
揭秘FaceBook Puma演变及发展——FaceBook公司的实时数据分析平台是建立在Hadoop 和Hive的基础之上,这个根能立稳吗?hive又是sql的Map reduce任务拆分,底层还是依赖hbase和hdfs存储
在12月2日下午的“大数据技术与应用”分论坛的第一场演讲中,来自全球知名互联网公司——FaceBook公司的软件工程师、研发经理邵铮就带来了一颗重磅炸弹,他将为我们讲解FaceBook公司的实时数据处理分析平台的核心——Puma的演进以及未来的发展思路。
FaceBook公司自成立以来发展就非常迅猛,时至今日,每天都有数以万计的人活跃在FaceBook之上,这一庞大的用户群体吸引了大量的企业的注意力,他们希望通过FaceBook这一平台对自己的产品或服务进行营销,以精准找到自己的潜在用户。要精准找到自己的客户,必然要对FaceBook网站用户的实时信息进行分析,FaceBook公司提供的实时数据分析工具就凸显出重要作用。

据邵铮工程师介绍,FaceBook公司的实时数据分析平台是建立在Hadoop 和Hive的基础之上的,Hadoop Hive集群共有超过3000个节点,共同完成对数据的实时处理分析。如上图所示,数据流通过程涉及的环节较多,每个环节的延迟都会对数据的分析处理能力产生影响,为了最大地降低延迟,尽最大可能为各个用户提供实时查询结果,就要尽可能低地较少每个环节的延迟。
邵铮工程师在本次技术课程中分享了两个关键之处,一是Scribe,另一个则是Hadoop下的由Facebook公司开发改良的Puma环节。
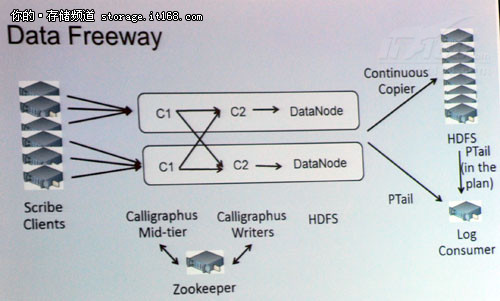
邵铮工程师给我们分享了现在Facebook公司所使用的Scribe,如上图所示。并重点给我们讲解了Puma的演进与未来的发展方向。
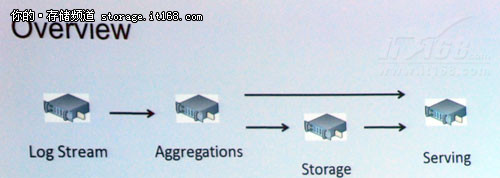
上图是邵铮工程师认为的Puma理想工作流程,但实际环境中因为各种因素的制约,实际上不太可能达到这一理想流程。

上图为Puma的第二个版本,Puma2的命名是为了方便记忆和说明。但据邵铮工程师介绍,Puma同样存在一些局限。他说,HBase的写入速度较快,但读取速度就相对较慢。
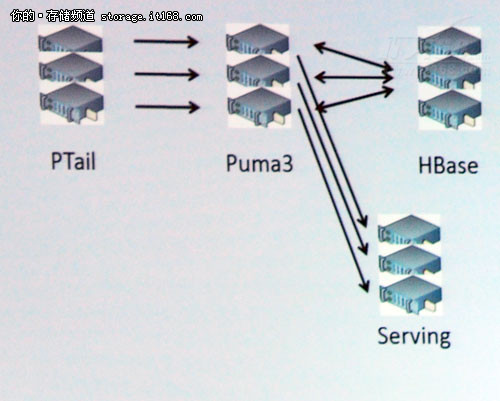
上图为Puma3的拓扑图,相对于Puma2,其延迟将大幅降低。据悉,Facebook公司目前对实时数据的处理分析能力在10秒多一点,但在未来将缩短到5秒甚至更短的时间。因为Facebook公司所具有的特殊性,其在未来将大幅缩短写性能,初步预期,相比于现在,将缩短25%的总体时间。现在每个机柜的内存为60GB,但在未来,其将大量部署SSD以替代内存,其内存大小将是现在的十倍,即600GB。
邵铮工程师表示,在未来,将对数据调度提供更好的支持,在这点上,需要对Puma进行简单的调度,因为连续的工作负载;并且将进行大规模普及,将Hive迁移到日常的报告查询。并且邵铮工程师透露了一个令人极度兴奋的消息,这些即将开源,将免费的开放给其他工程师。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号