RBF网络——核心思想:把向量从低维m映射到高维P,低维线性不可分的情况到高维就线性可分了
RBF网络能够逼近任意的非线性函数,可以处理系统内的难以解析的规律性,具有良好的泛化能力,并有很快的学习收敛速度,已成功应用于非线性函数逼近、时间序列分析、数据分类、模式识别、信息处理、图像处理、系统建模、控制和故障诊断等。
输入X是个m维的向量,样本容量为P,P>m。可以看到输入数据点Xp是径向基函数φp的中心。隐藏层的作用是把向量从低维m映射到高维P,低维线性不可分的情况到高维就线性可分了。

RBF Network 通常只有三层。输入层、中间层计算输入 x 矢量与样本矢量 c 欧式距离的 Radial Basis Function (RBF) 的值,输出层算它们的线性组合。
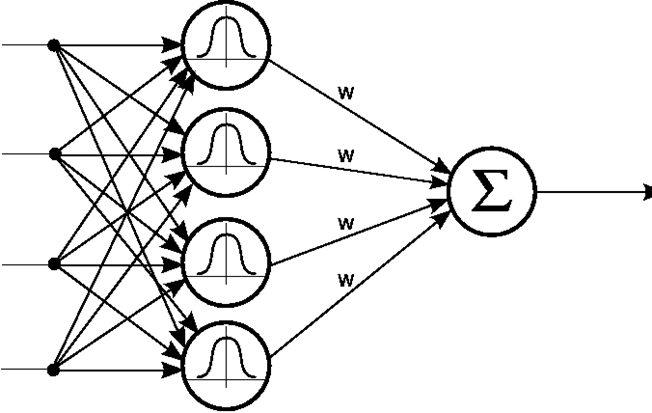 图一
图一
如此可见,和普通的三层神经网络,RBF 神经网络的区别在中间层。中间层采用 RBF Kernel 对输入作非线性变换,以便输出层训练线性分类器。
那么RBF Kernel 有什么特点呢?
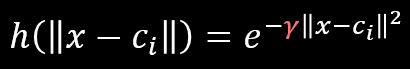
图二 Radial Basis Function
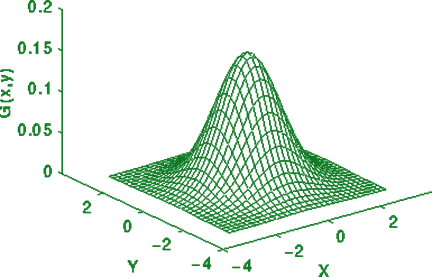
图三 Plot of Radial Basis Function with 2D input
RBF 拥有较小的支集。针对选定的样本点,它只对样本附近的输入有反应,如下图。
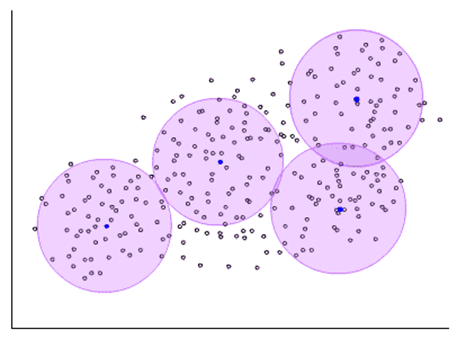 图四 RBF 使样本点只被附近(圈内)的输入激活
图四 RBF 使样本点只被附近(圈内)的输入激活T. Poggio 将 RBF 比作记忆点。与记忆样本越近,该记忆就越被激活。
有的同学看到这,也许会说:这不就是 SVM with RBF Kernel 么。
这些同学对了一半。光看模型,RBF Network 确实与 SVM with RBF kernel 无异。区别在于训练方式。
其实在深度学习出现之前,RBF神经网络就已经提出了 2-stage training。
第一阶段为非监督学习,从数据中选取记忆样本(图四中的紫色中心)。例如聚类算法可在该阶段使用。
第二阶段为监督学习,训练记忆样本与样本输出的联系。该阶段根据需要可使用 AD/BP。
1. RBF神经网络的训练过程可以使用BP,因此应纳入BP神经网络的范畴。
2. RBF神经网络的训练分两阶段,这一点类似深度学习,且使RBF神经网络不同于SVM with RBF kernel。
参考:
https://www.zhihu.com/question/44328472
https://www.cnblogs.com/zhangchaoyang/articles/2591663.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号