
图计算之 nebula-algorithm——todo,待实践,感觉有大坑
写在前面:

nebula-algorithm 目前仅支持 Nebula Graph v1.x,不支持 Nebula Graph v2.x。
这玩意是不是有大坑啊! 我看1.21以下都不支持了。。。
图计算之 nebula-algorithm
在开始 nebula-algorithm 介绍之前,先贴一个它的开源地址:https://github.com/vesoft-inc/nebula-algorithm。
Nebula 图计算
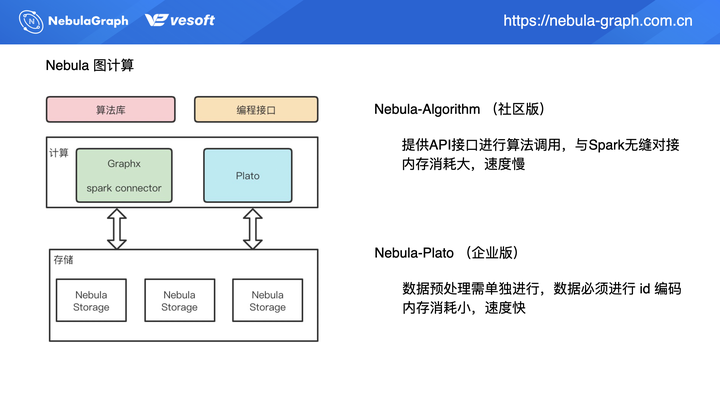
目前 Nebula 图计算集成了两种不同图计算框架,共有 2 款产品:nebula-algorithm 和 nebula-plato。
nebula-algorithm 是社区版本,同 nebula-plato 的不同之处在于,nebula-algorithm 提供了 API 接口来进行算法调用,最大的优势在于集成了 [GraphX](https://spark.apache.org/docs/latest/graphx-programming-guide.html),可无缝对接 Spark 生态。正是由于 nebula-algorithm 基于 GraphX 实现,所以底层的数据结构是 RDD 抽象,在计算过程中会有很大的内存消耗,相对的速度会比较慢。
nebula-plato 上面介绍过,数据内部要进行 ID 编码映射,即便是 int ID,但如果不是从 0 开始递增,都需要进行 ID 编码。nebula-plato 的优势就是内存消耗是比较小,所以它跑算法时,在相同数据和资源情况下,nebula-plato 速度是相对比较快的。
上图左侧是是 nebula-algorithm 和 nebula-plato 的架构,二者皆从存储层 Nebula Storage 中拉取数据。GraphX 这边(nebula-algorithm)主要是通过 Spark Connector 来拉取存储数据,写入也是通过 Spark Connector。
nebula-algorithm 使用方式
jar 包提交
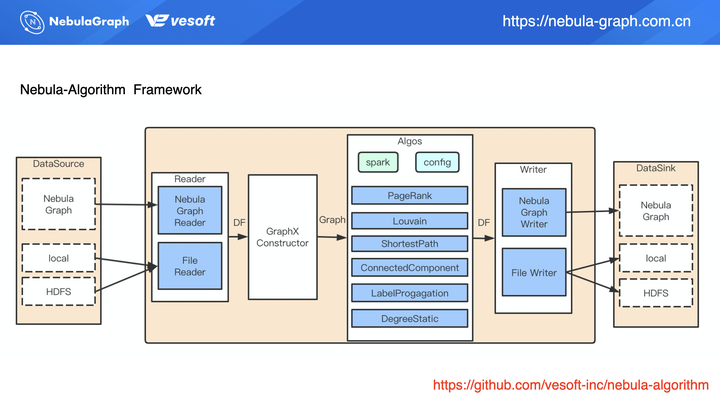
通过 jar 包的方式整个流程如上图所示:通过配置文件配置数据来源,目前配置文件数据源支持 Nebula Graph、HDFS 上 CSV 文件以及本地文件。数据读取后被构造成一个 GraphX 的图,该图再调用 nebula-algorithm 的算法库。算法执行完成后会得到一个算法结果的 data frame(DF),其实是一张二维表,基于这张二维表,Spark Connector 再写入数据。这里的写入可以把结果写回到图数据库,也可以写入到 HDFS 上。
API 调用
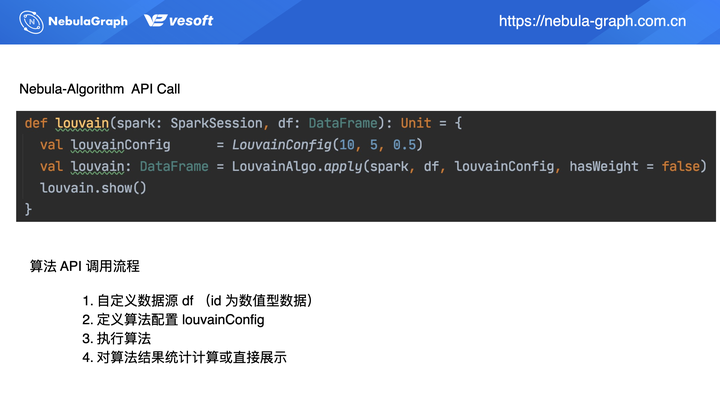
更推荐大家通过 API 调用的方式。像上面通过 jar 包形式在后面的数据写入部分是不处理数据的。而采用 API 调用方式,在数据写入部分可进行数据预处理,或是对算法结果进行统计分析。 API 调用的流程如上图所示,主要分为 4 步:
- 自定义数据源 df(id 为数值型数据)
- 定义算法配置 louvainConfig
- 执行算法
- 对算法结果统计计算或直接展示
上图的代码部分则为具体的调用示例。先定义个 Spark 入口:SparkSession,再通过 Spark 读取数据源 df,这种形式丰富了数据源,它不局限于读取 HDFS 上的 CSV,也支持读取 HBase 或者 Hive 数据。上述示例适用于顶点 ID 为数值类型的图数据,String 类型的 ID 在后面介绍。
回到数据读取之后的操作,数据读取之后将进行算法配置。上图示例调用 Louvain 算法,需要配置下 LouvainConfig 参数信息,即 Louvain 算法所需的参数,比如迭代次数、阈值等等。
算法执行完之后你可以自定义下一步操作结果统计分析或者是结果展示,上面示例为直接展示结果 louvain.show()。
ID Mapping 映射原理与实现
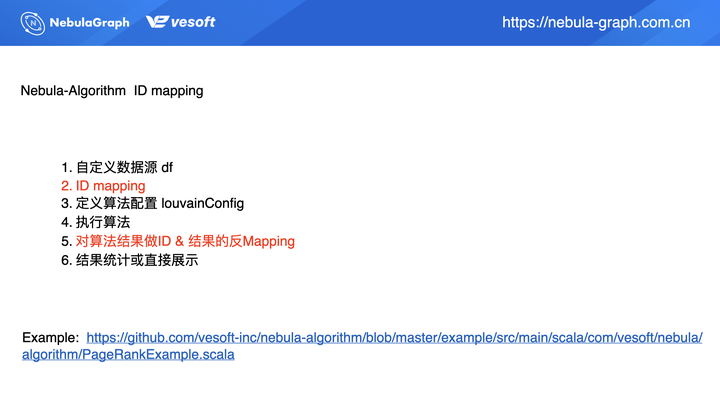
再来介绍下 ID 映射,String ID 的处理。
熟悉 GraphX 的小伙伴可能知道它是不支持 String ID 的,当我们的数据源 ID 是个 String 该如何处理呢?
同社区用户 GitHub issue 和论坛的日常交流中,许多用户都提到了这个问题。这里给出一个代码示例:https://github.com/vesoft-inc/nebula-algorithm/blob/master/example/src/main/scala/com/vesoft/nebula/algorithm/PageRankExample.scala
从上面的流程图上,我们可以看到其实同之前调用流程相同,只是多两步:ID Mapping 和 对结算结果做 ID & 结果的反 Mapping。因为算法运行结果是数值型,所以需要做一步反 Mapping 操作使得结果转化为 String 类型。
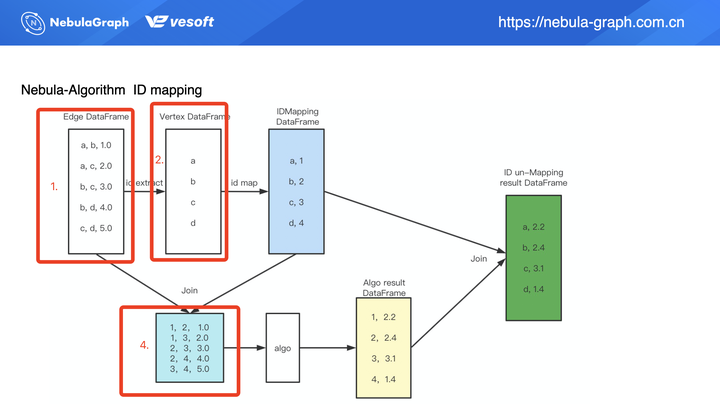
上图为 ID 映射(Mapping)的过程,在算法调用的数据源(方框 1)显示该数据为边数据,且为 String 类型(a、b、c、d),当中的 1.0、2.0 等等列数据为边权重。在第 2 步中将会从边数据中提取点数据,这里我们提取到了 a、b、c、d,提取到点数据之后通过 ID 映射生成 long 类型的数值 ID(上图蓝色框)。有了数值类型的 ID 之后,我们将映射之后的 ID 数据(蓝色框)和原始的边数据(方框 1)进行 Join 操作,得到一个编码之后的边数据(方框 4)。编码之后的数据集可用来做算法输入,算法执行之后得到数据结果(黄色框),我们可以看到这个结果是一个类似二维表的结构。
为了方便理解,我们假设现在这个是 PageRank 的算法执行过程,那我们得到的结果数据(黄色框)右列(2.2、2.4、3.1、1.4)则为计算出来的 PR 值。但这里的结果数据并非是最终结果,别忘了我们的原始数据是 String 类型的点数据,所以我们要再做下流程上的第 5 步:对结算结果做 ID & 结果的反 Mapping,这样我们可以得到最终的执行结果(绿色框)。
要注意的是,上图是以 PageRank 为例,因为 PageRank 的算法执行结果(黄框右列数据)为 double 类型数值,所以不需要做 ID 反映射,但是如果上面的流程执行的算法为连通分量或是标签传播,它的算法执行结果第二列数据是需要做 ID 反映射的。
节选下 PageRank 的代码中的实现
def pagerankWithIdMaping(spark: SparkSession, df: DataFrame): Unit = {
val encodedDF = convertStringId2LongId(df)
val pageRankConfig = PRConfig(3, 0.85)
val pr = PageRankAlgo.apply(spark, encodedDF, pageRankConfig, false)
val decodedPr = reconvertLongId2StringId(spark, pr)
decodedPr.show()
}我们可以看到算法调用之前通过执行 val encodedDF = convertStringId2LongId(df) 来进行 String ID 到 Long 类型的映射,语句执行完之后,我们才会调用算法,算法执行之后再来进行反映射 val decodedPr = reconvertLongId2StringId(spark, pr)。
在直播视频(B站:https://www.bilibili.com/video/BV1rR4y1T73V)中,讲述了 PageRank 示例代码实现,有兴趣的小伙伴可以看下视频 24‘31 ~ 25'24 的代码讲解,当中也讲述了编码映射的实现。
nebula-algorithm 支持的算法
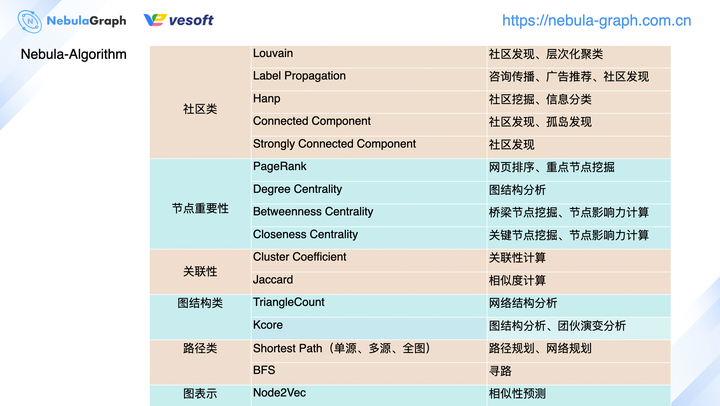
上图展示的是我们在 v3.0 版本中将会支持的图算法,当然当中部分的图算法在 v2.0 也是支持的,不过这里不做赘述具体的可以查看 GitHub 的文档:https://github.com/vesoft-inc/nebula-algorithm 。
按照分类,我们将现支持的算法分为了社区类、节点重要性、关联性、图结构类、路径类和图表示等 6 大类。虽然这里只是列举了 nebula-algorithm 的算法分类,但是企业版的 nebula-plato 的算法分类也是类似的,只不过各个大类中的内部算法会更丰富点。根据目前社区用户的提问反馈来讲,算法使用方便主要以上图的社区类和节点重要性两类为主,可以看到我们也是针对性的更加丰富这 2 大类的算法。如果你在 nebula-algorithm 使用过程中,开发了新的算法实现,记得来 GitHub 给 nebula-algorithm 提个 pr 丰富它的算法库。
下图是社区发现比较常见的 Louvain、标签传播算法的一个简单介绍:

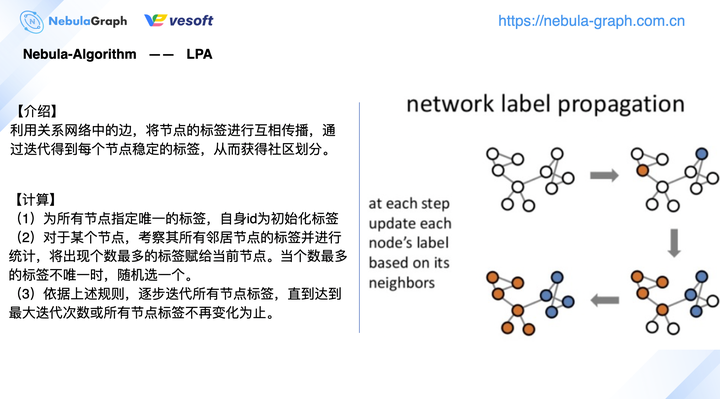
由于之前写过相关的算法介绍,这里不做赘述,可以阅读《GraphX 在图数据库 Nebula Graph 的图计算实践》。
这里简单介绍下连通分量算法
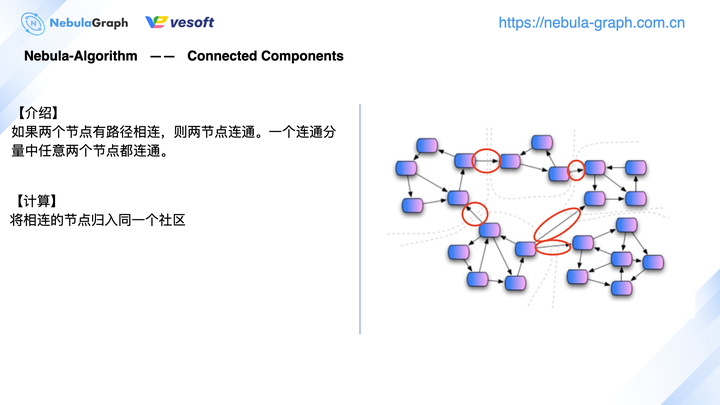
连通分量一般指的是弱连通分量,算法针对无向图,它的计算流程相对简单。如上图右侧所示,以虚线划分的 5 个小社区,在计算连通分量过程中,每个社区之间的连线(红色框)是不做计算的。你可理解为从图数据库中抽取出 1 个子图来进行 1 个联通分量的计算,计算出来有 5 个小连通分量。这时候基于全图去数据分析,不同的小社区之间又增加了连接边(红色框),将它们连接起来。
社区算法的应用场景
银行领域

再来看个具体的应用场景,在银行中存在这种情况,一个身份证号对应多个手机号、多台手机设备、多张借记卡、多张信用卡,还有多个 APP。而这些银行数据会分散存储,要做关联分析时,可以先通过联通分量来去计算小社区。举个例子:把同一个人所拥有的不同的设备、手机号等数据信息归到同一连通分量,把它们作为一个持卡人实体,再进行下一步计算。简单来说,将分散数据通过算法聚合成大节点统一分析。
安防领域
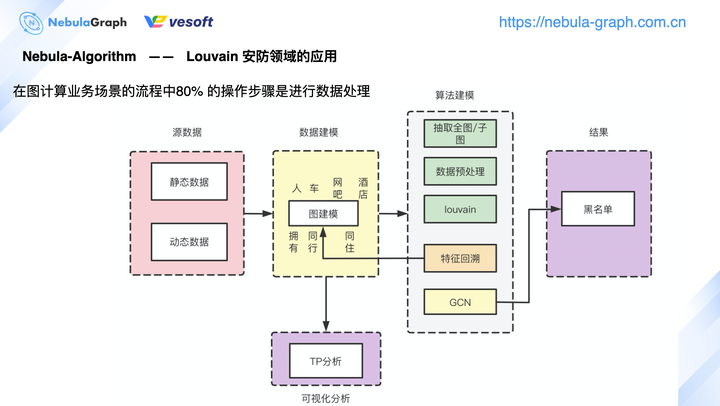
上图是 Louvain 算法在安防领域的应用,可以看到其实整个业务处理流程中,算法本身的比重占比并不高,整个处理流程 80% 左右是在对数据做预处理和后续结果进行统计分析。不同领域有不同的数据,领域源数据按业务场景进行实际的图建模。 以公安为例,通过公安数据进行人、车、网吧、酒店等实体抽取,即图数据库中可以分成这 4 个 tag(人、车、网吧、酒店),基于用户的动态数据抽象出拥有关系、同行关系、同住关系,即对应到图数据库中的 Edge Type。完成数据建模之后,再进行算法建模,根据业务场景选择抽取全图,还是抽取子图进行图计算。数据抽取后,需要进行数据预处理。数据预处理包括很多操作,比如将数据拆分成两类,一类进行模型训练,另外一类进行模型验证;或是对数据进行权重、特征方面的数值类转换,这些都称为数据的一个预处理。
数据预处理完之后,执行诸如 Louvain、节点重要程度之类的算法。计算完成后,通常会将基于点数据得到的新特征回溯到图数据库中,即图计算完成后,图数据库的 Tag 会新增一类属性,这个新属性就是 Tag 的新特征。计算结果写回到图数据库后,可将图数据库的数据读取到 Studio 画布进行可视化分析。这里需要领域专家针对具体业务需求进行可视化分析,或者数据完成计算后进入到 GCN 进行模型训练,最终得到黑名单。 以上为本次图计算的概述部分,下面为来自社区的一些相关提问。
社区提问
这里摘录了部分的社区用户提问,所有问题的提问可以观看直播视频 33‘05 开始的问题回复部分。
算法内部原理
dengchang:想了解下图计算各类成熟算法的内部原理,如果有结合实际场景跟数据的讲解那就更好了。
Nicole:赵老师可以看下之前的文章,比如:
一些相对比较复杂的算法,在直播中不便展开讲解,后续会发布文章来详细介绍。
图计算的规划
en,coder:目前我看到 Nebula Algorithm 计算要将数据库数据导出到 Spark,计算完再导入到数据库。后续是否考虑支持不导出,至少轻量级算法的计算,结果展示在 Studio。
Nicole:先回复前面的问题,其实用 nebula-algorithm 计算完不一定要将结果导入到图数据库,目前 nebula-algorithm 的 API 调用和jar 包提交两种方式均允许把结果写入到 HDFS。是否要将结果数据导入图数据库取决于你后续要针对图计算结果进行何种处理。至于“后续是否支持不导出,至少轻量级的计算”,我的理解轻量级的算法计算是不是先把数据从图数据库中查出来,在画布展示,再针对画布中所展示出来的一小部分数据进行轻量级计算,计算结果立马去通过 Studio 展示在画布中,而不是在写回到图数据库。如果是这样的话,其实后续 Nebula 有考虑去做个图计算平台,结合了 AP 和 TP,针对画布中的数据,也可以考虑进行简单的轻量级计算,计算结果是否要写回到图数据库由用户去配置。回到需求本身,是否进行画布数据的轻量级计算还是取决于你的具体场景,是否需要进行这种操作。
潮与虎:nebula-algorithm 打算支持 Flink 吗?
Nicole:这里可能指的是 Flink 的 Gelly 做图计算,目前暂时没有相关的打算。
繁凡:有计划做基于 nGQL 的模式匹配吗?全图的 OLAP 计算任务,实际场景有一些模式匹配的任务,一般自己开发代码,但是效率太低。
郝彤:模式匹配是个 OLTP 场景,TP 受限于磁盘的速度较慢,所以想用在 OLAP 上,但是 OLAP 通常是处理传统算法,不支持模式匹配。其实后续 AP 和 TP 融合之后,图数据放在内存中,速度会提升。
PageRank算法实践
演示环境
- 三台虚拟机,环境如下:
- Cpu name:Intel(R) Xeon(R) Platinum 8260M CPU @ 2.30GHz
- Processors:32
- CPU Cores:16
- Memory Size:128G
- 软件环境
- Spark:spark-2.4.6-bin-hadoop2.7 三个节点集群
- yarn V2.10.0:三个节点集群
- Nebula Graph V1.1.0:分布式部署,默认配置
测试数据
- 创建图空间
CREATE SPACE algoTest(partition_num=100, replica_factor=1);
- 创建点边 Schema
CREATE TAG PERSON()
CREATE EDGE FRIEND(likeness double);
- 导入数据
利用 Exchange 工具将数据离线导入 Nebula Graph。
- 测试结果
Spark 任务的资源分配为 --driver-memory=20G --executor-memory=100G --executor-cores=3
- PageRank 在一亿数据集上的执行时间为 21min(PageRank 算法执行时间)
- Louvain 在一亿数据集上的执行时间为 1.3h(Reader + Louvain 算法执行时间)
如何使用 Nebula Graph 的算法
- 下载 nebula-algorithm 项目并打成 jar 包
$ git clone git@github.com:vesoft-inc/nebula-java.git
$ cd nebula-java/tools/nebula-algorithm
$ mvn package -DskipTests
- 配置项目中的
src/main/resources/application.conf
{
# Spark relation config
spark: {
app: {
# not required, default name is the algorithm that you are going to execute.
name: PageRank
# not required
partitionNum: 12
}
master: local
# not required
conf: {
driver-memory: 8g
executor-memory: 8g
executor-cores: 1g
cores-max:6
}
}
# Nebula Graph relation config
nebula: {
# metadata server address
addresses: "127.0.0.1:45500"
user: root
pswd: nebula
space: algoTest
# partition specified while creating nebula space, if you didn't specified the partition, then it's 100.
partitionNumber: 100
# nebula edge type
labels: ["FRIEND"]
hasWeight: true
# if hasWeight is true,then weightCols is required, and weghtCols' order must be corresponding with labels.
# Noted: the graph algorithm only supports isomorphic graphs,
# so the data type of each col in weightCols must be consistent and all numeric types.
weightCols: [“likeness”]
}
algorithm: {
# the algorithm that you are going to execute,pick one from [pagerank, louvain]
executeAlgo: louvain
# algorithm result path
path: /tmp
# pagerank parameter
pagerank: {
maxIter: 20
resetProb: 0.15 # default 0.15
}
# louvain parameter
louvain: {
maxIter: 20
internalIter: 10
tol: 0.5
}
}
}
-
确保用户环境已安装 Spark 并启动 Spark 服务
-
提交 nebula-algorithm 应用程序:
spark-submit --master xxx --class com.vesoft.nebula.tools.algorithm.Main /your-jar-path/nebula-algorithm-1.0.1.jar -p /your-application.conf-path/application.conf
如果你对上述内容感兴趣,欢迎用 nebula-algorithm 试试^^
References
- Nebula Graph:https://github.com/vesoft-inc/nebula
- GraphX:https://github.com/apache/spark/tree/master/graphx
- Spark-connector:https://github.com/vesoft-inc/nebula-java/tree/master/tools/nebula-spark
- Exchange:https://github.com/vesoft-inc/nebula-java/blob/master/doc/tools/exchange/ex-ug-toc.md
- nebula-algorithm:https://github.com/vesoft-inc/nebula-java/tree/v1.0/tools/nebula-algorithm
https://docs.nebula-graph.com.cn/1.2.1/nebula-algorithm/na-ug-what-is-nebula-algorithm/
什么是 nebula-algorithm¶
nebula-algorithm 是一款基于 GraphX 的 Spark 应用程序,提供了 PageRank 和 Louvain 社区发现的图计算算法。使用 nebula-algorithm,您能以提交 Spark 任务的形式对 Nebula Graph 数据库中的数据执行图计算。
目前 nebula-algorithm 仅提供了 PageRank 和 Louvain 社区发现算法。如果您有其他需求,可以参考本项目,编写 Spark 应用程序调用 GraphX 自带的其他图算法,如 LabelPropagation、ConnectedComponent 等。
实现方法¶
nebula-algorithm 根据以下方式实现图算法:
- 从 Nebula Graph 数据库中读取图数据并处理成 DataFrame。
- 将 DataFrame 转换为 GraphX 的图。
- 调用 GraphX 提供的图算法(例如 PageRank)或者您自己实现的算法(例如 Louvain 社区发现)。
详细的实现方式,您可以参考 LouvainAlgo.scala 和 PageRankAlgo.scala。
PageRank 和 Louvain 简介¶
PageRank¶
GraphX 的 PageRank 算法基于 Pregel 计算模型,该算法流程包括 3 个步骤:
- 为图中每个顶点(如网页)设置一个相同的初始 PageRank 值。
- 第一次迭代:沿边发送消息,每个顶点收到所有关联边上邻接点(Adjacent Node)的信息,得到一个新的 PageRank 值;
- 第二次迭代:用这组新的 PageRank 按不同算法模式对应的公式形成该顶点新的 PageRank。
关于 PageRank 的详细信息,参考 Wikipedia PageRank 页面。
Louvain¶
Louvain 是基于模块度(Modularity)的社区发现算法,通过模块度来衡量一个社区的紧密程度,属于图的聚类算法。如果一个顶点加入到某一社区中使该社区的模块度相比其他社区有最大程度的增加,则该顶点就应当属于该社区。如果加入其它社区后没有使其模块度增加,则留在自己当前社区中。详细信息,您可以参考论文《Fast unfolding of communities in large networks》。
Louvain 算法包括两个阶段,其流程就是这两个阶段的迭代过程。
- 阶段一:不断地遍历网络图中的顶点,通过比较顶点给每个邻居社区带来的模块度的变化,将单个顶点加入到能够使 Modulaity 模块度有最大增量的社区中。例如,顶点 v 分别加入到社区 A、B、C 中,使得三个社区的模块度增量为 -1、1、2,则顶点 v 最终应该加入到社区 C 中。
- 阶段二:对第一阶段进行处理,将属于同一社区的顶点合并为一个大的超点重新构造网络图,即一个社区作为图的一个新的顶点。此时两个超点之间边的权重是两个超点内所有原始顶点之间相连的边权重之和,即两个社区之间的边权重之和。
整个 Louvain 算法就是不断迭代第一阶段和第二阶段,直到算法稳定(图的模块度不再变化)或者到达最大迭代次数。
使用场景¶
您可以将 PageRank 算法应用于以下场景:
- 社交应用的相似度内容推荐:在对微博、微信等社交平台进行社交网络分析时,可以基于 PageRank 算法根据用户通常浏览的信息以及停留时间实现基于用户的相似度的内容推荐。
- 分析用户社交影响力:在社交网络分析时根据用户的 PageRank 值进行用户影响力分析。
- 文献重要性研究:根据文献的 PageRank 值评判该文献的质量,PageRank 算法就是基于评判文献质量的想法来实现设计。
您可以将 Louvain 算法应用于以下场景:
- 金融风控:在金融风控场景中根据用户行为特征进行团伙识别。
- 社交网络:基于网络关系中点对(一条边连接的两个顶点)之间关联的广度和强度进行社交网络划分;对复杂网络分析、电话网络分析人群之间的联系密切度。
- 推荐系统:基于用户兴趣爱好的社区发现,可以根据社区并结合协同过滤等推荐算法进行更精确有效的个性化推荐。
使用限制¶
nebula-algorithm 目前仅支持 Nebula Graph v1.x,不支持 Nebula Graph v2.x。
编译 nebula-algorithm¶
前提条件¶
编译 nebula-algorithm 之前,必须先编译 Nebula Spark Connector。
操作步骤¶
切换到 nebula-java/tools/nebula-algorithm 目录,并编译打包 nebula-algorithm。
$ cd nebula-java/tools/nebula-algorithm
$ mvn clean package -Dgpg.skip -Dmaven.javadoc.skip=true -Dmaven.test.skip=true
编译成功后,您可以在当前目录里看到如下目录结构。
.
├── README.md
├── pom.xml
├── src
│ ├── main
│ └── test
└── target
├── classes
├── classes.682519136.timestamp
├── maven-archiver
├── maven-status
├── nebula-algorithm-1.x.y-tests.jar
├── nebula-algorithm-1.x.y.jar
├── original-nebula-algorithm-1.x.y.jar
├── test-classes
└── test-classes.682519136.timestamp
在 target 目录下,您可以看到 nebula-algorithm-1.x.y.jar 文件。
说明:JAR 文件版本号会因 Nebula Java Client 的发布版本而异。您可以在 nebula-java 仓库的 Releases 页面 查看最新的 v1.x 版本。
后续操作¶
在使用 nebula-algorithm 时,您可以参考 target/classes/application.conf 根据实际情况修改配置文件。详细信息请参考 使用示例。
使用示例¶
一般,您可以按以下步骤使用 nebula-algorithm:
- 参考配置文件修改 nebula-algorithm 的配置。
- 运行 nebula-algorithm。
本文以一个示例说明如何使用 nebula-algorithm。
示例环境¶
- 三台虚拟机,配置如下:
- CPU:Intel(R) Xeon(R) Platinum 8260M CPU @ 2.30GHz
- Processors:32
- CPU Cores:16
- 内存:128 GB
- 软件环境:
- Spark:spark-2.4.6-bin-hadoop2.7 三个节点集群
- yarn V2.10.0:三个节点集群
- Nebula Graph V1.2.1:分布式部署,默认配置
示例数据¶
在本示例中,Nebula Graph 图空间名称为 algoTest,Schema 要素如下表所示。
| 要素 | 名称 | 属性 |
|---|---|---|
| 标签 | PERSON |
无 |
| 边类型 | FRIEND |
likeness(double) |
前提条件¶
在操作之前,您需要确认以下信息:
- 已经完成 nebula-algorithm 编译。详细信息参考 编译 nebula-algorithm。
- Nebula Graph 数据库中已经有图数据。您可以使用不同的方式将其他来源的数据导入 Nebula Graph 数据库中,例如 Spark Writer。
- 当前机器上已经安装 Spark 并已启动 Spark 服务。
第 1 步. 修改配置文件¶
根据项目中的 src/main/resources/application.conf 文件修改 nebula-algorithm 配置。
{
# Spark 相关设置
spark: {
app: {
# Spark 应用程序的名称,可选项。默认设置为您即将运行的算法名称,例如 PageRank
name: PageRank
# Spark 中分区数量,可选项。
partitionNum: 12
}
master: local
# 可选项,如果这里未设置,则在执行 spark-submit spark 任务时设置
conf: {
driver-memory: 20g
executor-memory: 100g
executor-cores: 3
cores-max:6
}
}
# Nebula Graph 相关配置
nebula: {
# 必需。Meta 服务的信息
addresses: "127.0.0.1:45500" # 如果有多个 Meta 服务复本,则以英文逗号隔开
user: root
pswd: nebula
space: algoTest
# 必需。创建图空间时设置的分区数量。如果创建图空间时未设置分区数,则设置为默认值 100
partitionNumber: 100
# 必需。Nebula Graph 的边类型,如果有多种边类型,则以英文逗号隔开
labels: ["FRIENDS"]
hasWeight: true
# 如果 hasWeight 配置为 true,则必须配置 weightCols。根据 labels 列出的边类型,按顺序在 weightCols 里设置对应的属性,一种边类型仅对应一个属性
# 说明:nebula-algorithm 仅支持同构图,所以,weightCols 中列出的属性的数据类型必须保持一致而且均为数字类型
weightCols: ["likeness"] # 如果 labels 里有多种边类型,则相应设置对应的属性,属性之间以英文逗号隔开
}
algorithm: {
# 指定即将执行的算法,可以配置为 pagerank 或 louvain
executeAlgo: louvain
# 指定算法结果的存储路径
path: /tmp
# 如果选择的是 PageRank,则配置 pagerank 相关参数
#pagerank: {
# maxIter: 20
# resetProb: 0.15 # 默认值为 0.15
#}
# 如果选择的是 louvain,则配置 louvain 相关参数
#louvain: {
# maxIter: 20
# internalIter: 10
# tol: 0.5
#}
}
}
第 2 步. 执行 nebula-algorithm¶
运行以下命令,提交 nebula-algorithm 应用程序。
spark-submit --master "local" --class com.vesoft.nebula.tools.algorithm.Main /your-jar-path/nebula-algorithm-1.x.y.jar -p /your-application.conf-path/application.conf
其中,
--master:指定 Spark 集群中Master 进程的 URL。详细信息,参考 master-urls。--class:指定 Driver 主类。- 指定 nebula-algorithm JAR 文件的路径,JAR 文件版本号以您实际编译得到的 JAR 文件名称为准。
-p:Spark 配置文件文件路径。- 其他:如果您未在配置文件中设置 Spark 的任务资源分配(
conf)信息,您可以在这个命令中指定。例如,本示例中,--driver-memory=20G --executor-memory=100G --executor-cores=3。
测试结果¶
按本示例设置的 Spark 任务资源分配,对于一个拥有一亿个数据的数据集:
- PageRank 的执行时间(PageRank 算法执行时间)为 21 分钟
- Louvain 的执行时间(Reader + Louvain 算法执行时间)为 1.3 小时

 浙公网安备 33010602011771号
浙公网安备 33010602011771号