
RAG实验:块大小分割实验、矢量存储;FAISS 与 Chroma、向量存储和 Top k、向量存储中的距离度量
比较 RAG 第 1 部分:块大小分割实验
我探索了 RAG 模型中的各种块大小,并使用专为评估检索器组件而设计的 RAGAS 评估器对其进行了评估。如您所知,检索器部分会生成随后输入到语言模型 (LLM) 中的“上下文”。
在这个实验中,我采用了BGE作为嵌入技术(它在 HuggingFace 的排行榜上得分很高),并将 top_k 参数设置为 1。这表示只考虑最相似的文档。此外,我将重叠块配置为 10%,与其他相关论文中观察到的行业标准保持一致。
这是我的结果:
虽然对上下文的回忆可能会表现出一些变化,但 F 测量值与块大小及其对应的 F 分数呈现出明显的线性关系。值得注意的是,较小的块大小会产生较高的 F 分数,而较大的块大小则与较低的分数相关。
讨论:
F 分数中观察到的模式归因于 RAGAS 提供的“context_precision”分数,该分数倾向于为被认为更“精确”的上下文分配更高的分数。块大小越大,除了所问内容之外,还会传达其他信息,因此会降低“context_precision”分数。在这个实验中,我评估了来自HuggingFace 数据集的 50 个问题,将它们的上下文与“ground_truth”列中的相应条目进行比较。值得注意的是,所有问题都相对较短,并且要求封闭式问题,这自然会导致更短的 ground_truth。
对于未来的实验,一个值得探索的有趣途径可能是修改数据集,引入更复杂的问题,这些问题本身就需要更长更详细的回答。这种调整可能会为问题复杂性对模型整体性能的影响提供有价值的见解。
比较 RAG 第 2 部分:矢量存储;FAISS 与 Chroma
在本研究中,我们研究了两个向量存储 FAISS ( https://faiss.ai ) 和 Chroma 对检索到的上下文的影响,以评估它们的重要性。调查利用 suswiki 知识库(分成 200 个字符的文本块)来解决 50 个精心挑选的问题。对 FAISS 和 Chroma 向量存储进行了比较分析,并使用 RAGAS 评估器提供的上下文精确度和召回率分数来评估结果。
整个文本块集包含 5551 个数据点。值得注意的是,FAISS 需要72.4 秒来生成其向量索引,而 Chroma 需要91.59 秒来完成相同的任务。这些发现为这些向量存储在给定上下文中的效率和性能提供了宝贵的见解。
检索一个上下文文档
检索最相似的单个上下文文档优先考虑简单性和速度。此方法还具有额外的优势,即当出现差异时,可以轻松识别和呈现差异。
实验结果

FAISS 与 Chroma 在检索 50 个问题时的对比
如表 1 所示,尽管使用相同的知识库和问题,更改向量存储会产生不同的结果。不过,数字上的差异很小。同一张表还突出了 FAISS 在上下文准确率和召回率方面优于 Chroma。FAISS 在相似性搜索方面也更快,仅需 1.81 秒即可从 50 个问题中检索出 50 个上下文,而 Chroma 则落后 2.18 秒。
检索到的上下文的差异
在 50 个问题中,有 5 个问题从 FAISS 和 Chroma 检索到的上下文不同。这些差异导致上下文准确率和召回率出现差异。在其中 4 个案例中,FAISS 返回了准确的上下文,而 Chroma 则未达到目标。有趣的是,在 1 个 RAGAS 偏向 Chroma 的问题中,手动评估显示 FAISS 和 Chroma 均未返回正确的上下文。
检索多个上下文文档
此外,我们还进行了检索多篇文档的测试,以查看对准确率、召回率和 f 度量的影响。我们选择检索 3 篇文档作为我们的超参数,因为它在开源 RAG 项目中很受欢迎。此探索旨在调查增加检索到的上下文数量是否有助于检索器在单文档实验中未检索到正确文档的情况下改善其输出。之后,我们用 6 篇文档进行了测试,以进一步提高效果。
实验结果

在表 2 中,与检索单个文档相比,FAISS 得分略有提高,f 值从 0.95 上升到 0.97。相反,Chroma 的 f 值从 0.91 大幅下降到 0.73。有趣的是,FAISS 和 Chroma 的搜索时间与之前的实验几乎相同。

检索 6 篇文档时,总体得分与检索 3 篇文档时几乎相同,FAISS f 度量仅下降 2%,而 Chroma f 度量增加 3%。有趣的是,FAISS 检索 6 篇文档所需的时间比检索 3 篇文档所需的时间要短。
结论
在本实验中,我们利用 5551 个文本块和 50 个问题来比较 FAISS 和 Chroma 这两个向量库。随后,我们增加了检索到的文档数量,以观察其对 RAGAS 评估分数的影响。我们的研究结果表明,FAISS 在速度和检索准确度方面优于 Chroma,而 Chroma 的准确度会随着检索到的文档数量的增加而下降。
由于向量存储中实施了相似性搜索算法,因此更改向量存储会影响检索到的上下文。因此,向量存储选择成为 RAG 模型中的关键因素。FAISS 和 Chroma 之间的比较表明,FAISS 在初始化任务中速度更快,并且能够正确检索 Chroma 中错误的上下文,这体现在上下文准确率和召回率方面得分更高。此外,FAISS 还具有更快的搜索算法,使其成为比 Chroma 更受欢迎的选择。
尝试将检索到的文档数量从 1 增加到 3 和 6 会导致 Chroma 的准确率和召回率降低,而 FAISS 的改进幅度很小。幸运的是,所有实验的搜索时间都保持一致。
为什么向量存储之间存在差异?
Chroma 相似性搜索算法的非确定性归因于其使用近似最近邻 (ANN) 算法,具体来说是分层可导航小世界 (HNSW)。在搜索过程中,它涉及排除一些数据点。
相比之下,FAISS 采用两个组件:(1) 乘积量化 (PQ) 编码和 (2) 带倒排索引的搜索系统 [1]。PQ 引入了使用有损方法压缩高维向量的技术。在当前实现中,它还使用 HNSW 作为搜索系统。但是,与标准 HNSW 不同,这种组合提高了搜索效率,从而实现了更快的搜索和与查询更相关的上下文。
比较 RAG 第 2b 部分:向量存储和 Top k;FAISS 与 Chroma — 检索多个文档
简介
FAISS 和 Chroma 都是流行的开源矢量存储,人们可以自由使用。
FAISS结合了多种技术,例如乘积量化 (PQ) 和倒排索引 (INV) 以及分层可导航小世界 (HNSW),以此来提高速度。而 Chroma 只是使用 HNSW。然而,两者都通过在各自的代码中设置所有随机种子来确保其结果是确定的。
在这个实验中,我们测试在检索增强生成 (RAG) 架构的背景下,这两者中的哪一个更适合作为检索器检索段落/文本块。
实验设置
1.知识库:可持续维基— 专注于可持续性和统计方法的维基。但是,它也从数据科学规范的角度讨论了其他主题。
2.拆分参数:块大小 = 200 个字符 & 块重叠 = 10%(20 个字符)
3.嵌入:BGE-large
4.距离度量:欧几里得 (L2)
5.评估器:RAGAS
6. 问题和基本事实:自定义可持续数据集
实验步骤
- 为向量存储 FAISS 和 Chroma 设置类似的环境
- 使用相同的 50 个自定义查询,我们测试两个向量存储,它们应该从知识库中检索正确的段落。
- 我们将需要检索的文档数量从 1 改为 10。
- 然后,RAGAS 从向量存储中检索到段落并将其与基本事实进行比较。
- 如果检索到的段落可以回答基本事实,则将获得高分(最高 1.0),否则将获得低分(最低 0.0)
结果
我们可以比较 FAISS 和 Chroma 的上下文准确率和召回率。此外,我们还手动检查了第一次检索到的段落的结果,以确保 RAGAS 分数的质量。
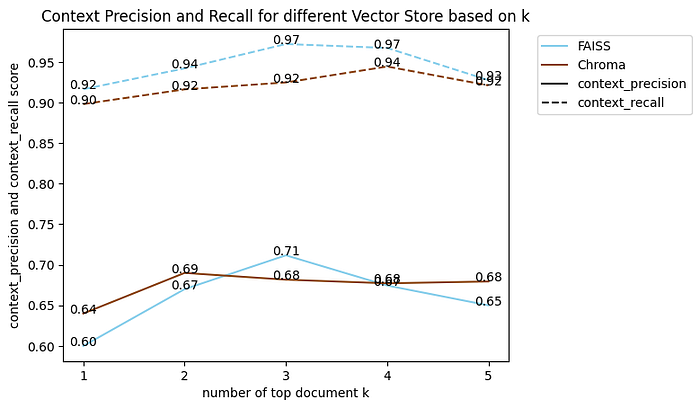
对不同数量的顶级文档进行 FAISS 和 Chroma 比较的总体结果。
通过检查表中的数据,可以发现,在上下文召回率方面,FAISS 通常优于 Chroma。但是,当我们将注意力转移到上下文精度时,一个模型优于另一个模型就变得不那么明显了。结果并没有明显偏向 FAISS 或 Chroma,表明两个模型在上下文理解方面都表现出相当的精度。有趣的是,随着文档数量的增加,Chroma 的表现更加稳定。
结论
总之,虽然 FAISS 表现出比 Chroma 更好的上下文召回率,但这两个模型在上下文准确率方面的区别并不明显。两个模型的准确率水平相似,但随着文档数量的增加,Chroma 的稳定性更高。然而,需要进一步研究才能确定哪种模型在不同场景中表现优异。
问题
RAGAS 评估器是一个自动化框架,它利用 LLM 的强大功能,根据基本事实为上下文提供精确度和召回率分数。目前,RAGAS 中最好的 LLM 是 GPT3.5。
不幸的是,我们在 OpenAI 中没有高级别,因此当我们尝试比较超过 5 个检索到的文本块时会遇到障碍。

OpenAI 发出错误消息,表示我们已达到令牌速率限制
RAGAS 评估人员面临的另一个挑战是算法与人类评估人员的一致性。正如他们的研究论文所述,算法的决策只有 70% 的时间与人类评估人员的决策一致(上下文准确率和召回率)。这种差异凸显了手头任务的复杂性和人类判断的细微差别。因此,虽然上述结果提供了有价值的见解,但它们应该被解释为一般准则,而不是绝对衡量标准。
比较 RAG 第 3 部分:向量存储中的距离度量(相似性指数)
背景:什么是距离度量?
距离度量或相似性度量是向量存储中的一个参数,用于决定使用哪种方法来计算一个数据点与另一个数据点之间的距离。
它将嵌入作为输入,并测量它们的相似性作为输出。为了计算两个向量 A = [a₁, a₂, … , aₙ] 和 B = [b₁, b₂, …, bₙ] 之间的相似性,我们使用相似性搜索算法。目前,最流行的三种是欧几里得距离/平方欧几里得/勾股距离、余弦相似度和最大内积 (MIP) / 点积。
欧氏距离 / 平方欧氏距离 / 毕达哥拉斯距离
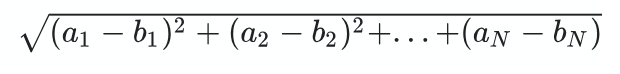
欧氏距离公式
它是衡量多维空间中两个向量之间最短直线距离的最直观指标。然而,维数灾难带来了缺点,因为计算复杂度会随着维数的增加而增加。欧氏距离值越低,向量越相似。
余弦相似度
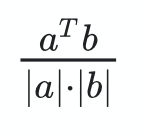
余弦相似度公式
计算两个向量之间的余弦角 $\theta$。它在处理稀疏向量时表现出显著的效率,因为它只考虑非零维度,从而减轻了计算开销。然而,它的缺点在于它偏向于具有高值的特征。此外,当这些值很小时,它对两个向量共享多少个相似特征仍然无动于衷(参考)。余弦值越高,向量越相似。
最大内积 (MIP)/点积
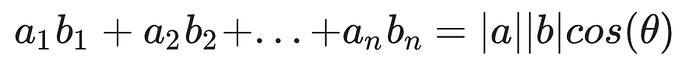
最大内积/点积公式
它计算两个向量长度的余弦乘积。通过添加常数或规范化器,它可以转换为其他相似性度量,例如欧几里德距离和余弦相似性。此外,在高维稀疏环境中,它比欧几里德和余弦相似性更快。然而,它具有与余弦相似性相同的弱点,因为它偏向于大范数项。这意味着,范数较小的项目不太可能是结果。此外,内积相似性搜索很难通过局部敏感哈希 (LSH) 和基于剪枝的方法进行近似(引用)。
实验
在这个实验中,我们冻结其他参数并比较三种不同的距离度量,即欧氏距离、余弦相似度和最大内积(MIP)。
我们的参数是:(1)知识库:可持续性维基(suswiki),(2)分割块大小:200 个字符,(3)分割块重叠:10\%,(4)嵌入模型:BGE large,(5)向量存储:FAISS 和 Chroma,(6)前 k 个文档:3,(7)问题答案:自己的数据集(50 行)
首先,我们尝试使用 FAISS 向量存储。我们使用欧几里得距离、余弦相似度和最大内积 (MIP) 等各种距离度量来检查检索到的上下文。数据集中的所有问题都一致地返回相同的检索到的文本块,并伴有相同的距离值。这种一致性可以归因于 FAISS 的默认距离标准化。
另一方面,Chroma 向量存储的结果在所有数据集上都表现出变化性。在 50 个问题中,有 4 个问题导致检索到不同的上下文。为了评估和总结这些问题,我们采用了 RAGAS 指标 - 上下文精度和召回率指标。表 1 中列出的结果表明,与余弦相似度和最大内积相比,使用欧几里得距离作为相似度指标可获得较高的 F1 分数。值得注意的是,余弦相似度记录的分数明显低于替代指标。

结论
TL/DR;如果您使用色度矢量存储,请使用欧氏距离/最大内积。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号