
百度的TSDB——可针对tag查询,应该类似kairosDB
天工架构
目前,天工平台的服务主要由物接入、物解析、物管理、规则引擎和时序数据库组成,并可无缝对接百度云天算智能大数据平台及基础平台产品,可提供千万级设备接入的能力,百万数据点每秒的读写性能,超高的压缩率,端到端的安全防护。其基本架构如下图所示:
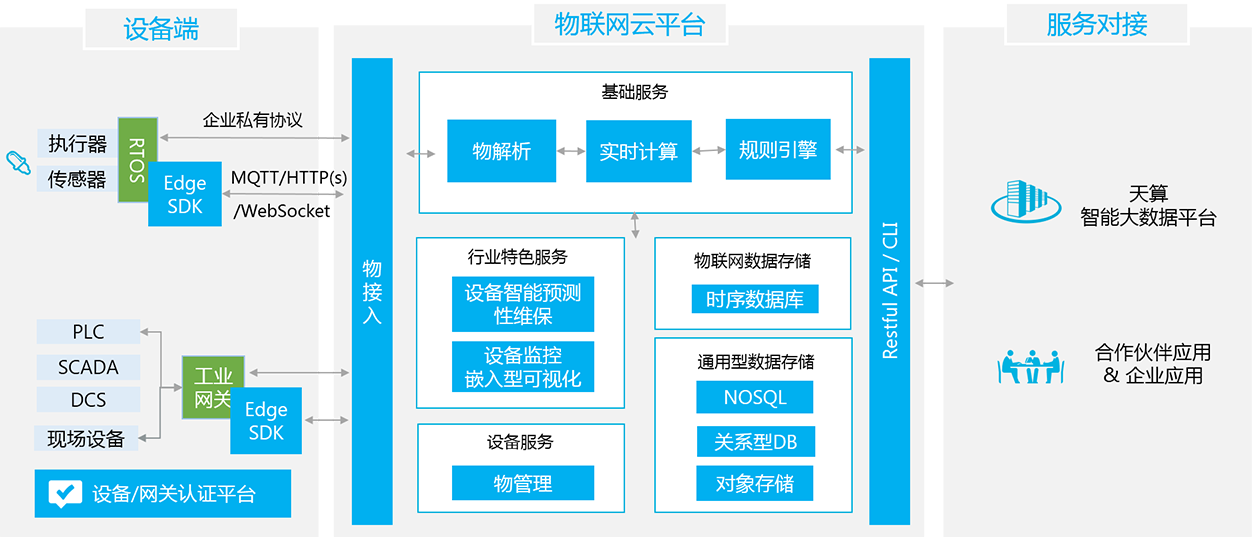
-
时序数据库:用于管理时间序列数据的专业化数据库。区别于传统的关系型数据库,时序数据库针对时间序列数据的存储、查询和展现进行了专门的优化,从而获得极高的数据压缩能力、极优的查询性能,特别适用于物联网应用场景。
-
天算智能大数据平台:提供了完备的大数据托管服务、智能API、众多业务场景模板以及人脸识别、文字识别、语音识别等服务,帮助用户实现智能业务。
百度的大数据计算系统已成功应用于百度搜索、广告、百度地图、百度糯米、百度外卖等几乎全部的核心业务,经过多年的业务应用锤炼和技术演进,百度大数据计算系统的集群规模、计算能力均为国内第一。天工平台可与天算智能大数据平台实现无缝对接,助力企业快速具备海量数据分析能力。
TSDB是用于管理时间序列数据的专业化数据库。区别于传统的关系型数据库,TSDB针对时间序列数据的存储、查询和展现进行了专门的优化,从而获得极高的数据压缩能力、极优的查询性能,特别适用于物联网应用场景。
在执行具体操作前,用户需了解TSDB相关的核心概念。
TSDB:Time Series Database,时序数据库,用于保存时间序列(按时间顺序变化)的海量数据。
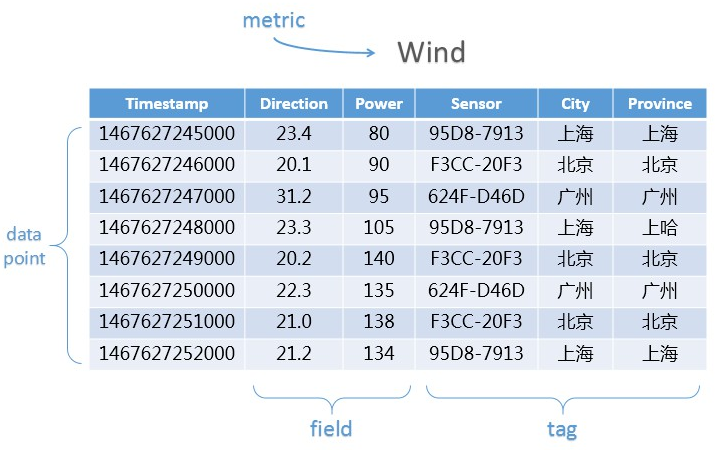
度量(metric):即数据的类别,如发动机的温度、转速等。
时间戳(timestamp):数据产生的时间点。
数值(value):度量得到的数值,如56°C、1000r/s等(实际中不带单位)。
标签(tag):一个标签是一个key-value对,用于提供额外的信息,如“型号=ABC123”、“出厂编号=1234567890”等。
数据点(data point):“一个metric + 一个timestamp + 一个value + n个tag”唯一定义了一个数据点。
分组(group):可以按标签(tag)、时间戳(timestamp)、数值(value)对数据点进行分组。
聚合函数(aggregator):可以对一段时间的数据点做聚合,如每10分钟的和值、平均值、最大值、最小值等。
数据库(database):一个用户可以有多个数据库,一个数据库可以写入多个“度量”的“数据点”。
metric、timestamp、value、tag、data point的关系如下图所示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号