
ES查看segment大小
摘自:http://www.aboutyun.com/thread-17078-1-1.html
Segment Memory
Segment不是file吗?segment memory又是什么?前面提到过,一个segment是一个完备的lucene倒排索引,而倒排索引是通过词典 (Term Dictionary)到文档列表(Postings List)的映射关系,快速做查询的。 由于词典的size会很大,全部装载到heap里不现实,因此Lucene为词典做了一层前缀索引(Term Index),这个索引在Lucene4.0以后采用的数据结构是FST (Finite State Transducer)。 这种数据结构占用空间很小,Lucene打开索引的时候将其全量装载到内存中,加快磁盘上词典查询速度的同时减少随机磁盘访问次数。
下面是词典索引和词典主存储之间的一个对应关系图:
<ignore_js_op>
说了这么多,要传达的一个意思就是,ES的data node存储数据并非只是耗费磁盘空间的,为了加速数据的访问,每个segment都有会一些索引数据驻留在heap里。因此segment越多,瓜分掉的heap也越多,并且这部分heap是无法被GC掉的! 理解这点对于监控和管理集群容量很重要,当一个node的segment memory占用过多的时候,就需要考虑删除、归档数据,或者扩容了。
怎么知道segment memory占用情况呢? CAT API可以给出答案。
1. 查看一个索引所有segment的memory占用情况:
<ignore_js_op>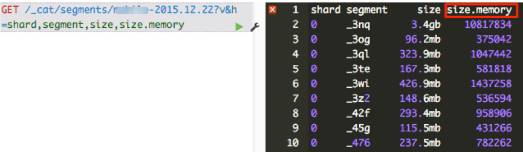
2. 查看一个node上所有segment占用的memory总和:
<ignore_js_op>
那么有哪些途径减少data node上的segment memory占用呢? 总结起来有三种方法:
- 删除不用的索引。
- 关闭索引 (文件仍然存在于磁盘,只是释放掉内存)。需要的时候可以重新打开。
- 定期对不再更新的索引做optimize (ES2.0以后更改为force merge api)。这Optimze的实质是对segment file强制做合并,可以节省大量的segment memory。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号