基于深度学习的恶意样本行为检测(含源码) ----采用CNN深度学习算法对Cuckoo沙箱的动态行为日志进行检测和分类
from:http://www.freebuf.com/articles/system/182566.html
0×01 前言
目前的恶意样本检测方法可以分为两大类:静态检测和动态检测。静态检测是指并不实际运行样本,而是直接根据二进制样本或相应的反汇编代码进行分析,此类方法容易受到变形、加壳、隐藏等方式的干扰。动态检测是指将样本在沙箱等环境中运行,根据样本对操作系统的资源调度情况进行分析。现有的动态行为检测都是基于规则对行为进行打分,分值的高低代表恶意程度的高低,但是无法给出类别定义。
本文采用CNN深度学习算法对Cuckoo沙箱的动态行为日志进行检测和分类尝试,分别测试了二分类和多分类方法,效果还有不小提升空间,希望共同交流。
0×02 现有技术
在大数据环境背景下,使用机器学习算法成为选择的趋势。相比手工分析,机器学习算法更加高效。目前已经有不少采用机器学习算法对样本动态行为进行检测的研究。Malheur由Konrad Rieck等人提出并给出了相应的开源实现,以样本中API出现的相对顺序作为特征向量,利用原型和聚类算法进行检测分析,该方法的缺点是特征向量过于稀疏,在高达几万维的特征向量中往往只有几十到几百维的特征值非零。
Radu等人采用随机森林算法检测恶意动态行为,根据API调用信息提取了68维的特征向量,对四类恶意样本进行了分类。该研究没有考虑白样本,适合在对样本黑白分类后进行恶意类别细分。Ivan等人用KNN,朴素贝叶斯,SVM,J48,MLP这5种算法进行了比较分析,不过其用于实验的总样本数只有470个,其结果的可靠性不是很高。笔者也用这些算法进行了实验,其结果没有论文中的数据那么好。
上述研究方法都采用了传统机器学习算法,利用手工分析获取特征向量进行分类处理,其结果受特征向量选取的影响极大。本文采用卷积神经网络(CNN)算法,借助CNN在自然语言处理方面的研究成果,进行样本的恶意动态行为检测。特点是不需要人工提取特征向量,具体的特征是算法根据样本的动态行为信息自行学习的。
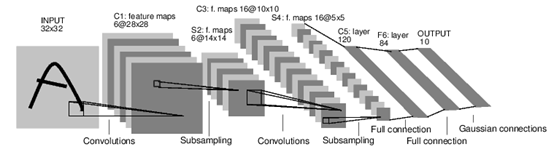
CNN即卷积神经网络,1998年Yann LeCun设计了用于手写数字识别的卷积神经网络LeNet-5,后经Hinton及其学生Alex Krizhevskyx修改,于2012年获得了ImageNet竞赛冠军。之后CNN就得到了广泛应用,检测结果十分优异。下图是经典卷积神经网络LeNet-5的网络结构,可以看到CNN主要包括卷积层,降采样层和全连接层等部分。本文采用CNN算法分别对样本的动态行为进行二分类和多分类。二分类表示只根据样本的动态行为判别样本是否为恶意的。多分类是指对于恶意样本还更详细的划分出恶意类别信息。后面给出具体的算法实现过程。
0×03 数据预处理
通过在沙箱运行样本,获取样本的动态行为报告。这里受限于两个条件:1)样本能跑出动态行为;2)该样本在VirtusTotal上能查询到对应结果。由于当前处于预研阶段,故先采用了部分样本进行试验。动态行为报告格式如下图。
 在实验过程中一共使用了7类共15921个样本。样本的分布如下表:
在实验过程中一共使用了7类共15921个样本。样本的分布如下表:
 对于每一个样本,其原始的动态行为报告是json结构数据。为了便于使用,将原始报告转为了如下图(a)所示的文本格式。每个样本的行为由一个txt文档表示,文档中的每一行表示一个api调用。每一行分为三个部分,由空格分隔。第一部分是api类型,对应原始report.json中的category字段;第二部分是调用的api名称;剩下部分是调用过程中的相关参数。在实际实验过程中发现,不考虑参数信息时算法效果更好,所以去除了动态行为的参数信息,如下图(b)。最终使用时对于相邻的重复api调用只考虑一次,相当于做了去重处理,如下图(c)。经过处理后每个样本的动态行为日志信息可以得到大幅度精简。
对于每一个样本,其原始的动态行为报告是json结构数据。为了便于使用,将原始报告转为了如下图(a)所示的文本格式。每个样本的行为由一个txt文档表示,文档中的每一行表示一个api调用。每一行分为三个部分,由空格分隔。第一部分是api类型,对应原始report.json中的category字段;第二部分是调用的api名称;剩下部分是调用过程中的相关参数。在实际实验过程中发现,不考虑参数信息时算法效果更好,所以去除了动态行为的参数信息,如下图(b)。最终使用时对于相邻的重复api调用只考虑一次,相当于做了去重处理,如下图(c)。经过处理后每个样本的动态行为日志信息可以得到大幅度精简。

经过格式转换后,动态行为检测问题就变成了对文本的分类问题。因此可以采用CNN在自然语言处理方面的方法。
0×04 算法实现
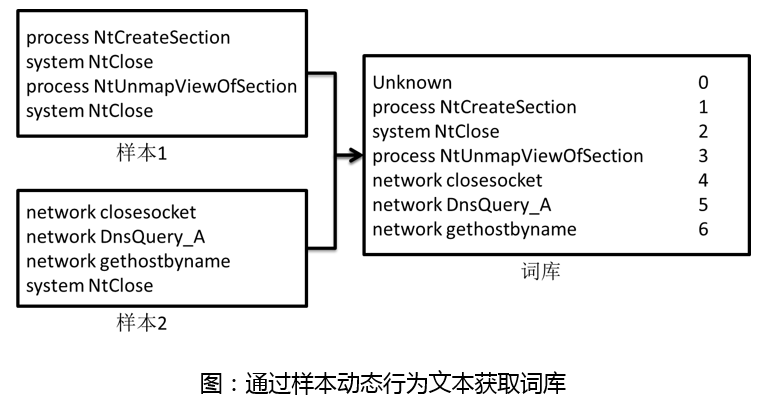
1. 获取词库
在动态行为文本中的每一行表示一个动态行为,将一行视为一个整体,遍历所有的动态行为日志,获取所有出现过的动态行为,作为词库。用连续数字对词库中的每一个词进行标号,这样可以获取动态行为到标号id的映射。注意,除了出现过的动态行为外,还另外添加了一个“Unknown”动态行为,用于之后匹配不在词库中的未知行为。下图是一个简单的例子,表示在一共只有两个样本的情况下,获取到的词库信息。
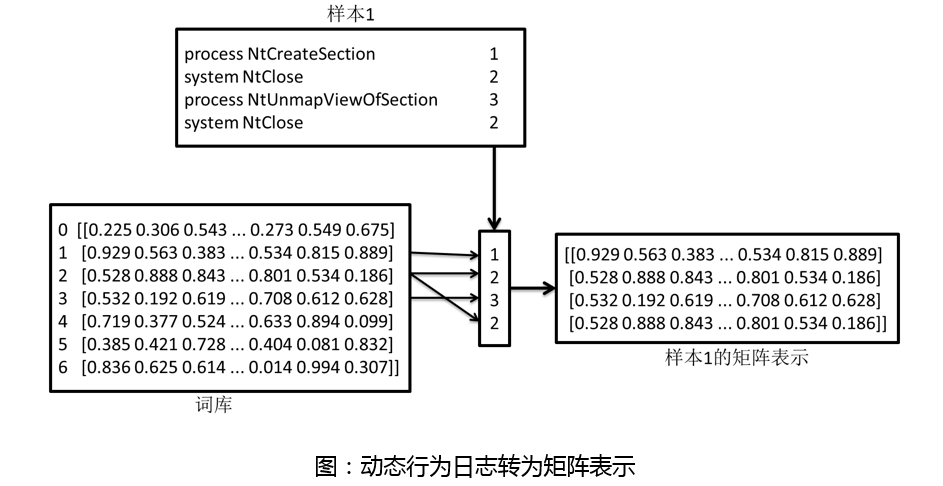
2. 将样本转为矩阵表示
CNN最初用于图像处理。在使用CNN进行文本分类时首先需要将文本转为类似图片的二维矩阵。为了实现文本的矩阵表示,先将词库中的每一个词用一个长度为300的向量表示,这个向量长度是一个可以选择的参数。初始化向量时采用随机初始化,之后会随着训练不断更新词向量。对于每一个样本,将样本中的动态行为根据词库转换为对应的id序列。再根据此id序列以及词库中每个id的向量将样本转换为二维矩阵。整体过程如下图所示。注意,在转换过程中需要制定最大词长度,以保证所有样本转换后的矩阵有相同的维度。对于长度不足的样本需要在最后进行补0,对于超长的样本,笔者尝试过用tf-idf分析处理,但实际效果并没有提升,所以这里采用直接截断。
3. 使用CNN训练样本
借用一张Ye Zhang等人论文中的流程图。对于输入的样本矩阵,分别用多个卷积核进行卷积。卷积核的长度可以是任意选择的,本文中使用的是(3, 4, 5),即使用了3个不同长度的卷积核。卷积核的宽度与词向量的长度相同。这样经过一次卷积操作后,原本的二维矩阵就会变成一个列向量。这种处理类似于N-Gram算法,取长度为3的卷积核其实就是对相邻的3个动态行为提取特征。每一种尺度的卷积核都可以有多个,图中每种尺度的卷积核有2个。本文实际使用时采用了128个。经过卷积后,再对每一个卷积结果使用max-pooling,取列向量中的最大值。这样每一个列向量就转变成了一个1×1的值。将所有卷积核结果对应的最大值连接在一起构成全连接层。最后用softmax进行多分类处理。

0×05 实验结果
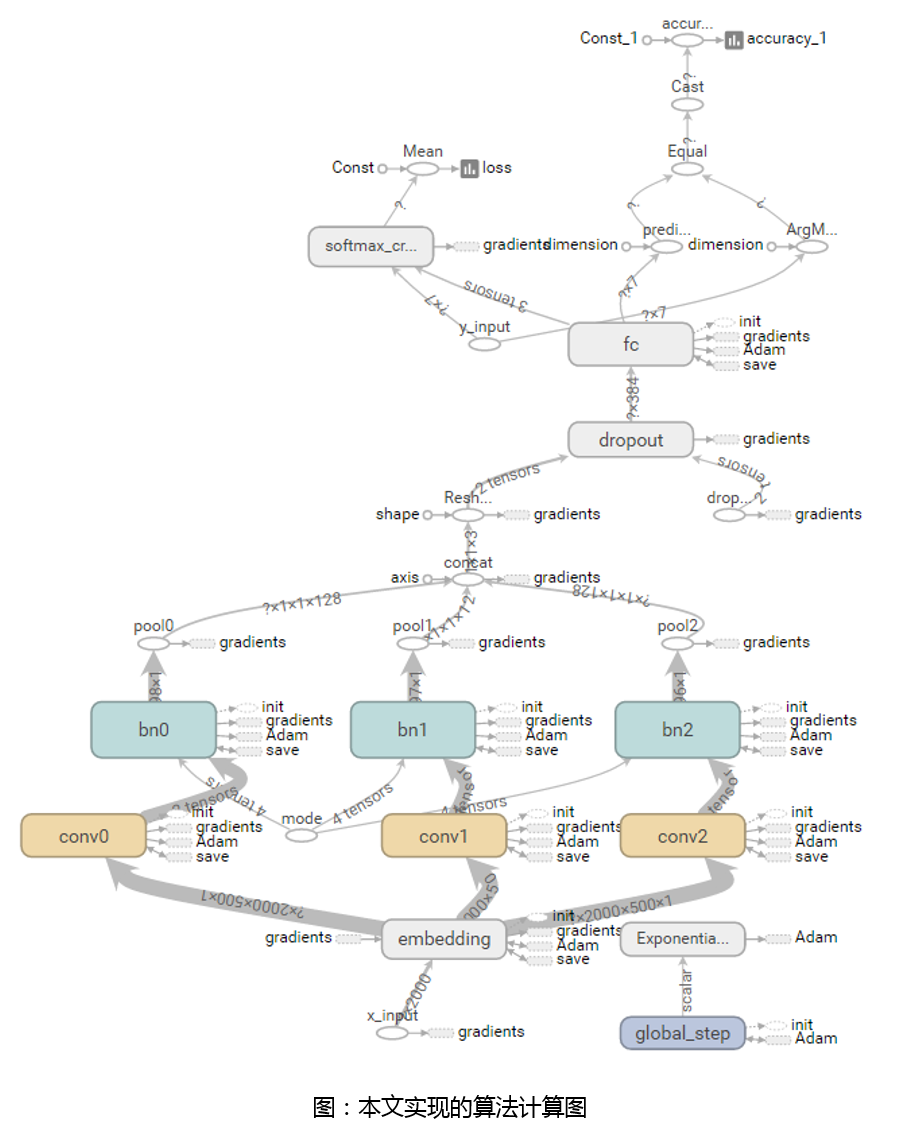
本文采用Tensorflow实现算法结构。整体流程的计算图如下图所示。Embedding是词嵌入部分,即将动态行为文本转换为二维,conv对应上面介绍的卷积操作,pool对应max-pooling,fc为全连接层,最后结果由softmax输出。在具体实现时还加入了batchnorm和学习速率指数衰减,用以加速学习和优化结果。注意图中有一个dropout层,但实际使用时keep_prob传入的是1.0,即并没有进行dropout。该层是在调试结果时使用的。
运行时采用80%的数据作为训练数据,20%的数据作为测试数据。每个batch大小为128,共迭代50轮,每轮需迭代99个batch,每训练200个batch统计一次模型在测试集上的效果。
分别测试了二分类和多分类效果。二分类是指只判断样本的行为是否为恶意的。多分类指将样本根据动态行为划分为数据预处理中提到的7类。
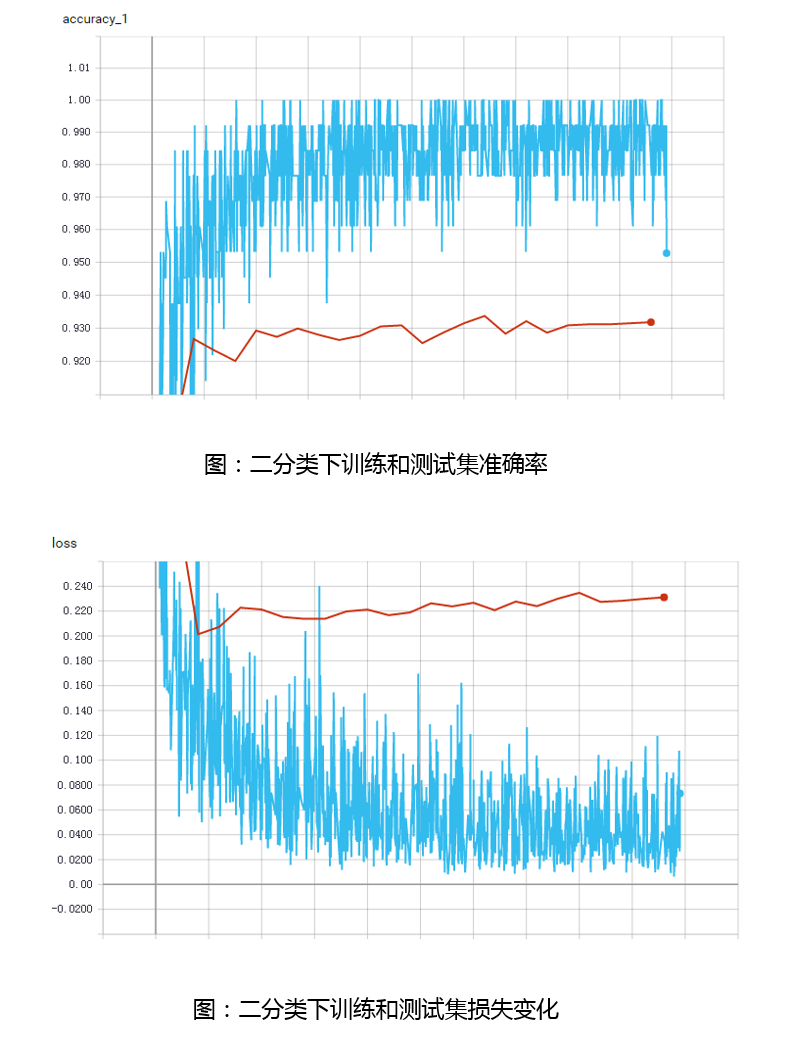
1. 二分类结果
只对样本的动态行为进行黑白分类。算法在训练集和测试集上的准确率和损失值如下图所示,蓝色线是训练集结果,红色线是测试集结果。可以看到结果在迭代1400个batch后趋于稳定。在训练集上,准确率在98%附近浮动,损失值在0.04附近浮动。在测试集上,准确率最高为93.37%,但是损失值在迭代400个batch后就开始发散,并没有收敛。
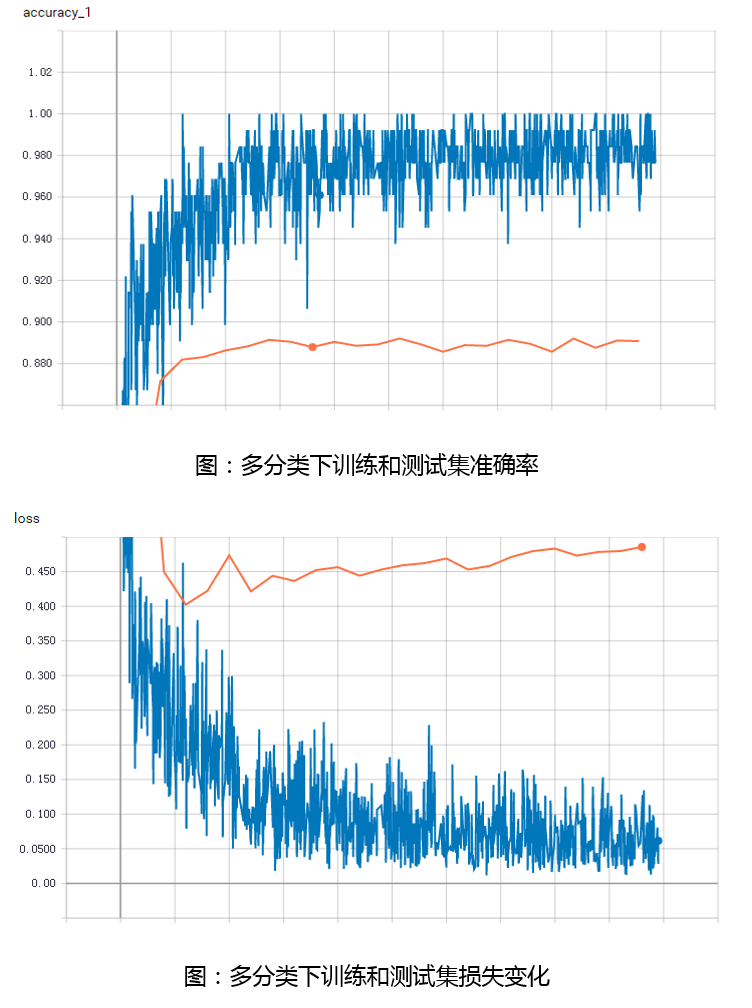
2. 多分类结果
下面给出了随着训练次数增加算法在训练集和测试集上的准确率和损失值变化。蓝色线表示训练集上效果,橙色线表示测试集上效果。可以看到,在迭代到1600个batch后,算法效果已经基本趋于稳定,训练集准确率在98%附近波动,损失值在0.07附近波动。在测试集上,算法准确率最高点出现在迭代了2600个batch的时候,准确率为89.20%,损失值也在迭代了400个batch后开始发散。
0×06 相关代码
代码的git地址为:https://github.com/zwq0320/malicious_dynamic_behavior_detection_by_cnn 欢迎大家交流指正。
0×07 参考资料
【1】http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.702.6310&rep=rep1&type=pdf
【2】https://ieeexplore.ieee.org/abstract/document/7166115/
【4】https://pdfs.semanticscholar.org/d3f5/87797f95e1864c54b80bc98e957da6746e27.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号