获取代理服务器ip列表的方法
开源项目:https://github.com/SpiderClub/haipproxy,看爬代理的网址列表应该是最多的。
CRAWLER_TASKS = [
{
'name': 'mogumiao.com',
'resource': ['http://www.mogumiao.com/proxy/free/listFreeIp',
'http://www.mogumiao.com/proxy/api/freeIp?count=15'],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'json',
'parse_rule': {
'detail_rule': ['msg'],
'ip_key': 'ip',
'port_key': 'port',
},
'interval': 5,
'enable': 1,
},
{
# now we can't get proxies from it,but it required by ip181
'name': 'xdaili.cn',
'resource': ['http://www.xdaili.cn:80/ipagent/freeip/getFreeIps?page=1&rows=10'],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'json',
'parse_rule': {
'detail_rule': ['RESULT'],
'ip_key': 'ip',
'port_key': 'port',
},
'interval': 10,
'enable': 0,
},
{
'name': 'xicidaili.com',
'resource': ['http://www.xicidaili.com/nn/%s' % i for i in range(1, 6)] +
['http://www.xicidaili.com/wn/%s' % i for i in range(1, 6)] +
['http://www.xicidaili.com/wt/%s' % i for i in range(1, 6)],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tr',
'infos_pos': 1,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 60,
'enable': 1
},
{
'name': 'kuaidaili.com',
'resource': ['https://www.kuaidaili.com/free/inha/%s' % i for i in range(1, 6)] +
['https://www.kuaidaili.com/proxylist/%s' % i for i in range(1, 11)],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tr',
'infos_pos': 4,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 60,
'enable': 1
},
{
'name': 'kxdaili.com',
'resource': [
'http://www.kxdaili.com/dailiip/%s/%s.html#ip' % (i, j) for i in range(1, 3) for j in range(1, 11)
],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tr',
'infos_pos': 1,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 60,
'enable': 1
},
{
'name': 'mrhinkydink.com',
'resource': ['http://www.mrhinkydink.com/proxies.htm'],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'css',
'pre_extract': '.text',
'infos_pos': 1,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 2 * 60,
'enable': 1,
},
{
'name': 'nianshao.me',
'resource': ['http://www.nianshao.me/?stype=1&page=%s' % i for i in range(1, 11)] +
['http://www.nianshao.me/?stype=2&page=%s' % i for i in range(1, 11)] +
['http://www.nianshao.me/?stype=5&page=%s' % i for i in range(1, 11)],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tr',
'infos_pos': 1,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 60,
'enable': 1 # it seems the website is down
},
{
'name': '66ip.cn',
'resource': ['http://www.66ip.cn/%s.html' % i for i in range(1, 3)] +
['http://www.66ip.cn/areaindex_%s/%s.html' % (i, j)
for i in range(1, 35) for j in range(1, 3)],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tr',
'infos_pos': 4,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 2 * 60,
'enable': 1
},
{
'name': 'baizhongsou.com',
'resource': ['http://ip.baizhongsou.com/'],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tr',
'infos_pos': 1,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': True,
'protocols': None
},
'interval': 30,
'enable': 1
},
{
'name': 'data5u.com',
'resource': [
'http://www.data5u.com/free/index.shtml',
'http://www.data5u.com/free/gngn/index.shtml',
'http://www.data5u.com/free/gwgn/index.shtml'
],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//ul[contains(@class, "l2")]',
'infos_pos': 0,
'infos_end': None,
'detail_rule': 'span li::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 10,
'enable': 1,
},
{
# can not access
'name': 'httpsdaili.com',
'resource': ['http://www.httpsdaili.com/?stype=1&page=%s' % i for i in range(1, 8)],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tr[contains(@class, "odd")]',
'infos_pos': 0,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 3 * 60,
'enable': 0,
},
{
'name': 'ip181.com',
'resource': ['http://www.ip181.com/'] +
['http://www.ip181.com/daili/%s.html' % i for i in range(1, 20)],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tr',
'infos_pos': 1,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 10,
'enable': 1,
},
{
'name': 'ip3366.net',
'resource': ['http://www.ip3366.net/free/?stype=1&page=%s' % i for i in range(1, 3)] +
['http://www.ip3366.net/free/?stype=3&page=%s' % i for i in range(1, 3)],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tr',
'infos_pos': 1,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 30,
'enable': 1
},
{
'name': 'iphai.com',
'resource': [
'http://www.iphai.com/free/ng',
'http://www.iphai.com/free/wg',
'http://www.iphai.com/free/np',
'http://www.iphai.com/free/wp',
'http://www.iphai.com/'
],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tr',
'infos_pos': 1,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 60,
'enable': 1,
},
{
'name': 'swei360.com',
'resource': ['http://www.swei360.com/free/?page=%s' % i for i in range(1, 4)] +
['http://www.swei360.com/free/?stype=3&page=%s' % i for i in range(1, 4)],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tr',
'infos_pos': 1,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 30,
'enable': 1,
},
{
'name': 'yundaili.com',
'resource': [
'http://www.yun-daili.com/free.asp?stype=1',
'http://www.yun-daili.com/free.asp?stype=2',
'http://www.yun-daili.com/free.asp?stype=3',
'http://www.yun-daili.com/free.asp?stype=4',
],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tr[contains(@class, "odd")]',
'infos_pos': 0,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 6 * 60,
'enable': 1,
},
{
'name': 'ab57.ru',
'resource': ['http://ab57.ru/downloads/proxyold.txt'],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'text',
'parse_rule': {
'pre_extract': None,
'delimiter': '\r\n',
'redundancy': None,
'protocols': None
},
'interval': 60,
'enable': 1,
},
{
'name': 'proxylists.net',
'resource': ['http://www.proxylists.net/http_highanon.txt'],
'parse_type': 'text',
'task_queue': SPIDER_COMMON_TASK,
'parse_rule': {
'pre_extract': None,
'delimiter': '\r\n',
'redundancy': None,
'protocols': None
},
'interval': 60,
'enable': 1,
},
{
'name': 'my-proxy.com',
'resource': [
'https://www.my-proxy.com/free-elite-proxy.html',
'https://www.my-proxy.com/free-anonymous-proxy.html',
'https://www.my-proxy.com/free-socks-4-proxy.html',
'https://www.my-proxy.com/free-socks-5-proxy.html'
],
'task_queue': SPIDER_COMMON_TASK,
# if the parse method is specified, set it in the Spider's parser_maps
'parse_type': 'myproxy',
'interval': 60,
'enable': 1,
},
{
'name': 'us-proxy.org',
'resource': ['https://www.us-proxy.org/'],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tbody//tr',
'infos_pos': 0,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 60,
'enable': 1,
},
{
'name': 'socks-proxy.net',
'resource': [
'https://www.socks-proxy.net/',
],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tbody//tr',
'infos_pos': 0,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 60,
'enable': 1,
},
{
'name': 'sslproxies.org/',
'resource': ['https://www.sslproxies.org/'],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tbody//tr',
'infos_pos': 0,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 60,
'enable': 1,
},
{
'name': 'atomintersoft.com',
'resource': [
'http://www.atomintersoft.com/high_anonymity_elite_proxy_list',
'http://www.atomintersoft.com/anonymous_proxy_list',
],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tr',
'infos_pos': 1,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': True,
'protocols': None
},
'interval': 60,
'enable': 1,
},
{
'name': 'rmccurdy.com',
'resource': [
'https://www.rmccurdy.com/scripts/proxy/good.txt'
],
'task_queue': SPIDER_COMMON_TASK,
'parse_type': 'text',
'parse_rule': {
'pre_extract': None,
'delimiter': '\n',
'redundancy': None,
'protocols': None
},
'interval': 60,
'enable': 1,
},
{
# there are some problems using crawlspider, so we use basic spider
'name': 'coderbusy.com',
'resource': ['https://proxy.coderbusy.com/'] +
['https://proxy.coderbusy.com/classical/https-ready.aspx?page=%s' % i for i in range(1, 21)] +
['https://proxy.coderbusy.com/classical/post-ready.aspx?page=%s' % i for i in range(1, 21)] +
['https://proxy.coderbusy.com/classical/anonymous-type/anonymous.aspx?page=%s'
% i for i in range(1, 6)] +
['https://proxy.coderbusy.com/classical/anonymous-type/highanonymous.aspx?page=%s'
% i for i in range(1, 6)] +
['https://proxy.coderbusy.com/classical/country/cn.aspx?page=%s' % i for i in range(1, 21)] +
['https://proxy.coderbusy.com/classical/country/us.aspx?page=%s' % i for i in range(1, 11)] +
['https://proxy.coderbusy.com/classical/country/id.aspx?page=%s' % i for i in range(1, 6)] +
['https://proxy.coderbusy.com/classical/country/ru.aspx?page=%s' % i for i in range(1, 6)],
'task_queue': SPIDER_AJAX_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tr',
'infos_pos': 1,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 1,
'port_pos': 2,
'extract_protocol': False,
'split_detail': False,
'protocols': None
},
'interval': 2 * 60,
'enable': 1,
},
{
'name': 'proxydb.net',
'resource': ['http://proxydb.net/?offset=%s' % (15 * i) for i in range(20)],
'task_queue': SPIDER_AJAX_TASK,
'parse_type': 'common',
'parse_rule': {
'detail_rule': 'a::text',
'split_detail': True,
},
'interval': 3 * 60,
'enable': 1,
},
{
'name': 'cool-proxy.net',
'resource': ['https://www.cool-proxy.net/proxies/http_proxy_list/country_code:/port:/anonymous:1/page:%s'
% i for i in range(1, 11)],
'task_queue': SPIDER_AJAX_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tr',
'infos_pos': 1,
'infos_end': -1,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 30,
'enable': 1,
},
{
'name': 'goubanjia.com',
'resource': ['http://www.goubanjia.com/'],
'task_queue': SPIDER_AJAX_TASK,
'parse_type': 'goubanjia',
'interval': 10,
'enable': 1,
},
{
'name': 'cn-proxy.com',
'resource': [
'http://cn-proxy.com/',
'http://cn-proxy.com/archives/218'
],
'task_queue': SPIDER_GFW_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tbody//tr',
'infos_pos': 0,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 60,
'enable': 1,
},
{
'name': 'free-proxy-list.net',
'resource': [
'https://free-proxy-list.net/',
'https://free-proxy-list.net/uk-proxy.html',
'https://free-proxy-list.net/anonymous-proxy.html',
],
'task_queue': SPIDER_GFW_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tbody//tr',
'infos_pos': 0,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 60,
'enable': 1,
},
{
'name': 'xroxy',
'resource': ['http://www.xroxy.com/proxylist.php?port=&type=&ssl=&country=&latency=&reliability=&'
'sort=reliability&desc=true&pnum=%s#table' % i for i in range(20)],
'task_queue': SPIDER_GFW_TASK,
'parse_type': 'xroxy',
'interval': 60,
'enable': 1,
},
{
'name': 'proxylistplus',
'resource': [
'http://list.proxylistplus.com/Fresh-HTTP-Proxy-List-1',
'http://list.proxylistplus.com/SSL-List-1'
],
'task_queue': SPIDER_GFW_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tr[contains(@class, "cells")]',
'infos_pos': 1,
'infos_end': -1,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': False,
'split_detail': False,
'protocols': None
},
'interval': 3 * 60,
'enable': 1,
},
{
'name': 'cnproxy.com',
'resource': ['http://www.cnproxy.com/proxy%s.html' % i for i in range(1, 11)] +
['http://www.cnproxy.com/proxyedu%s.html' % i for i in range(1, 3)],
'task_queue': SPIDER_AJAX_GFW_TASK,
'parse_type': 'cnproxy',
'interval': 60,
'enable': 1,
},
{
'name': 'free-proxy.cz',
'resource': ['http://free-proxy.cz/en/proxylist/main/%s' % i for i in range(1, 30)],
'task_queue': SPIDER_AJAX_GFW_TASK,
'parse_type': 'free-proxy',
'interval': 3 * 60,
'enable': 1,
},
{
'name': 'proxy-list.org',
'resource': ['https://proxy-list.org/english/index.php?p=%s' % i for i in range(1, 11)],
'task_queue': SPIDER_AJAX_GFW_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'css',
'pre_extract': '.table ul',
'infos_pos': 1,
'infos_end': None,
'detail_rule': 'li::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': True,
'protocols': None
},
'interval': 60,
'enable': 1,
},
{
'name': 'gatherproxy',
'resource': [
'http://www.gatherproxy.com/',
'http://www.gatherproxy.com/proxylist/anonymity/?t=Elite',
'http://www.gatherproxy.com/proxylist/anonymity/?t=Anonymous',
'http://www.gatherproxy.com/proxylist/country/?c=China',
'http://www.gatherproxy.com/proxylist/country/?c=Brazil',
'http://www.gatherproxy.com/proxylist/country/?c=Indonesia',
'http://www.gatherproxy.com/proxylist/country/?c=Russia',
'http://www.gatherproxy.com/proxylist/country/?c=United%20States',
'http://www.gatherproxy.com/proxylist/country/?c=Thailand',
'http://www.gatherproxy.com/proxylist/port/8080',
'http://www.gatherproxy.com/proxylist/port/3128',
'http://www.gatherproxy.com/proxylist/port/80',
'http://www.gatherproxy.com/proxylist/port/8118'
],
'task_queue': SPIDER_AJAX_GFW_TASK,
'parse_type': 'common',
'parse_rule': {
'pre_extract_method': 'xpath',
'pre_extract': '//tr',
'infos_pos': 1,
'infos_end': None,
'detail_rule': 'td::text',
'ip_pos': 0,
'port_pos': 1,
'extract_protocol': True,
'split_detail': False,
'protocols': None
},
'interval': 60,
'enable': 1,
},
]
# crawler will fetch tasks from the following queues
CRAWLER_TASK_MAPS = {
'common': SPIDER_COMMON_TASK,
'ajax': SPIDER_AJAX_TASK,
'gfw': SPIDER_GFW_TASK,
'ajax_gfw': SPIDER_AJAX_GFW_TASK
}
# validator scheduler will fetch tasks from resource queue and store into task queue
VALIDATOR_TASKS = [
{
'name': 'http',
'task_queue': TEMP_HTTP_QUEUE,
'resource': VALIDATED_HTTP_QUEUE,
'interval': 5, # 20 minutes
'enable': 1,
},
{
'name': 'https',
'task_queue': TEMP_HTTPS_QUEUE,
'resource': VALIDATED_HTTPS_QUEUE,
'interval': 5,
'enable': 1,
},
{
'name': 'weibo',
'task_queue': TEMP_WEIBO_QUEUE,
'resource': VALIDATED_WEIBO_QUEUE,
'interval': 5,
'enable': 1,
},
{
'name': 'zhihu',
'task_queue': TEMP_ZHIHU_QUEUE,
'resource': VALIDATED_ZHIHU_QUEUE,
'interval': 5,
'enable': 1,
},
]
# validators will fetch proxies from the following queues
TEMP_TASK_MAPS = {
'init': INIT_HTTP_QUEUE,
'http': TEMP_HTTP_QUEUE,
'https': TEMP_HTTPS_QUEUE,
'weibo': TEMP_WEIBO_QUEUE,
'zhihu': TEMP_ZHIHU_QUEUE
}
# target website that use http protocol
HTTP_TASKS = ['http']
# target website that use https protocol
HTTPS_TASKS = ['https', 'zhihu', 'weibo']
# todo the three maps may be combined in one map
# validator scheduler and clients will fetch proxies from the following queues
SCORE_MAPS = {
'http': VALIDATED_HTTP_QUEUE,
'https': VALIDATED_HTTPS_QUEUE,
'weibo': VALIDATED_WEIBO_QUEUE,
'zhihu': VALIDATED_ZHIHU_QUEUE
}
# validator scheduler and clients will fetch proxies from the following queues which are verified recently
TTL_MAPS = {
'http': TTL_HTTP_QUEUE,
'https': TTL_HTTPS_QUEUE,
'weibo': TTL_WEIBO_QUEUE,
'zhihu': TTL_ZHIHU_QUEUE
}
SPEED_MAPS = {
'http': SPEED_HTTP_QUEUE,
'https': SPEED_HTTPS_QUEUE,
'weibo': SPEED_WEIBO_QUEUE,
'zhihu': SPEED_ZHIHU_QUEUE
}
因为项目参考了Github上开源的各个爬虫代理的实现,参考了下面的项目:
开源项目:https://github.com/TimoGroom/IPProxys
突破反爬虫的利器:开源IP代理池【转】
突破反爬虫的一个常用做法是使用代理IP,可以是作为初学者或者个人来说,买一些代理ip成本稍微高一些,因此最近写了一个开源项目IPProxys,用来为个人提供代理ip。
IPProxys原理:通过爬取各大代理网站提供的免费IP,进行去重,并验证ip的可用性,将有效的ip存储到sqlite中,并提供一个HTTP接口供爬虫程序获取ip。
IPProxys项目已经上传到github中,链接为/qiyeboy/IPProxys。下面对整个项目工程进行一下说明,如下图所示:
api包:主要是实现http服务器,提供api接口(通过get请求,返回json数据)
data文件夹:主要是数据库文件的存储位置和qqwry.dat(可以查询换ip软件的地理位置)
db包:主要是封装了一些数据库的操作
spider包:主要是爬虫的核心功能,爬取代理网站上的代理ip
test包:测试一些用例,不参与整个项目的运行
util包:提供一些工具类。查询ip的地理位置
validator包:用来测试ip地址是否可用
:主要是配置信息(包括配置ip地址的解析方式和数据库的配置)
整个项目的代码量不大,大家可以根据自己的需求进行修改,也可以提出自己的想法和建议帮助我改进这个项目。
如何使用IPProxys项目呢?
1.将项目目录clone到当前文件夹 $gitclone
2.切换工程目录 $cdIPProxys
3.运行脚本 windows上运行效果如下图所示:
项目依赖项:
需要安装sqlite数据库
安装requests库:pipinstallrequests
安装lxml:apt-getinstallpython-lxml
当IPProxys运行起来后,外部的爬虫如何获取ip呢? 外部的爬虫只需要向IPProxys所在主机的8000端口发送GET请求即可。GET请求的参数为:
访问http://127.0.0.1:8000/?types=0&count=5&country=中国这个链接的含义是获取5个ip地址在中国的高匿代理。
响应为JSON格式,返回数据为:
{"ip":"220.160.22.115","port":80},
{"ip":"183.129.151.130","port":80},
{"ip":"59.52.243.88","port":80},
{"ip":"112.228.35.24","port":8888},
{"ip":"106.75.176.4","port":80}
一般爬取到的有效ip大约有60个左右,基本上满足个人的需要。
看了下源码,爬的服务器列表如下:
parserList = [
{
'urls': ['http://m.66ip.cn/%s.html'% n for n in ['index']+range(2,12)],
'type':'xpath',
'pattern': ".//*[@class='profit-c']/table/tr[position()>1]",
'postion':{'ip':'./td[1]','port':'./td[2]','type':'./td[4]','protocol':''}
},
{
'urls': ['http://m.66ip.cn/areaindex_%s/%s.html'%(m,n) for m in range(1,35) for n in range(1,10)],
'type':'xpath',
'pattern': ".//*[@id='footer']/div/table/tr[position()>1]",
'postion':{'ip':'./td[1]','port':'./td[2]','type':'./td[4]','protocol':''}
},
{
'urls': ['http://www.kuaidaili.com/proxylist/%s/'% n for n in range(1,11)],
'type': 'xpath',
'pattern': ".//*[@id='index_free_list']/table/tbody/tr[position()>0]",
'postion':{'ip':'./td[1]','port':'./td[2]','type':'./td[3]','protocol':'./td[4]'}
},
{
'urls': ['http://www.kuaidaili.com/free/%s/%s/'% (m,n) for m in ['inha', 'intr', 'outha', 'outtr'] for n in range(1,11)],
'type':'xpath',
'pattern': ".//*[@id='list']/table/tbody/tr[position()>0]",
'postion':{'ip':'./td[1]','port':'./td[2]','type':'./td[3]','protocol':'./td[4]'}
},
{
'urls': ['http://www.cz88.net/proxy/%s'% m for m in ['index.shtml']+['http_%s.shtml' % n for n in range(2, 11)]],
'type':'xpath',
'pattern':".//*[@id='boxright']/div/ul/li[position()>1]",
'postion':{'ip':'./div[1]','port':'./div[2]','type':'./div[3]','protocol':''}
},
{
'urls': ['http://www.ip181.com/daili/%s.html'% n for n in range(1, 11)],
'type':'xpath',
'pattern': ".//div[@class='row']/div[3]/table/tbody/tr[position()>1]",
'postion':{'ip':'./td[1]','port':'./td[2]','type':'./td[3]','protocol':'./td[4]'}
},
{
'urls': ['http://www.xicidaili.com/%s/%s'%(m,n) for m in ['nn', 'nt', 'wn', 'wt'] for n in range(1, 8) ],
'type':'xpath',
'pattern': ".//*[@id='ip_list']/tr[position()>1]",
'postion':{'ip':'./td[2]','port':'./td[3]','type':'./td[5]','protocol':'./td[6]'}
},
{
'urls':['http://www.cnproxy.com/proxy%s.html'% i for i in range(1,11)],
'type':'module',
'moduleName':'CnproxyPraser',
'pattern':r'<tr><td>(\d+\.\d+\.\d+\.\d+)<SCRIPT type=text/javascript>document.write\(\"\:\"(.+)\)</SCRIPT></td><td>(HTTP|SOCKS4)\s*',
'postion':{'ip':0,'port':1,'type':-1,'protocol':2}
}
]
此外,https://www.baibianip.com/api/generatedymatic.html,有专门返回免费的ip代理列表,
代理IP从哪找
由于开python培训有讲过爬虫的缘故,这个问题已经被ask无数次了,一般问的基友也都是爬虫防ban用的,那么在此,我把我个人尝试过的代理渠道都写一下。总体来讲,质量好的都不便宜,便宜的质量都比较渣,一分钱一分货
1)通过程序扫出来的代理
通过程序扫IP段、端口找出来的临时性代理。
诸如百度搜索“HTTP代理”,写着“每日更新”、“国内高匿免费”什么的都是这类,购买的话都很廉价。我用过的有:
西刺(免费代理IP_HTTP代理服务器IP_隐藏IP_QQ代理)
云代理(云代理 - 高速http代理ip每天更新)
......
基本都大同小异,没有哪个好那个坏,几个平台提供的代理至少有3成的重复率。
这类代理,有效期都不高,即便批量验证过在使用时还是会废掉一部分,可以应付低效率的采集、刷单次访问量,但是搞别的的还是算了吧
2)ADSL拨号服务器
ADSL拨号,断线重连切IP,淘宝有卖的,限定地区拨号、全国拨号都有。相对较稳定,至少比扫描出来的强很多,但切换IP耗时较长,需要几秒到1分钟之间。
所以如果采集是每访问一次切一次IP的话,效率会很慢,只能等当前IP被对方ban掉的时候在拨号换新的IP。
去年刷百度下拉、搞百度点击器的代理切换曾用过ADSL拨号,比较稳定,有些效果,当然也用过上面扫出来的代理,太烂,没法用。但是限于换IP需要断线重连,导致不容易并发执行任务,所以要大规模化要有些成本。
ADSL拨号可以应付对效率要求不高的采集、刷访问量、刷点击之类的。
3)第三方访问
比如通过“谷歌网页翻译”、“有道网页翻译”、“http代理浏览器”等第三方访问渠道请求目标网页。
速度慢,且采集捕获目标内容的时候多了很多干扰。
4)VPN软件
诸如“flyvpn”、“green vpn”,采集是IP被ban了直接换一个,VPN软件本身靠谱代理还是挺稳定的,就是人得在电脑旁边,手动换一次。但是偶尔查查几万关键词的百度排名、几万页面收录,用VPN还是挺悠闲的,这点量级总共也换不了多少次。
5)自建代理
买一台服务器,利用squid+stunnel搭建一台HTTP高匿代理服务器,Tinyproxy也行。squit用来实现http代理,stunnel在代理的基础上建一条隧道实现加密。
如果觉得ip数量少,就多买几台服务器,依次配置squid~~
由于是自建代理,都是独享且是真实的IP,所有相当稳定。采集、抢购、刷票、刷点击、刷主播人气什么的都可以干,只有有钱上机子就行~~
去年接了一个爬虫单子,抓国外某股票网站,共千万页面量级,反爬虫做的挺恶心,无奈买了20台低配机子做HTTP代理服务器,一个月5000成本~~
5)自建代理服务商
如果上面方法自己懒得搞,也没有关系。找个做类似服务的商家,开个api端口即可。
国外的有:
Crawlera ( Web Crawling Platform & Data as a Service )
......
国内的有:
阿步云(阿布云代理 - 最专业、最稳定、IP最丰富的高匿名HTTP代理IP提供商)
鲲鹏代理(IPRENT - 国内最专业稳定高匿独享HTTP代理解决方案提供商)
瀚云代理(瀚云代理 – http代理ip)
......
Crawlera和阿步云都用过,除了贵都挺好的,另外在请求频率和并发数上有限制。没办法,要一个ip共享给10个人,每个人并发100,费用又不涨,他们那边得赔死,光带宽费就海里去了。
下面的内容来自知乎:https://www.zhihu.com/question/47419361
换了很多家 芝麻(http://www.zhimaruanjian.com/pay/),站大爷(http://ip.zdaye.com/FreeIPlist.html?adr=%CF%E3%B8%DB,有免费的ip,少量),西刺 ,大象都用过,西刺,大象就不说了 辣鸡!!!!差点用吐血,站大爷 说实话 客服现在好多了 但是真心贵 ,贫民用不起,质量也就跟芝麻差不多。 前端时间上知乎看了篇软文,用了下别人推荐的蘑菇代理(吐槽下,现在网站怎么都叫些无厘头的名字。。) ,吐槽归吐槽,这家还真不错,性价比高,别说我打广告,确实不错,我自己现在主要在用http://www.mogumiao.com这家,芝麻备用(以防万一,站大爷这么牛逼都挂了好多次,我还是怕的,万一呢,不过暂时没发现有什么问题,可能是名气小所以才稳定吧)
现在代理IP网上一搜一大堆,因为我自己的业务需求我自己也在使用代理ip,现在用的是快代理我用的时间不能说很长,但是也有一段时间,基本现在网上代理我也都测试过,具体数据我没有闲时间去一个一个测,就是说一下这些的使用心得吧.
网上现在有芝麻代理,牛魔代理等一些今年刚上的代理,这些有心人自己仔细观察一下就能知道就是一家
还有西刺代理,站大爷,快代理,这几个都是某搜索引擎的自然排名前三个,还有之后的就不一一叙述了.
芝麻代理等很多客户端类型的代理ip提供商,这些类似于之前的被G掉的VPN,只不过他这个就是相当于国内的VPN吧
快代理,西刺代理,站大爷等适合开发者去做一些api调用,他们都有免费的,收费的ip,收费的肯定是比免费的好,这个毋庸置疑,不用想着空手套白狼的事情
这些地方的连接在下边.按需选择吧~
西刺代理 www.xicidaili.com
站大爷 www.zdaye.com
手动搬运dalao项目过来回答一下。
这个项目做了什么东西呢? dalao是这样写的:
DungProxy是一个代理IP服务,他包括一个代理IP资源server端和一系列适配中心IP资源得客户端。
server负责代理IP资源的收集维护。
client则是一系列方便用户使用得API,他屏蔽了代理IP下载、代理IP选取、IP绑定、IP切换等比较复杂逻辑。用户只需要引入client即可方便使用代理IP服务
简单来说:
server是一个代理IP爬虫,同时负责简单的数据清洗。
client本质是一个代理IP池,获取数据源之后,基于需要代理访问的网站在本地维护一个代理IP池供爬虫使用。
参考链接:
一只程序汪的自我修养 - 可能是一份没什么用的爬虫代理IP指南(分享自知乎网)https://zhuanlan.zhihu.com/p/25313283?utm_source=qq&utm_medium=social
先占个坑,现在正在写一个代理采集和校验相关程序,到时候开源出来给大伙用用
填坑来了。历时两个多月,目前终于完成了该代理项目。昨晚用知乎爬虫做了性能测试,测试结果如下
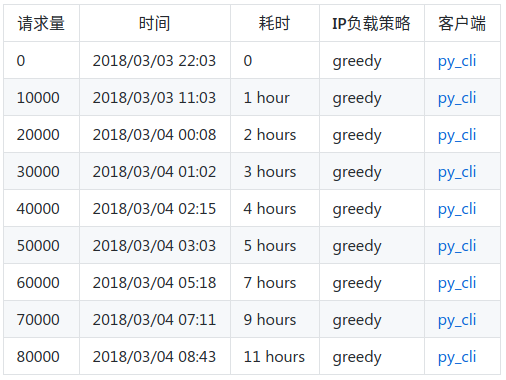
效果还不错。大家可以试用一下,好用给个star就行了。
项目地址:
SpiderClub/haipproxy都说好的代理,那我来喷一喷不好的代理吧。
1、站大爷,就是一个垃圾,骗子公司,其官网卖的那种代理扫描软件,根本没有扫描功能,就一个简单的验证功能,官网宣传说带扫描功能,其实根本不带,会技术抓包的同学可以自己去研究一下。
站大爷,客服态度蛮横,付款后有问题不退款直接加黑名单或者踢出群。
2、data5u,开放代理来来回回每天就返回那1000多个。都是重复的。
3、快代理,太贵了,不值。并且代理和data5u很多重复的。
刚开始用神箭手,实时API用起来还凑合,并发几十次,还可以。用了一段时间各种失败,并发几次都请求频率太高,找了几次客服被拉黑了,wtf...,果断弃用。
后来同事推荐了芝麻代理,因为时间紧,任务重,选了个按天不限ip的套餐,一天1500,速度哇哇的,并发几百上千的都不怕,就是略贵,虽然是公司的,但还是感觉肝儿疼,用了四天完成任务,弃用,据说18年涨到3000一天了。
好吧,拿人钱财替人消灾吧,自己写了个IP代理池,爬取网上免费的IP资源,效果还不错。顺便读了几天混淆过的js代码,找到了目标网站反爬策略的一个小漏洞,先凑合着用吧。哎,这个事在这打个广告,真是有点难为情。
现在出来搞事情了, 做的就是这个方向。
与某几个省的运营商建立了非常密切的合作关系
机房也都是自己运营的
传送门在这里
也许、可能、似乎、我也不保证(逃)是目前市面上你能找到最稳定的代理了。
欢迎大家撩骚,手机号18129823435 :) 任何意见, 我都欢迎。
蟹蟹。
大家千万不要买芝麻代理!
大家千万不要买芝麻代理!
大家千万不要买芝麻代理!
我买了之后发现一个都不能用,然后要退钱,对方不退钱,垃圾公司
根据《中华人民共和国合同法》第一百一十二条之规定,当事人一方不履行合同义务或者履行合同义务不符合约定的,在履行义务或者采取补救措施后,对方还有其他损失的,应当赔偿损失。及《中华人民共和国消费者权益保护法》第二十条规定,经营者向消费者提供有关商品或者服务的质量、性能、用途、有效期限等信息,应当真实、全面,不得作虚假或者引人误解的宣传。该公司存在虚假宣传行为,必须承担相应的违约责任,必须退还给您相关的款项,并应支付违约金。 因此,我向您提出如下建议: 1.与客服沟通,告诉其上述法律依据,看是否能协商解决。 2.请求消费者协会或者依法成立的其他调解组织调解 3.向当地有关行政部门投诉; 4.向人民法院提起诉讼。
百变IP,稳定高匿,岂止于快。这不是软文,这就是直白的推荐!
https://www.baibianip.com/api/doc.html 百变IP 稳定高匿的私密代理IP
百变IP 稳定高匿的私密代理IP
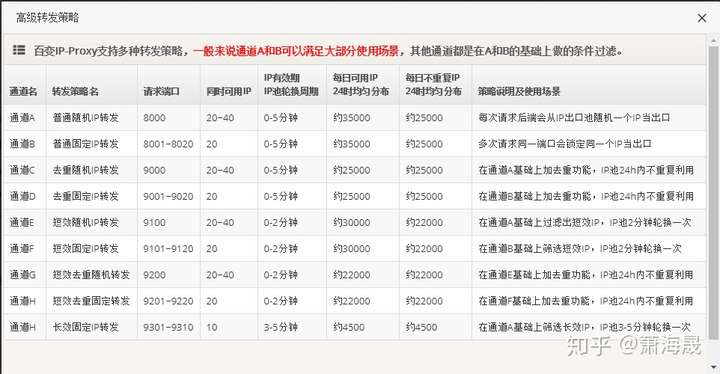
百变IP提供多种接入方式和接口;
方式一(统一入口,智能转发,免提取使用):使用百变IP-Proxy,统一入口,免提取,设置白名单即可使用,支持多种转发策略;
通道A:http://proxy.baibianip.com:8000 每次请求随机一个出口IP,每日3~8万可用IP,24小时均匀分布。
通道B:proxy.baibianip.com:8001~8020 这20个端口,每次请求都会固定一个出口IP,IP有效期1-5分钟。
方式二(通过API提取IP:Port列表后使用):用传统方式,使用动态私密代理
先提取后使用:可开通动态私密代理,通过API或者网页提取IP:Port列表后使用,接口可返回IP、Port、IP所在地区、剩余可用时间,支持自定义字段。每日3~8万可用IP,24小时均匀分布,IP有效期1-5分钟。
所有代理均为高匿私密代理,机房带宽、家庭IP,支持HTTPS、Keep-Alive、POST;
提示:代理均需设置IP白名单或使用用户名/密码认证后才可使用,白名单可通过用户中心手工设置,也可以通过API进行设置。
可以在你的机器上通过访问 http://proxy.baibianip.com:7000/getip.html 来获取当前你机器的出口IP。程序尽量部署到服务器跑,部分小区宽带有多个IP出口。
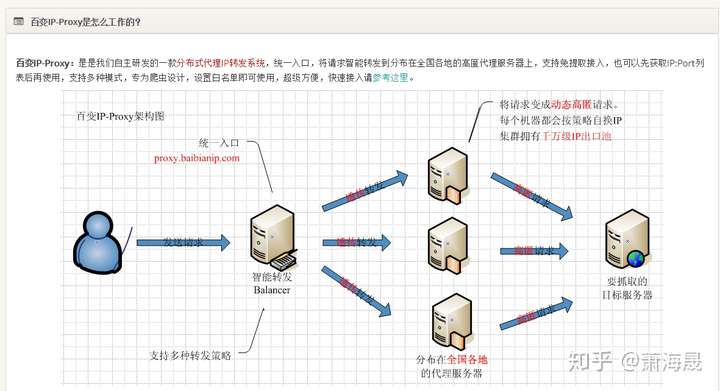
对于百变IP-Proxy来说,各通道调用方式完全一样,无需任何额外改造,只需在程序中控制请求端口号即可(比如用通道B的8001端口,现在想换一个IP当出口,只需换8002就好,无需发送换IP的命令给我们),简单方便,百变IP会自动切换后端出口IP,百变IP智能转发服务会根据后端服务器的心跳情况、负载情况、网络稳定性、IP分散度等综合因素根据算法智能转发。系统支持Keep-Alive。智能转发服务不会出现因为切换IP而出现服务不能用的情况,平滑切换。
一般来说百变IP-Proxy的通道A和B可以满足大部分使用场景;
作为一名资深程序狗,一直在做爬虫,用过很多的代理IP。比如 快代理、阿布云、百变IP、站大爷、F代理、data5u、讯代理之类的,他们各有优劣。
快代理就是贵,私密代理IP个数少,开放代理吧就那么多,也不稳定;
阿布云,连接数太少了;站大爷贵,体验也不好;
自己现在在用一家叫亿牛云的 个人感觉挺好的 还有免费测试http://ip.16yun.cn:817/reg_accounts/register/?sale_user=DSQ_1132032275

 浙公网安备 33010602011771号
浙公网安备 33010602011771号