
神经网络中的激活函数——加入一些非线性的激活函数,整个网络中就引入了非线性部分,sigmoid 和 tanh作为激活函数的话,一定要注意一定要对 input 进行归一话,但是 ReLU 并不需要输入归一化
1 什么是激活函数?
激活函数,并不是去激活什么,而是指如何把“激活的神经元的特征”通过函数把特征保留并映射出来(保留特征,去除一些数据中是的冗余),这是神经网络能解决非线性问题关键。
目前知道的激活函数有如下几个:sigmoid,tanh,ReLu,softmax。
simoid函数也称S曲线:f(x)=11+e−x
tanh:f(x)=tanh(x)
ReLU:f(x)=max(x,0)
softmax:f(x)=log(1+exp(x))
2 神经网络中为什么要使用激活函数?
- 激活函数是用来加入非线性因素的,因为线性模型的表达力不够
这句话字面的意思很容易理解,但是在具体处理图像的时候是什么情况呢?我们知道在神经网络中,对于图像,我们主要采用了卷积的方式来处理,也就是对每个像素点赋予一个权值,这个操作显然就是线性的。但是对于我们样本来说,不一定是线性可分的,为了解决这个问题,我们可以进行线性变化,或者我们引入非线性因素,解决线性模型所不能解决的问题。
这里插一句,来比较一下上面的那些激活函数,因为神经网络的数学基础是处处可微的,所以选取的激活函数要能保证数据输入与输出也是可微的,运算特征是不断进行循环计算,所以在每代循环过程中,每个神经元的值也是在不断变化的。
这就导致了tanh特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果显示出来,但有是,在特征相差比较复杂或是相差不是特别大时,需要更细微的分类判断的时候,sigmoid效果就好了。
还有一个东西要注意,sigmoid 和 tanh作为激活函数的话,一定要注意一定要对 input 进行归一话,否则激活后的值都会进入平坦区,使隐层的输出全部趋同,但是 ReLU 并不需要输入归一化来防止它们达到饱和。
- 构建稀疏矩阵,也就是稀疏性,这个特性可以去除数据中的冗余,最大可能保留数据的特征,也就是大多数为0的稀疏矩阵来表示。
其实这个特性主要是对于Relu,它就是取的max(0,x),因为神经网络是不断反复计算,实际上变成了它在尝试不断试探如何用一个大多数为0的矩阵来尝试表达数据特征,结果因为稀疏特性的存在,反而这种方法变得运算得又快效果又好了。
所以我们可以看到目前大部分的卷积神经网络中,基本上都是采用了ReLU 函数。
摘自:http://blog.csdn.net/huahuazhu/article/details/74188288
神经网络中如果不加入激活函数,其一定程度可以看成线性表达,最后的表达能力不好,如果加入一些非线性的激活函数,整个网络中就引入了非线性部分,增加了网络的表达能力。目前比较流行的激活函数主要分为以下7种:
1.sigmoid
2.tanh
3.ReLu
4.Leaky ReLu
5.PReLu
6.RReLu
7 Maxout
总结
参考文献:
[ReLu]:Rectifier Nonlinearities Improve Neural Network Acoustic Models
[PRelu]:Delving Deep into Rectifiers:Surpassing Human-Level Performance on ImageNet Classification
ReLU
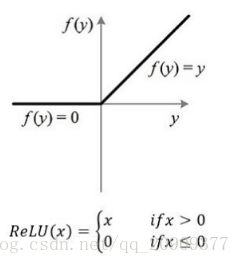
tensorflow中:tf.nn.relu(features, name=None)
LReLU
(Leaky-ReLU)
其中ai
是固定的。i表示不同的通道对应不同的ai
.
tensorflow中:tf.nn.leaky_relu(features, alpha=0.2, name=None)
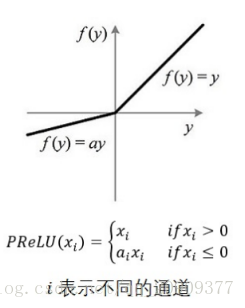
PReLU
其中ai
是可以学习的的。如果ai=0,那么 PReLU 退化为ReLU;如果 ai是一个很小的固定值(如ai=0.01),则 PReLU 退化为 Leaky ReLU(LReLU)。
PReLU 只增加了极少量的参数,也就意味着网络的计算量以及过拟合的危险性都只增加了一点点。特别的,当不同 channels 使用相同的ai时,参数就更少了。BP 更新ai
时,采用的是带动量的更新方式(momentum)。
tensorflow中:没找到啊!
CReLU
(Concatenated Rectified Linear Units)

tensorflow中:tf.nn.crelu(features, name=None)
ELU
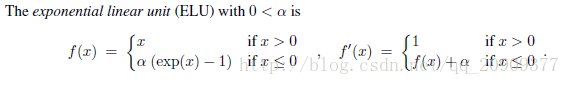
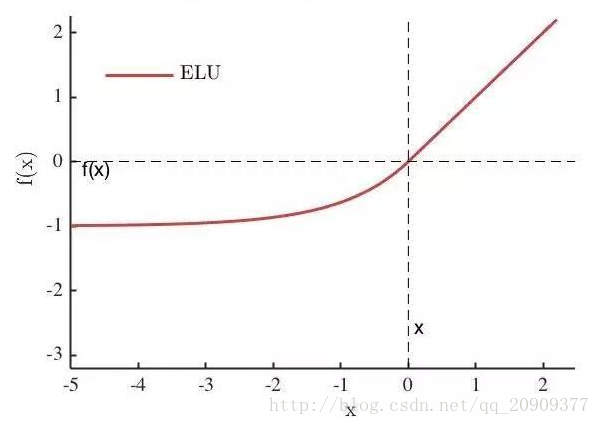
其中α是一个可调整的参数,它控制着ELU负值部分在何时饱和。
右侧线性部分使得ELU能够缓解梯度消失,而左侧软饱能够让ELU对输入变化或噪声更鲁棒。ELU的输出均值接近于零,所以收敛速度更快
tensorflow中:tf.nn.elu(features, name=None)
SELU
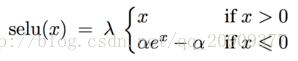
经过该激活函数后使得样本分布自动归一化到0均值和单位方差(自归一化,保证训练过程中梯度不会爆炸或消失,效果比Batch Normalization 要好)
其实就是ELU乘了个lambda,关键在于这个lambda是大于1的。以前relu,prelu,elu这些激活函数,都是在负半轴坡度平缓,这样在activation的方差过大的时候可以让它减小,防止了梯度爆炸,但是正半轴坡度简单的设成了1。而selu的正半轴大于1,在方差过小的的时候可以让它增大,同时防止了梯度消失。这样激活函数就有一个不动点,网络深了以后每一层的输出都是均值为0方差为1。
tensorflow中:tf.nn.selu(features, name=None)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号