
AI agent智能体任务分解和调度的几篇经典文章
ReAct论文解读:LLM ReAct范式,在大语言模型中结合推理和动作
最近在研究如何让GPT正确做动作,比如搜索内容,发现了《SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS》这篇论文。作者提出了ReAct范式,通过将推理和动作相结合来克服LLM胡言乱语的问题,同时提高了结果的可解释性和可信赖度。
作者对人类的行为有一个洞察:
在人类从事一项需要多个步骤的任务时,而步骤和步骤之间,或者说动作和动作之间,往往会有一个推理过程。
以做一道菜为例,切好菜和打开煤气之间,有一个这样的推理,或者说内心独白:”现在我切好菜了,后面要煮菜了,我需要打开煤气。“在做菜过程中,如果发生意外,发现没有盐时,有这样一个推理:”没有盐了,今天我就用胡椒粉调味“,然后我们就会去拿胡椒粉。
通过这个洞察,作者提出一个方法:
让LLM把内心独白说出来,然后再根据独白做相应的动作,来提高LLM答案的准确性。
以下面这个问题为例:
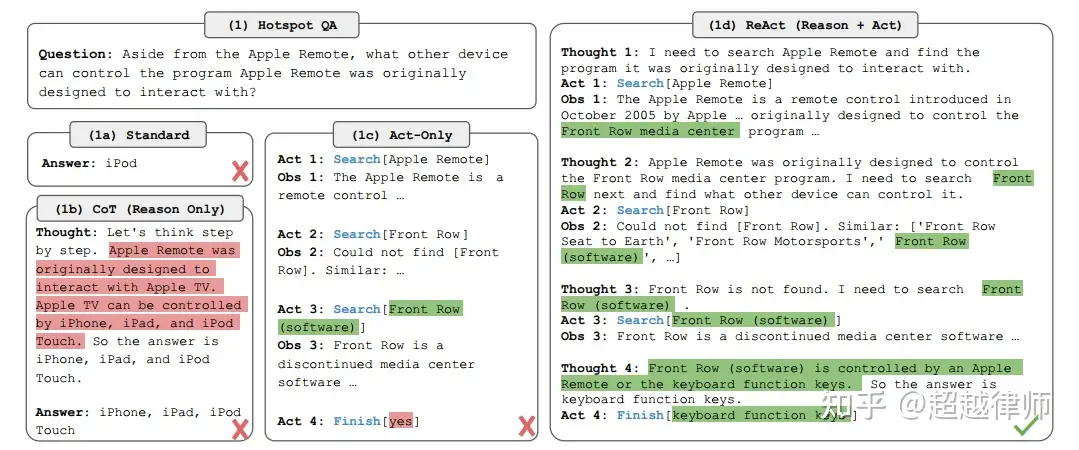
除了Apple遥控器,还有什么其他设备可以控制相关软件?相关软件指的是,Apple遥控器最早可以控制的软件。
说明:
- Apple遥控器最早只能控制Front Row软件。
- Front Row软件可以被两种设备控制,Apple遥控器和键盘的功能键。
- 所以,正确答案是键盘的功能键。
传统方式1,直接问LLM。得到结果:
iPod。
答案错误,显然是在胡言乱语。因为LLM的内容生成,是根据之前所有的字预测后续内容,所以,我推测,出现这个结果很可能因为,LLM其实并不知道相关答案,只是Apple遥控器和iPod的语义很接近,所以才得出iPod这个结论。
传统方法2,思维链。得到结果:
想法:让我们一步一步思考这个问题。Apple遥控器可以控制Apple电视。Apple电视可以被iPhone、iPad和iPod Touch控制。
答案:iPhone、iPad和iPod Touch控制。
答案错误,思维链范式,其实也是在胡诌,因为它不知道答案。
传统方法3,动作范式。得到结果:
动作1:搜索【Apple 遥控器】
结果1:Apple遥控器是一种遥控器……最早可以控制“Front Row”……
动作2:搜索【Front Row】
结果2:无结果
动作3:搜索【Front Row软件】
结果3:FrontRow是一种过时软件……
动作4:完成【是的】
答案错误,动作范式,即隐式推理,也没有得到正确答案。不难理解,隐式推理对LLM的推理能力要求很高,因为他会隐去思考过程。我觉得当LLM推理能力达到一定程度时,应该也能得出正确答案。
ReAct方法,即推理+动作。得到结果:
想法1:我需要搜索Apple遥控器,并找到Apple遥控器最早可以控制的软件。
动作1:搜索【Apple 遥控器】
结果1:Apple遥控器是一种遥控器……最早可以控制“Front Row”……
想法2:Apple遥控器最早可以控制Front Row。我需要搜索Front Row下一步,找出还有什么其他设备可以控制他
动作2:搜索【Front Row】
结果2:无结果,可以试试“Front Row Seat to Earth”和“Front Row软件”
想法3:Front Row没有找到,我可以搜索“Front Row软件”
动作3:搜索【Front Row软件】
结果3:FrontRow是一种过时软件……可以被Apple遥控器和键盘功能键控制。
想法4:现在我知道答案了。
动作4:完成【键盘功能键】
答案正确。通过显式推理,加上动作,LLM Agent自主找到了答案。整个过程感觉就像是个不是特别聪明的孩子,要把想法写出来,然后去综合所有想法和观察,接着再做出相应的动作。但显然这个方法很有效,它最终找到了答案。
也许将来,聪明的LLM Agent不需要显式推理,通过纯动作,即传统方法3,也能得到正确答案。但作为人类,我们还是会去使用ReAct范式,因为他具备了可解释性。我们可以知道Agent是怎么想的,尤其是在需要调试和人工介入的情况下。
此外,作者还提出了进一步提高ReAct准确率的方法,即微调finetuning,类似人类“内化”知识的过程,将上千条正确的推理动作轨迹输入进LLM进行finetuning,可以显著提高准确率。与其他三种方法同时finetuning后进行比较,ReAct的表现显著超越其他三种传统方法。
以上就是ReAct范式的核心思想。
Reflexion: Language Agents with Verbal Reinforcement Learning
一句话概括论文(用了什么方法,得到了什么样的效果)/ 一张图概括论文
reflexion是一个新的框架,通过自然语言反馈来增强agents的功能。Reflexion 在 HumanEval 编码基准上实现了 91% pass@1 准确率,超过了之前最先进的 GPT-4 的 80%。
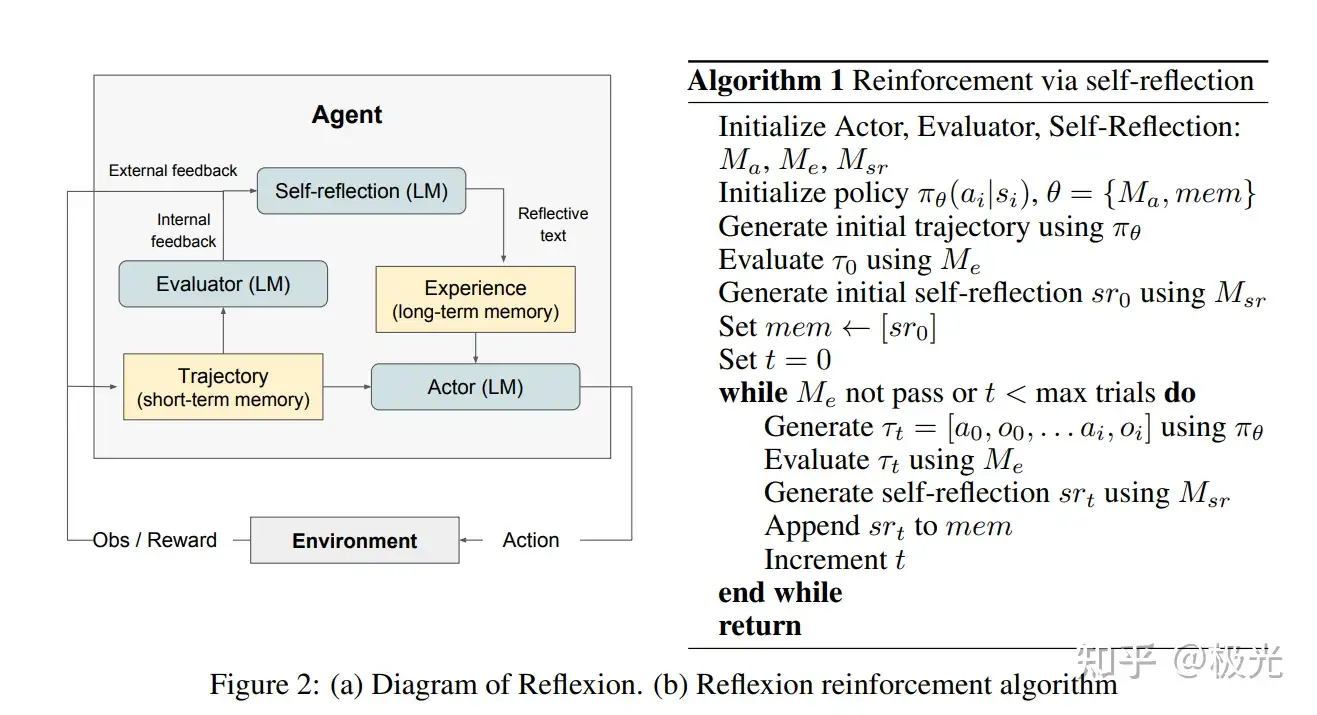
reflexion框架
详细介绍论文方法
对于框架类/模型类论文:
有哪些组件?
Actor,Evaluator,Self-reflection,Memory
详细介绍每个组件
Actor:
�� , 是一个LLM,和传统的强化学习一样,它在t时刻根据policy π� 生成动作 �� ,并获得执行动作后的环境反馈(观察环境) ��
论文尝试了多个Actor model,例如CoT和ReAct
Evaluator( �� )
- 功能:评估Actor的输出的好坏/打分
- 本身也是一个LLM
- 输入:生成的trajectory
- 输出:reward score
- 细节:对于不同的task,reward function不同,例如对于reasoning task,使用exact match grading,对于decision-making task,使用预先定义的启发式函数
Self-reflection
- 功能:生成自然语言式的反思
- 输入:reward signal,当前决策(trajectory),长期记忆(mem)
- 输出:feedback ( �� )
Memory(包括图里的trajectory和experience)
- 不是模型,而是负责存储东西
- short-term mem:记录trajectory history
- long-term mem:接收self-reflection的输出
整体的process
- 首先初始化policy模型(也就是actor),之后,第一大步如下:
- 1. actor与环境交互(这里的环境可能就是大模型接收到的用户输入)生成trajectory
- 2. evaluator给trajectory打分,分数记为 �� ,这个分数只是一个标量
- 3. self-reflection根据 {�0,�0} 产生summary ��0 ,并把 ��0 存储在memory中
- 之后我们设置循环最大步数t,开始循环:
- 生成trajectory
- 评估trajectory
- 生成反思 sr
- 把反思append到memory
- 直到evaluator认为trajectory足够好了,或者t已经达到最大步数。
任务评估
(都有哪些任务,任务对应的数据集是什么,任务具体在干什么,模型在任务中具体做了哪些设置,结果怎么样)
在HotPotQA上执行基于搜索的问答,在AlfWorld中执行常见家庭环境中的多步骤任务,以及在HumanEval、MBPP和LeetcodeHard(一个新的benchmark)中使用解释器和编译器在类似竞争的环境中执行代码编写任务。
Reflexion在AlfWorld中比strong baseline提高了22%,在HotPotQA中提高了20%,在HumanEval中提高了11%
ALFWorld
AlfWorld是一套基于文本的环境,它挑战代理在基于文本世界的各种交互式环境中解决多步骤任务。
- 任务具体干什么:
在134个AlfWorld环境中运行该代理,执行六项不同的任务,包括寻找隐藏的物体(例如,在抽屉中找到刮刀)、移动物体(例如将刀移动到砧板上)以及用其他物体操纵物体。
例子:
Environment: You are in the middle of a room. Looking quickly around you, you see a bed 1, a desk 2, a desk 1, a drawer 6, a drawer 5, a drawer 4, a drawer 3, a drawer 2, a drawer 1, a garbagecan 1, a laundryhamper 1, a safe 1, a shelf 6, a shelf 5, a shelf 4, a shelf 3, a shelf 2, and a shelf 1.
Task: examine the mug with the desklamp.
- 模型具体做什么:
除了用LLM对自然语言进行分类之外,还写了启发式策略:如果智能体执行了超过30个动作,或者收到同样的回答超过三次,就进行self-reflection
baseline: 智能体判断要self-reflection时,重置环境,重新开始。
Reflexion:进行self-reflection找到错误,更新memory,重置环境,重新尝试。(受prompt长度限制,memory最多保留三次reflection)
例子:(对于上面的具体environment和task)
Trial #1 > think: To solve the task, I need to find and take a mug, then find and use a desklamp.
> think: First I need to find a mug. A mug is more likely to appear in drawer (1-6), desk (1-2), shelf (1-6), garbagecan (1), laundryhamper (1). I can check one by one, starting with drawer 1.
>act: go to drawer 1 The drawer 1 is closed.
. . .
>act: open drawer 6 You open the drawer 6.
The drawer 6 is open. In it, you see a keychain 2.
>act: go to desk 1 On the desk 1, you see a creditcard 3, a desklamp 1, a laptop 2, a mug 1, a pen 1, and a pencil 1.
> think: Now I find a mug (1). Next, I need to take it.
>act: take mug 1 from desk 1 You pick up the mug 1 from the desk 1.
> think: Now I take a mug (1). Next, I need to find a desklamp. A desklamp is more likely to appear in desk (1-2), sidetable (1-2), shelf (1-6), bed (1), drawer (1-6). I can check one by one, starting with desk 1.
>act: go to desk 1
Nothing happens.
>act: go to desk 2
On the desk 2, you see a alarmclock 1, a bowl 1, a mug 3, a pencil 3, and a pencil 2.
> think: Now I find a desklamp (1). Next, I need to use it.
> act: use desklamp 1
Nothing happens.
>act: use desklamp 1
Nothing happens.
Status: Fail
Reflection: In this environment, my plan was to find a mug then find and use a desklamp. However, the task says to examine the mug with the desklamp. I should have looked for the desklamp first, then looked for the mug. I noticed that the desklamp was found on desk 1. In the next trial, I will go to desk 1, find the lamp, then look for the mug and examine it with the desklamp.
Trial #2
>act: go to desk 1
On the desk 1, you see a creditcard 3, a desklamp 1, a laptop 2, a mug 1, a pen 1, and a pencil 1.
> think: To solve the task, I need to find and take a mug, then find and use a desklamp.
>act: take mug 1 from desk 1
You pick up the mug 1 from the desk 1.
> think: To solve the task, I need to find and take a mug, then find and use a desklamp.
>act: use desklamp 1
You turn on the desklamp 1.
Status: Success
实际上,论文里给的reflection中,智能体并没有意识到它真正在哪里犯错,它的错误是没拿到desklamp却试图使用,而不是要先找desklamp.而且在trail #2的修正中,智能体也并没有直接去找desklamp,还是去找了mug,之后没有离开desk1,直接使用了desklamp.所以,这是一个失败的例子。
个人觉得reflection实际起到的作用(仅仅就这个例子而言)是增大了“desklamp”的“权重”,让robot对desklamp更敏感。
- 结论:ReAct+Reflexion显著优于ReAct,用简单的启发式方法来检测幻觉和低效的计划,完成了134项任务中的130项。
- 更好的原因:
baseline中失败的 AlfWorld 轨迹中的一个常见错误:代理认为它拥有某个物品,但实际上并非如此。代理继续在长轨迹中执行多个操作,并且无法回溯其操作以发现错误。
反思通过使用self-reflection将长期失败的轨迹提炼成相关经验来消除几乎所有这些情况,这些经验可以用作将来的“自我提示”。长期记忆在 AlfWorld 中对智能体有帮助的主要情况有两种:1)长轨迹中的早期错误可以很容易地识别出来。代理可以建议新的行动选择,甚至是新的长期计划。 2) 检索某个物品需要翻找很多箱子和抽屉。智能体可以利用多次试验的经验记忆来彻底搜索房间。
Reasoning & programming
to do...
局限性
可能只有局部最优,依赖于大模型的自我监督能力,不保证能够成功。
长期内存用滑动窗口方法储存,但未来可以扩展,例如用向量数据库.
对于programming有局限性:
there are many practical limitations to test-driven development in specifying accurate input-output mappings such as non-deterministic generator functions, impure functions that interact with APIs, functions that vary output according to hardware specifications, or functions that invoke parallel or concurrent behavior that may be difficult to predict.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号