1、VGG16 2、VGG19 3、ResNet50 4、Inception V3 5、Xception介绍——迁移学习
ResNet, AlexNet, VGG, Inception: 理解各种各样的CNN架构
本文翻译自ResNet, AlexNet, VGG, Inception: Understanding various architectures of Convolutional Networks,原作者保留版权
卷积神经网络在视觉识别任务上的表现令人称奇。好的CNN网络是带有上百万参数和许多隐含层的“庞然怪物”。事实上,一个不好的经验规则是:网络越深,效果越好。AlexNet,VGG,Inception和ResNet是最近一些流行的CNN网络。为什么这些网络表现如此之好?它们是如何设计出来的?为什么它们设计成那样的结构?回答这些问题并不简单,但是这里我们试着去探讨上面的一些问题。网络结构设计是一个复杂的过程,需要花点时间去学习,甚至更长时间去自己动手实验。首先,我们先来讨论一个基本问题:
为什么CNN模型战胜了传统的计算机视觉方法?

图像分类指的是给定一个图片将其分类成预先定义好的几个类别之一。图像分类的传统流程涉及两个模块:特征提取和分类。
特征提取指的是从原始像素点中提取更高级的特征,这些特征能捕捉到各个类别间的区别。这种特征提取是使用无监督方式,从像素点中提取信息时没有用到图像的类别标签。常用的传统特征包括GIST, HOG, SIFT, LBP等。特征提取之后,使用图像的这些特征与其对应的类别标签训练一个分类模型。常用的分类模型有SVM,LR,随机森林及决策树等。
上面流程的一大问题是特征提取不能根据图像和其标签进行调整。如果选择的特征缺乏一定的代表性来区分各个类别,模型的准确性就大打折扣,无论你采用什么样的分类策略。采用传统的流程,目前的一个比较好的方法是使用多种特征提取器,然后组合它们得到一种更好的特征。但是这需要很多启发式规则和人力来根据领域不同来调整参数使得达到一个很好的准确度,这里说的是要接近人类水平。这也就是为什么采用传统的计算机视觉技术需要花费多年时间才能打造一个好的计算机视觉系统(如OCR,人脸验证,图像识别,物体检测等),这些系统在实际应用中可以处理各种各样的数据。有一次,我们用了6周时间为一家公司打造了一个CNN模型,其效果更好,采用传统的计算机视觉技术要达到这样的效果要花费一年时间。
传统流程的另外一个问题是它与人类学习识别物体的过程是完全不一样的。自从出生之初,一个孩子就可以感知周围环境,随着他的成长,他接触更多的数据,从而学会了识别物体。这是深度学习背后的哲学,其中并没有建立硬编码的特征提取器。它将特征提取和分类两个模块集成一个系统,通过识别图像的特征来进行提取并基于有标签数据进行分类。
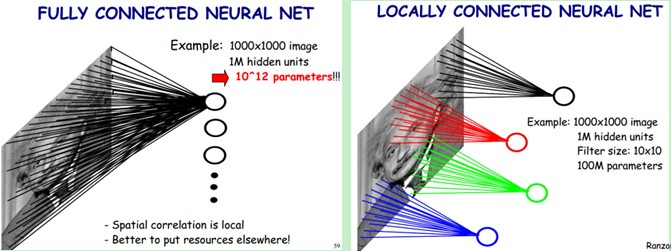
这样的集成系统就是多层感知机,即有多层神经元密集连接而成的神经网络。一个经典的深度网络包含很多参数,由于缺乏足够的训练样本,基本不可能训练出一个不过拟合的模型。但是对于CNN模型,从头开始训练一个网络时你可以使用一个很大的数据集如ImageNet。这背后的原因是CNN模型的两个特点:神经元间的权重共享和卷积层之间的稀疏连接。这可以从下图中看到。在卷积层,某一个层的神经元只是和输入层中的神经元局部连接,而且卷积核的参数是在整个2-D特征图上是共享的。
为了理解CNN背后的设计哲学,你可能会问:其目标是什么?
(1)准确度
如果你在搭建一个智能系统,最重要的当然是要尽可能地准确。公平地来说,准确度不仅取决于网路,也取决于训练样本数量。因此,CNN模型一般在一个标准数据集ImageNet上做对比。
ImageNet项目仍然在继续改进,目前已经有包含21841类的14,197,122个图片。自从2010年,每年都会举行ImageNet图像识别竞赛,比赛会提供从ImageNet数据集中抽取的属于1000类的120万张图片。每个网络架构都是在这120万张图片上测试其在1000类上的准确度。
(2)计算量
大部分的CNN模型都需要很大的内存和计算量,特别是在训练过程。因此,计算量会成为一个重要的关注点。同样地,如果你想部署在移动端,训练得到的最终模型大小也需要特别考虑。你可以想象到,为了得到更好的准确度你需要一个计算更密集的网络。因此,准确度和计算量需要折中考虑。
除了上面两个因素,还有其他需要考虑的因素,如训练的容易度,模型的泛化能力等。下面按照提出时间介绍一些最流行的CNN架构,可以看到它们准确度越来越高。
AlexNet
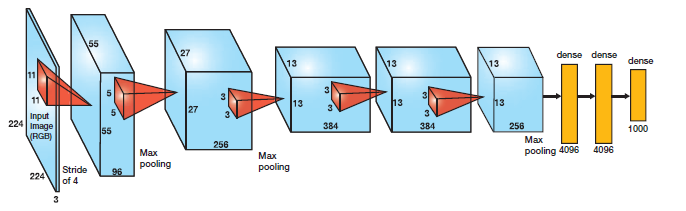
AlexNet是一个较早应用在ImageNet上的深度网络,其准确度相比传统方法有一个很大的提升。它首先是5个卷积层,然后紧跟着是3个全连接层,如下图所示:
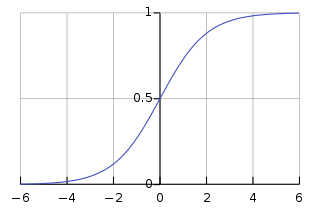
Alex Krizhevs提出的AlexNet采用了ReLU激活函数,而不像传统神经网络早期所采用的Tanh或Sigmoid激活函数,ReLU数学表达为:
ReLU相比Sigmoid的优势是其训练速度更快,因为Sigmoid的导数在稳定区会非常小,从而权重基本上不再更新。这就是梯度消失问题。因此AlexNet在卷积层和全连接层后面都使用了ReLU。
AlexNet的另外一个特点是其通过在每个全连接层后面加上Dropout层减少了模型的过拟合问题。Dropout层以一定的概率随机地关闭当前层中神经元激活值,如下图所示:
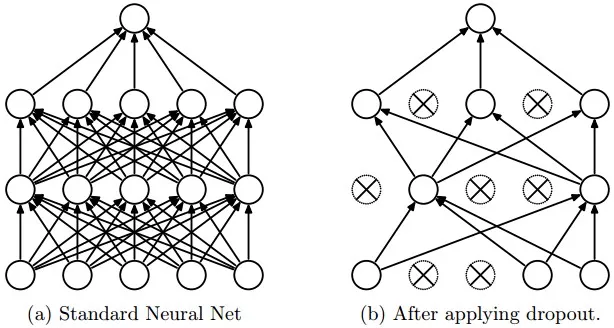
为什么Dropout有效?
Dropout背后理念和集成模型很相似。在Drpout层,不同的神经元组合被关闭,这代表了一种不同的结构,所有这些不同的结构使用一个的子数据集并行地带权重训练,而权重总和为1。如果Dropout层有 个神经元,那么会形成
个不同的子结构。在预测时,相当于集成这些模型并取均值。这种结构化的模型正则化技术有利于避免过拟合。Dropout有效的另外一个视点是:由于神经元是随机选择的,所以可以减少神经元之间的相互依赖,从而确保提取出相互独立的重要特征。
VGG16
VGG16是牛津大学VGG组提出的。VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
比如,3个步长为1的3x3卷积核连续作用在一个大小为7的感受野,其参数总量为 ,如果直接使用7x7卷积核,其参数总量为
,这里
指的是输入和输出的通道数。而且3x3卷积核有利于更好地保持图像性质。VGG网络的架构如下表所示:
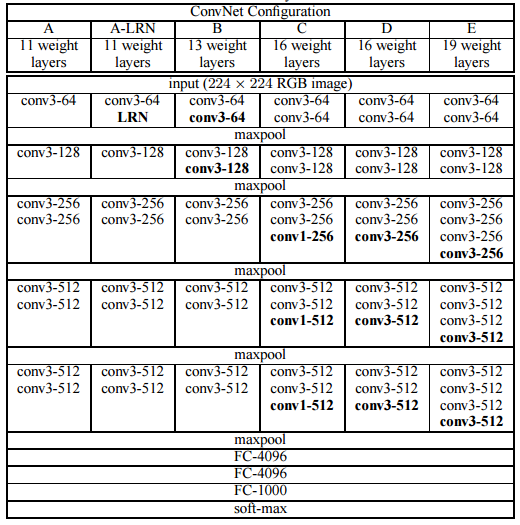
可以看到VGG-D,其使用了一种块结构:多次重复使用同一大小的卷积核来提取更复杂和更具有表达性的特征。这种块结构( blocks/modules)在VGG之后被广泛采用。
VGG卷积层之后是3个全连接层。网络的通道数从较小的64开始,然后每经过一个下采样或者池化层成倍地增加,当然特征图大小成倍地减小。最终其在ImageNet上的Top-5准确度为92.3%。
GoogLeNet/Inception
尽管VGG可以在ImageNet上表现很好,但是将其部署在一个适度大小的GPU上是困难的,因为需要VGG在内存和时间上的计算要求很高。由于卷积层的通道数过大,VGG并不高效。比如,一个3x3的卷积核,如果其输入和输出的通道数均为512,那么需要的计算量为9x512x512。
在卷积操作中,输出特征图上某一个位置,其是与所有的输入特征图是相连的,这是一种密集连接结构。GoogLeNet基于这样的理念:在深度网路中大部分的激活值是不必要的(为0),或者由于相关性是冗余。因此,最高效的深度网路架构应该是激活值之间是稀疏连接的,这意味着512个输出特征图是没有必要与所有的512输入特征图相连。存在一些技术可以对网络进行剪枝来得到稀疏权重或者连接。但是稀疏卷积核的乘法在BLAS和CuBlas中并没有优化,这反而造成稀疏连接结构比密集结构更慢。
据此,GoogLeNet设计了一种称为inception的模块,这个模块使用密集结构来近似一个稀疏的CNN,如下图所示。前面说过,只有很少一部分神经元是真正有效的,所以一种特定大小的卷积核数量设置得非常小。同时,GoogLeNet使用了不同大小的卷积核来抓取不同大小的感受野。
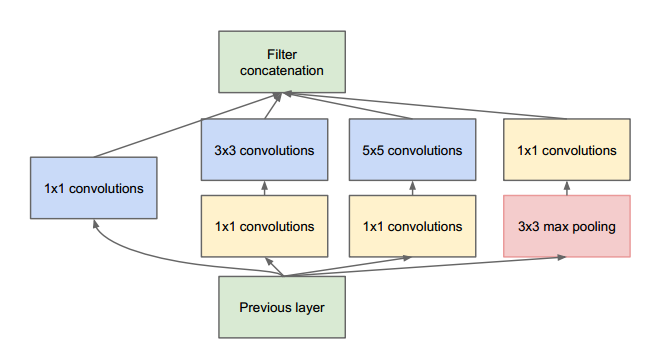
Inception模块的另外一个特点是使用了一中瓶颈层(实际上就是1x1卷积)来降低计算量:
这里假定Inception模块的输入为192个通道,它使用128个3x3卷积核和32个5x5卷积核。5x5卷积的计算量为25x32x192,但是随着网络变深,网络的通道数和卷积核数会增加,此时计算量就暴涨了。为了避免这个问题,在使用较大卷积核之前,先去降低输入的通道数。所以,Inception模块中,输入首先送入只有16个卷积核的1x1层卷积层,然后再送给5x5卷积层。这样整体计算量会减少为16x192+25x32x16。这种设计允许网络可以使用更大的通道数。(译者注:之所以称1x1卷积层为瓶颈层,你可以想象一下一个1x1卷积层拥有最少的通道数,这在Inception模块中就像一个瓶子的最窄处)
GoogLeNet的另外一个特殊设计是最后的卷积层后使用全局均值池化层替换了全连接层,所谓全局池化就是在整个2D特征图上取均值。这大大减少了模型的总参数量。要知道在AlexNet中,全连接层参数占整个网络总参数的90%。使用一个更深更大的网络使得GoogLeNet移除全连接层之后还不影响准确度。其在ImageNet上的top-5准确度为93.3%,但是速度还比VGG还快。
ResNet
从前面可以看到,随着网络深度增加,网络的准确度应该同步增加,当然要注意过拟合问题。但是网络深度增加的一个问题在于这些增加的层是参数更新的信号,因为梯度是从后向前传播的,增加网络深度后,比较靠前的层梯度会很小。这意味着这些层基本上学习停滞了,这就是梯度消失问题。深度网络的第二个问题在于训练,当网络更深时意味着参数空间更大,优化问题变得更难,因此简单地去增加网络深度反而出现更高的训练误差。残差网络ResNet设计一种残差模块让我们可以训练更深的网络。
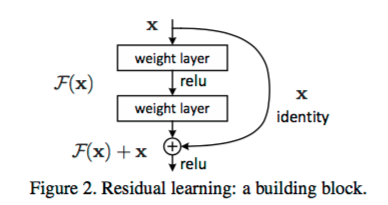
深度网络的训练问题称为退化问题,残差单元可以解决退化问题的背后逻辑在于此:想象一个网络A,其训练误差为x。现在通过在A上面堆积更多的层来构建网络B,这些新增的层什么也不做,仅仅复制前面A的输出。这些新增的层称为C。这意味着网络B应该和A的训练误差一样。那么,如果训练网络B其训练误差应该不会差于A。但是实际上却是更差,唯一的原因是让增加的层C学习恒等映射并不容易。为了解决这个退化问题,残差模块在输入和输出之间建立了一个直接连接,这样新增的层C仅仅需要在原来的输入层基础上学习新的特征,即学习残差,会比较容易。
与GoogLeNet类似,ResNet也最后使用了全局均值池化层。利用残差模块,可以训练152层的残差网络。其准确度比VGG和GoogLeNet要高,但是计算效率也比VGG高。152层的ResNet其top-5准确度为95.51%。
ResNet主要使用3x3卷积,这点与VGG类似。在VGG基础上,短路连接插入进入形成残差网络。如下图所示:
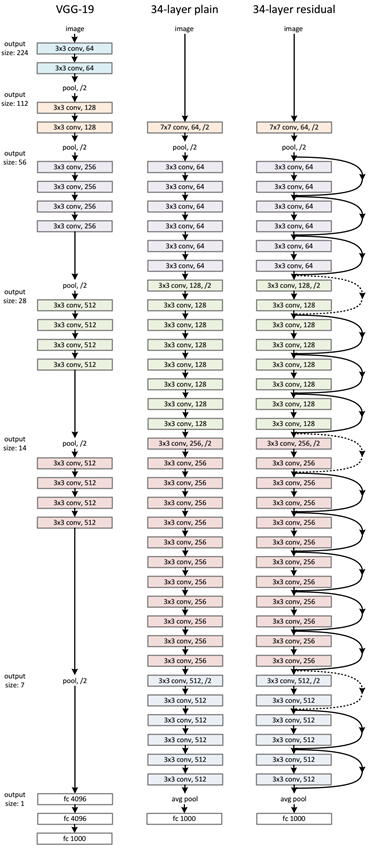
残差网络实验结果表明:34层的普通网络比18层网路训练误差还打,这就是前面所说的退化问题。但是34层的残差网络比18层残差网络训练误差要好。
总结
随着越来越复杂的架构的提出,一些网络可能就流行几年就走下神坛,但是其背后的设计哲学却是值得学习的。这篇文章对近几年比较流行的CNN架构的设计原则做了一个总结。译者注:可以看到,网络的深度越来越大,以保证得到更好的准确度。网络结构倾向采用较少的卷积核,如1x1和3x3卷积核,这说明CNN设计要考虑计算效率了。一个明显的趋势是采用模块结构,这在GoogLeNet和ResNet中可以看到,这是一种很好的设计典范,采用模块化结构可以减少我们网络的设计空间,另外一个点是模块里面使用瓶颈层可以降低计算量,这也是一个优势。这篇文章没有提到的是最近的一些移动端的轻量级CNN模型,如MobileNet,SqueezeNet,ShuffleNet等,这些网络大小非常小,而且计算很高效,可以满足移动端需求,是在准确度和速度之间做了平衡。
图像识别是当今深度学习的主流应用,而Keras是入门最容易、使用最便捷的深度学习框架,所以搞图像识别,你也得强调速度,不能磨叽。本文让你在最短时间内突破五个流行网络结构,迅速达到图像识别技术前沿。
几个月前,我写了一篇关于如何使用已经训练好的卷积(预训练)神经网络模型(特别是VGG16)对图像进行分类的教程,这些已训练好的模型是用Python和Keras深度学习库对ImageNet数据集进行训练得到的。
这些已集成到(先前是和Keras分开的)Keras中的预训练模型能够识别1000种类别对象(例如我们在日常生活中见到的小狗、小猫等),准确率非常高。
先前预训练的ImageNet模型和Keras库是分开的,需要我们克隆一个单独github repo,然后加到项目里。使用单独的github repo来维护就行了。
不过,在预训练的模型(VGG16、VGG19、ResNet50、Inception V3 与 Xception)完全集成到Keras库之前(不需要克隆单独的备份),我的教程已经发布了,通过下面链接可以查看集成后的模型地址。我打算写一个新的教程,演示怎么使用这些最先进的模型。
https://github.com/fchollet/keras/blob/master/keras/applications/vgg16.py
具体来说,是先写一个Python脚本,能加载使用这些网络模型,后端使用TensorFlow或Theano,然后预测你的测试集。
在本教程前半部分,我们简单说说Keras库中包含的VGG、ResNet、Inception和Xception模型架构。
然后,使用Keras来写一个Python脚本,可以从磁盘加载这些预训练的网络模型,然后预测测试集。
最后,在几个示例图像上查看这些分类的结果。
Keras上最好的深度学习图像分类器
下面五个卷积神经网络模型已经在Keras库中,开箱即用:
1、VGG16
2、VGG19
3、ResNet50
4、Inception V3
5、Xception
我们从ImageNet数据集的概述开始,之后简要讨论每个模型架构。
ImageNet是个什么东东
ImageNet是一个手动标注好类别的图片数据库(为了机器视觉研究),目前已有22,000个类别。
然而,当我们在深度学习和卷积神经网络的背景下听到“ImageNet”一词时,我们可能会提到ImageNet视觉识别比赛,称为ILSVRC。
这个图片分类比赛是训练一个模型,能够将输入图片正确分类到1000个类别中的某个类别。训练集120万,验证集5万,测试集10万。
这1,000个图片类别是我们在日常生活中遇到的,例如狗,猫,各种家居物品,车辆类型等等。ILSVRC比赛中图片类别的完整列表如下:
http://image-net.org/challenges/LSVRC/2014/browse-synsets
在图像分类方面,ImageNet比赛准确率已经作为计算机视觉分类算法的基准。自2012年以来,卷积神经网络和深度学习技术主导了这一比赛的排行榜。
在过去几年的ImageNet比赛中,Keras有几个表现最好的CNN(卷积神经网络)模型。这些模型通过迁移学习技术(特征提取,微调(fine-tuning)),对ImaegNet以外的数据集有很强的泛化能力。
VGG16 与 VGG19
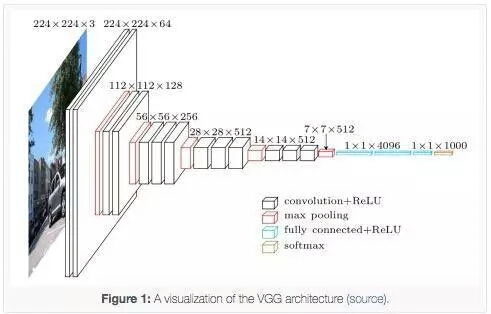
在2014年,VGG模型架构由Simonyan和Zisserman提出,在“极深的大规模图像识别卷积网络”(Very Deep Convolutional Networks for Large Scale Image Recognition)这篇论文中有介绍。
论文地址:https://arxiv.org/abs/1409.1556
VGG模型结构简单有效,前几层仅使用3×3卷积核来增加网络深度,通过max pooling(最大池化)依次减少每层的神经元数量,最后三层分别是2个有4096个神经元的全连接层和一个softmax层。
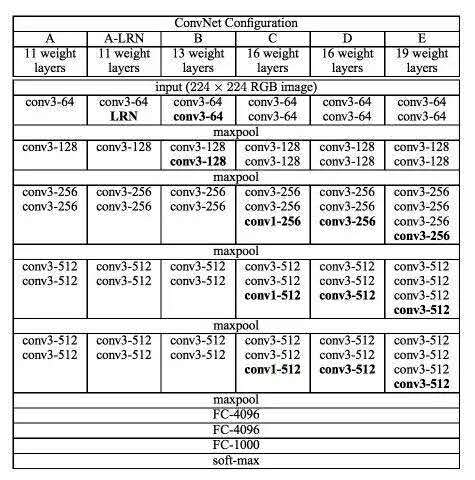
“16”和“19”表示网络中的需要更新需要weight(要学习的参数)的网络层数(下面的图2中的列D和E),包括卷积层,全连接层,softmax层:
在2014年,16层和19层的网络被认为已经很深了,但和现在的ResNet架构比起来已不算什么了,ResNet可以在ImageNet上做到50-200层的深度,而对于CIFAR-10了来说可以做到1000+的深度。
Simonyan和Zisserman发现训练VGG16和VGG19有些难点(尤其是深层网络的收敛问题)。因此为了能更容易进行训练,他们减少了需要更新weight的层数(图2中A列和C列)来训练较小的模型。
较小的网络收敛后,用较小网络学到的weight初始化更深网络的weight,这就是预训练。这样做看起没有问题,不过预训练模型在能被使用之前,需要长时间训练。
在大多数情况下,我们可以不用预训练模型初始化,而是更倾向于采用Xaiver/Glorot初始化或MSRA初始化。读All you need is a good init这篇论文可以更深了解weight初始化和深层神经网络收敛的重要性。
MSRA初始化: https://arxiv.org/abs/1502.01852
All you need is a good init: https://arxiv.org/abs/1511.06422
不幸的是,VGG有两个很大的缺点:
1、网络架构weight数量相当大,很消耗磁盘空间。
2、训练非常慢
由于其全连接节点的数量较多,再加上网络比较深,VGG16有533MB+,VGG19有574MB。这使得部署VGG比较耗时。我们仍然在很多深度学习的图像分类问题中使用VGG,然而,较小的网络架构通常更为理想(例如SqueezeNet、GoogLeNet等)。
ResNet(残差网络)
与传统的顺序网络架构(如AlexNet、OverFeat和VGG)不同,其加入了y=x层(恒等映射层),可以让网络在深度增加情况下却不退化。下图展示了一个构建块(build block),输入经过两个weight层,最后和输入相加,形成一个微架构模块。ResNet最终由许多微架构模块组成。
在2015年的“Deep Residual Learning for Image Recognition”论文中,He等人首先提出ResNet,ResNet架构已经成为一项有意义的模型,其可以通过使用残差模块和常规SGD(需要合理的初始化weight)来训练非常深的网络:
论文地址:https://arxiv.org/abs/1512.03385
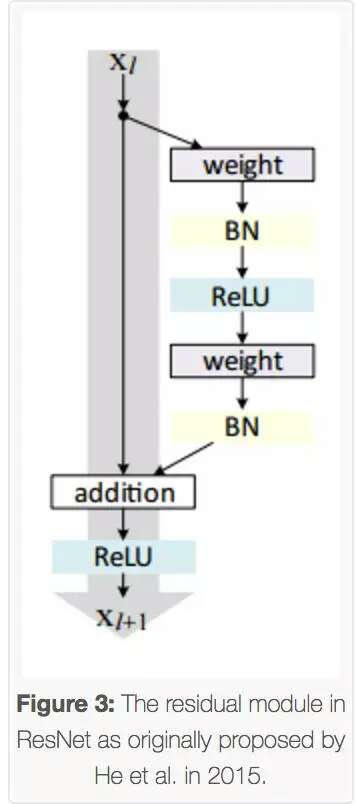
其在2016年后发表的文章“Identity Mappings in Deep Residual Networks”中表明,通过使用identity mapping(恒等映射)来更新残差模块,可以获得很高的准确性。
论文地址:https://arxiv.org/abs/1603.05027
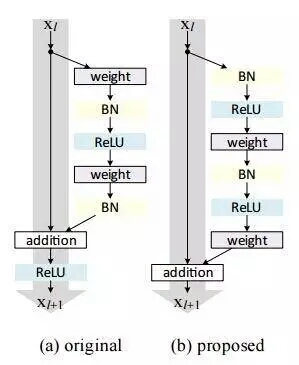
需要注意的是,Keras库中的ResNet50(50个weight层)的实现是基于2015年前的论文。
即使是RESNET比VGG16和VGG19更深,模型的大小实际上是相当小的,用global average pooling(全局平均水平池)代替全连接层能降低模型的大小到102MB。
Inception V3
“Inception”微架构由Szegedy等人在2014年论文"Going Deeper with Convolutions"中首次提出。
论文地址:https://arxiv.org/abs/1409.4842
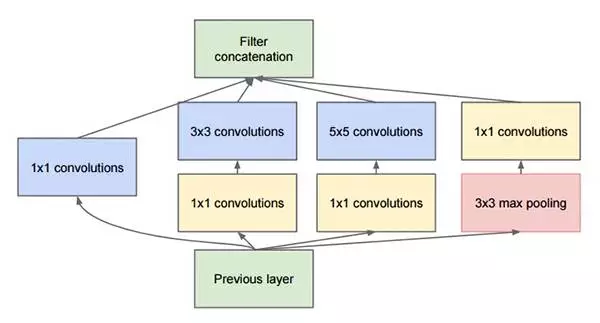
Inception模块的目的是充当“多级特征提取器”,使用1×1、3×3和5×5的卷积核,最后把这些卷积输出连接起来,当做下一层的输入。
这种架构先前叫GoogLeNet,现在简单地被称为Inception vN,其中N指的是由Google定的版本号。Keras库中的Inception V3架构实现基于Szegedy等人后来写的论文"Rethinking the Inception Architecture for Computer Vision",其中提出了对Inception模块的更新,进一步提高了ImageNet分类效果。Inception V3的weight数量小于VGG和ResNet,大小为96MB。
论文地址:https://arxiv.org/abs/1512.00567
Xception
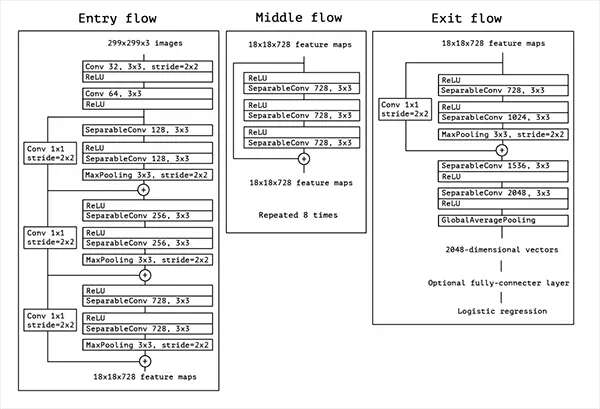
Xception是由François Chollet本人(Keras维护者)提出的。Xception是Inception架构的扩展,它用深度可分离的卷积代替了标准的Inception模块。
原始论文“Xception: Deep Learning with Depthwise Separable Convolutions”在这里:
论文地址:https://arxiv.org/abs/1610.02357
Xception的weight数量最少,只有91MB。
至于说SqueezeNet?
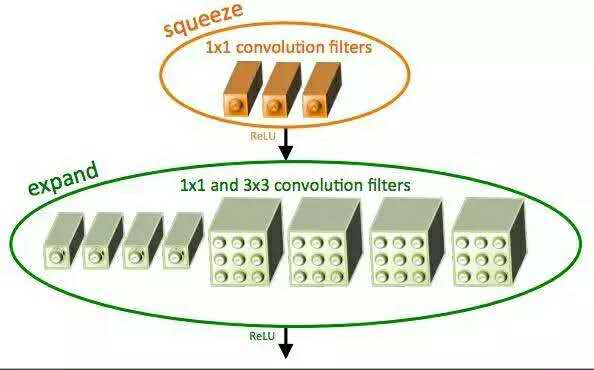
SqueezeNet架构通过使用squeeze卷积层和扩展层(1x1和3X3卷积核混合而成)组成的fire moule获得了AlexNet级精度,且模型大小仅4.9MB。
虽然SqueezeNet模型非常小,但其训练需要技巧。在我即将出版的书“深度学习计算机视觉与Python”中,详细说明了怎么在ImageNet数据集上从头开始训练SqueezeNet。
让我们学习如何使用Keras库中预训练的卷积神经网络模型进行图像分类吧。
新建一个文件,命名为classify_image.py,并输入如下代码:
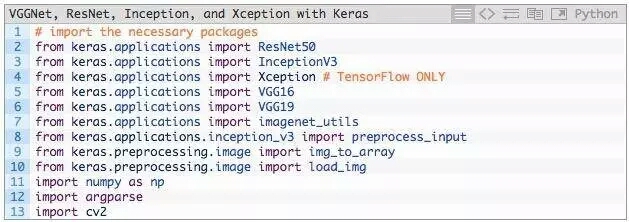
第2-13行的作用是导入所需Python包,其中大多数包都属于Keras库。
具体来说,第2-6行分别导入ResNet50,Inception V3,Xception,VGG16和VGG19。
需要注意,Xception网络只能用TensorFlow后端(如果使用Theano后端,该类会抛出错误)。
第7行,使用imagenet_utils模块,其有一些函数可以很方便的进行输入图像预处理和解码输出分类。
除此之外,还导入的其他辅助函数,其次是NumPy进行数值处理,cv2进行图像编辑。
接下来,解析命令行参数:
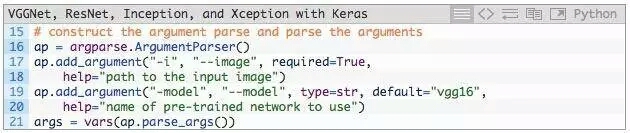
我们只需要一个命令行参数--image,这是要分类的输入图像的路径。
还可以接受一个可选的命令行参数--model,指定想要使用的预训练模型,默认使用vgg16。
通过命令行参数得到指定预训练模型的名字,我们需要定义一个Python字典,将模型名称(字符串)映射到其真实的Keras类。
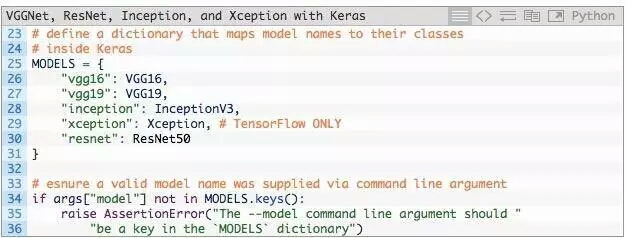
第25-31行定义了MODELS字典,它将模型名称字符串映射到相应的类。
如果在MODELS中找不到--model名称,将抛出AssertionError(第34-36行)。
卷积神经网络将图像作为输入,然后返回与类标签相对应的一组概率作为输出。
经典的CNN输入图像的尺寸,是224×224、227×227、256×256和299×299,但也可以是其他尺寸。
VGG16,VGG19和ResNet均接受224×224输入图像,而Inception V3和Xception需要299×299像素输入,如下面的代码块所示:
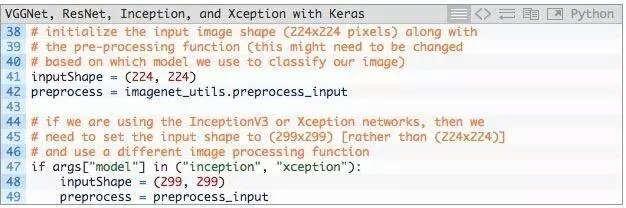
将inputShape初始化为224×224像素。我们还使用函数preprocess_input执行平均减法。
然而,如果使用Inception或Xception,我们需要把inputShape设为299×299像素,接着preprocess_input使用separate pre-processing function,图片可以进行不同类型的缩放。
下一步是从磁盘加载预训练的模型weight(权重)并实例化模型:
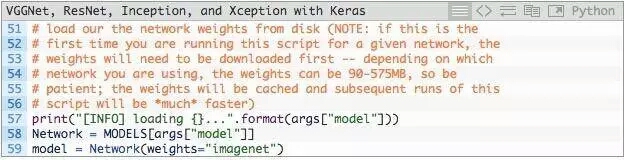
第58行,从--model命令行参数得到model的名字,通过MODELS词典映射到相应的类。
第59行,然后使用预训练的ImageNet权重实例化卷积神经网络。
注意:VGG16和VGG19的权重文件大于500MB。ResNet为〜100MB,而Inception和Xception在90-100MB之间。如果是第一次运行此脚本,这些权重文件自动下载并缓存到本地磁盘。根据您的网络速度,这可能需要一些时间。然而,一旦权重文件被下载下来,他们将不需要重新下载,再次运行classify_image.py会非常快。
模型现在已经加载并准备好进行图像分类 - 我们只需要准备图像进行分类:
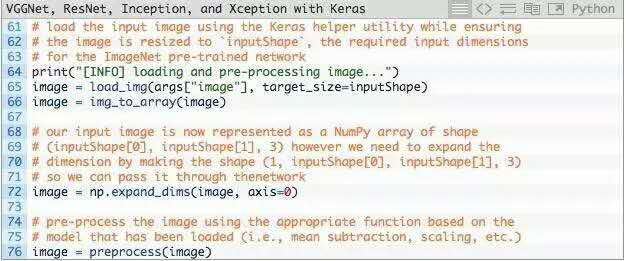
第65行,从磁盘加载输入图像,inputShape调整图像的宽度和高度。
第66行,将图像从PIL/Pillow实例转换为NumPy数组。
输入图像现在表示为(inputShape[0],inputShape[1],3)的NumPy数组。
第72行,我们通常会使用卷积神经网络分批对图像进行训练/分类,因此我们需要通过np.expand_dims向矩阵添加一个额外的维度(颜色通道)。
经过np.expand_dims处理,image具有的形状(1,inputShape[0],inputShape[1],3)。如没有添加这个额外的维度,调用.predict会导致错误。
最后,第76行调用相应的预处理功能来执行数据归一化。
经过模型预测后,并获得输出分类:
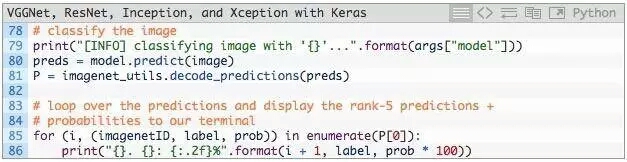
第80行,调用CNN中.predict得到预测结果。根据这些预测结果,将它们传递给ImageNet辅助函数decode_predictions,会得到ImageNet类标签名字(id转换成名字,可读性高)以及与标签相对应的概率。
然后,第85行和第86行将前5个预测(即具有最大概率的标签)输出到终端 。
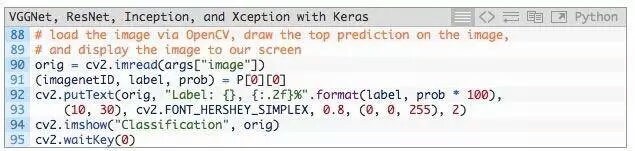
在我们结束示例之前,我们将在此处执行的最后一件事情,通过OpenCV从磁盘加载我们的输入图像,在图像上绘制#1预测,最后将图像显示在我们的屏幕上:
查看预训练模型的实际运行,请看下节。
这篇博文中的所有示例都使用Keras>=2.0和TensorFlow后端。如果使用TensorFlow,请确保使用版本>=1.0,否则将遇到错误。我也用Theano后端测试了这个脚本,并确认可以使用Theano。
安装TensorFlow/Theano和Keras后,点击底部的源代码+示例图像链接就可下载。
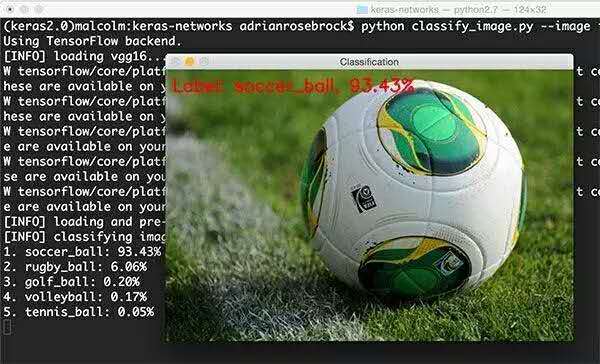
现在我们可以用VGG16对图像进行分类:
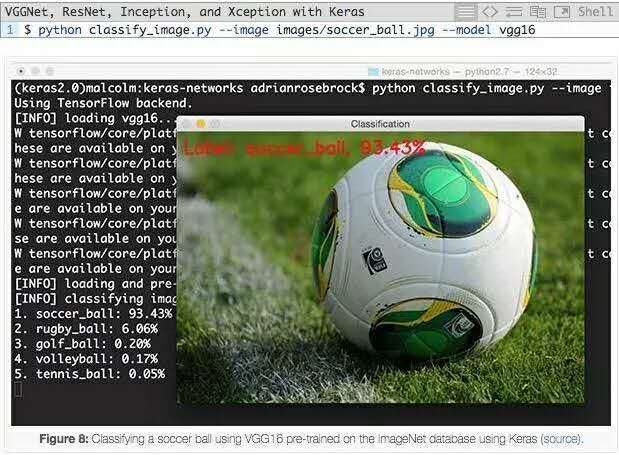
我们可以看到VGG16正确地将图像分类为“足球”,概率为93.43%。
要使用VGG19,我们只需要更改--network命令行参数:
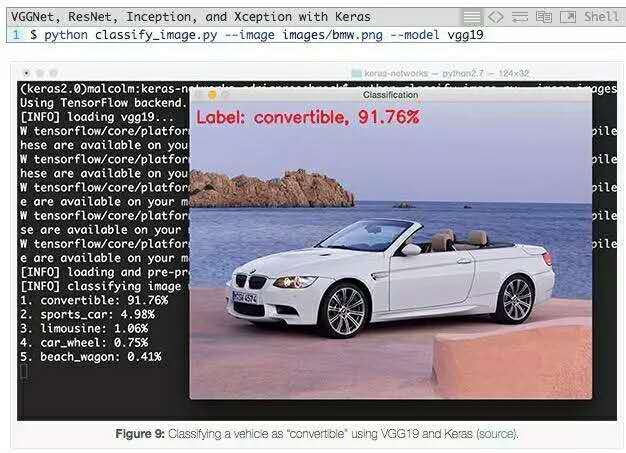
VGG19能够以91.76%的概率将输入图像正确地分类为“convertible”。看看其他top-5预测:“跑车”的概率为4.98%(其实是轿车),“豪华轿车”为1.06%(虽然不正确但看着合理),“车轮”为0.75%(从模型角度来说也是正确的,因为图像中有车轮)。
在以下示例中,我们使用预训练ResNet架构,可以看下top-5概率值:
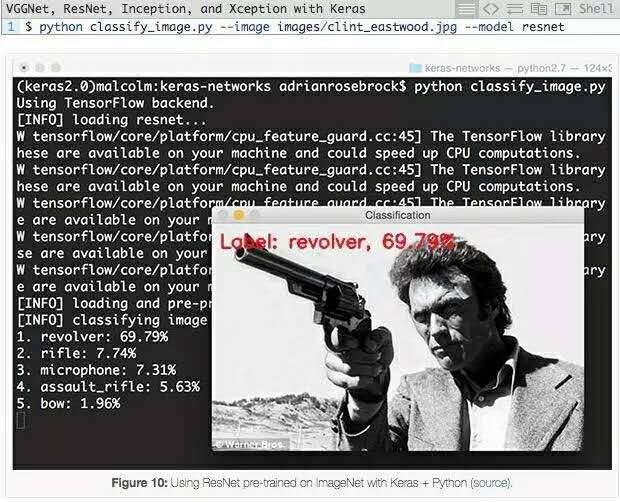
ResNet正确地将ClintEastwood持枪图像分类为“左轮手枪”,概率为69.79%。在top-5中还有,“步枪”为7.74%,“冲锋枪”为5.63%。由于"左轮手枪"的视角,枪管较长,CNN很容易认为是步枪,所以得到的步枪也较高。
下一个例子用ResNet对狗的图像进行分类:
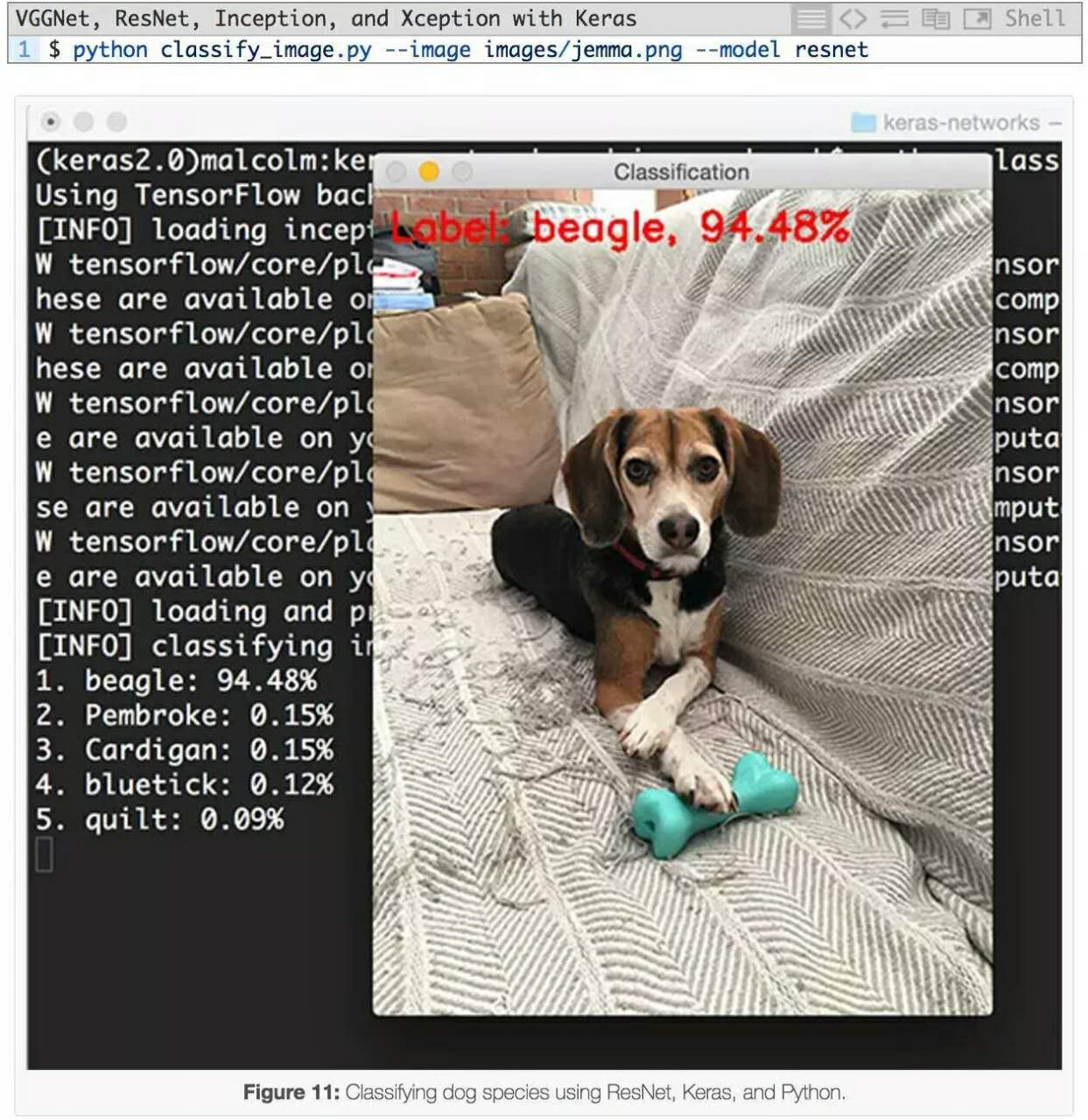
狗的品种被正确识别为“比格犬”,具有94.48%的概率。
然后,我尝试从这个图像中分出《加勒比海盗》演员约翰尼・德普:
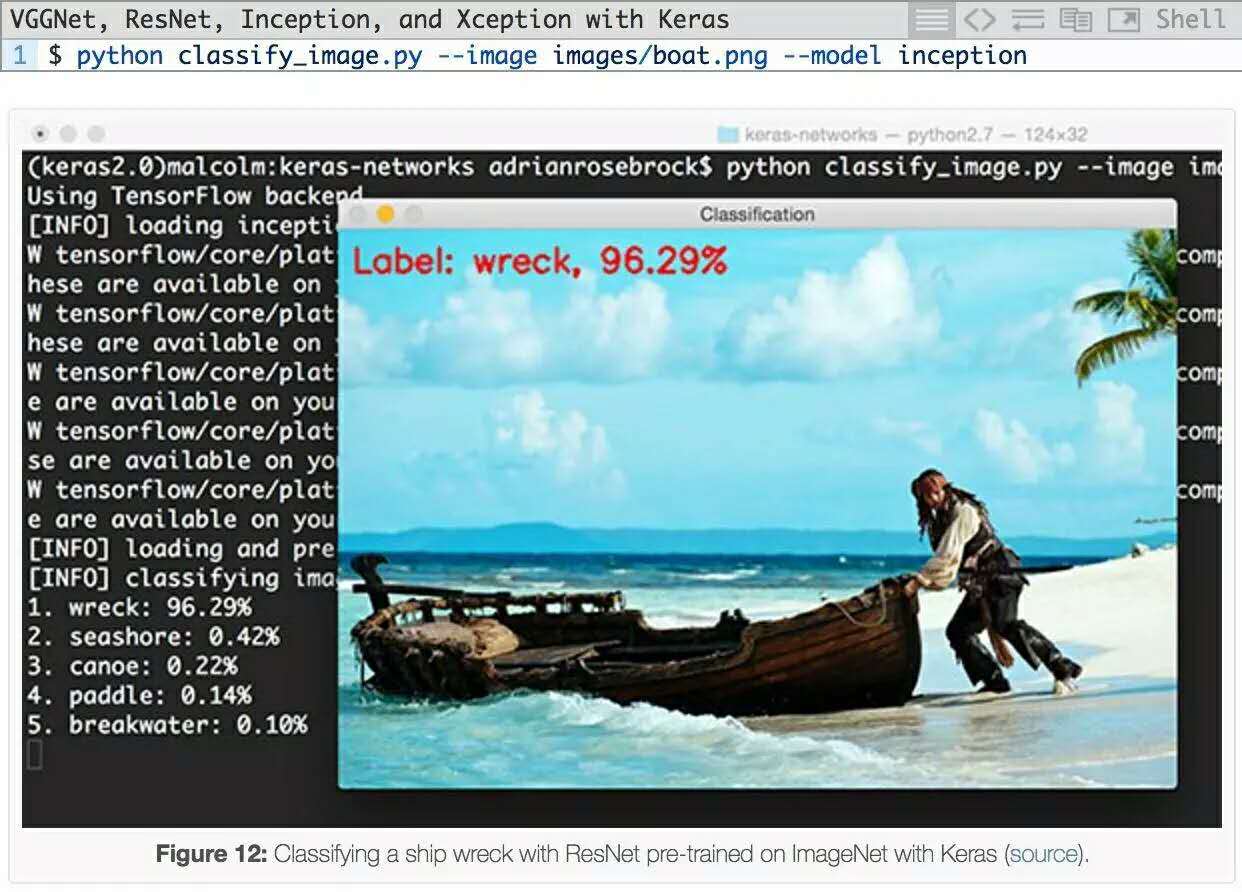
虽然ImageNet中确实有一个“船”类,但有趣的是,Inception网络能够正确地将场景识别为“(船)残骸”,且有具有96.29%概率的。所有其他预测标签,包括 “海滨”,“独木舟”,“桨”和“防波堤”都是相关的,在某些情况下也是绝对正确的。
对于Inception网络的另一个例子,我给办公室的沙发拍摄了照片:
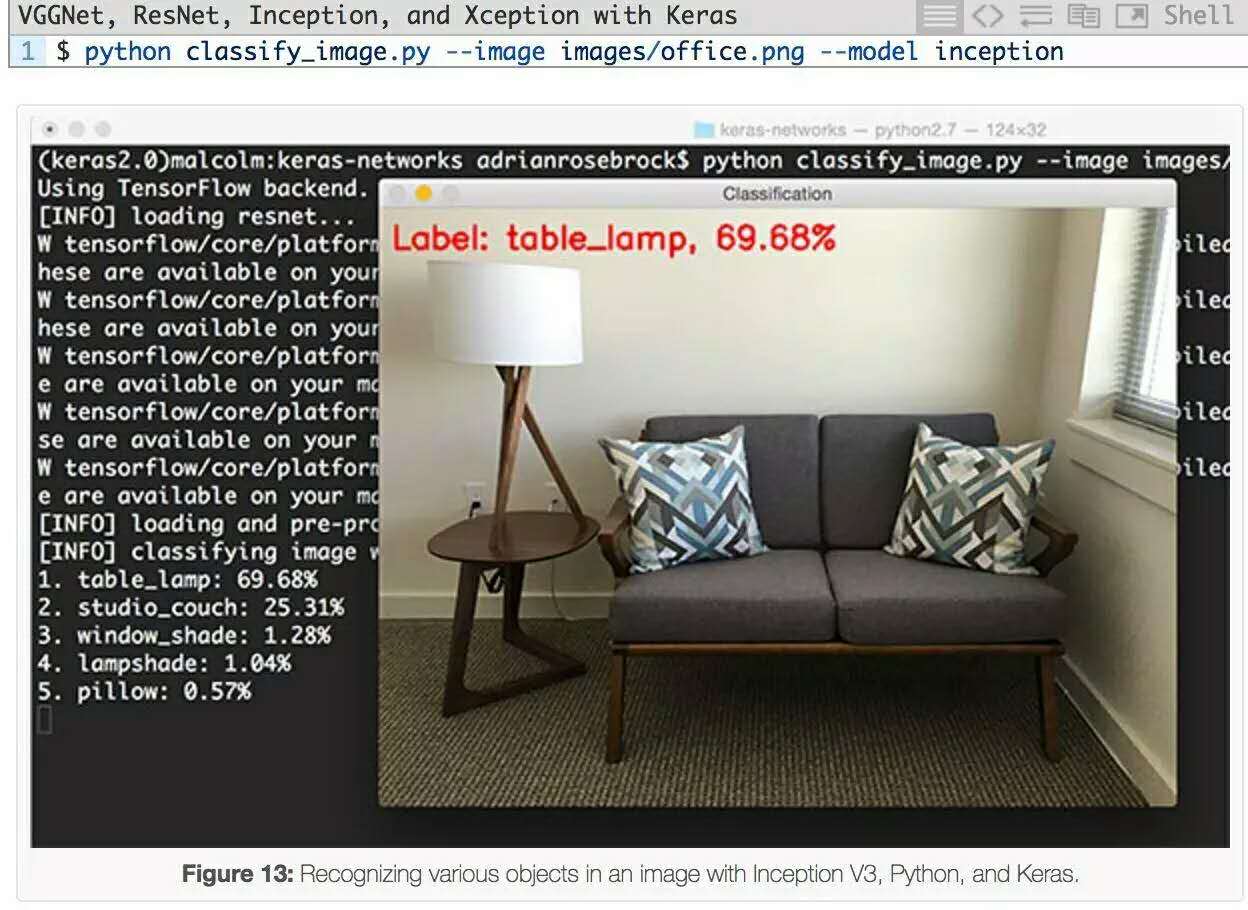
Inception正确地预测出图像中有一个“桌灯”,概率为69.68%。其他top-5预测也是完全正确的,包括“工作室沙发”、“窗帘”(图像的最右边,几乎不显眼)“灯罩”和“枕头”。
Inception虽然没有被用作对象检测器,但仍然能够预测图像中的前5个对象。卷积神经网络可以做到完美的对物体进行识别!
再来看下Xception:
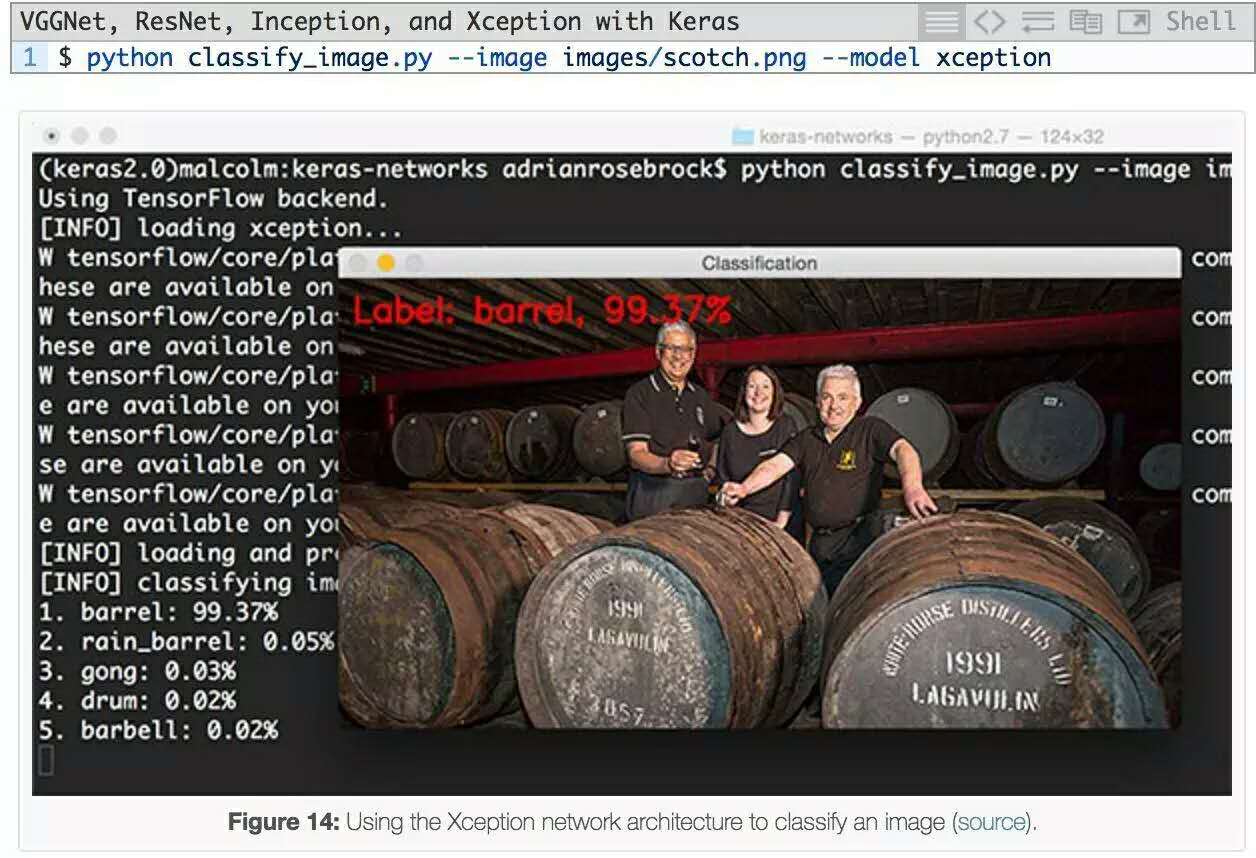
这里我们有一个苏格兰桶的图像,尤其是我最喜欢的苏格兰威士忌,拉加维林。Xception将此图像正确地分类为 “桶”。
最后一个例子是使用VGG16进行分类:
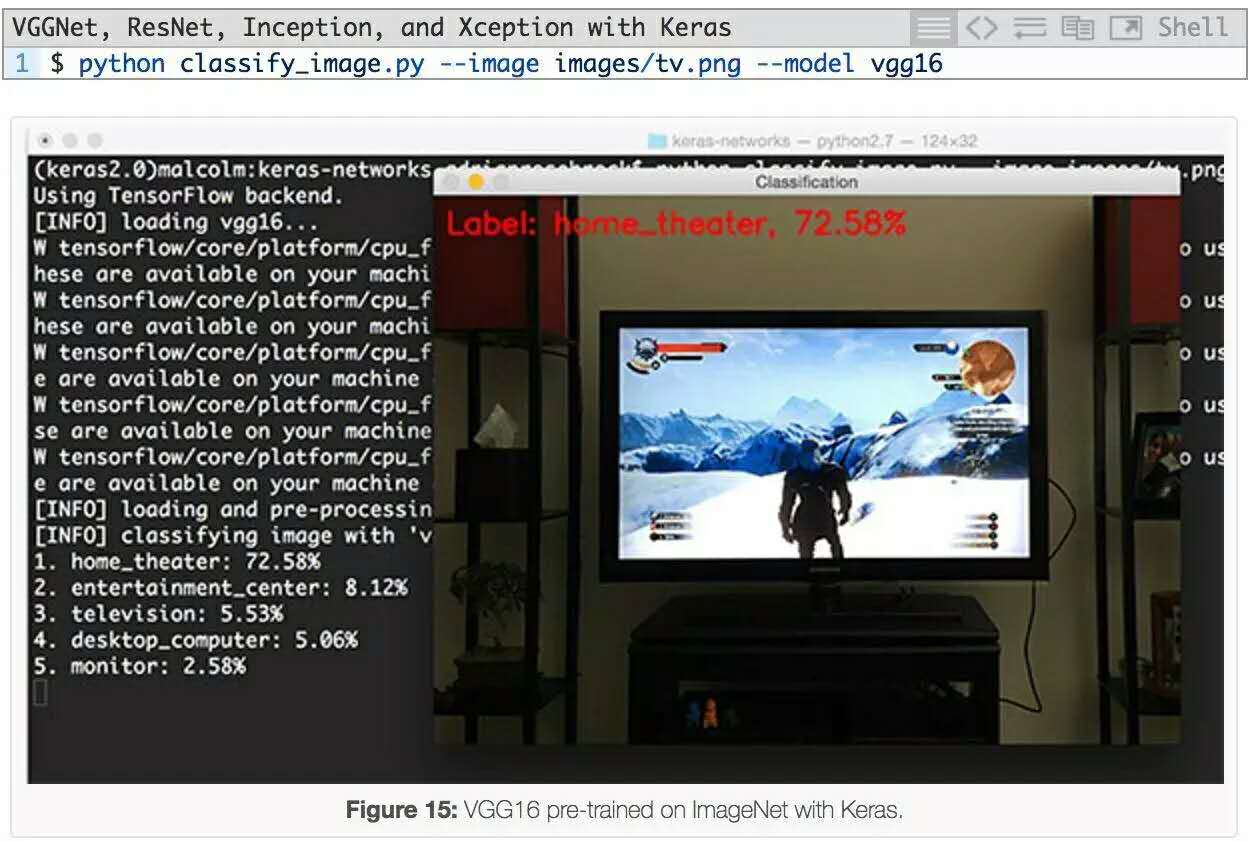
几个月前,当我打完《巫师 III》(The Wild Hunt)这局游戏之后,我给显示器照了这个照片。VGG16的第一个预测是“家庭影院”,这是一个合理的预测,因为top-5预测中还有一个“电视/监视器”。
从本文章的示例可以看出,在ImageNet数据集上预训练的模型能够识别各种常见的日常对象。你可以在你自己的项目中使用这个代码!
简单回顾一下,在今天的博文中,我们介绍了在Keras中五个卷积神经网络模型:
VGG16
VGG19
ResNet50
Inception V3
Xception
此后,我演示了如何使用这些神经网络模型来分类图像。希望本文对你有帮助。
原文地址:
http://www.pyimagesearch.com/2017/03/20/imagenet-vggnet-resnet-inception...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号