排列算法问题
| 类循环排列
# tree DFS def loop_permutation(arr, depth, path, result): if depth == len(arr): result.append(list(path)) return for n in arr: path.append(n) loop_permutation(arr, depth + 1, path, result) path.pop() ans = [] arr = [1,2] loop_permutation(arr, depth=0, path=[], result=ans) print(ans)
结果:
[[1, 1], [1, 2], [2, 1], [2, 2]]
| 全排列
对输入的 n 个数作全排列。 输入样例
3
1 2 3
输出样例
123
132
213
231
312
321
下面解法不是最优,见后交换。
# tree DFS def full_permutation(arr, used, depth, path, result): if depth == len(arr): result.append(list(path)) return for i,n in enumerate(arr): if used[i]: continue path.append(n) used[i] = 1 full_permutation(arr, used, depth + 1, path, result) used[i] = 0 path.pop() ans = [] arr = [1,2,3] used = [0]*len(arr) full_permutation(arr, used, depth=0, path=[], result=ans) print(ans)
全排列:
从n个不同元素中任取m(m≤n)个元素,按照一定的顺序排列起来,叫做从n个不同元素中取出m个元素的一个排列。当m=n时所有的排列情况叫全排列。
例如:
1 、2 、3三个元素的全排列为:
{1,2,3},{1,3,2},{2,1,3},{2,3,1},{3,1,2},{3,2,1}。
全排列的生成算法方法是将给定的序列中所有可能的全排列无重复无遗漏地枚举出来。此处全排列的定义是:从n个元素中取出m个元素进行排列,当n=m时这个排列被称为全排列。
字典序、邻位对换法、循环左移法、循环右移法、递增进位制法、递减进位制法都是常见的全排列生成算法。
解法1(递归)
如下图:要对1、2、3、4进行排序,第一个位置上的元素有四种可能:1或2或3或4,假如已经确定了第一个元素为4,剩下的第二个位置上可以是1、2、3,很显然这具有递归结构,如果原始要排列的数组顺序为1、2、3、4,现在只要分别交换1、2,1、3,1、4然后对剩下的3个元素进行递归的排列。
看下面的图,观察就知道交换思路了。f([1,2,3])=1+f([2,3] U 2+f([3,4]) U 3+f([1,2]))!
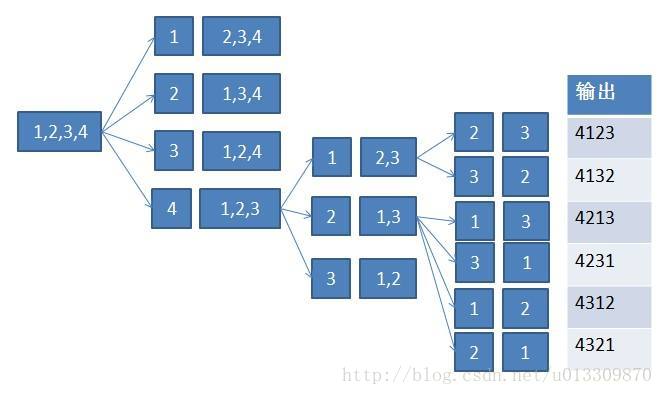
代码:
public void Permutation(char chs[],int start )
{
if(start==chs.length-1)
{
Arrays.toString(chs);
//如果已经到了数组的最后一个元素,前面的元素已经排好,输出。
}
for(int i=start;i<=chs.length-1;i++)
{
//把第一个元素分别与后面的元素进行交换,递归的调用其子数组进行排序
Swap(chs,i,start);
Permutation(chs,start+1);
Swap(chs,i,start);
//子数组排序返回后要将第一个元素交换回来。
//如果不交换回来会出错,比如说第一次1、2交换,第一个位置为2,子数组排序返回后如果不将1、2
//交换回来第二次交换的时候就会将2、3交换,因此必须将1、2交换使1还是在第一个位置
}
}
public void Swap(char chs[],int i,int j)
{
char temp;
temp=chs[i];
chs[i]=chs[j];
chs[j]=temp;
}
python实现:
def full_permutation(arr, depth, result): if depth == len(arr): result.append(list(arr)) return for i in range(depth, len(arr)): arr[i], arr[depth] = arr[depth], arr[i] full_permutation(arr, depth + 1, result) arr[i], arr[depth] = arr[depth], arr[i] ans = [] arr = [1,2,3] full_permutation(arr, depth=0, result=ans) print(ans)
结果:[[1, 2, 3], [1, 3, 2], [2, 1, 3], [2, 3, 1], [3, 2, 1], [3, 1, 2]]
递归方法会对重复元素进行交换比如使用递归对{1,1}进行全排序会输出:{1,1},{1,1}两个重复的结果。要在排序的时候去掉重复结果,可以修改一下代码如下:
public static void Permutation(char chs[],int start)
{
if(start==end)
{
list.add(new String(chs));
}
for(int i=start;i<=chs.length-1;i++)
{
if(i==start||chs[i]!=chs[start])
{
//在排列的时候进行判断如果后面的元素与start相同时就不进行排序。
//这样就可以避免对重复元素进行排序
Swap(chs,i,start);
Permutation(chs,start+1);
Swap(chs,i,start);
}
}
}
# tree DFS def full_permutation(arr, depth, result): if depth == len(arr): result.append(list(arr)) return for i in range(depth, len(arr)): if i == depth or arr[i] != arr[depth]: arr[i], arr[depth] = arr[depth], arr[i] full_permutation(arr, depth + 1, result) arr[i], arr[depth] = arr[depth], arr[i] ans = [] arr = [1,1,3] full_permutation(arr, depth=0, result=ans) print(ans)
结果:[[1, 1, 3], [1, 3, 1], [3, 1, 1]]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号