)
例如:a.bcd
如果d小于5,直接舍去
如果d大于5,直接进位
如果d等于5:
d后面没有数据,且c为偶数,那么不进位,保留c
d后面没有数据,且c为奇数,那么进位,c变成(c + 1)
如果d后面还有非0数字,例如实际上小数为a.bcdef,此时一定要进位,c变成(c + 1)
ROUND_CEILING (趋向正无穷),
ROUND_FLOOR (趋向负无穷),
ROUND_HALF_DOWN (五舍六入),
ROUND_HALF_EVEN (四舍六入,5趋向最接近的偶数),
ROUND_HALF_UP (传统的中式的四舍五入)
ROUND_UP (远离0).
ROUND_DOWN (趋向0),
ROUND_05UP (四舍六入,5保留)
strip函数
string.strip(s[, chars])
Return a copy of the string with leading and trailing characters removed.
实例:
a = " yyx xxwyyefwyy "
print(a.strip().strip('yy'))
print(a)
结果输出:
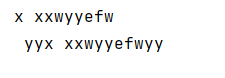
list创建 浅拷贝
l1 = [[1, 2], [3, 4], [5, 6]]
l2 = list(l1) # list函数返回值是一个新创建的list. If iterable is passed as a parameter, it creates a list consisting of iterable's items.
l3 = l1.copy() # 浅拷贝
l3[1][0] = 7
print(l1)
print(l2)
print(l3)

类继承__new__和__init__
实例1:
class A:
def __new__(self):
print("A __new__ ")
return object.__new__(self)
def __init__(self):
print("A __init__ ")
class B(A):
def __new__(self):
print("B __new__ ")
def __init__(self):
print("B__init__ ")
def main():
obj1 = B()
obja = A()
main()
结果输出

__init__默认不会递归到父类中,可以使用super函数显示调用父类的__init__
python真正的构造函数是__new__,__new__方法会优先于初始化方法__init__被调用,一些需要优先__init__的操作可以写在__new__方法中。__new__方法用于创建对象并返回对象,创建的对象要为new对象,返回其他视为未返回对象。当返回对象时会自动调用__init__方法进行初始化。如果没有返回对象__init__不会被调用- 如果
__new__返回的是super(),则会调用父类的__new__方法,如果返回不是super则不会调用
实例2:
class Person(object):
def __new__(self, *args, **kwargs):
print("in __new__")
instance = object.__new__(self)
return instance
def __init__(self, name, age):
print("in __init__")
self._name = name
self._age = age
p = Person("wang", 33)
结果输出:

这个却同时运行了
__new__和__init__,因为返回了instance,才调用__init__
实例3:
class A(object):
def __new__(cls):
print("A 的__new__方法被执行")
return super().__new__(cls)
def __init__(self):
print("A 的__init__方法被执行")
class B(A):
def __new__(cls):
print("B 的__new__方法被执行")
return super().__new__(cls)
def __init__(self):
print("B 的__init__方法被执行")
b = B()
结果输出:

__new__方法优先于__init__,__init__默认不会递归到父类中,可以使用super函数显示调用父类的__init__
list format
sample_list = list('HELLO')
print('first={0[0]},third={0[2]}'.format(sample_list))
结果输出:

0表示占位第一个元素也就是sample_list=['H','E','L','L','O'],0[0]='H',0[2]='L'
函数作用域
n = 0
def f():
def inner():
nonlocal n
n = 2
n = 1
print(n)
inner()
print(n)
if __name__ == '__main__':
f()
print(n)
结果输出:

nonlocal关键字可以改变变量的作用域,只能使用在闭包场合,可以在函数内部修改函数外部的变量。
装饰器
class Parrot(object):
def __init__(self):
self._v = 100
@property
def v(self):
return self._v
@v.setter
def v(self, value):
if value < 0:
raise ValueError("dsfref")
self._v = value
@v.deleter
def v(self):
del self._v
p = Parrot()
del p.v
p.v = -1
print(p.v)
结果输出:
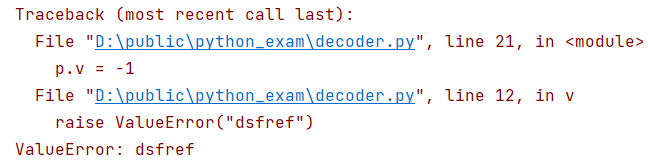
@property、@setter、@deleter装饰器用来将函数变成属性操作。本身这个属性的定义是不存在的,比如图中的v
实例2:
class Student():
def __init__(self):
self._score = 10000
@property
def score(self):
return self._score
@score.setter
def score(self, value):
if value < 0:
print (11111)
return
self._score = value
@score.deleter
def score(self):
del self._score
a = Student()
del a.score
a.score = -1
print (a.score)

builtins.AttributeError: 'Student' object has no attribute '_score'注:因为score()没有生效。
类属性继承
实例1:
class soam(object):
num_ins = 0
@classmethod
def count(cls):
cls.num_ins += 1
def __init__(self):
self.count()
class sun(soam):
num_ins = 0
class other(soam):
num_ins = 0
x = soam()
y1, y2 = sun(), sun()
z2, z3, z4 = other(), other(), other()
print(x.num_ins, y1.num_ins, z2.num_ins)
print(soam.num_ins, sun.num_ins, other.num_ins)
结果输出:

类也是一个对象,也可以有自己的属性。而且类本身也是callable的;类的属性不等同于对象的属性,通过classmethod装饰器,对象方法可以操作类的属性。
继承类的属性及其作用域,如果class other不自己定义num_ins,那么就会继承父类的属性。但是继承类自己定义了num_ins,内存地址发生了变化。
实例2:
class Base():
__a = "Base"
@classmethod
def display(cls):
print(cls.__a)
class Derived(Base):
__a = "Derived" # 私有变量只能函数内部使用
Base.display()
Derived.display()

实例3:
class A():
def __init__(self):
self._i = 1
self.j = 5
class B(A):
def __init__(self):
super().__init__()
self._i = 2
self.j = 7
x = B()
print(x._i, x.j)
print(x.__i, x.j)
结果输出:

Statiticmethod
class Spam:
numInstances = 0
@staticmethod
def count():
Spam.numInstances += 1
def __init__(self):
self.count()
class Sub(Spam):
numInstances = 0
class Other(Spam):
numInstances = 0
x = Spam()
y1, y2 = Sub(), Sub()
z1, z2, z3 = Other(), Other(), Other()
print(x.numInstances, y1.numInstances, z1.numInstances)
print(Spam.numInstances, Sub.numInstances, Other.numInstances)
结果输出:

一定要注意这里
staticmethod和class method的区别,staticmethod是通过类名索引。输出是完全不一样的
dict has_key
user = {'a': 'b', 'v': 'e'}
print(user.has_key('b'))
结果输出:

python2 False python3 报错,python3中语法改成了in或者not in
format迭代类型字典传参
sap_list = ['foo', 'bar']
print('{0} {1}'.format(*sap_list))
sap_list = 'foo', 'bar'
print('{0} {1}'.format(*sap_list))
sap_list = {'a': 'foo', 'b': 'bar'}
print('{a} {b}'.format(**sap_list))
结果输出:

元组的定义方法,可以没有括号,括号是可选的; 迭代类型和字典类型作为参数的写法,迭代类型args,字典类型**kargs,和**
元组定义
sap_list = ('a', 1)
print(sap_list)
sap_list = ('a', (1, 3))
print(sap_list[1])
sap_list = 'a', (1, 3)
print(sap_list[1])
结果输出:
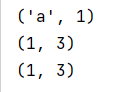
元组的定义方法,可以没有括号,括号是可选的
测试用例
#coding=utf-8
import unittest
class MyTest(unittest.TestCase):
@classmethod
def setUpClass(cls):
print("SETUPCLASS")
@classmethod
def tearDownClass(cls):
print("TEARDOWNCLASS")
def setUp(self):
print("SETUP")
def tearDown(self):
print("TEARDOWN")
def test_one(self):
print("TEST_ONE")
def test_two(self):
print("TEST_TWO")
if __name__ == '__main__':
unittest.main()
结果输出:

setUpClass在所有用例执行前都会执行。
setUp在左右用例前都会执行,但是要注意大小写,U和C都是大写。
tearDown是在左右用例后都会执行。
tearDownClass是用例结束后执行。
可迭代对象
如何实现一个对象可迭代
第一种,实现__iter__,通过yield生成迭代器
第二种,实现__iter__,返回自身,实现__next__
第三种,实现__getitems__,接收角标,返回元素
数组切片
x = "abcde" # [a:b:c] 表示 [a,b) 区间内 的 step为 c 的数集
print(x[::-2]) # eca 反向取值。从倒数第一个开始取,步长为2
print(x[1:2:1]) #
print(x[-3::]) # cde,第-3个值为c,后面全选
print(x[:-2]) # abc,结束值为第-2个值也就是d,从第0个位置到第d个位置(不包含d)
结果输出:

集合逻辑运算
a = {1,2,3,4,5}
b = {5,6}
print (a^b) # 对称差集,也就是说,不能同时在a和b里的元素
print (a&b) # 在a且在b里的
print (a|b) # 在a或在b里的
print (a-b) # 在a里不在b里的
结果输出:
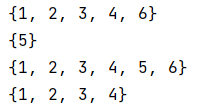
编程规范-异常处理
def d(a, b):
try:
res = a/b
print(1)
except ZeroDivisionError as e:
print(2)
except:
print(3)
finally:
print(4)
d(1,0)
结果输出:

finally一定会执行;except只有第一个捕获的会执行;这里第一个except捕获了ZeroDivisionError, 第二个except不会再捕获到错误
编程规范-变量命名
- 小写加下划线:包;模块;函数;方法;函数参数;变量
- 每个单词大写字母开头(CapWords):类;异常;
- 全大写,加下划线(CAPS_WITH_UNDER):常量;
- 下划线开头:类或对象的私有成员
编程规范-导入
导入模块,一行只导入一个
import sys
import os
编程规范-变量作用域
g1 = 1#全局变量
g2 = []
def f():
g1 = 2 #重新定义修改局部变量
g2.append(1) #因为是列表,f中是修改,而不是重新定义
f()
print(g1)
print(g2)
结果输出:
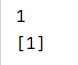
g1: 因为是数值,f中直接就重新定义了;
g2: 因为是列表,f中是修改,而不是重新定义,所以是对全局变量的修改;
如果这里重新定义,再修改,就是对局部变量的修改了,不会影响全局变量;
编程规范-空格布局
- 标点符号后面加空格
- 前后加空格:
- 算术:加、减、乘、取余
- 赋值:=、 +=
- 比较:>=、<=、==
- 逻辑:and、or
- 不加空格:
- 函数参数的等号:如func(a, b=None)
- 高优先级的乘法()、指数(**)x = x2 - 1
- 调用函数:result.write()
- 括号内侧:左括号后面、右括号的前面,不加空格
- 紧贴索引切块、函数后的括号左边不加空格:a[1]、fun(b)
编程规范-文档注释
文档注释,只有以下2个是正确的。易错。打断注释文本,单行小于72字符
""" Return a foobang
Optional plotz says to frobnicate the bizbaz first.
"""
"""API for interacting with the volume manager."""
编程规范-与None比较
- 与None比较:要用is 或 is not None
- 不要用==比较布尔值
编程规范-参数注释空格
特殊情况:参数注释时,冒号后面加空格;默认的参数等号前后也要空格
例如:
def munge(input: AnyStr): # AnyStr解释input
def munge() -> PosInt
实例:
# Yes:
def munge(sep: AnyStr = None): ...
def munge() -> AnyStr: ...
def munge(input: AnyStr, sep: AnyStr = None, limit=1000): ...
# No:
def munge(input: AnyStr=None): ...
def munge()->PosInt: ...
def munge(input: AnyStr, limit = 1000): …
# 这里有等号 def func(sep: AnyStr = None): ...
# 这里没有 def func(sep=None): ...
字典获取
字典获取:dict.get(key) 而不是 dict[key]容易出错
dic = {'a': 1, 'b': 3}
print(dic.get('a'))
print(dic['a'])
结果输出:

参数检查
参数检查用isinstance,不用type
isinstance是面向对象的描述,可以解决派生(继承)
type类似于java的class反射
for循环
用for I in iterable而不是for I in range(x)
迭代器不会立刻分配空间
死锁
死锁的必要条件
1)互斥条件:一个资源每次只能被一个事务使用
2)请求与保持:一个事务因请求资源而阻塞,对已获得的资源保持不放
3)不可剥夺条件:进程已获得的资源,在未使用完之前,不能强行剥夺
4)循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
产生死锁的原因主要是:
1)因为系统资源不足
2)进程运行推进的顺序不合适
3)资源分配不当等
性能优化
性能调优
需要频繁操作list的性能,预留好足够的空间,而不是不断的append
tuple代替list,来节约内存,并且小数量的tuple,python解释器会缓存
频繁调用的外部对象,用局部变量引用
import math
def afun(tan=math.tan):
for x in xrange(10000):
return tan(x)
用生成器表达式,代替list生成式,以节约内存
even_cnt = len([x for x in range(10) if x % 2 == 0])
改成
even_cnt = sum(1 for x in range(10) if x % 2 == 0)
深浅拷贝
import copy
a = [1, 2, ['x', 'y']]
b = a
c = copy.copy(a) # 对于list的第一层,是实现了深拷贝,但对于嵌套的list,仍然是浅拷贝。这其实很好理解,
# 内层的list保存的是地址,复制过去的时候是把地址复制过去了。嵌套的list在内存中指向的还是同一个
d = copy.deepcopy(a)
a.append(3)
a[2].append('z')
a.append(['x', 'y'])
print(a)
print(b)
print(c)
print(d)
结果输出:

__all__相关知识
在模块中定义了__all__之后,从外部from module import *只会import __all__中定义的内容。
有__all__未列出的属性,外部无法引用,错
设置了__all__,则内部属性无需_开头,错
python中防御会话固定攻击的办法
- 用户登录时生成新的Session ID. 如果攻击者使用的会话标识符不是有效的,那么这种方式将会非常有效。如果不是有效的会话标识符,服务器将会要求用户重新登录。如果攻击者使用的是有效的Session ID,那么还可以通过校验的方式来避免攻击。
- 大部分防止会话劫持的方法对会话固定攻击同样有效。如设置HttpOnly,关闭透明化Session ID,User-Agent验证,Token校验等
子进程
即便使用了shell=False 参数,subprocessor仍然可能会被命令注入。
check_output, check_call, popen call都是可以被注入的
这四个方法都是起子进程,区别是处理结果和异常的方式不一样,不影响是否会被命令注入
集合顺序
foo_dict = {"a": "foo", "b": "bar"}
print("{a} {b}".format(**foo_dict))
foo_tuple = "foo", "bar"
print("{0} {1}".format(*foo_tuple))
foo_list = ["foo", "bar"]
print("{0} {1}".format(*foo_list))
foo_set = {"foo", "bar"}
print("{0} {1}".format(*foo_set))
结果输出:

可变参数
关于可变参数*args和**kargs
在函数定义的位置顺序:位置参数 元组参数 字典参数
元组参数不拆包,元组作为单一个参数
字典不拆包,没法作为字典参数(易错)
def a(arg, *args, **dict):
print(arg)
print(args)
print(dict)
arg = 1
tuple = 1, 2
dict = {"a": "b"}
a(1, 1, 2, d='4', *tuple, q="b", **dict)
结果输出:

- 函数中同时存在元组参数与字典参数时,元组参数一定要放在字典参数前边。
- 只要是可变参数,一定要放在普通参数后边。
- 可变参数在函数调用时必须解封装后传递,否则函数内部会当做一个参数进行处理(无论元组或者字典)
编码与解码
编码就是编成字节码。字符串根据utf8编码encode为字节码,字节解码decode对应的字符串 。
有一个UTF-8编码的文件,需要转码成GBK编码的文件:decode(‘utf-8’) —> encode(‘gbk’)
for循环作用域
def create3():
return [lambda x, i=i:i*x for i in range(4)]
def create2():
return [lambda x: i*x for i in range(4)]
for m in create3():
print(m(2))
for m in create2():
print(m(2))
结果输出:

闭包
如果在一个内嵌函数里,对在外部函数内(但不是在全局作用域)的变量进行引用,那么内嵌函数就被认为是闭包(closure)。
定义在外部函数内但由内部函数引用或者使用的变量称为自由变量。
总结一下,创建一个闭包必须满足以下几点:
- 必须有一个内嵌函数
- 内嵌函数必须引用外部函数中的变量
- 外部函数的返回值必须是内嵌函数
flist = []
for i in range(3):
def func(x):
return x*i
flist.append(func)
for f in flist:
print(f(2))
结果输出:

unittest的testCase执行顺序
setUpClass() -> setUp() -> test1() -> tearDown() -> setUp() -> test2() -> tearDown() ->…-> tearDownClass
python四种数字类型
int/ long/ float/ complex
路径处理
os.path.abspath()该函数返回绝对路径,可以处理
import os
print(os.path.abspath('hello.py'))
结果输出:

序列相加相乘
print((1, 2) + (3, 4))
print((1, 2)*3)
print('abc'*3)
print(('abc')*3)
print(('abc',)*3)
结果输出:

python 链式比较
- 优先级 比较 高于 等于
- 比较:<= < > >=
- 等于:<= < > >=
print(4>3==3)
print(4>3 and 3==3)
结果输出:

正则表达式
import re
m = re.match('(\w\w\w)-(\d?)','abc-123')
print(m.group())
print(m.groups())
print(m.group(0))
print(m.group(1))
print(m.group(2))
结果输出:


