HMM(隐马尔科夫模型)——本质上就是要预测出股市的隐藏状态(牛市、熊市、震荡、反弹等)和他们之间的转移概率
摘自:http://blog.csdn.net/baskbeast/article/details/51218777
可以看 《统计学习方法》里的介绍
举一个日常生活中的例子,我们希望根据当前天气的情况来预测未来天气情况。一种办法就是假设这个模型的每个状态都只依赖于前一个的状态,即马尔科夫假设,这个假设可以极大简化这个问题。当然,这个例子也是有些不合实际的。但是,这样一个简化的系统可以有利于我们的分析,所以我们通常接受这样的假设,因为我们知道这样的系统能让我们获得一些有用的信息,尽管不是十分准确的。 上面的图显示了天气进行转移的模型。
上面的图显示了天气进行转移的模型。
注意一个含有N个状态的一阶过程有N²个状态转移。每一个转移的概率叫做状态转移概率,就是从一个状态转移到另一个状态的概率。这所有的N²个概率可以用一个状态转移矩阵来表示,上面天气例子的状态转移矩阵如下: 这个矩阵表示,如果昨天是阴天,那么今天有25%的可能是晴天,12.5%的概率是阴天,62.5%的概率会下雨,很明显,矩阵中每一行的和都是1。
这个矩阵表示,如果昨天是阴天,那么今天有25%的可能是晴天,12.5%的概率是阴天,62.5%的概率会下雨,很明显,矩阵中每一行的和都是1。
为了初始化这样一个系统,我们需要一个初始的概率向量:
这个向量表示第一天是晴天。到这里,我们就为上面的一阶马尔科夫过程定义了以下三个部分:
- 状态:晴天、阴天和下雨。
- 初始向量:定义系统在时间为0的时候的状态的概率。
- 状态转移矩阵:每种天气转换的概率。所有的能被这样描述的系统都是一个马尔科夫过程。
然而,当马尔科夫过程不够强大的时候,我们又该怎么办呢?在某些情况下,马尔科夫过程不足以描述我们希望发现的模式。
比如我们的股市,如果只是观测市场,我们只能知道当天的价格、成交量等信息,但是并不知道当前股市处于什么样的状态(牛市、熊市、震荡、反弹等等),在这种情况下我们有两个状态集合,一个可以观察到的状态集合(股市价格成交量状态等)和一个隐藏的状态集合(股市状况)。我们希望能找到一个算法可以根据股市价格成交量状况和马尔科夫假设来预测股市的状况。
在上面的这些情况下,可以观察到的状态序列和隐藏的状态序列是概率相关的。于是我们可以将这种类型的过程建模为有一个隐藏的马尔科夫过程和一个与这个隐藏马尔科夫过程概率相关的并且可以观察到的状态集合,就是隐马尔可夫模型。
隐马尔可夫模型(Hidden Markov Model)
是一种统计模型,用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数,然后利用这些参数来作进一步的分析。下图是一个三个状态的隐马尔可夫模型状态转移图,其中x表示隐含状态,y表示可观察的输出,a表示状态转换概率,b表示输出概率。 用一个掷筛子的例子阐述一下:假设我手里有三个不同的骰子。第一个骰子是我们平常见的骰子(称这个骰子为D6),6个面,每个面(1,2,3,4,5,6)出现的概率是1/6。第二个骰子是个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。第三个骰子有八个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。
用一个掷筛子的例子阐述一下:假设我手里有三个不同的骰子。第一个骰子是我们平常见的骰子(称这个骰子为D6),6个面,每个面(1,2,3,4,5,6)出现的概率是1/6。第二个骰子是个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。第三个骰子有八个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。
假设我们开始掷骰子,我们先从三个骰子里挑一个,挑到每一个骰子的概率都是1/3。然后我们掷骰子,得到一个数字,1,2,3,4,5,6,7,8中的一个。不停的重复上述过程,我们会得到一串数字,每个数字都是1,2,3,4,5,6,7,8中的一个。例如我们可能得到这么一串数字(掷骰子10次):1
6 3 5 2 7 3 5 2 4
这串数字叫做可见状态链。但是在隐马尔可夫模型中,我们不仅仅有这么一串可见状态链,还有一串隐含状态链。在这个例子里,这串隐含状态链就是你用的骰子的序列。比如,隐含状态链有可能是:D4 D6 D8 D6 D4 D8 D6 D6 D6 D4。
一般来说,HMM中说到的马尔可夫链其实是指隐含状态链,因为隐含状态(骰子)之间存在转换概率。在我们这个例子里,D6的下一个状态是D4,D6,D8的概率都是1/3。D4,D8的下一个状态是D4,D6,D8的转换概率也都一样是1/3。这样设定是为了最开始容易说清楚,但是我们其实是可以随意设定转换概率的。比如,我们可以这样定义,D6后面不能接D4,D6后面是D6的概率是0.9,是D8的概率是0.1。这样就是一个新的HMM。
同样的,尽管可见状态之间没有转换概率,但是隐含状态和可见状态之间有一个概率叫做输出概率。就我们的例子来说,六面骰子(D6)产生1的输出概率是1/6。产生2,3,4,5,6的概率也都是1/6。我们同样可以对输出概率进行其他定义。比如,我有一个被赌场动过手脚的六面骰子,掷出来是1的概率更大,是1/2,掷出来是2,3,4,5,6的概率是1/10。

其实对于HMM来说,如果提前知道所有隐含状态之间的转换概率和所有隐含状态到所有可见状态之间的输出概率,做模拟是相当容易的。但是应用HMM模型时候呢,往往是缺失了一部分信息的,有时候你知道骰子有几种,每种骰子是什么,但是不知道掷出来的骰子序列;有时候你只是看到了很多次掷骰子的结果,剩下的什么都不知道。如果应用算法去估计这些缺失的信息,就成了一个很重要的问题。
和HMM模型相关的算法主要分为三类,分别解决三种问题:
- 知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道每次掷出来的都是哪种骰子(隐含状态链)。
- 还是知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道掷出这个结果的概率。
- 知道骰子有几种(隐含状态数量),不知道每种骰子是什么(转换概率),观测到很多次掷骰子的结果(可见状态链),我想反推出每种骰子是什么(转换概率)。
如果要解决上面股市中的问题,我们就需要解决问题1和问题3,下面我们就看看如何实现。
HMM在股票市场中的应用
我们假设隐藏状态数量是6,即假设股市的状态有6种,虽然我们并不知道每种状态到底是什么,但是通过后面的图我们可以看出那种状态下市场是上涨的,哪种是震荡的,哪种是下跌的。可观测的特征状态我们选择了3个指标进行标示,进行预测的时候假设假设所有的特征向量的状态服从高斯分布,这样就可以使用 hmmlearn 这个包中的 GaussianHMM 进行预测了。下面我会逐步解释。
首先导入必要的包:
from hmmlearn.hmm import GaussianHMM
import numpy as np
from matplotlib import cm, pyplot as plt
import matplotlib.dates as dates
import pandas as pd
import datetime
测试时间从2005年1月1日到2015年12月31日,拿到每日沪深300的各种交易数据。
#6个隐藏状态
data = get_price('CSI300.INDX',start_date=beginDate, end_date=endDate,frequency='1d')
data[0:9]
拿到每日成交量和收盘价的数据。
计算每日最高最低价格的对数差值,作为特征状态的一个指标。
Out[4]:
计算每5日的指数对数收益差,作为特征状态的一个指标。
#这个作为后面计算收益使用
logRet_5 = np.log(np.array(close[5:])) - np.log(np.array(close[:-5]))
logRet_5
计算每5日的指数成交量的对数差,作为特征状态的一个指标。
Out[6]:
由于计算中出现了以5天为单位的计算,所以要调整特征指标的长度。
把我们的特征状态合并在一起。
Out[8]:
下面运用 hmmlearn 这个包中的 GaussianHMM 进行预测。
Out[9]:
关于 covariance_type 的参数有下面四种:
spherical:是指在每个马尔可夫隐含状态下,可观察态向量的所有特性分量使用相同的方差值。对应协方差矩阵的非对角为0,对角值相等,即球面特性。这是最简单的高斯分布PDF。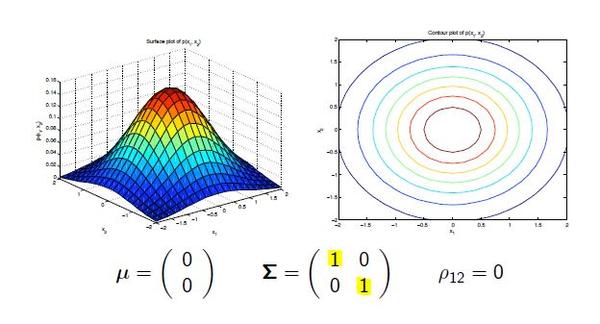 diag:是指在每个马尔可夫隐含状态下,可观察态向量使用对角协方差矩阵。对应协方差矩阵非对角为0,对角值不相等。diag是hmmlearn里面的默认类型。
diag:是指在每个马尔可夫隐含状态下,可观察态向量使用对角协方差矩阵。对应协方差矩阵非对角为0,对角值不相等。diag是hmmlearn里面的默认类型。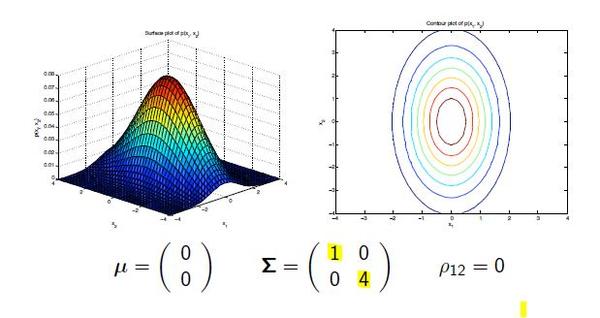 full:是指在每个马尔可夫隐含状态下,可观察态向量使用完全协方差矩阵。对应的协方差矩阵里面的元素都是不为零。
full:是指在每个马尔可夫隐含状态下,可观察态向量使用完全协方差矩阵。对应的协方差矩阵里面的元素都是不为零。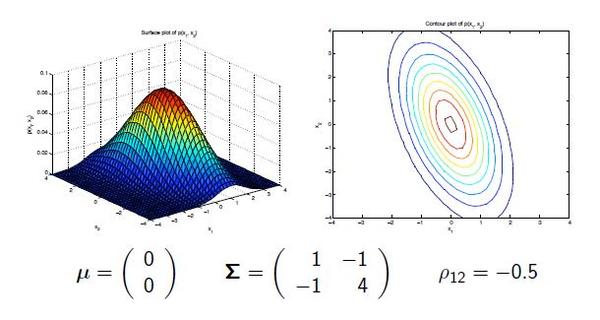 tied:是指所有的马尔可夫隐含状态使用相同的完全协方差矩阵。
tied:是指所有的马尔可夫隐含状态使用相同的完全协方差矩阵。
这四种PDF类型里面,spherical, diag和full代表三种不同的高斯分布概率密度函数,而tied则可以看作是GaussianHMM和GMMHMM的特有实现。其中,full是最强大的,但是需要足够多的数据来做合理的参数估计;spherical是最简单的,通常用在数据不足或者硬件平台性能有限的情况之下;而diag则是这两者一个折中。在使用的时候,需要根据可观察态向量不同特性的相关性来选择合适的类型。
转自知乎用户Aubrey Li
我们把每个预测的状态用不同颜色标注在指数曲线上看一下结果。
for i in range(model.n_components):
pos = (hidden_states==i)
plt.plot_date(Date[pos],close[pos],'o',label='hidden state %d'%i,lw=2)
plt.legend(loc="left")
从图中可以比较明显的看出绿色的隐藏状态代表指数大幅上涨,浅蓝色和黄色的隐藏状态代表指数下跌。
为了更直观的表现不同的隐藏状态分别对应了什么,我们采取获得隐藏状态结果后第二天进行买入的操作,这样可以看出每种隐藏状态代表了什么。
for i in range(model.n_components):
pos = (hidden_states==i)
pos = np.append(0,pos[:-1])#第二天进行买入操作
df = res.logRet_1
res['state_ret%s'%i] = df.multiply(pos)
plt.plot_date(Date,np.exp(res['state_ret%s'%i].cumsum()),'-',label='hidden state %d'%i)
plt.legend(loc="left")
可以看到,隐藏状态1是一个明显的大牛市阶段,隐藏状态0是一个缓慢上涨的阶段(可能对应反弹),隐藏状态3和5可以分别对应震荡下跌的大幅下跌。其他的两个隐藏状态并不是很明确。由于股指期货可以做空,我们可以进行如下操作:当处于状态0和1时第二天做多,当处于状态3和5第二天做空,其余状态则不持有。
#做多
short = (hidden_states==3) + (hidden_states == 5) #做空
long = np.append(0,long[:-1]) #第二天才能操作
short = np.append(0,short[:-1]) #第二天才能操作
收益曲线图如下:
Out[13]:
可以看到效果还是很不错的。但事实上该结果是有些问题的。真实操作时,我们并没有未来的信息来训练模型。不过可以考虑用历史数据进行训练,再对之后的数据进行预测。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号