
C语言逆向——指针,函数指针,数组指针是比较难理解的,结构体指针要体会其编译器生成汇编代码的本质
指针类型
在C语言里面指针是一种数据类型,是给编译看的,也就是说指针与int、char、数组、结构体是平级的,都是一个类型。
带"*"号的变量我们称之为指针类型,例如:
char* x;short* y;int* a;float* b;...任何类型都可以带这个符号,格式就是:类型* 名称;星号可以是多个。
指针变量的赋值格式如下:

指针类型的变量宽度永远是4字节,无论类型是什么,无论有几个星号。
指针类型和其他数据类型是一样的,也可以做自增、自减,但与其他数据类型不一样的是,指针类型自增、自减是加、减去掉一个星号后的宽度(注意:函数指针无法+-)。
如下代码:
#include <stdio.h>int main(){ int** a; char** b; a = (int**)1; b = (char**)2; a++; b++; printf("%d %d \n", a, b); return 0;}第一次自增,a+4 = 5,b+4 = 6,因为减去一个星号还是指针,指针的宽度永远是4:

自减同理可得,那么我们知道了自增、自减就可以知道指针类型的加减运算规律:
因为自增、自减,本质上就是+1,所以我们可以得出算式:
指针类型变量 + N = 指针类型变量 + N * (去掉一个*后类型的宽度)
指针类型变量 - N = 指针类型变量 - N * (去掉一个*后类型的宽度)
但需要注意,指针类型无法做乘除运算。
最后:指针类型是可以做比较的。

&的使用
&符号是取地址符,任何变量都可以使用&来获取地址,但不能用在常量上。
如下代码:
#include <stdio.h>struct Point { int x; int y;};char a;short b;int c;Point p;int main(){ printf("%x %x %x %x \n", &a, &b, &c, &p); return 0;}
在这里使用取地址符可以直接获取每个变量、结构体的地址,但是这种格式可能跟我们之前看到的8位不一样,前面少了2个0,这时候可以将%x占位符替换为%p来打印显示。

那么取地址符(&变量)的类型是什么呢?我们可以来探测下:
char a;short* b;int** c;int x = &a;int x = &b;int x = &c;以上代码我们在编译的时候是没法成功的,它的报错内容是:

通过报错内容我们可以看出类型不同无法转换,但是我仔细观察报错内容:char*无法转换成int,short**无法转换成int...那么就说明了一点,在我们使用取地址符时,变量会在其原本的数据类型后加一个星号。
可以这样进行指针赋值:
char x;char* p1;char** p2;char*** p3;char**** p4;p1 = &x; // &x -> char*p2 = &p1;p3 = &p2;p4 = &p3;p1 = (char*)p4;取值运算符
取值运算符就是我们之前所了解的“*”星号,“*”星号有这几个用途:
-
乘法运算符(1*2)
-
定义新的类型(char*)
-
取值运算符(星号+指针类型的变量);也就是取地址的存储的值。
如下代码就是使用取值运算符:
int* a = (int*)1;printf("%x \n", *a);这段代码可以编译,但是是无法运行的,我们可以运行一下然后来看看反汇编代码:


如上反汇编代码,我们可以清楚的看见首先0x1给了局部变量(ebp-4),之后这个局部变量(ebp-4)给了eax,而后eax又作为了内存地址去寻找对应存储的值(*local_var的汇编就是这样简单,lea和mov),但是这里eax为0x1,所以在内存中根本就不存在这个地址,也就没办法找到对应的值,自然就无法运行。
那么取值运算符(星号+指针类型)是什么类型呢?我们来探测下:
int*** a;int**** b;int***** c;int* d;int x = *(a);int x = *(b);int x = *(c);int x = *(d);以上代码我们在编译的时候是没法成功的,它的报错内容是:

通过报错内容我们可以看出类型不同无法转换,但是我仔细观察报错内容:int**无法转换成int,int***无法转换成int...那么就说明了一点,在我们使用*这个取值运算符时,变量会在其原本的数据类型后减去一个星号。
取值运算符举例:
int x = 1;int* p = &x;int** p2 = &p;*(p) = 2;int*** p3 = &p2;int r = *(*(*(p3)));数组参数传递
之前我们学过几本类型的参数传递,如下代码所示:
#include <stdio.h>void plus(int p) { p = p + 1;}int main(){ int x = 1; plus(x); printf("%d \n", x); return 0;}如上代码变量x最终值是多少?相信很多人都知道答案了,是1,原封不动。

为什么是1?这是因为在变量x作为参数传入plus函数,是传入值而不是这个变量本身,所以并不会改变变量本身。
数组也是可以作为参数传递,我们想要传入一个数组,然后打印数组的值(定义数组参数时方括号中不要写入常量):
#include <stdio.h>void printArray(int arr[], int aLength) { for (int i=0; i<aLength; i++) { printf("%d \n", arr[i]); }}int main(){ int arr[] = {0,1,2,3,4}; printArray(arr, 5); return 0;}我们想打印数组不仅要知道数组是什么,也要获取数组的长度,所以需要两个参数(实际上我们也有其他方法获取长度,这里先不多说)。

我们来看下反汇编代码,看看数组是否和基本类型一样传入的是值:

通过如上代码所示,我们可以很清晰的看见,ebp-14也就是数组的第一个值的地址给了eax,最后eax压入堆栈,也就是传递给了函数。
所以我们得出结论:数组参数传递时,传入的是数组第一个值的地址,而不是值;换而言之,我们在printArray函数中修改传入的数组,也就修改了数组本身。
我们再换个思路,在数组作为参数传递的时候,可以换一种形式,直接传入地址也是可以打印的,也就是使用指针来操作数组:

事实证明这是可行的,我们在传入参数的时候使用数组第一个值的地址即可。
指针与字符串
在学习完指针类型后,我们可以来了解一下这些函数:
int strlen(char* s); // 返回类型是字符串s的长度,不包含结束符号\0char* strcpy(char* dest, char* src); // 复制字符串src到dest中,返回指针为dest的值char* strcat(char* dest, char* src); // 将字符串src添加到dest尾部,返回指针为dest的值int strcmp(char* s1, char* s2); // 比较s1和s2,一样则返回0,不一样返回非0字符串的几种表现形式:
char str[6] = {'A','B','C','D','E','F'};char str[] = "ABCDE";char* str = "ABCDE";指针函数(本质就是函数,只不过函数的返回类型是某一类型的指针):
char* strcpy(char* dest, char* src);char* strcat(char* dest, char* src);指针取值的两种方式
如下图所示的则是一级指针(一个星号)和多级指针(多个星号):

这段代码看着很复杂,但我们有基础后再看它轻而易举,脑子里浮现的就是汇编代码。
指针取值有两种方式,如下代码:
#include <stdio.h>int main(){ int* p = (int*)1; printf("%d %d", *(p), p[0]); return 0;}我们可以使用取值运算符,也可以使用数组的方式,因为其本质都是一样的,我们来看下反汇编代码:

也就说明:*()与[]的互换,如下是互换的一些例子:
int* p = (int*)1;printf("%d %d \n",p[0],*p); //p[0] = *(p+0) = *p int** p = (int**)1;printf("%d %d \n",p[0][0],**p); printf("%d %d \n",p[1][2],*(*(p+1)+2));int*** p = (int***)1;printf("%d %d \n",p[1][2][3],*(*(*(p+1)+2)+3)); /**(*(*(*(*(*(*(p7))))))))= *(*(*(*(*(*(p7+0)+0)+0)+0)+0)+0)= p7[0][0][0][0][0][0][0]*/总结:
*(p+i) = p[i] *(*(p+i)+k) = p[i][k] *(*(*(p+i)+k)+m) = p[i][k][m] *(*(*(*(*(p+i)+k)+m)+w)+t) = p[i][k][m][w][t] 结构体指针
我们来了解一下结构体指针,如下代码:
#include <stdio.h>struct Point { int a; int b;};int main(){ Point p; Point* px = &p; printf("%d \n", sizeof(px)); return 0;}我们打印结构体指针的宽度,最终结果是4,这时候我们需要知道不论你是什么类型的指针,其特性就是我们之前说的指针的特性,并不会改变。
如下代码就是使用结构体指针:
// 创建结构体Point p;p.x=10;p.y=20;// 声明结构体指针Point* ps;// 为结构体指针赋值ps = &p;// 通过指针读取数据printf("%d \n",ps->x);// 通过指针修改数据ps->y=100;printf("%d\n",ps->y);提问:结构体指针一定要指向结构体吗?如下代码就是最好的解释:==》这个例子诠释了指针的本质,编译器具有解释权,结构体在存储的时候本质上和多个局部变量没有区别,所以在使用p->x的时候,本质上就是在取局部变量!
#include <stdio.h>struct Point{ int x; int y;};int main(){ int arr[10] = {1,2,3,4,5,6,7,8,9,10}; Point* p = (Point*)arr; int x = p->x; int y = p->y; printf("%d %d \n", x, y); return 0;}
我们实践下,看看本质:
#include <stdio.h>
struct Point
{
int x;
int y;
};
int main()
{
Point A;
A.x = 99;
A.y = 100;
Point* p2 = &A;
int x2 = p2->x;
int y2 = p2->y;
printf("%d %d \n", x2, y2);
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
Point* p = (Point*)arr; //这个例子让你体会结构体指针精髓
int x = p->x;
int y = p->y;
printf("%d %d \n", x, y);
return 0;
}


上面是vc6的编译结果,我们看下vs2022的汇编是不是一样的!
Point A;
A.x = 99;
00007FF72149189D mov dword ptr [A],63h
A.y = 100;
00007FF7214918A4 mov dword ptr [rbp+0Ch],64h
Point* p2 = &A;
00007FF7214918AB lea rax,[A]
00007FF7214918AF mov qword ptr [p2],rax
int x2 = p2->x;
00007FF7214918B3 mov rax,qword ptr [p2]
00007FF7214918B7 mov eax,dword ptr [rax]
00007FF7214918B9 mov dword ptr [x2],eax
int y2 = p2->y;
00007FF7214918BC mov rax,qword ptr [p2]
00007FF7214918C0 mov eax,dword ptr [rax+4]
00007FF7214918C3 mov dword ptr [y2],eax
printf("%d %d \n", x2, y2);
00007FF7214918C6 mov r8d,dword ptr [y2]
00007FF7214918CA mov edx,dword ptr [x2]
00007FF7214918CD lea rcx,[string "%d %d \n" (07FF721499CF0h)]
00007FF7214918D4 call printf (07FF72149118Bh)
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
00007FF7214918D9 mov dword ptr [arr],1
00007FF7214918E3 mov dword ptr [rbp+8Ch],2
00007FF7214918ED mov dword ptr [rbp+90h],3
00007FF7214918F7 mov dword ptr [rbp+94h],4
00007FF721491901 mov dword ptr [rbp+98h],5
00007FF72149190B mov dword ptr [rbp+9Ch],6
00007FF721491915 mov dword ptr [rbp+0A0h],7
00007FF72149191F mov dword ptr [rbp+0A4h],8
00007FF721491929 mov dword ptr [rbp+0A8h],9
00007FF721491933 mov dword ptr [rbp+0ACh],0Ah
Point* p = (Point*)arr; //这个例子让你体会结构体指针精髓
00007FF72149193D lea rax,[arr]
00007FF721491944 mov qword ptr [p],rax
int x = p->x;
00007FF72149194B mov rax,qword ptr [p]
00007FF721491952 mov eax,dword ptr [rax]
00007FF721491954 mov dword ptr [x],eax
int y = p->y;
00007FF72149195A mov rax,qword ptr [p]
00007FF721491961 mov eax,dword ptr [rax+4]
00007FF721491964 mov dword ptr [y],eax
printf("%d %d \n", x, y);
00007FF72149196A mov r8d,dword ptr [y]
00007FF721491971 mov edx,dword ptr [x]
00007FF721491977 lea rcx,[string "%d %d \n" (07FF721499CF0h)]
00007FF72149197E call printf (07FF72149118Bh)
return 0;
00007FF721491983 xor eax,eax
可以看到,vs2022出来的汇编结果本质上没有差异!
指针数组与数组指针
指针数组和数组指针,这两个是完全不一样的东西,指针数组的定义:
char* arr[10];Point* arr[10];int********** arr[10];指针数组的赋值方式:
char* a = "Hello";char* b = "World";// onechar* arr[2] = {a, b};// twochar* arr1[2];arr1[0] = a;arr1[1] = b;// threechar* arr2[2] = {"Hello", "World"};一共有三种赋值方式,在实际应用中我们更偏向于第三种方式。
结构体指针也有数组,我们可以看下其定义和对应宽度:

接下来我们要学习的是数组指针,数组指针在实际应用很少用到,数组指针是最难学的。
首先分析一下如下代码:
int arr[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 0};int* p = &arr[0];int* p = arr; // &arr[0]==》这个本质差异要注意!!!int* p = (int *)&arr; // &arr -> int *[10]&arr就是我们要学的数组指针(注意:arr不是数组指针,&arr才是),也就是int *[10],数组指针的定义如下:
int(*px)[5]; // 一维数组指针char(*px)[3];int(*px)[2][2]; // 二维数组指针char(*px)[3][3][3]; // 三维数组指针px就是我们随便定义的名字,本质上就是指针,那么也就有着指针的特性,无论是长度还是加减法...
思考:int *p[5] 与 int(*p)[5]有什么区别?我们可以来看看宽度:

可以看见一个是20,一个是4;一个是指针变量的数组,一个是数组指针,本质是不一样的。
数组指针的宽度和赋值:
int(*px1)p[5];char(*px2)[3]; int(*px3)[2][2];char(*px4)[3][3][3];printf("%d %d %d %d\n",sizeof(px1),sizeof(px2),sizeof(px3),sizeof(px4));// 4 4 4 4 px1 = (int (*)[5])1;px2 = (char (*)[3])2;px3 = (int (*)[2][2])3;px4 = (char (*)[3][3][3])4;数组指针的运算:
int(*px1)p[5];char(*px2)[3]; int(*px3)[2][2];char(*px4)[3][3][3];px1 = (int (*)[5])1;px2 = (char (*)[3])1;px3 = (int (*)[2][2])1;px4 = (char (*)[3][3][3])1;px1++; //int(4) *5 +20 =21px2++; //char(1) *3 +3 =4px3++; //int(4) *2 *2 +16 =17px4++; //char(1) *3 *3 *3 +9 =10printf("%d %d %d %d \n",px1,px2,px3,px4);数组指针的使用:
// 第一种:int arr[] = {1,2,3,4,5,6,7,8,9,0};int(*px)[10] = &arr;// *px 是啥类型? int[10] 数组类型// px[0] 等价于 *px 所以 *px 也等于 int[10]数组printf("%d %d \n",(*px)[0],px[0][0]);px++; // 后 (*px)[0]就访问整个数组地址后的地址内的数据// 第二种:int arr[3][3] = { {1,2,3}, {4,5,6}, {7,8,9}};// 此时的 px指针 指向的 {1,2,3}这个数组的首地址int(*px)[3] = &arr[0];// *px -> 此时就是数组{1,2,3}本身// 越过第一个数组 此时px指针指向 {4,5,6}的首地址px++;printf("%d %d \n",(*px)[0],px[0][0]);// 这里打印的就是 4 4思考:二维数组指针可以访问一维数组吗?==》数组本质认识又来了!!!
int arr[] = {1,2,3,4,5,6,7,8,9,0};int(*px)[2][2] = (int(*)[2][2])arr;是可以的,因为*px实际上就是int[2][2],我们之前学过多维数组,int[2][2]也就等于int[4],所以{1,2,3,4}就给了int[2][2],也就是{{1,2}, {3,4}},所以(*px)[1][1]为4。

实验下:
#include <stdio.h>
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
// int x = arr;
// int y = &arr;
printf("%p %p", arr, &arr);
int (*px)[2][2] = (int(*)[2][2])arr;
return 0;
}

所以,你实际上看到arr[0]这个东西,和一个普通的局部变量[ebp-28h]没有区别,编译器内部在看arr的时候,应该就是当做一个数组名而已了。

调用约定
函数调用约定就是告诉编译器怎么传递参数,怎么传递返回值,怎么平衡堆栈。
常见的几种调用约定:
|
调用约定 |
参数压栈顺序 |
平衡堆栈 |
|
__cdecl |
从右至左入栈 |
调用者清理栈 |
|
__stdcall |
从右至左入栈 |
自身清理堆栈 |
|
__fastcall |
ECX/EDX 传送前两个,剩下:从右至左入栈 |
自身清理堆栈 |
一般情况下自带库默认使用 __stdcall,我们写的代码默认使用 __cdecl,更换调用约定就是在函数名称前面加上关键词:
int __stdcall method(int x,int y){ return x+y;}method(1,2);函数指针
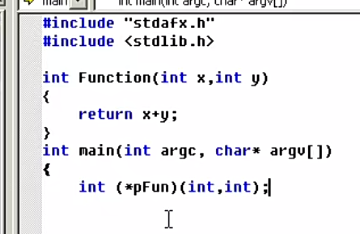
函数指针变量定义的格式:
// 返回类型 (调用约定 *变量名)(参数列表);int (__cdecl *pFun)(int,int);函数指针类型变量的赋值与使用:
// 定义函数指针变量int (__cdecl *pFun)(int,int);// 为函数指针变量赋值pFun = (int (__cdecl *)(int,int))10;// 使用函数指针变量int r = pFun(1,2);我们来看下函数指针的反汇编代码:

可以很清晰的看见函数指针生成来一堆汇编代码,传参、调用、以及如何平衡堆栈;而如上这段代码最终会调用地址0xA,但它本身不存在,所以无法运行。
所以我们想要调用某个函数时可以将地址赋值给pFun即可,并且在定义时写好对应的参数列表即可;也就是说函数指针通常用来使用别人写好的函数。
我们也通过函数指针绕过调试器断点,假设有攻击者要破解你的程序,它在MessageBox下断点,你正常的代码就会被成功断点,但是如果你使用函数指针的方式就可以绕过。
首先,我们先写一段正常的MessageBox程序,然后使用DTDebug来下断点:

可以看见,我们下断点成功断下来了,断点本质上就是在MOV EDI, EDI所在那行的地址下断点,那么我们可以直接跳过这行调用调用下一行,实际上这段汇编的核心在于我标记的部分,准确一点的说就是CALL指令哪一行,我们可以右键Follo跟进:


我们可以从0x77D5057D开始执行,通过汇编代码可以知道这个函数需要5个参数,并且最后的RETN则表示内平栈则使用__stdcall,所以我们函数指针(操作系统API返回通常是4字节)可以这样写:
#include <windows.h>int main(){ int (__stdcall *pFun)(int,int,int,int,int); pFun = (int (__stdcall *)(int,int,int,int,int))0x77D5057D; MessageBox(0,0,0,0); pFun(0,0,0,0,0); return 0;}这样就可以绕过断点了:???没有明白

实践,我们来做一个隐藏代码到数据区的例子:
Function的汇编:

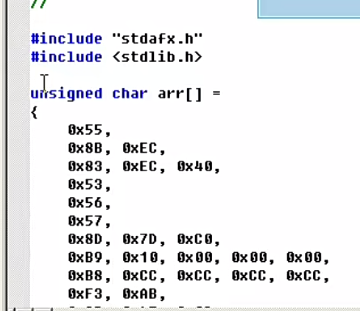
取出code bytes(二进制op code):

将上述op code放入数组:
然后修改代码:

最后效果:
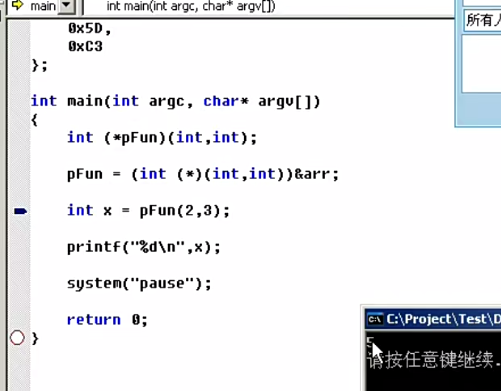
依然可以正常求和!!!
是不是发现一个本质,那就是数据和代码本质上没有区别!!!
下面贴一些代码:
隐藏代码到数据区的“骚”操作
在我们逆向学习的过程中,我们知道有些程序是被加了“壳”的,为逆向分析带来了许多困难,而这里的隐藏代码到数据区,如果代码较多,也能为逆向分析带来些许困难,实现对函数的“加密”。
接下我们就来了解一下将代码隐藏到数据区的“骚”操作:
首先来看看没有隐藏的源代码:
#include<stdio.h>
int add(int a,int b);
int main(int argc, char* argv[])
{
printf("%d",add(3,4));
return 0;
}
int add(int a,int b){
return a+b;
}我们来到反汇编:
55 push ebp
8B EC mov ebp,esp
83 EC 40 sub esp,40h
53 push ebx
56 push esi
57 push edi
8D 7D C0 lea edi,[ebp-40h]
B9 10 00 00 00 mov ecx,10h
B8 CC CC CC CC mov eax,0CCCCCCCCh
F3 AB rep stos dword ptr [edi]
8B 45 08 mov eax,dword ptr [ebp+8]
03 45 0C add eax,dword ptr [ebp+0Ch]
5F pop edi
5E pop esi
5B pop ebx
8B E5 mov esp,ebp
5D pop ebp
C3 ret这里是add函数的反汇编代码和硬编码,我们将这里的硬编码放入一个数组中:
#include <stdio.h>
int main(int argc, char* argv[])
{
char add[] = {
0X55,0X8B, 0XEC,0X83, 0XEC, 0X40, 0X53,0X56,0X57,0X8D, 0X7D, 0XC0,0XB9, 0X10, 0X00, 0X00, 0X00,0XB8, 0XCC, 0XCC, 0XCC, 0XCC,0XF3, 0XAB,0X8B, 0X45, 0X08,0X03, 0X45, 0X0C,0X5F,0X5E,0X5B,0X8B, 0XE5,0X5D,0XC3,
};
int (*sub)(int,int);
sub = (int (__cdecl *)(int,int))&add;
printf("%d\n",sub(3,4));
return 0;
}
![]()

这样隐藏后,在反汇编窗口就无法直接找到add函数了,必须通过数组地址,找到硬编码,再将会硬编码转换至汇编进行分析,在非常庞大的数据量下寻找硬编码也是比较困难的,这样就能做到对代码的很好的隐藏(在计算机看来,代码和数据并无两样,计算机只负责存储)。
通过编译运行我们能够在程序终端看到仍然输出7,可以确定将代码隐藏进了数据区,这里实际上是将硬编码存储进了数据区。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号