数据挖掘的步骤——降维处理前一定记得进行无量纲化处理
数据挖掘的步骤
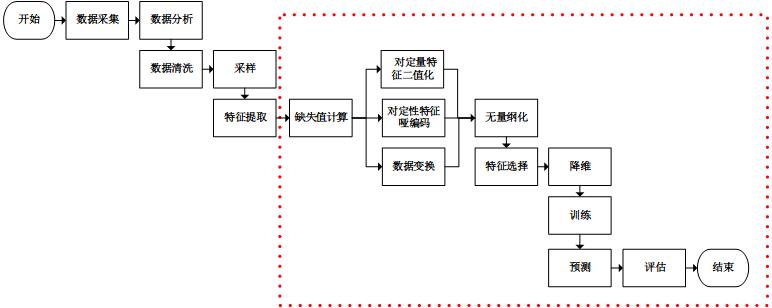
我们使用sklearn进行虚线框内的工作(sklearn也可以进行文本特征提取)。通过分析sklearn源码,我们可以看到除训练,预测和评估以外,处理其他工作的类都实现了3个方法:fit、transform和fit_transform。从命名中可以看到,fit_transform方法是先调用fit然后调用transform,我们只需要关注fit方法和transform方法即可。
transform方法主要用来对特征进行转换。从可利用信息的角度来说,转换分为无信息转换和有信息转换。无信息转换是指不利用任何其他信息进行转换,比如指数、对数函数转换等。有信息转换从是否利用目标值向量又可分为无监督转换和有监督转换。无监督转换指只利用特征的统计信息的转换,统计信息包括均值、标准差、边界等等,比如标准化、PCA法降维等。有监督转换指既利用了特征信息又利用了目标值信息的转换,比如通过模型选择特征、LDA法降维等。通过总结常用的转换类,我们得到下表:
| 包 | 类 | 参数列表 | 类别 | fit方法有用 | 说明 |
| sklearn.preprocessing | StandardScaler | 特征 | 无监督 | Y | 标准化 |
| sklearn.preprocessing | MinMaxScaler | 特征 | 无监督 | Y | 区间缩放 |
| sklearn.preprocessing | Normalizer | 特征 | 无信息 | N | 归一化 |
| sklearn.preprocessing | Binarizer | 特征 | 无信息 | N | 定量特征二值化 |
| sklearn.preprocessing | OneHotEncoder | 特征 | 无监督 | Y | 定性特征编码 |
| sklearn.preprocessing | Imputer | 特征 | 无监督 | Y | 缺失值计算 |
| sklearn.preprocessing | PolynomialFeatures | 特征 | 无信息 | N | 多项式变换(fit方法仅仅生成了多项式的表达式) |
| sklearn.preprocessing | FunctionTransformer | 特征 | 无信息 | N | 自定义函数变换(自定义函数在transform方法中调用) |
| sklearn.feature_selection | VarianceThreshold | 特征 | 无监督 | Y | 方差选择法 |
| sklearn.feature_selection | SelectKBest | 特征/特征+目标值 | 无监督/有监督 | Y | 自定义特征评分选择法 |
| sklearn.feature_selection | SelectKBest+chi2 | 特征+目标值 | 有监督 | Y | 卡方检验选择法 |
| sklearn.feature_selection | RFE | 特征+目标值 | 有监督 | Y | 递归特征消除法 |
| sklearn.feature_selection | SelectFromModel | 特征+目标值 | 有监督 | Y | 自定义模型训练选择法 |
| sklearn.decomposition | PCA | 特征 | 无监督 | Y | PCA降维 |
| sklearn.lda | LDA | 特征+目标值 | 有监督 | Y | LDA降维 |
示例代码:
把 StandardScaler, PCA, LogisticRegression 运用管道连接起来
from sklearn.preprocessing import StandardScaler
|
Test Accuracy: 0.956
可以把 Pipeline 当作对这些转化器(trainsformers)和估算器(estimators)的封装。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号