
AI agent中的任务分解和调度-学术界文章汇总-【分而治之子任务分解、子任务独立智能体、强化学习、历史经验积累、自检可行性和错误反馈】
Reflexion: Language Agents withVerbal Reinforcement Learning
该文章提出了一种名为"Reflexion"的新型框架,用于通过语言反馈来强化语言智能体的学习。主要包含以下几个关键点:
-
框架组成:
- Actor模型:基于大语言模型生成文本和动作
- Evaluator模型:评估Actor生成的输出
- Self-Reflection模型:生成语言反馈,帮助Actor自我改进
-
算法流程:
- 初始化Actor、Evaluator和Self-Reflection模型
- 使用Actor生成初始轨迹
- 使用Evaluator评估轨迹,并由Self-Reflection模型生成反馈文本
- 将反馈文本添加到Agent的记忆中
- 重复上述步骤,直到任务完成或达到最大尝试次数
-
关键技术:
- 将奖励信号转化为语言反馈,提供更丰富的学习信号
- 利用Agent的记忆存储过往经验,指导后续决策
- 探索不同的Evaluator实现,如二元分类、自动生成单元测试等
-
实验结果:
- 在决策、推理和编程任务上,Reflexion Agent显著优于基线模型
- 在HumanEval编程基准上,Reflexion达到91%的pass@1准确率,超越了之前的最佳模型GPT-4的80%
总的来说,Reflexion提出了一种新的"语言强化学习"范式,利用语言反馈来指导智能体的学习和决策,在多个任务上取得了显著的性能提升。这种方法为将大语言模型应用于交互式环境提供了新的思路。
在Reflexion中,强化学习算法的体现主要体现在以下几个方面:
- 马尔可夫决策过程(MDP)
- 状态 s_t: 当前环境观测 o_t
- 动作 a_t: Actor 生成的动作或文本输出
- 奖励 r_t: Evaluator 给出的评估分数
- 转移概率 P(s_{t+1} | s_t, a_t): 环境的状态转移概率
- 策略优化
- Actor 模型 M_a 表示策略 π_θ,其中 θ 包括模型参数和记忆 mem
- 通过与环境交互,更新 θ 以最大化累积奖励
- 经验回放
- 将过去的经验(轨迹 τ_t 和自我反思 sr_t)存储在记忆 mem 中
- 在后续决策中利用这些经验来指导 Actor 的行为
- 自我评估和反馈
- Evaluator 模型 M_e 用于评估生成的轨迹
- Self-Reflection 模型 M_sr 用于根据评估结果生成自我反思反馈
- 这些反馈信号被用于更新 Actor 的策略 π_θ
总的来说,Reflexion 将强化学习的核心概念,如 MDP、策略优化、经验回放等,与语言模型的自我反思和记忆机制相结合,形成了一种新的强化学习范式。这种方法能够帮助语言模型快速学习复杂任务,并显著提高其决策能力。
根据文章中提到的相关工作,主要有以下几个方向:
-
推理和决策:
- Self-Refine[15]: 采用迭代自我优化的框架,通过自我评估来改进生成结果。
- Pryzant et al.[21]: 对生成的内容进行语义优化。
- Paul et al.[20]: 使用批评模型提供中间反馈来改进推理响应。
- Xie et al.[27]: 使用随机束搜索策略进行更有效的决策搜索。
- Yoran et al.[31]和Nair et al.[16]: 使用决策模型推理多个生成结果。
-
编程:
- AlphaCode[14]: 使用隐藏测试用例评估生成的代码。
- CodeT[5]: 使用自生成的单元测试来评估代码实现。
- Self-Debugging[7]和CodeRL[12]: 使用调试组件来改进现有的代码实现。
这些工作都尝试利用自我评估和自我改进的方法来增强语言模型在推理和编程任务上的能力。但它们大多局限于单次生成任务,或者依赖于预定义的测试用例。
Reflexion的创新之处在于:
- 将奖励信号转化为语言反馈,提供更丰富的学习信号。
- 利用Agent的记忆存储过往经验,指导后续决策。
- 探索不同的自我评估方法,如二元分类和自动生成单元测试。
- 在决策、推理和编程等多个任务上取得了显著的性能提升。
这种"语言强化学习"的范式为将大语言模型应用于交互式环境提供了新的思路和方法。
详细介绍一下Reflexion算法的流程:
输入:
- 环境观测 o_t
- 环境反馈信号 r_t
算法组件:
- Actor (M_a): 基于大语言模型生成文本和动作,输出 a_t。
- Evaluator (M_e): 评估生成的轨迹 τ_t,输出奖励信号 r_t。
- Self-Reflection (M_sr): 根据轨迹 τ_t 和奖励信号 r_t 生成自我反思文本 sr_t。
算法流程:
- 初始化 Actor, Evaluator, Self-Reflection 模型。
- 使用 Actor 生成初始轨迹 τ_0。
- 使用 Evaluator 评估 τ_0,得到奖励信号 r_0。
- 使用 Self-Reflection 生成初始自我反思 sr_0,并存入记忆 mem。
- 循环执行以下步骤,直到通过评估或达到最大尝试次数: a. 使用 Actor 生成当前轨迹 τ_t。 b. 使用 Evaluator 评估 τ_t,得到奖励信号 r_t。 c. 使用 Self-Reflection 生成自我反思 sr_t,并存入记忆 mem。 d. 更新 Actor 的策略 π_θ,其中 θ = {M_a, mem}。
- 返回最终生成的轨迹。
输出:
- 最终生成的轨迹
关键点:
- 使用语言反馈信号 sr_t 来指导 Actor 的决策,而不是简单的奖励信号 r_t。
- 将 Actor 的策略 π_θ 参数化为语言模型 M_a 和记忆 mem 的组合。
- 探索不同的 Evaluator 和 Self-Reflection 实现,如基于LLM的自我评估。
- 利用短期记忆(轨迹)和长期记忆(自我反思)来增强决策能力。
总的来说,Reflexion 提出了一种新的"语言强化学习"范式,通过自我反思和记忆来帮助语言模型快速学习复杂任务。
Unified and Modular Training for Open-Source Language Agents
该文章的主要要点和关键技术包括:
-
提出了LUMOS框架 - 一个用于训练开源语言智能体的统一、模块化和开源框架:
- 包含三个主要模块: 规划模块、映射模块和执行模块
- 提出了两种智能体训练和推理方式: LUMOS-OnePass和LUMOS-Iterative
-
关键技术:
- 利用LLM将现有数据集中的人工注释转换成LUMOS框架所需的子目标和动作注释
- 将转换后的注释组织成对话形式,以促进规划和映射模块之间的交互
- 采用统一的数据格式,覆盖多种复杂交互任务类型,如问答、数学、编码、网页浏览等
-
算法流程:
- 训练阶段:
- 使用LLM将现有数据集的人工注释转换成LUMOS格式
- 组织转换后的注释为对话形式
- 使用LLAMA-2-7B/13B作为规划和映射模块的基础模型进行训练
- 推理阶段:
- LUMOS-OnePass: 一次性生成所有子目标和动作
- LUMOS-Iterative: 逐步生成子目标和动作,根据执行反馈进行自适应规划
- 训练阶段:
-
实验结果显示LUMOS在多个复杂交互任务上优于现有开源智能体,甚至超越了基于GPT的智能体。同时LUMOS还展现出良好的跨任务泛化能力。
总的来说,LUMOS提出了一种统一、模块化和开源的智能体训练框架,通过利用LLM转换现有数据注释,实现了在多种复杂交互任务上的优秀性能。这为开发开源语言智能体提供了一种有效的方法。
该文章提到的一些相关研究包括:
-
基于闭源LLM的智能体框架:
- ReAct (Yao et al., 2022b)
- Shen et al. (2023)
- Lu et al. (2023)
- Xu et al. (2023)
- Lin et al. (2023)
- Liu et al. (2023c) 这些方法主要依赖于闭源的LLM,缺乏可负担性、可重复性和透明性。
-
利用大模型生成训练数据来提升小模型性能的方法:
- Bosselut et al. (2019)
- West et al. (2022)
- Wang et al. (2023b)
- Hsieh et al. (2023)
- Brahman et al. (2023)
-
其他开源智能体训练方法:
- ReWOO-open (Xu et al., 2023)
- FireAct (Chen et al., 2023)
- AgentLM (Zeng et al., 2023)
- AutoAct (Qiao et al., 2024)
这些方法也关注于在较小的LLM上训练智能体,但与LUMOS相比,LUMOS提出了更深入的分析和统一的任务表示,以实现更好的跨任务泛化能力。
总的来说,LUMOS的创新点在于提出了一种统一、模块化和开源的智能体训练框架,并通过LLM转换现有数据注释的方式,构建了大规模、高质量的训练数据,从而在多种复杂交互任务上展现出优秀的性能。
文章里的规划模块和接地模块的算法流程:
规划模块(Planning Module)的算法流程:
- 输入: 任务描述 T
- 输出: 一系列高层次子目标 S = {s1, s2, ..., sn}
- 算法步骤: a. 根据任务描述 T,利用预训练的规划模型 πplan 生成子目标序列 S。 b. 每个子目标 si 都是一个自然语言描述,表示完成该子目标需要达成的目标。
接地模块(Grounding Module)的算法流程:
- 输入: 任务描述 T、动作接口 I = {i1, i2, ..., ik}、规划模块生成的子目标序列 S
- 输出: 一系列可执行的低层次动作 A = {a1, a2, ..., am}
- 算法步骤: a. 根据任务描述 T、动作接口 I 和子目标序列 S,利用预训练的接地模型 πground 生成动作序列 A。 b. 每个动作 aj 都是一个具体的操作,如查询知识、检索段落、回答问题等,可以直接在执行模块中执行。 c. 动作的生成需要考虑任务描述、可用动作接口以及前面生成的子目标,以确保动作序列能够完成给定的子目标。
总的来说,规划模块负责任务分解,生成高层次子目标;接地模块则根据子目标、任务描述和动作接口,将子目标转换为可执行的低层次动作序列。
ADAPT: As-Needed Decomposition and Planning with Language Models
该文章提出了一种名为ADAPT的递归算法,用于解决复杂任务。其主要要点和关键技术包括:
-
将任务执行分为两个模块:计划器和执行器。计划器负责将复杂任务分解为子任务,执行器负责执行这些子任务。
-
ADAPT采用递归的方式,当执行器无法完成某个子任务时,会动态地调用计划器进一步分解该子任务。这种按需分解的方式可以适应任务复杂度和执行器能力的变化。
-
算法流程如下:
- 首先将任务交给执行器尝试完成。
- 如果执行器失败,则调用计划器将任务分解为子任务,并使用逻辑运算符(AND/OR)组合这些子任务。
- 递归地对每个子任务应用ADAPT算法,直到达到最大分解深度。
-
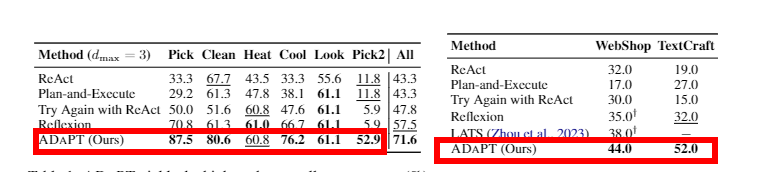
实验结果表明,与现有方法相比,ADAPT在三个复杂任务数据集上取得了显著的性能提升,最高可达28.3%、27%和33%的绝对百分点。
-
分析发现,ADAPT能够动态适应执行器的能力,并根据任务复杂度调整分解深度,体现了其灵活性和有效性。
总之,ADAPT通过将任务分解和执行分离,并采用递归的动态分解策略,有效地提升了复杂任务的解决能力。这种方法为利用语言模型解决复杂问题提供了一种新的思路。
详细介绍一下ADAPT算法的流程:
输入:
- 复杂任务T
- 当前分解深度k
输出:
- 任务是否完成(True/False)
算法流程:
-
检查是否达到最大分解深度dmax,如果是则返回False(任务失败)。
-
调用执行器(executor LLM)尝试直接完成任务T,并获得执行器的成功判断completed。
-
如果执行器失败(completed为False):
- 调用计划器(planner LLM)对任务T进行分解,得到一组子任务P和一个逻辑函数logic(·)。
- 递归地对每个子任务Tsub∈P调用ADAPT(Tsub, k+1),得到子任务的执行结果O。
- 使用logic(O)将子任务的执行结果组合,得到整个任务T的执行结果completed。
-
返回completed,表示任务是否完成。
算法的核心在于:
- 先让执行器尝试完成任务,
- 如果失败则动态分解任务,递归地处理子任务,
- 最后根据子任务的执行结果判断整个任务是否完成。
这种动态分解和递归处理的方式,使ADAPT能够适应任务复杂度和执行器能力的变化,从而取得较好的性能。
该文章涉及的相关研究主要包括以下几个方面:
-
使用LLM进行决策任务:
- ReAct (Yao et al., 2023b): 使用LLM迭代生成动作并执行的方法。
- 一些改进ReAct的工作,如引入反馈学习(Shinn et al., 2023)或搜索启发式(Yao et al., 2023a)。
-
任务分解和模块化方法:
- 之前的工作使用神经网络模块(Andreas et al., 2016; Gupta et al., 2019)或seq2seq模型(Min et al., 2019)进行任务分解。
- 近期使用LLM作为模块的方法,如LLM Programs (Schlag et al., 2023; Dohan et al., 2022)。
- 层次化问题求解的传统AI方法,如层次任务网络(Erol et al., 1994)。
-
自适应和递归分解:
- Reflexion (Shinn et al., 2023)等方法通过反馈学习来适应执行失败。
- Khot et al. (2023)提出了递归分解的方法,ADAPT进一步扩展了这一思路。
-
复杂环境中的决策任务:
- ALFWorld (Shridhar et al., 2021)、WebShop (Yao et al., 2022)等复杂交互环境任务。
- TextCraft是本文新引入的一个基于Minecraft的复合任务环境。
总的来说,ADAPT结合了任务分解、自适应性和递归处理等多个研究方向,在复杂决策任务上取得了显著的性能提升。这为利用LLM解决复杂问题提供了一种新的思路和方法。
文章里的算法实际效果:
Open-world Multi-task Agents withMemory-Augmented Multimodal LanguageModels
该文章的主要要点和关键技术如下:
-
提出了JARVIS-1, 一个能在Minecraft这个复杂的开放世界环境中完成多任务的智能体。
-
关键技术包括:
(1) 使用多模态语言模型(MLM)作为规划器, 能够理解视觉观察和文本指令, 生成复杂的计划。
(2) 为MLM增加了一个多模态记忆模块, 可以存储和利用之前成功的规划经验, 提高规划的正确性和一致性。
(3) 赋予JARVIS-1自我提出任务并自我提升的能力, 通过探索和积累经验不断增强自身的规划技能。
- 算法流程包括:
(1) 接收当前任务指令和环境观察, 生成多模态查询。
(2) 利用多模态记忆检索相关的规划经验, 作为参考提示。
(3) 将任务指令、环境观察和检索到的经验一起输入到MLM规划器, 生成可执行的计划序列。
(4) 将计划序列交给底层控制器执行, 并将执行结果存入多模态记忆。
(5) 通过自我提出任务并探索, 不断积累新的经验, 提升自身的规划能力。
总的来说, JARVIS-1 通过多模态感知、交互式规划和自我提升等关键技术, 在复杂的Minecraft环境中展现出强大的多任务解决能力。
详细展开算法流程,包括输入、输出等
详细展开JARVIS-1的算法流程:
输入:
- 当前任务指令(文本)
- 当前环境观察(视觉信息)
- 当前agent状态(库存、位置等符号信息)
输出:
- 可执行的行动序列(一系列短期目标)
- 成功执行计划后更新的agent状态
算法流程:
-
查询生成:
- 将当前任务指令和agent状态转换为文本描述
- 将当前环境观察转换为文本描述
- 将上述文本信息组合成多模态查询
-
记忆检索:
- 使用多模态查询在记忆库中检索相关的成功计划经验
- 根据查询与记忆的相似度对检索结果进行排序
-
交互式规划:
- 将任务指令、环境观察和检索到的计划经验输入到MLM规划器
- MLM规划器生成初步的行动序列计划
- 通过自检机制验证计划是否可行,发现潜在问题
- 如果计划存在问题,则通过自解释机制分析错误原因,并重新规划
-
执行和更新:
- 将生成的可执行行动序列交给底层控制器执行
- 记录执行过程中的agent状态变化,更新多模态记忆
-
自我提升:
- 定期生成新的探索任务,让agent自主探索环境
- 将探索过程中积累的新经验存入多模态记忆
- 利用积累的经验,不断提升agent的规划能力
通过上述算法流程,JARVIS-1能够在复杂的Minecraft环境中,通过多模态感知、交互式规划和自我提升,完成各种多样化的任务。
根据文章,JARVIS-1 涉及到以下相关研究领域:
-
基于大语言模型的规划和控制:
- Huang et al. (2022a)提出了利用LLM进行任务分解和动作序列生成的方法。
- Brohan et al. (2022b)提出了SayCan,利用LLM和价值函数生成可行的机器人规划。
- Huang et al. (2022b)提出了Inner Monologue,通过LLM的交互式规划增强可执行性。
- Yao et al. (2022)提出了ReAct,在规划前对当前状态进行推理。
-
多模态感知和融合:
- Fan et al. (2022)提出了MineCLIP,利用视觉-语言对齐进行多模态感知。
- Huang et al. (2023)提出了一种结合多模态输入的通用智能体。
-
记忆增强的规划:
- Lewis et al. (2020)提出了RAG,利用外部知识库增强LLM的生成能力。
- Zhu et al. (2023)提出了利用文本知识和记忆增强LLM的方法。
-
开放世界环境中的自主学习:
- Baker et al. (2022)提出了VPT,利用视频预训练进行开放世界任务学习。
- Lifshitz et al. (2023)提出了Steve-1,结合MineCLIP和VPT实现指令跟随。
- Wang et al. (2023a)提出了利用LLM进行开放世界探索和目标生成的方法。
-
交互式规划和自我解释:
- Chen et al. (2023)提出了LLM的自我调试机制。
- Shinn et al. (2023)提出了利用自我反思增强规划的方法。
总的来说,JARVIS-1 综合利用了这些前沿研究成果,在开放世界Minecraft环境中实现了更加通用和自主的智能代理。
TDAG: A Multi-Agent Framework based on Dynamic Task Decompositionand Agent Generation 24年2月份的文章
该文章的主要要点和关键技术如下:
-
提出了一个基于动态任务分解和代理生成的多代理框架(TDAG):
- 动态任务分解: 将复杂任务分解成更小的子任务,并根据前序子任务的完成情况动态调整后续子任务。
- 代理生成: 为每个子任务动态生成针对性的子代理,提高适应性和效率。
-
开发了一个名为ItineraryBench的基准测试,用于评估LLM代理在复杂实际任务(旅行规划)中的性能:
- 包含互相关联的、逐步复杂的任务
- 采用细粒度的评估指标,可以捕捉到部分任务完成的情况
-
算法流程:
- 主代理接收到复杂任务后,将其分解为多个子任务(t1, t2, ..., tn)
- 为每个子任务动态生成对应的子代理,并提供优化后的工具文档
- 子代理利用工具文档和递增技能库执行子任务,并将结果(r1, r2, ..., ri-1)反馈给主代理
- 主代理根据前序子任务的执行情况,动态调整后续子任务(t'i)
- 重复上述过程,直至完成整个任务
总的来说,该文章提出了一种灵活高效的多代理框架,通过动态任务分解和代理生成来应对复杂多步骤任务,并开发了一个细粒度评估的基准测试来验证该框架的有效性。
详细展开TDAG算法的流程:
输入:
- 复杂任务T
输出:
- 完成任务T的详细计划
算法流程:
-
任务分解:
- 主代理接收到任务T,将其分解为多个子任务(t1, t2, ..., tn)
- 分解策略是根据任务的结构和约束动态确定的,而不是固定的
-
子代理生成:
- 为每个子任务ti,动态生成一个针对性的子代理i
- 子代理的生成包括两个步骤:
- 生成优化后的工具文档,提高子代理的理解和执行效率
- 构建递增技能库,存储子代理之前解决类似子任务的经验
-
子任务执行:
- 子代理i接收子任务ti,以及前序子任务的执行结果(r1, r2, ..., ri-1)
- 子代理利用工具文档和技能库来解决子任务ti,得到结果ri
-
任务更新:
- 主代理根据前序子任务的执行结果(r1, r2, ..., ri-1),动态调整后续子任务(t'i)
- 调整策略考虑意外结果或新获得的信息,以提高整体任务的完成率
-
循环迭代:
- 重复步骤2-4,直至完成整个任务T
通过这样的动态分解、代理生成和任务更新机制,TDAG框架能够更好地应对复杂多步骤任务中的不确定性和变化,提高代理的适应性和执行效率。
相关工作,主要包括以下几个方面:
-
基于LLM的智能代理:
- Zhang et al. (2022)提出了LLM模型OPT
- Significant-Gravitas (2023)开发了AutoGPT项目
- Nakajima (2023)开发了BabyAGI项目
- Team (2023)开发了Xagent项目
-
增强代理的规划和推理能力:
- Yao et al. (2023)提出了ReAct方法
- Shinn et al. (2023)提出了Reflexion方法
- Prasad et al. (2023)提出了ADAPT方法
-
评估LLM代理的性能:
- Liu et al. (2023)提出了AgentBench基准
- Ge et al. (2023)提出了OpenAGI平台
- Mialon et al. (2023)提出了GAIA基准
-
任务分解和代理生成:
- Sun et al. (2023)提出了P&E方法
- Prasad et al. (2023)提出了ADAPT方法
总的来说,这些相关工作为TDAG框架的提出和评估提供了重要的背景和参考。TDAG在此基础上提出了动态任务分解和自适应代理生成的创新点,以进一步增强LLM代理在复杂任务场景下的性能。
REACT:SYNERGIZINGREASONING ANDACTING INLANGUAGEMODELS
文章要点总结:
- ReAct是一种新的基于提示的范式,用于协同语言模型中的推理和行动,以解决一般任务。
- ReAct在各种基准上优于最先进的基线,包括问答(HotPotQA、Yang等人,2018)、事实验证(Fever、Thorne等人,2018)、基于文本的游戏(ALFWorld、Shridhar等人,2020b)和网页导航(WebShop、Yao等人,2022)。
- ReAct的优势在于它能够在推理和行动之间进行无缝的协同,这使得它能够学习新的任务并做出稳健的决策,即使在以前从未见过的环境中或面对信息不确定性也是如此。
- ReAct的局限性在于它需要大量的演示才能很好地学习,这可能难以在实践中实现。
- 未来工作的方向包括扩展ReAct以处理更复杂的任务,并将其与其他范式(如强化学习)相结合,以进一步提高其性能。
算法详细展开
ReAct 算法
输入:
- 任务描述 (例如,问题、指令)
- 环境观察 (例如,网页内容、游戏状态)
输出:
- 行动 (例如,点击链接、移动角色)
- 想法 (例如,推理步骤、内部知识)
算法步骤:
- 初始化:
- 创建一个空的 ReAct 轨迹,包括行动、想法和环境观察。
- 循环:
- 如果任务完成,则停止。
- 否则,生成一个新的行动或想法,并将其添加到 ReAct 轨迹中。
- 使用当前的 ReAct 轨迹与环境交互,并获取新的环境观察。
- 重复步骤 2。
行动和想法的生成:
- 行动可以是任何与环境交互的操作,例如点击链接、移动角色、输入文本等。
- 想法可以是任何有助于任务完成的推理步骤或内部知识,例如分解任务目标、提取关键信息、进行常识推理等。
ReAct 轨迹的生成:
- ReAct 轨迹可以是任何格式,例如文本、列表、树形结构等。
- ReAct 轨迹可以是静态的,也可以是动态的,例如根据环境观察进行调整。
Act 算法
输入:
- 任务描述 (例如,问题、指令)
输出:
- 行动 (例如,点击链接、移动角色)
算法步骤:
- 初始化:
- 创建一个空的行动列表。
- 循环:
- 如果任务完成,则停止。
- 否则,生成一个新的行动,并将其添加到行动列表中。
- 使用当前的行动列表与环境交互,并获取新的环境观察。
- 重复步骤 2。
行动的生成:
- 行动可以是任何与环境交互的操作,例如点击链接、移动角色、输入文本等。
CoT 算法
输入:
- 任务描述 (例如,问题、指令)
输出:
- 想法 (例如,推理步骤、内部知识)
算法步骤:
- 初始化:
- 创建一个空的推理步骤列表。
- 循环:
- 如果任务完成,则停止。
- 否则,生成一个新的推理步骤,并将其添加到推理步骤列表中。
- 使用当前的推理步骤列表进行推理,并生成新的想法。
- 重复步骤 2。
想法的生成:
- 想法可以是任何有助于任务完成的推理步骤或内部知识,例如分解任务目标、提取关键信息、进行常识推理等。
算法比较
| 算法 | 输入 | 输出 | 优点 | 缺点 | |---|---|---|---|---| | ReAct | 任务描述、环境观察 | 行动、想法 | 结合推理和行动,提高任务完成率 | 需要大量示范学习 | | Act | 任务描述 | 行动 | 简单易用 | 缺乏推理能力 | | CoT | 任务描述 | 想法 | 具有推理能力 | 缺乏行动能力 |
总结
ReAct 算法是一种新的基于提示的范式,用于协同语言模型中的推理和行动,以解决一般任务。 ReAct 在各种基准上优于最先进的基线,包括问答、事实验证、基于文本的游戏和网页导航。 ReAct 的优势在于它能够在推理和行动之间进行无缝的协同,这使得它能够学习新的任务并做出稳健的决策,即使在以前从未见过的环境中或面对信息不确定性也是如此。 ReAct 的局限性在于它需要大量的演示才能很好地学习,这可能难以在实践中实现。 未来工作的方向包括扩展 ReAct 以处理更复杂的任务,并将其与其他范式(如强化学习)相结合,以进一步提高其性能。
一些其他值得一提的相关研究:
-
基于语言的交互式决策:
- Zhu et al. (2021) 提出了一种自适应信息寻找方法,用于开放域问答任务。
- Reed et al. (2022) 提出了一种通用的代理模型,能够在多种任务中表现出色。
-
语言模型与知识融合:
- Lewis et al. (2020) 提出了一种检索增强的生成方法,用于知识密集型NLP任务。
- Lazaridou et al. (2022) 利用少量提示训练语言模型,增强其在网络交互中的能力。
-
语言模型的可解释性和可信度:
- Wang et al. (2022a,b) 提出了基于自我一致性的方法,提高语言模型的可解释性。
- Creswell and Shanahan (2022) 设计了一种分步推理架构,以增强语言模型的可信度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号