
Nebula入门学习——day4 nGQL中的图查询和其他算法
MATCH¶
MATCH语句提供基于模式(pattern)匹配的搜索功能。
一个MATCH语句定义了一个搜索模式,用该模式匹配存储在 Nebula Graph 中的数据,然后用RETURN子句检索数据。
本文示例使用测试数据集 basketballplayer 进行演示。
我自己最喜欢用的是:
(root@nebula) [basketballplayer]> MATCH (v) RETURN v LIMIT 10
+-----------------------------------------------------------+
| v |
+-----------------------------------------------------------+
| ("player102" :player{age: 33, name: "LaMarcus Aldridge"}) |
| ("player106" :player{age: 25, name: "Kyle Anderson"}) |
| ("player115" :player{age: 40, name: "Kobe Bryant"}) |
| ("player129" :player{age: 37, name: "Dwyane Wade"}) |
| ("player138" :player{age: 38, name: "Paul Gasol"}) |
| ("team209" :team{name: "Timberwolves"}) |
| ("team225" :team{name: "Bucks"}) |
| ("team226" :team{name: "Magic"}) |
| ("player108" :player{age: 36, name: "Boris Diaw"}) |
| ("player122" :player{age: 30, name: "DeAndre Jordan"}) |
+---------------------------------------
语法¶
与GO或LOOKUP等其他查询语句相比,MATCH的语法更灵活。MATCH语句采用的路径类型是trail,即遍历时只有点可以重复,边不可以重复。
MATCH 语法如下:
MATCH <pattern> [<clause_1>] RETURN <output> [<clause_2>];
pattern:pattern 的详细说明请参见模式。MATCH语句支持匹配一个或多个模式,多个模式之间用英文逗号(,)分隔。例如(a)-[]->(b),(c)-[]->(d)。
clause_1:支持WHERE、WITH、UNWIND、OPTIONAL MATCH子句,也可以使用MATCH作为子句。
output:定义需要返回的输出。可以使用AS设置输出的别名。
clause_2:支持ORDER BY、LIMIT子句。
注意事项¶
除以下三种情况之外,请确保 MATCH 语句有至少一个索引可用。
MATCH语句中WHERE子句使用 id() 函数指定了点的 VID,不需要创建索引即可执行。
- 当遍历所有点边时,例如
MATCH (v) RETURN v LIMIT N,不需要创建索引,但必须使用LIMIT限制输出结果数量。
- 当遍历指定 Tag 的点或指定 Edge Type 的边时,例如
MATCH (v:player) RETURN v LIMIT N,不需要创建索引,但必须使用LIMIT限制输出结果数量。
Note
目前 match 语句无法查询到悬挂边。
历史版本兼容性
从 3.0.0 版本开始,为了区别不同 Tag 的属性,返回属性时必须额外指定 Tag 名称。即从RETURN <变量名>.<属性名>改为RETURN <变量名>.<Tag名>.<属性名>。
示例¶
创建索引¶
# 在 Tag player 的 name 属性和 Edge type follow 上创建索引。
nebula> CREATE TAG INDEX IF NOT EXISTS name ON player(name(20));
nebula> CREATE EDGE INDEX IF NOT EXISTS follow_index on follow();
# 重建索引使其生效。
nebula> REBUILD TAG INDEX name;
+------------+
| New Job Id |
+------------+
| 121 |
+------------+
nebula> REBUILD EDGE INDEX follow_index;
+------------+
| New Job Id |
+------------+
| 122 |
+------------+
# 确认重建索引成功。
nebula> SHOW JOB 121;
+----------------+---------------------+------------+----------------------------+----------------------------+-------------+
| Job Id(TaskId) | Command(Dest) | Status | Start Time | Stop Time | Error Code |
+----------------+---------------------+------------+----------------------------+----------------------------+-------------+
| 121 | "REBUILD_TAG_INDEX" | "FINISHED" | 2021-05-27T02:18:02.000000 | 2021-05-27T02:18:02.000000 | "SUCCEEDED" |
| 0 | "storaged1" | "FINISHED" | 2021-05-27T02:18:02.000000 | 2021-05-27T02:18:02.000000 | "SUCCEEDED" |
| 1 | "storaged0" | "FINISHED" | 2021-05-27T02:18:02.000000 | 2021-05-27T02:18:02.000000 | "SUCCEEDED" |
| 2 | "storaged2" | "FINISHED" | 2021-05-27T02:18:02.000000 | 2021-05-27T02:18:02.000000 | "SUCCEEDED" |
+----------------+---------------------+------------+----------------------------+----------------------------+-------------+
nebula> SHOW JOB 122;
+----------------+----------------------+------------+----------------------------+----------------------------+-------------+
| Job Id(TaskId) | Command(Dest) | Status | Start Time | Stop Time | Error Code |
+----------------+----------------------+------------+----------------------------+----------------------------+-------------+
| 122 | "REBUILD_EDGE_INDEX" | "FINISHED" | 2021-05-27T02:18:11.000000 | 2021-05-27T02:18:11.000000 | "SUCCEEDED" |
| 0 | "storaged1" | "FINISHED" | 2021-05-27T02:18:11.000000 | 2021-05-27T02:18:21.000000 | "SUCCEEDED" |
| 1 | "storaged0" | "FINISHED" | 2021-05-27T02:18:11.000000 | 2021-05-27T02:18:21.000000 | "SUCCEEDED" |
| 2 | "storaged2" | "FINISHED" | 2021-05-27T02:18:11.000000 | 2021-05-27T02:18:21.000000 | "SUCCEEDED" |
+----------------+----------------------+------------+----------------------------+----------------------------+-------------+
==》什么鬼。。。job清单如何查看???
匹配点¶
历史版本兼容性
从 Nebula Graph 3.0.0 开始,支持MATCH (v) RETURN v LIMIT n,不需要创建索引; 但是必须使用 LIMIT 限制输出结果数量。
不可以直接执行 MATCH (v) RETURN v。
用户可以在一对括号中使用自定义变量来表示模式中的点。例如(v)。
nebula> MATCH (v) \
RETURN v \
LIMIT 3;
+-----------------------------------------------------------+
| v |
+-----------------------------------------------------------+
| ("player102" :player{age: 33, name: "LaMarcus Aldridge"}) |
| ("player106" :player{age: 25, name: "Kyle Anderson"}) |
| ("player115" :player{age: 40, name: "Kobe Bryant"}) |
+-----------------------------------------------------------+
如果不指定tag则有返回同时有team和player:
(root@nebula) [basketballplayer]> MATCH (v) RETURN v LIMIT 100
+---------------------------------------------------------------+
| v |
+---------------------------------------------------------------+
| ("player114" :player{age: 39, name: "Tracy McGrady"}) |
| ("player150" :player{age: 20, name: "Luka Doncic"}) |
| ("team204" :team{name: "Spurs"}) |
| ("team218" :team{name: "Raptors"}) |
| ("team229" :team{name: "Heat"}) |
| ("player105" :player{age: 31, name: "Danny Green"}) |
| ("player109" :player{age: 34, name: "Tiago Splitter"}) |
| ("player111" :player{age: 38, name: "David West"}) |
| ("player118" :player{age: 30, name: "Russell Westbrook"}) |
匹配 Tag¶
历史版本兼容性
在 Nebula Graph 3.0.0 之前,匹配 Tag 的前提是 Tag 本身有索引或者 Tag 的某个属性有索引,否则,用户无法基于该 Tag 执行 MATCH 语句。从 Nebula Graph 3.0.0 开始,匹配 Tag 可以不创建索引,但需要使用 LIMIT 限制输出结果数量。
用户可以在点的右侧用:<tag_name>表示模式中的 Tag。
nebula> MATCH (v:player) \
RETURN v \
LIMIT 3;
+-----------------------------------------------------------+
| v |
+-----------------------------------------------------------+
| ("player102" :player{age: 33, name: "LaMarcus Aldridge"}) |
| ("player106" :player{age: 25, name: "Kyle Anderson"}) |
| ("player115" :player{age: 40, name: "Kobe Bryant"}) |
+-----------------------------------------------------------+
...
需要匹配拥有多个 Tag 的点,可以用英文冒号(:)。
nebula> CREATE TAG actor (name string, age int);
nebula> INSERT VERTEX actor(name, age) VALUES "player100":("Tim Duncan", 42);
nebula> MATCH (v:player:actor) \
RETURN v \
LIMIT 10;
+----------------------------------------------------------------------------------------+
| v |
+----------------------------------------------------------------------------------------+
| ("player100" :actor{age: 42, name: "Tim Duncan"} :player{age: 42, name: "Tim Duncan"}) |
+----------------------------------------------------------------------------------------+
匹配点的属性¶
Note
匹配点的属性的前提是 Tag 本身有对应属性的索引,否则,用户无法执行 MATCH 语句匹配该属性。
用户可以在 Tag 的右侧用{<prop_name>: <prop_value>}表示模式中点的属性。
# 使用属性 name 搜索匹配的点。
nebula> MATCH (v:player{name:"Tim Duncan"}) \
RETURN v;
+----------------------------------------------------+
| v |
+----------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"}) |
+----------------------------------------------------+
使用WHERE子句也可以实现相同的操作:
nebula> MATCH (v:player) \
WHERE v.player.name == "Tim Duncan" \
RETURN v;
+----------------------------------------------------+
| v |
+----------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"}) |
+----------------------------------------------------+
openCypher 兼容性
在 openCypher 9 中,=是相等运算符,在 nGQL 中,==是相等运算符,=是赋值运算符。
匹配点 ID¶
用户可以使用点 ID 去匹配点。id()函数可以检索点的 ID。
nebula> MATCH (v) \
WHERE id(v) == 'player101' \
RETURN v;
+-----------------------------------------------------+
| v |
+-----------------------------------------------------+
| ("player101" :player{age: 36, name: "Tony Parker"}) |
+-----------------------------------------------------+
要匹配多个点的 ID,可以用WHERE id(v) IN [vid_list]。
nebula> MATCH (v:player { name: 'Tim Duncan' })--(v2) \
WHERE id(v2) IN ["player101", "player102"] \
RETURN v2;
+-----------------------------------------------------------+
| v2 |
+-----------------------------------------------------------+
| ("player101" :player{age: 36, name: "Tony Parker"}) |
| ("player101" :player{age: 36, name: "Tony Parker"}) |
| ("player102" :player{age: 33, name: "LaMarcus Aldridge"}) |
+-----------------------------------------------------------+
匹配连接的点¶
用户可以使用--符号表示两个方向的边,并匹配这些边连接的点。
历史版本兼容性
在 nGQL 1.x 中,--符号用于行内注释,从 nGQL 2.x 起,--符号表示出边或入边,不再用于注释。
nebula> MATCH (v:player{name:"Tim Duncan"})--(v2:player) \
RETURN v2.player.name AS Name;
+---------------------+
| Name |
+---------------------+
| "Manu Ginobili" |
| "Manu Ginobili" |
| "Dejounte Murray" |
...
用户可以在--符号上增加<或>符号指定边的方向。
# -->表示边从 v 开始,指向 v2。对于点 v 来说是出边,对于点 v2 来说是入边。
nebula> MATCH (v:player{name:"Tim Duncan"})-->(v2:player) \
RETURN v2.player.name AS Name;
+-----------------+
| Name |
+-----------------+
| "Tony Parker" |
| "Manu Ginobili" |
+-----------------+
如果需要判断目标点,可以使用CASE表达式。
nebula> MATCH (v:player{name:"Tim Duncan"})--(v2) \
RETURN \
CASE WHEN v2.team.name IS NOT NULL \
THEN v2.team.name \
WHEN v2.player.name IS NOT NULL \
THEN v2.player.name END AS Name;
+---------------------+
| Name |
+---------------------+
| "Manu Ginobili" |
| "Manu Ginobili" |
| "Spurs" |
| "Dejounte Murray" |
...
如果需要扩展模式,可以增加更多点和边。
nebula> MATCH (v:player{name:"Tim Duncan"})-->(v2)<--(v3) \
RETURN v3.player.name AS Name;
+---------------------+
| Name |
+---------------------+
| "Dejounte Murray" |
| "LaMarcus Aldridge" |
| "Marco Belinelli" |
...
如果不需要引用点,可以省略括号中表示点的变量。
nebula> MATCH (v:player{name:"Tim Duncan"})-->()<--(v3) \
RETURN v3.player.name AS Name;
+---------------------+
| Name |
+---------------------+
| "Dejounte Murray" |
| "LaMarcus Aldridge" |
| "Marco Belinelli" |
...
匹配路径¶
连接起来的点和边构成了路径。用户可以使用自定义变量命名路径。
nebula> MATCH p=(v:player{name:"Tim Duncan"})-->(v2) \
RETURN p; ==》一直没有找到,原来是要这样写!!!【【常用!!!!】】
+--------------------------------------------------------------------------------------------------------------------------------------+
| p |
+--------------------------------------------------------------------------------------------------------------------------------------+
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:serve@0 {end_year: 2016, start_year: 1997}]->("team204" :team{name: "Spurs"})> |
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:follow@0 {degree: 95}]->("player101" :player{age: 36, name: "Tony Parker"})> |
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:follow@0 {degree: 95}]->("player125" :player{age: 41, name: "Manu Ginobili"})> |
+--------------------------------------------------------------------------------------------------------------------------------------+
openCypher 兼容性
在 nGQL 中,@符号表示边的 rank,在 openCypher 中,没有 rank 概念。
匹配边¶
历史版本兼容性
在 Nebula Graph 3.0.0 之前,匹配边的前提是边本身有对应属性的索引,否则,用户无法基于边执行 MATCH 语句。从 Nebula Graph 3.0.0 开始,匹配边可以不创建索引,但需要使用 LIMIT 限制输出结果数量,并且必须指定边的方向。
nebula> MATCH ()<-[e]-() \
RETURN e \
LIMIT 3;
+----------------------------------------------------+
| e |
+----------------------------------------------------+
| [:follow "player101"->"player102" @0 {degree: 90}] |
| [:follow "player103"->"player102" @0 {degree: 70}] |
| [:follow "player135"->"player102" @0 {degree: 80}] |
+----------------------------------------------------+
匹配 Edge type¶
和点一样,用户可以用:<edge_type>表示模式中的 Edge type,例如-[e:follow]-。
历史版本兼容性
在 Nebula Graph 3.0.0 之前,匹配 Edge Type 的前提是 Edge type 本身有对应属性的索引,否则,用户无法基于 Edge Type 执行 MATCH 语句。从 Nebula Graph 3.0.0 开始,匹配 Edge Type 可以不创建索引,但需要使用 LIMIT 限制输出结果数量,并且必须指定边的方向。
nebula> MATCH ()-[e:follow]->() \
RETURN e \
limit 3; ==》原来不用上面的方式,也可以返回边!!!像我下面这样,不指定edge type也是可以的!!!【【常用!!!!】】
+----------------------------------------------------+
| e |
+----------------------------------------------------+
| [:follow "player102"->"player100" @0 {degree: 75}] |
| [:follow "player102"->"player101" @0 {degree: 75}] |
| [:follow "player129"->"player116" @0 {degree: 90}] |
+----------------------------------------------------+
(root@nebula) [basketballplayer]> MATCH ()-[e:follow]->() \
-> RETURN e \
-> limit 3;
+----------------------------------------------------+
| e |
+----------------------------------------------------+
| [:follow "player102"->"player100" @0 {degree: 75}] |
| [:follow "player102"->"player101" @0 {degree: 75}] |
| [:follow "player129"->"player116" @0 {degree: 90}] |
+----------------------------------------------------+
Got 3 rows (time spent 1350/1667 us)
Tue, 24 May 2022 17:06:49 CST
(root@nebula) [basketballplayer]> MATCH ()-[e]->() RETURN e limit 3;
+-----------------------------------------------------------------------+
| e |
+-----------------------------------------------------------------------+
| [:serve "player102"->"team203" @0 {end_year: 2015, start_year: 2006}] |
| [:serve "player102"->"team204" @0 {end_year: 2019, start_year: 2015}] |
| [:follow "player102"->"player100" @0 {degree: 75}] |
+-----------------------------------------------------------------------+
Got 3 rows (time spent 1314/1635 us)
Tue, 24 May 2022 17:06:56 CST
匹配边的属性¶
Note
匹配边的属性的前提是 Edge type 本身有对应属性的索引,否则,用户无法执行 MATCH 语句匹配该属性。
用户可以用{<prop_name>: <prop_value>}表示模式中 Edge type 的属性,例如[e:follow{likeness:95}]。
nebula> MATCH (v:player{name:"Tim Duncan"})-[e:follow{degree:95}]->(v2) \
RETURN e;
+--------------------------------------------------------+
| e |
+--------------------------------------------------------+
| [:follow "player100"->"player101" @0 {degree: 95}] |
| [:follow "player100"->"player125" @0 {degree: 95}] |
+--------------------------------------------------------+
匹配多个 Edge type¶
使用|可以匹配多个 Edge type,例如[e:follow|:serve]。第一个 Edge type 前的英文冒号(:)不可省略,后续 Edge type 前的英文冒号可以省略,例如[e:follow|serve]。
nebula> MATCH (v:player{name:"Tim Duncan"})-[e:follow|:serve]->(v2) \
RETURN e;
+---------------------------------------------------------------------------+
| e |
+---------------------------------------------------------------------------+
| [:follow "player100"->"player101" @0 {degree: 95}] |
| [:follow "player100"->"player125" @0 {degree: 95}] |
| [:serve "player100"->"team204" @0 {end_year: 2016, start_year: 1997}] |
+---------------------------------------------------------------------------+
匹配多条边¶
用户可以扩展模式,匹配路径中的多条边。
nebula> MATCH (v:player{name:"Tim Duncan"})-[]->(v2)<-[e:serve]-(v3) \
RETURN v2, v3;
+----------------------------------+-----------------------------------------------------------+
| v2 | v3 |
+----------------------------------+-----------------------------------------------------------+
| ("team204" :team{name: "Spurs"}) | ("player104" :player{age: 32, name: "Marco Belinelli"}) |
| ("team204" :team{name: "Spurs"}) | ("player101" :player{age: 36, name: "Tony Parker"}) |
| ("team204" :team{name: "Spurs"}) | ("player102" :player{age: 33, name: "LaMarcus Aldridge"}) |
...
匹配定长路径¶
用户可以在模式中使用:<edge_type>*<hop>匹配定长路径。hop必须是一个非负整数。
nebula> MATCH p=(v:player{name:"Tim Duncan"})-[e:follow*2]->(v2) \
RETURN DISTINCT v2 AS Friends;
+-----------------------------------------------------------+
| Friends |
+-----------------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"}) |
| ("player125" :player{age: 41, name: "Manu Ginobili"}) |
| ("player102" :player{age: 33, name: "LaMarcus Aldridge"}) |
+-----------------------------------------------------------+
我们看看边上面的匹配结果是如何发生的:
(root@nebula) [basketballplayer]> MATCH p=(v:player{name:"Tim Duncan"})-[e:follow*2]->(v2) RETURN p;
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| p |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:follow@0 {degree: 95}]->("player101" :player{age: 36, name: "Tony Parker"})-[:follow@0 {degree: 95}]->("player125" :player{age: 41, name: "Manu Ginobili"})> |
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:follow@0 {degree: 95}]->("player101" :player{age: 36, name: "Tony Parker"})-[:follow@0 {degree: 95}]->("player100" :player{age: 42, name: "Tim Duncan"})> |
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:follow@0 {degree: 95}]->("player125" :player{age: 41, name: "Manu Ginobili"})-[:follow@0 {degree: 90}]->("player100" :player{age: 42, name: "Tim Duncan"})> |
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:follow@0 {degree: 95}]->("player101" :player{age: 36, name: "Tony Parker"})-[:follow@0 {degree: 90}]->("player102" :player{age: 33, name: "LaMarcus Aldridge"})> |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
如果hop为 0,模式会匹配路径上的起始点。
nebula> MATCH (v:player{name:"Tim Duncan"}) -[*0]-> (v2) \
RETURN v2;
+----------------------------------------------------+
| v2 |
+----------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"}) |
+----------------------------------------------------+
匹配变长路径¶
用户可以在模式中使用:<edge_type>*[minHop..maxHop]匹配变长路径。
Note
设置边界时,minHop 和 maxHop 至少存在其中一个。
Caution
如果未设置 maxHop 可能会导致 graph 服务 OOM,请谨慎执行该命令。
| 参数 | 说明 |
|---|---|
minHop |
可选项。表示路径的最小长度。minHop必须是一个非负整数,默认值为 1。 |
maxHop |
可选项。表示路径的最大长度。maxHop必须是一个非负整数,默认值为无穷大。 |
nebula> MATCH p=(v:player{name:"Tim Duncan"})-[e:follow*]->(v2) \
RETURN v2 AS Friends;
+-----------------------------------------------------------+
| Friends |
+-----------------------------------------------------------+
| ("player125" :player{age: 41, name: "Manu Ginobili"}) |
| ("player101" :player{age: 36, name: "Tony Parker"}) |
...
nebula> MATCH p=(v:player{name:"Tim Duncan"})-[e:follow*1..3]->(v2) \
RETURN v2 AS Friends;
+-----------------------------------------------------------+
| Friends |
+-----------------------------------------------------------+
| ("player101" :player{age: 36, name: "Tony Parker"}) |
| ("player125" :player{age: 41, name: "Manu Ginobili"}) |
| ("player100" :player{age: 42, name: "Tim Duncan"}) |
...
nebula> MATCH p=(v:player{name:"Tim Duncan"})-[e:follow*1..]->(v2) \
RETURN v2 AS Friends;
+-----------------------------------------------------------+
| Friends |
+-----------------------------------------------------------+
| ("player125" :player{age: 41, name: "Manu Ginobili"}) |
| ("player101" :player{age: 36, name: "Tony Parker"}) |
| ("player100" :player{age: 42, name: "Tim Duncan"}) |
...
两跳之内匹配:【如果不建索引,是没法搞的啊!!!当心!!!】
(root@nebula) [basketballplayer]> MATCH p=(v:player{name:"Tim Duncan"})-[e:follow*1..2]->(v2) RETURN p;
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| p |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:follow@0 {degree: 95}]->("player125" :player{age: 41, name: "Manu Ginobili"})> |
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:follow@0 {degree: 95}]->("player101" :player{age: 36, name: "Tony Parker"})> |
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:follow@0 {degree: 95}]->("player101" :player{age: 36, name: "Tony Parker"})-[:follow@0 {degree: 95}]->("player125" :player{age: 41, name: "Manu Ginobili"})> |
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:follow@0 {degree: 95}]->("player101" :player{age: 36, name: "Tony Parker"})-[:follow@0 {degree: 95}]->("player100" :player{age: 42, name: "Tim Duncan"})> |
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:follow@0 {degree: 95}]->("player125" :player{age: 41, name: "Manu Ginobili"})-[:follow@0 {degree: 90}]->("player100" :player{age: 42, name: "Tim Duncan"})> |
| <("player100" :player{age: 42, name: "Tim Duncan"})-[:follow@0 {degree: 95}]->("player101" :player{age: 36, name: "Tony Parker"})-[:follow@0 {degree: 90}]->("player102" :player{age: 33, name: "LaMarcus Aldridge"})> |
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
用户可以使用DISTINCT关键字聚合重复结果。
nebula> MATCH p=(v:player{name:"Tim Duncan"})-[e:follow*1..3]->(v2:player) \
RETURN DISTINCT v2 AS Friends, count(v2);==》注意是两条独立语句!!!
+-----------------------------------------------------------+-----------+
| Friends | count(v2) |
+-----------------------------------------------------------+-----------+
| ("player102" :player{age: 33, name: "LaMarcus Aldridge"}) | 1 |
| ("player100" :player{age: 42, name: "Tim Duncan"}) | 4 |
| ("player101" :player{age: 36, name: "Tony Parker"}) | 3 |
| ("player125" :player{age: 41, name: "Manu Ginobili"}) | 3 |
+-----------------------------------------------------------+-----------+
如果minHop为0,模式会匹配路径上的起始点。与上个示例相比,下面的示例设置minHop为0,因为它是起始点,所以结果集中"Tim Duncan"比上个示例多计算一次。
nebula> MATCH p=(v:player{name:"Tim Duncan"})-[e:follow*0..3]->(v2:player) \
RETURN DISTINCT v2 AS Friends, count(v2);
+-----------------------------------------------------------+-----------+
| Friends | count(v2) |
+-----------------------------------------------------------+-----------+
| ("player102" :player{age: 33, name: "LaMarcus Aldridge"}) | 1 |
| ("player100" :player{age: 42, name: "Tim Duncan"}) | 5 |
| ("player125" :player{age: 41, name: "Manu Ginobili"}) | 3 |
| ("player101" :player{age: 36, name: "Tony Parker"}) | 3 |
+-----------------------------------------------------------+-----------+
匹配多个 Edge type 的变长路径¶
用户可以在变长或定长模式中指定多个 Edge type。hop、minHop和maxHop对所有 Edge type 都生效。
nebula> MATCH p=(v:player{name:"Tim Duncan"})-[e:follow|serve*2]->(v2) \
RETURN DISTINCT v2;
+-----------------------------------------------------------+
| v2 |
+-----------------------------------------------------------+
| ("team204" :team{name: "Spurs"}) |
| ("player100" :player{age: 42, name: "Tim Duncan"}) |
| ("team215" :team{name: "Hornets"}) |
| ("player125" :player{age: 41, name: "Manu Ginobili"}) |
| ("player102" :player{age: 33, name: "LaMarcus Aldridge"}) |
+-----------------------------------------------------------+
匹配多个模式¶
用户可以用英文逗号(,)分隔多个模式。
nebula> MATCH (v1:player{name:"Tim Duncan"}), (v2:team{name:"Spurs"}) \
RETURN v1,v2;
+----------------------------------------------------+----------------------------------+
| v1 | v2 |
+----------------------------------------------------+----------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"}) | ("team204" :team{name: "Spurs"}) |
+----------------------------------------------------+----------------------------------+
多MATCH检索¶
不同的模式有不同的筛选条件时,可以使用多MATCH,会返回模式完全匹配的行。
nebula> MATCH (m)-[]->(n) WHERE id(m)=="player100" \
MATCH (n)-[]->(l) WHERE id(n)=="player125" \
RETURN id(m),id(n),id(l);
+-------------+-------------+-------------+
| id(m) | id(n) | id(l) |
+-------------+-------------+-------------+
| "player100" | "player125" | "team204" |
| "player100" | "player125" | "player100" |
+-------------+-------------+-------------+
OPTIONAL MATCH检索¶
Performance
Nebula Graph 3.1.0 中MATCH语句的性能和资源占用得到了优化.但对性能要求较高时,仍建议使用 GO, LOOKUP, | 和 FETCH 等来替代MATCH。
OPTIONAL MATCH¶
OPTIONAL MATCH通常与MATCH语句一起使用,作为MATCH语句的可选项去匹配命中的模式,如果没有命中对应的模式,对应的列返回NULL。
openCypher 兼容性¶
本文操作仅适用于 nGQL 中的 openCypher 方式。
示例¶
MATCH语句中使用OPTIONAL MATCH的示例如下:
nebula> MATCH (m)-[]->(n) WHERE id(m)=="player100" \
OPTIONAL MATCH (n)-[]->(l) WHERE id(n)=="player125" \
RETURN id(m),id(n),id(l);
+-------------+-------------+-------------+
| id(m) | id(n) | id(l) |
+-------------+-------------+-------------+
| "player100" | "team204" | __NULL__ |
| "player100" | "player101" | __NULL__ |
| "player100" | "player125" | "team204" |
| "player100" | "player125" | "player100" |
+-------------+-------------+-------------+
而使用多MATCH,不使用OPTIONAL MATCH时,会返回模式完全匹配的行。示例如下:
nebula> MATCH (m)-[]->(n) WHERE id(m)=="player100" \
MATCH (n)-[]->(l) WHERE id(n)=="player125" \
RETURN id(m),id(n),id(l);
+-------------+-------------+-------------+
| id(m) | id(n) | id(l) |
+-------------+-------------+-------------+
| "player100" | "player125" | "team204" |
| "player100" | "player125" | "player100" |
+-------------+-------------+-------------+
LOOKUP¶
LOOKUP根据索引遍历数据。用户可以使用LOOKUP实现如下功能:
- 根据
WHERE子句搜索特定数据。
- 通过 Tag 列出点:检索指定 Tag 的所有点 ID。
- 通过 Edge type 列出边:检索指定 Edge type 的所有边的起始点、目的点和 rank。
- 统计包含指定 Tag 的点或属于指定 Edge type 的边的数量。
OpenCypher 兼容性¶
本文操作仅适用于原生 nGQL。
注意事项¶
- 索引会导致写性能大幅降低(降低 90%甚至更多)。请不要随意在生产环境中使用索引,除非很清楚使用索引对业务的影响。
-
通过Explain命令查看选择的索引。
历史版本兼容性
在 2.5.0 版本之前,如果用
LOOKUP语句基于指定属性查询时该属性没有索引,系统将报错,而不会使用其它索引。
前提条件¶
请确保LOOKUP语句有至少一个索引可用。
如果已经存在相关的点、边或属性,必须在新创建索引后重建索引,才能使其生效。
Lookup语法¶
LOOKUP ON {<vertex_tag> | <edge_type>} ==》这玩意专门针对边的搜索???
[WHERE <expression> [AND <expression> ...]]
YIELD <return_list> [AS <alias>]; ==》为啥是yield而不是return???
<return_list>
<prop_name> [AS <col_alias>] [, <prop_name> [AS <prop_alias>] ...];
WHERE <expression>:指定遍历的过滤条件,还可以结合布尔运算符 AND 和 OR 一起使用。详情请参见 WHERE。
YIELD:定义需要返回的输出。详情请参见YIELD。
AS:设置别名。
WHERE 语句限制¶
在LOOKUP语句中使用WHERE子句,不支持如下操作:
$-和$^。- 在关系表达式中,不支持运算符两边都有字段名,例如
tagName.prop1 > tagName.prop2。 - 不支持运算表达式和函数表达式中嵌套 AliasProp 表达式。
- 不支持 XOR 运算符。
- 不支持除
STARTS WITH之外的字符串操作。 - 不支持图模式
检索点¶
返回 Tag 为player且name为Tony Parker的点。
nebula> CREATE TAG INDEX IF NOT EXISTS index_player ON player(name(30), age);==》是name和age都会建立索引?
nebula> REBUILD TAG INDEX index_player;
+------------+
| New Job Id |
+------------+
| 15 |
+------------+
nebula> LOOKUP ON player \
WHERE player.name == "Tony Parker" \
YIELD id(vertex);
+---------------+
| id(VERTEX) |
+---------------+
| "player101" |
+---------------+
nebula> LOOKUP ON player \
WHERE player.name == "Tony Parker" \
YIELD properties(vertex).name AS name, properties(vertex).age AS age;
+---------------+-----+
| name | age |
+---------------+-----+
| "Tony Parker" | 36 |
+---------------+-----+
nebula> LOOKUP ON player \
WHERE player.age > 45 \
YIELD id(vertex);
+-------------+
| id(VERTEX) |
+-------------+
| "player144" |
| "player140" |
+-------------+
nebula> LOOKUP ON player \
WHERE player.name STARTS WITH "B" \
AND player.age IN [22,30] \
YIELD properties(vertex).name, properties(vertex).age;
+-------------------------+------------------------+
| properties(VERTEX).name | properties(VERTEX).age |
+-------------------------+------------------------+
| "Ben Simmons" | 22 |
| "Blake Griffin" | 30 |
+-------------------------+------------------------+
nebula> LOOKUP ON player \
WHERE player.name == "Kobe Bryant"\
YIELD id(vertex) AS VertexID, properties(vertex).name AS name |\
GO FROM $-.VertexID OVER serve \
YIELD $-.name, properties(edge).start_year, properties(edge).end_year, properties($$).name;
+---------------+-----------------------------+---------------------------+---------------------+
| $-.name | properties(EDGE).start_year | properties(EDGE).end_year | properties($$).name |
+---------------+-----------------------------+---------------------------+---------------------+
| "Kobe Bryant" | 1996 | 2016 | "Lakers" |
+---------------+-----------------------------+---------------------------+---------------------+
检索边¶
返回 Edge type 为follow且degree为90的边。
nebula> CREATE EDGE INDEX IF NOT EXISTS index_follow ON follow(degree);
nebula> REBUILD EDGE INDEX index_follow;
+------------+
| New Job Id |
+------------+
| 62 |
+------------+
nebula> LOOKUP ON follow \
WHERE follow.degree == 90 YIELD edge AS e;
+----------------------------------------------------+
| e |
+----------------------------------------------------+
| [:follow "player109"->"player125" @0 {degree: 90}] |
| [:follow "player118"->"player120" @0 {degree: 90}] |
| [:follow "player118"->"player131" @0 {degree: 90}] |
...
nebula> LOOKUP ON follow \
WHERE follow.degree == 90 \
YIELD properties(edge).degree;
+-------------------------+
| properties(EDGE).degree |
+-------------------------+
| 90 |
| 90 |
...
nebula> LOOKUP ON follow \
WHERE follow.degree == 60 \
YIELD dst(edge) AS DstVID, properties(edge).degree AS Degree |\
GO FROM $-.DstVID OVER serve \
YIELD $-.DstVID, properties(edge).start_year, properties(edge).end_year, properties($$).name;
+-------------+-----------------------------+---------------------------+---------------------+
| $-.DstVID | properties(EDGE).start_year | properties(EDGE).end_year | properties($$).name |
+-------------+-----------------------------+---------------------------+---------------------+
| "player105" | 2010 | 2018 | "Spurs" |
| "player105" | 2009 | 2010 | "Cavaliers" |
| "player105" | 2018 | 2019 | "Raptors" |
+-------------+-----------------------------+---------------------------+---------------------+
通过 Tag 列出所有的对应的点/通过 Edge type 列出边¶
如果需要通过 Tag 列出所有的点,或通过 Edge type 列出边,则 Tag、Edge type 或属性上必须有至少一个索引。
例如一个 Tag player有属性name和age,为了遍历所有包含 Tag player的点 ID,Tag player、属性name或属性age中必须有一个已经创建索引。
- 查找所有 Tag 为
player的点 VID。
-
nebula> CREATE TAG IF NOT EXISTS player(name string,age int); nebula> CREATE TAG INDEX IF NOT EXISTS player_index on player(); nebula> REBUILD TAG INDEX player_index; +------------+ | New Job Id | +------------+ | 66 | +------------+ nebula> INSERT VERTEX player(name,age) \ VALUES "player100":("Tim Duncan", 42), "player101":("Tony Parker", 36); # 列出所有的 player。类似于 MATCH (n:player) RETURN id(n) /*, n */。 nebula> LOOKUP ON player YIELD id(vertex); +-------------+ | id(VERTEX) | +-------------+ | "player100" | | "player101" | ...
- 查找 Edge type 为
follow的所有边的信息。
-
nebula> CREATE EDGE IF NOT EXISTS follow(degree int); nebula> CREATE EDGE INDEX IF NOT EXISTS follow_index on follow(); nebula> REBUILD EDGE INDEX follow_index; +------------+ | New Job Id | +------------+ | 88 | +------------+ nebula> INSERT EDGE follow(degree) \ VALUES "player100"->"player101":(95); # 列出所有的 follow 边。类似于 MATCH (s)-[e:follow]->(d) RETURN id(s), rank(e), id(d) /*, type(e) */。 nebula)> LOOKUP ON follow YIELD edge AS e; +-----------------------------------------------------+ | e | +-----------------------------------------------------+ | [:follow "player105"->"player100" @0 {degree: 70}] | | [:follow "player105"->"player116" @0 {degree: 80}] | | [:follow "player109"->"player100" @0 {degree: 80}] | ...
统计点或边¶
统计 Tag 为player的点和 Edge type 为follow的边。
nebula> LOOKUP ON player YIELD id(vertex)|\
YIELD COUNT(*) AS Player_Number;
+---------------+
| Player_Number |
+---------------+
| 51 |
+---------------+
nebula> LOOKUP ON follow YIELD edge AS e| \
YIELD COUNT(*) AS Follow_Number;
+---------------+
| Follow_Number |
+---------------+
| 81 |
+---------------+
Note
使用 SHOW STATS命令也可以统计点和边。
感觉没有讲出lookup的应用场景和精髓!!!
GO¶
GO从给定起始点开始遍历图。GO语句采用的路径类型是walk,即遍历时点和边都可以重复。
openCypher 兼容性¶
本文操作仅适用于原生 nGQL。
语法¶
GO [[<M> TO] <N> STEPS ] FROM <vertex_list>
OVER <edge_type_list> [{REVERSELY | BIDIRECT}]
[ WHERE <conditions> ]
YIELD [DISTINCT] <return_list> ==》还是yield而不是return
[{ SAMPLE <sample_list> | <limit_by_list_clause> }]
[| GROUP BY {<col_name> | expression> | <position>} YIELD <col_name>]
[| ORDER BY <expression> [{ASC | DESC}]]
[| LIMIT [<offset>,] <number_rows>];
<vertex_list> ::=
<vid> [, <vid> ...]
<edge_type_list> ::=
<edge_type> [, <edge_type> ...]
| *
<return_list> ::=
<col_name> [AS <col_alias>] [, <col_name> [AS <col_alias>] ...]
<N> STEPS:指定跳数。如果没有指定跳数,默认值N为1。如果N为0,Nebula Graph 不会检索任何边。
M TO N STEPS:遍历M~N跳的边。如果M为0,输出结果和M为1相同,即GO 0 TO 2和GO 1 TO 2是相同的。
<vertex_list>:用逗号分隔的点 ID 列表,或特殊的引用符$-.id。详情参见管道符。
<edge_type_list>:遍历的 Edge type 列表。
REVERSELY | BIDIRECT:默认情况下检索的是<vertex_list>的出边(正向),REVERSELY表示反向,即检索入边;BIDIRECT为双向,即检索正向和反向,通过返回<edge_type>._type字段判断方向,其正数为正向,负数为反向。
-
WHERE <conditions>:指定遍历的过滤条件。用户可以在起始点、目的点和边使用WHERE子句,还可以结合AND、OR、NOT、XOR一起使用。详情参见 WHERE。Note
遍历多个 Edge type 时,
WHERE子句有一些限制。例如不支持WHERE edge1.prop1 > edge2.prop2。
YIELD [DISTINCT] <return_list>:定义需要返回的输出。<return_list>建议使用 Schema 函数,当前支持src(edge)、dst(edge)、type(edge)等,暂不支持嵌套函数。详情参见 YIELD。
SAMPLE <sample_list>:用于在结果集中取样。详情参见 SAMPLE。
<limit_by_list_clause>:用于在遍历过程中逐步限制输出数量。详情参见 LIMIT。
GROUP BY:根据指定属性的值将输出分组。详情参见 GROUP BY。分组后需要再次使用YIELD定义需要返回的输出。
-
ORDER BY:指定输出结果的排序规则。详情参见 ORDER BY。Note
没有指定排序规则时,输出结果的顺序不是固定的。
LIMIT [<offset>,] <number_rows>]:限制输出结果的行数。详情参见 LIMIT。
示例¶
# 返回 player102 所属队伍。
nebula> GO FROM "player102" OVER serve YIELD dst(edge); ==》默认1跳
+-----------+
| dst(EDGE) |
+-----------+
| "team203" |
| "team204" |
+-----------+
# 返回距离 player102 两跳的朋友。
nebula> GO 2 STEPS FROM "player102" OVER follow YIELD dst(edge);
+-------------+
| dst(EDGE) |
+-------------+
| "player101" |
| "player125" |
| "player100" |
| "player102" |
| "player125" |
+-------------+
# 添加过滤条件。
nebula> GO FROM "player100", "player102" OVER serve \
WHERE properties(edge).start_year > 1995 \ ==》引起property返回hash map
YIELD DISTINCT properties($$).name AS team_name, properties(edge).start_year AS start_year, properties($^).name AS player_name;
+-----------------+------------+---------------------+
| team_name | start_year | player_name |
+-----------------+------------+---------------------+
| "Spurs" | 1997 | "Tim Duncan" |
| "Trail Blazers" | 2006 | "LaMarcus Aldridge" |
| "Spurs" | 2015 | "LaMarcus Aldridge" |
+-----------------+------------+---------------------+
# 遍历多个 Edge type。属性没有值时,会显示 UNKNOWN_PROP。
nebula> GO FROM "player100" OVER follow, serve \
YIELD properties(edge).degree, properties(edge).start_year;
+-------------------------+-----------------------------+
| properties(EDGE).degree | properties(EDGE).start_year |
+-------------------------+-----------------------------+
| 95 | UNKNOWN_PROP |
| 95 | UNKNOWN_PROP |
| UNKNOWN_PROP | 1997 |
+-------------------------+-----------------------------+
# 返回 player100 入方向的邻居点。
nebula> GO FROM "player100" OVER follow REVERSELY \
YIELD src(edge) AS destination;
+-------------+
| destination |
+-------------+
| "player101" |
| "player102" |
...
# 该 MATCH 查询与上一个 GO 查询具有相同的语义。
nebula> MATCH (v)<-[e:follow]- (v2) WHERE id(v) == 'player100' \
RETURN id(v2) AS destination;
+-------------+
| destination |
+-------------+
| "player101" |
| "player102" |
...
# 查询 player100 的朋友和朋友所属队伍。
nebula> GO FROM "player100" OVER follow REVERSELY \
YIELD src(edge) AS id | \
GO FROM $-.id OVER serve \
WHERE properties($^).age > 20 \
YIELD properties($^).name AS FriendOf, properties($$).name AS Team;
+---------------------+-----------------+
| FriendOf | Team |
+---------------------+-----------------+
| "Boris Diaw" | "Spurs" |
| "Boris Diaw" | "Jazz" |
| "Boris Diaw" | "Suns" |
...
# 该 MATCH 查询与上一个 GO 查询具有相同的语义。==》写起来更直观!!!不像上面那样,还需要自己去画图绕下。。。
nebula> MATCH (v)<-[e:follow]- (v2)-[e2:serve]->(v3) \
WHERE id(v) == 'player100' \
RETURN v2.player.name AS FriendOf, v3.team.name AS Team;
+---------------------+-----------------+
| FriendOf | Team |
+---------------------+-----------------+
| "Boris Diaw" | "Spurs" |
| "Boris Diaw" | "Jazz" |
| "Boris Diaw" | "Suns" |
...
# 查询 player100 1~2 跳内的朋友。
nebula> GO 1 TO 2 STEPS FROM "player100" OVER follow \
YIELD dst(edge) AS destination;
+-------------+
| destination |
+-------------+
| "player101" |
| "player125" |
...
# 该 MATCH 查询与上一个 GO 查询具有相同的语义。
nebula> MATCH (v) -[e:follow*1..2]->(v2) \
WHERE id(v) == "player100" \
RETURN id(v2) AS destination;
+-------------+
| destination |
+-------------+
| "player100" |
| "player102" |
...
# 根据年龄分组。
nebula> GO 2 STEPS FROM "player100" OVER follow \
YIELD src(edge) AS src, dst(edge) AS dst, properties($$).age AS age \
| GROUP BY $-.dst \
YIELD $-.dst AS dst, collect_set($-.src) AS src, collect($-.age) AS age;
+-------------+----------------------------+----------+
| dst | src | age |
+-------------+----------------------------+----------+
| "player125" | ["player101"] | [41] |
| "player100" | ["player125", "player101"] | [42, 42] |
| "player102" | ["player101"] | [33] |
+-------------+----------------------------+----------+
# 分组并限制输出结果的行数。
nebula> $a = GO FROM "player100" OVER follow YIELD src(edge) AS src, dst(edge) AS dst; \
GO 2 STEPS FROM $a.dst OVER follow \
YIELD $a.src AS src, $a.dst, src(edge), dst(edge) \
| ORDER BY $-.src | OFFSET 1 LIMIT 2;
+-------------+-------------+-------------+-------------+
| src | $a.dst | src(EDGE) | dst(EDGE) |
+-------------+-------------+-------------+-------------+
| "player100" | "player125" | "player100" | "player101" |
| "player100" | "player101" | "player100" | "player125" |
+-------------+-------------+-------------+-------------+
# 在多个边上通过 IS NOT EMPTY 进行判断。
nebula> GO FROM "player100" OVER follow WHERE properties($$).name IS NOT EMPTY YIELD dst(edge);
+-------------+
| dst(EDGE) |
+-------------+
| "player125" |
| "player101" |
+-------------+
FETCH¶
FETCH可以获取指定点或边的属性值。
openCypher 兼容性¶
本文操作仅适用于原生 nGQL。
获取点的属性值¶
语法¶
FETCH PROP ON {<tag_name>[, tag_name ...] | *}
<vid> [, vid ...]
YIELD <return_list> [AS <alias>];
| 参数 | 说明 |
|---|---|
tag_name |
Tag 名称。 |
* |
表示当前图空间中的所有 Tag。 |
vid |
点 ID。 |
YIELD |
定义需要返回的输出。详情请参见 YIELD。 |
AS |
设置别名。 |
基于 Tag 获取点的属性值¶
在FETCH语句中指定 Tag 获取对应点的属性值。
nebula> FETCH PROP ON player "player100" YIELD properties(vertex);
+-------------------------------+
| properties(VERTEX) |
+-------------------------------+
| {age: 42, name: "Tim Duncan"} |
+-------------------------------+
获取点的指定属性值¶
使用YIELD子句指定返回的属性。
nebula> FETCH PROP ON player "player100" \
YIELD properties(vertex).name AS name;
+--------------+
| name |
+--------------+
| "Tim Duncan" |
+--------------+
获取多个点的属性值¶
指定多个点 ID 获取多个点的属性值,点之间用英文逗号(,)分隔。
nebula> FETCH PROP ON player "player101", "player102", "player103" YIELD properties(vertex);
+--------------------------------------+
| properties(VERTEX) |
+--------------------------------------+
| {age: 33, name: "LaMarcus Aldridge"} |
| {age: 40, name: "Tony Parker"} |
| {age: 32, name: "Rudy Gay"} |
+--------------------------------------+
基于多个 Tag 获取点的属性值¶
在FETCH语句中指定多个 Tag 获取属性值。Tag 之间用英文逗号(,)分隔。
# 创建新 Tag t1。
nebula> CREATE TAG IF NOT EXISTS t1(a string, b int);
# 为点 player100 添加 Tag t1。
nebula> INSERT VERTEX t1(a, b) VALUES "player100":("Hello", 100);
# 基于 Tag player 和 t1 获取点 player100 上的属性值。
nebula> FETCH PROP ON player, t1 "player100" YIELD vertex AS v;
+----------------------------------------------------------------------------+
| v |
+----------------------------------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"} :t1{a: "Hello", b: 100}) |
+----------------------------------------------------------------------------+
用户可以在FETCH语句中组合多个 Tag 和多个点。
nebula> FETCH PROP ON player, t1 "player100", "player103" YIELD vertex AS v;
+----------------------------------------------------------------------------+
| v |
+----------------------------------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"} :t1{a: "Hello", b: 100}) |
| ("player103" :player{age: 32, name: "Rudy Gay"}) |
+----------------------------------------------------------------------------+
在所有标签中获取点的属性值¶
在FETCH语句中使用*获取当前图空间所有标签里,点的属性值。
nebula> FETCH PROP ON * "player100", "player106", "team200" YIELD vertex AS v;
+----------------------------------------------------------------------------+
| v |
+----------------------------------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"} :t1{a: "Hello", b: 100}) |
| ("player106" :player{age: 25, name: "Kyle Anderson"}) |
| ("team200" :team{name: "Warriors"}) |
+----------------------------------------------------------------------------+
获取边的属性值¶
语法¶
FETCH PROP ON <edge_type> <src_vid> -> <dst_vid>[@<rank>] [, <src_vid> -> <dst_vid> ...]
YIELD <output>;
| 参数 | 说明 |
|---|---|
edge_type |
Edge type 名称。 |
src_vid |
起始点 ID,表示边的起点。 |
dst_vid |
目的点 ID,表示边的终点。 |
rank |
边的 rank。可选参数,默认值为0。起始点、目的点、Edge type 和 rank 可以唯一确定一条边。 |
YIELD |
定义需要返回的输出。详情请参见 YIELD。 |
获取边的所有属性值¶
# 获取连接 player100 和 team204 的边 serve 的所有属性值。
nebula> FETCH PROP ON serve "player100" -> "team204" YIELD properties(edge);
+------------------------------------+
| properties(EDGE) |
+------------------------------------+
| {end_year: 2016, start_year: 1997} |
+------------------------------------+
获取边的指定属性值¶
使用YIELD子句指定返回的属性。
nebula> FETCH PROP ON serve "player100" -> "team204" \
YIELD properties(edge).start_year;
+-----------------------------+
| properties(EDGE).start_year |
+-----------------------------+
| 1997 |
+-----------------------------+
获取多条边的属性值¶
指定多个边模式 (<src_vid> -> <dst_vid>[@<rank>]) 获取多个边的属性值。模式之间用英文逗号(,)分隔。
nebula> FETCH PROP ON serve "player100" -> "team204", "player133" -> "team202" YIELD edge AS e;
+-----------------------------------------------------------------------+
| e |
+-----------------------------------------------------------------------+
| [:serve "player100"->"team204" @0 {end_year: 2016, start_year: 1997}] |
| [:serve "player133"->"team202" @0 {end_year: 2011, start_year: 2002}] |
+-----------------------------------------------------------------------+
基于 rank 获取属性值¶
如果有多条边,起始点、目的点和 Edge type 都相同,可以通过指定 rank 获取正确的边属性值。
# 插入不同属性值、不同 rank 的边。
nebula> insert edge serve(start_year,end_year) \
values "player100"->"team204"@1:(1998, 2017);==》这个是啥?rank吧?
nebula> insert edge serve(start_year,end_year) \
values "player100"->"team204"@2:(1990, 2018);
# 默认返回 rank 为 0 的边。
nebula> FETCH PROP ON serve "player100" -> "team204" YIELD edge AS e;
+-----------------------------------------------------------------------+
| e |
+-----------------------------------------------------------------------+
| [:serve "player100"->"team204" @0 {end_year: 2016, start_year: 1997}] |
+-----------------------------------------------------------------------+
# 要获取 rank 不为 0 的边,请在 FETCH 语句中设置 rank。
nebula> FETCH PROP ON serve "player100" -> "team204"@1 YIELD edge AS e;
+-----------------------------------------------------------------------+
| e |
+-----------------------------------------------------------------------+
| [:serve "player100"->"team204" @1 {end_year: 2017, start_year: 1998}] |
+-----------------------------------------------------------------------+
复合语句中使用 FETCH¶
将FETCH与原生 nGQL 结合使用是一种常见的方式,例如和GO一起。
# 返回从点 player101 开始的 follow 边的 degree 值。
nebula> GO FROM "player101" OVER follow \
YIELD src(edge) AS s, dst(edge) AS d \
| FETCH PROP ON follow $-.s -> $-.d \
YIELD properties(edge).degree;
+-------------------------+
| properties(EDGE).degree |
+-------------------------+
| 95 |
| 90 |
| 95 |
+-------------------------+
用户也可以通过自定义变量构建类似的查询。
nebula> $var = GO FROM "player101" OVER follow \
YIELD src(edge) AS s, dst(edge) AS d; \
FETCH PROP ON follow $var.s -> $var.d \
YIELD properties(edge).degree;
+-------------------------+
| properties(EDGE).degree |
+-------------------------+
| 95 |
| 90 |
| 95 |
+-------------------------+
更多复合语句的详情,请参见复合查询(子句结构)。
索引介绍¶
Nebula Graph 支持两种类型索引:原生索引和全文索引。
和一般数据库意义上的索引概念不同,Nebula Graph中的索引没有加速查询的功能,是用于定位到数据的必要前置条件。==》从这里可看出图数据库的内在实现,索引定位到V、E,然后才使用图的查找算法。
原生索引¶
原生索引可以基于指定的属性查询数据,有如下特点:
- 包括 Tag 索引和 Edge type 索引。
- 必须手动重建索引(
REBUILD INDEX)。
- 支持创建同一个 Tag 或 Edge type 的多个属性的索引(复合索引),但是不能跨 Tag 或 Edge type。
原生索引操作¶
全文索引¶
全文索引是基于Elastic Search来实现的,用于对字符串属性进行前缀搜索、通配符搜索、正则表达式搜索和模糊搜索,有如下特点:
- 只允许创建一个属性的索引。
- 只能创建指定长度(不超过 256 字节)字符串的索引。
- 不支持逻辑操作,例如
AND、OR、NOT。
Note
如果需要进行整个字符串的匹配,请使用原生索引。
全文索引操作¶
在对全文索引执行任何操作之前,请确保已经部署全文索引。详情请参见部署全文索引 和部署 listener。==》是和ES配合使用的,ES建立索引,nebula图存储,二者交互实现全文检索。
部署完成后,Elasticsearch 集群上会自动创建全文索引。不支持重建或修改全文索引。如果需要删除全文索引,请在 Elasticsearch 集群上手动删除。
使用全文索引请参见使用全文索引查询。
全文检索的一个示例:
示例¶
//创建图空间。
nebula> CREATE SPACE IF NOT EXISTS basketballplayer (partition_num=3,replica_factor=1, vid_type=fixed_string(30));
//登录文本搜索客户端。
nebula> SIGN IN TEXT SERVICE (127.0.0.1:9200, HTTP);
//切换图空间。
nebula> USE basketballplayer;
//添加 listener 到 Nebula Graph 集群。
nebula> ADD LISTENER ELASTICSEARCH 192.168.8.5:9789;
//创建 Tag。
nebula> CREATE TAG IF NOT EXISTS player(name string, age int);
//创建原生索引。
nebula> CREATE TAG INDEX IF NOT EXISTS name ON player(name(20));
//重建原生索引。
nebula> REBUILD TAG INDEX;
//创建全文索引,索引名称需要以 nebula 开头。
nebula> CREATE FULLTEXT TAG INDEX nebula_index_1 ON player(name);
//重建全文索引。
nebula> REBUILD FULLTEXT INDEX;
//查看全文索引。
nebula> SHOW FULLTEXT INDEXES;
+------------------+-------------+-------------+--------+
| Name | Schema Type | Schema Name | Fields |
+------------------+-------------+-------------+--------+
| "nebula_index_1" | "Tag" | "player" | "name" |
+------------------+-------------+-------------+--------+
//插入测试数据。
nebula> INSERT VERTEX player(name, age) VALUES \
"Russell Westbrook": ("Russell Westbrook", 30), \
"Chris Paul": ("Chris Paul", 33),\
"Boris Diaw": ("Boris Diaw", 36),\
"David West": ("David West", 38),\
"Danny Green": ("Danny Green", 31),\
"Tim Duncan": ("Tim Duncan", 42),\
"James Harden": ("James Harden", 29),\
"Tony Parker": ("Tony Parker", 36),\
"Aron Baynes": ("Aron Baynes", 32),\
"Ben Simmons": ("Ben Simmons", 22),\
"Blake Griffin": ("Blake Griffin", 30);
//测试查询
nebula> LOOKUP ON player WHERE PREFIX(player.name, "B") YIELD id(vertex);
+-----------------+
| id(VERTEX) |
+-----------------+
| "Boris Diaw" |
| "Ben Simmons" |
| "Blake Griffin" |
+-----------------+
nebula> LOOKUP ON player WHERE WILDCARD(player.name, "*ri*") YIELD player.name, player.age;
+-----------------+-----+
| name | age |
+-----------------+-----+
| "Chris Paul" | 33 |
| "Boris Diaw" | 36 |
| "Blake Griffin" | 30 |
+-----------------+-----+
nebula> LOOKUP ON player WHERE WILDCARD(player.name, "*ri*") | YIELD count(*);
+----------+
| count(*) |
+----------+
| 3 |
+----------+
nebula> LOOKUP ON player WHERE REGEXP(player.name, "R.*") YIELD player.name, player.age;
+---------------------+-----+
| name | age |
+---------------------+-----+
| "Russell Westbrook" | 30 |
+---------------------+-----+
nebula> LOOKUP ON player WHERE REGEXP(player.name, ".*") YIELD id(vertex);
+---------------------+
| id(VERTEX) |
+---------------------+
| "Danny Green" |
| "David West" |
| "Russell Westbrook" |
+---------------------+
...
nebula> LOOKUP ON player WHERE FUZZY(player.name, "Tim Dunncan", AUTO, OR) YIELD player.name;
+--------------+
| name |
+--------------+
| "Tim Duncan" |
+--------------+
//删除全文索引。
nebula> DROP FULLTEXT INDEX nebula_index_1;
GET SUBGRAPH¶
GET SUBGRAPH语句检索指定 Edge type 的起始点可以到达的点和边的信息,返回子图信息。
语法¶
GET SUBGRAPH [WITH PROP] [<step_count> STEPS] FROM {<vid>, <vid>...}
[{IN | OUT | BOTH} <edge_type>, <edge_type>...]
YIELD [VERTICES AS <vertex_alias>] [, EDGES AS <edge_alias>];
WITH PROP:展示属性。不添加本参数则隐藏属性。
step_count:指定从起始点开始的跳数,返回从 0 到step_count跳的子图。必须是非负整数。默认值为 1。
vid:指定起始点 ID。
edge_type:指定 Edge type。可以用IN、OUT和BOTH来指定起始点上该 Edge type 的方向。默认为BOTH。
YIELD:定义需要返回的输出。可以仅返回点或边。必须设置别名。
Note
GET SUBGRAPH语句检索的路径类型为trail,即检索的路径只有点可以重复,边不可以重复。详情请参见路径。
示例¶
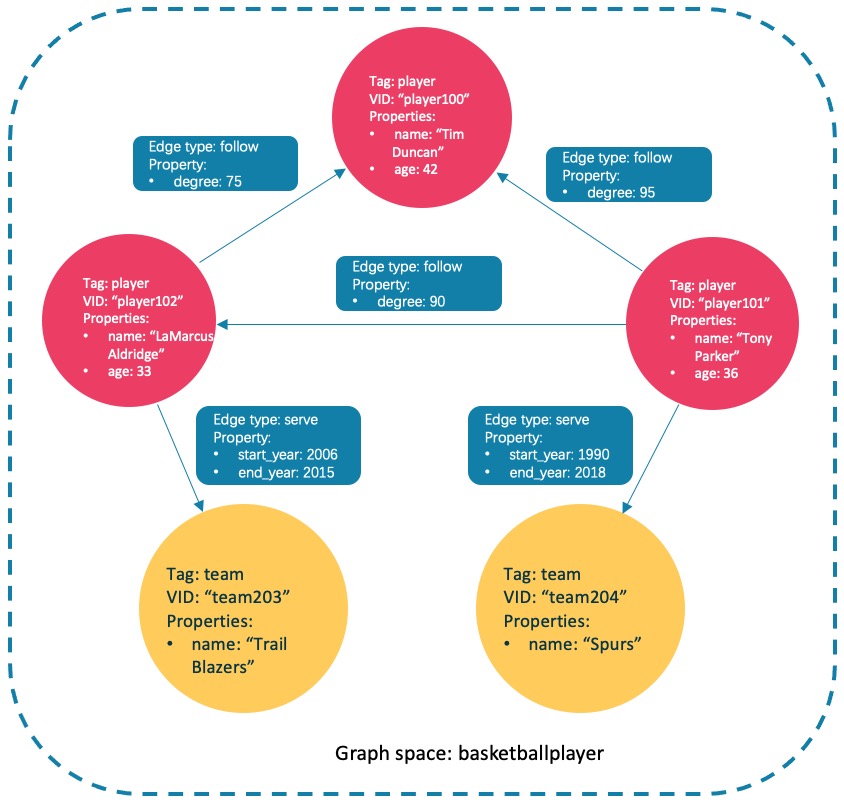
以下面的示例图进行演示。
插入测试数据:
nebula> CREATE SPACE IF NOT EXISTS subgraph(partition_num=15, replica_factor=1, vid_type=fixed_string(30));
nebula> USE subgraph;
nebula> CREATE TAG IF NOT EXISTS player(name string, age int);
nebula> CREATE TAG IF NOT EXISTS team(name string);
nebula> CREATE EDGE IF NOT EXISTS follow(degree int);
nebula> CREATE EDGE IF NOT EXISTS serve(start_year int, end_year int);
nebula> INSERT VERTEX player(name, age) VALUES "player100":("Tim Duncan", 42);
nebula> INSERT VERTEX player(name, age) VALUES "player101":("Tony Parker", 36);
nebula> INSERT VERTEX player(name, age) VALUES "player102":("LaMarcus Aldridge", 33);
nebula> INSERT VERTEX team(name) VALUES "team203":("Trail Blazers"), "team204":("Spurs");
nebula> INSERT EDGE follow(degree) VALUES "player101" -> "player100":(95);
nebula> INSERT EDGE follow(degree) VALUES "player101" -> "player102":(90);
nebula> INSERT EDGE follow(degree) VALUES "player102" -> "player100":(75);
nebula> INSERT EDGE serve(start_year, end_year) VALUES "player101" -> "team204":(1999, 2018),"player102" -> "team203":(2006, 2015);
- 查询从点
player101开始、0~1 跳、所有 Edge type 的子图。
-
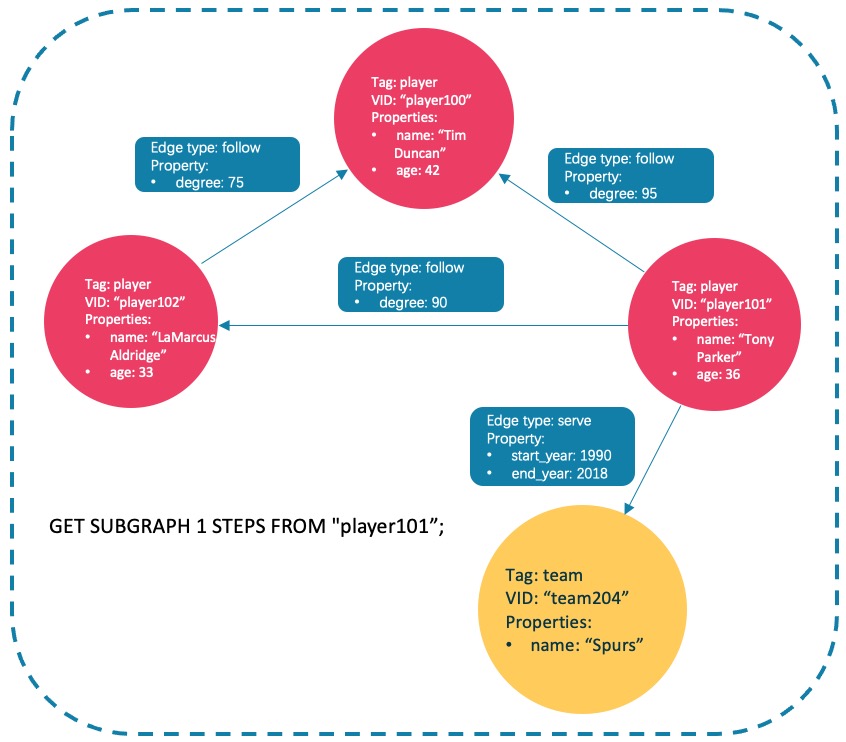
nebula> GET SUBGRAPH 1 STEPS FROM "player101" YIELD VERTICES AS nodes, EDGES AS relationships; +-------------------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------------------------+ | nodes | relationships | +-------------------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------------------------+ | [("player101" :player{})] | [[:serve "player101"->"team204" @0 {}], [:follow "player101"->"player100" @0 {}], [:follow "player101"->"player102" @0 {}]] |==》这个我能够理解!!!下面的为啥team204也冒出来了?? | [("team204" :team{}), ("player100" :player{}), ("player102" :player{})] | [[:follow "player102"->"player100" @0 {}]] | +-------------------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------------------------+返回的子图如下。
![GET SUBGRAPH FROM "player101"]()
- 查询从点
player101开始、0~1 跳、follow类型的入边的子图。
-
nebula> GET SUBGRAPH 1 STEPS FROM "player101" IN follow YIELD VERTICES AS nodes, EDGES AS relationships; +---------------------------+---------------+ | nodes | relationships | +---------------------------+---------------+ | [("player101" :player{})] | [] | | [] | [] | +---------------------------+---------------+因为
player101没有follow类型的入边。所以仅返回点player101。
- 查询从点
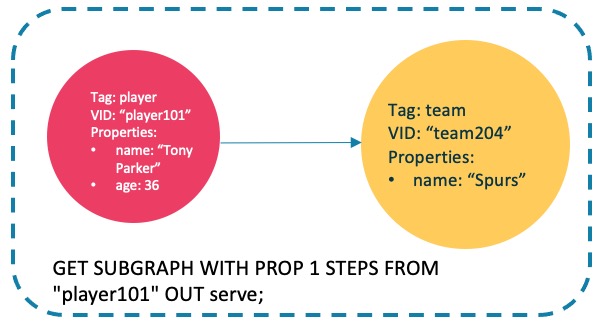
player101开始、0~1 跳、serve类型的出边的子图,同时展示边的属性。
-
nebula> GET SUBGRAPH WITH PROP 1 STEPS FROM "player101" OUT serve YIELD VERTICES AS nodes, EDGES AS relationships; +-------------------------------------------------------+-------------------------------------------------------------------------+ | nodes | relationships | +-------------------------------------------------------+-------------------------------------------------------------------------+ | [("player101" :player{age: 36, name: "Tony Parker"})] | [[:serve "player101"->"team204" @0 {end_year: 2018, start_year: 1999}]] | | [("team204" :team{name: "Spurs"})] | [] | +-------------------------------------------------------+-------------------------------------------------------------------------+返回的子图如下。
![GET SUBGRAPH FROM "101" OUT serve]()
FAQ¶
为什么返回结果中会出现超出step_count跳数之外的关系?¶
为了展示子图的完整性,会在满足条件的所有点上额外查询一跳。例如下图。
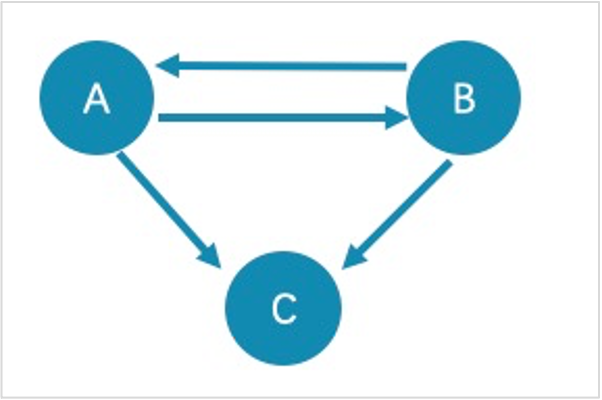
- 用
GET SUBGRAPH 1 STEPS FROM "A";查询的满足结果的路径是A->B、B->A和A->C,为了子图的完整性,会在满足结果的点上额外查询一跳,即B->C。==》啥情况,,,没有看懂为啥这么做。。。
- 用
GET SUBGRAPH 1 STEPS FROM "A" IN follow;查询的满足结果的路径是B->A,在满足结果的点上额外查询一跳,即A->B。
如果只是查询满足条件的路径或点,建议使用 MATCH 或 GO 语句。例如:
nebula> MATCH p= (v:player) -- (v2) WHERE id(v)=="A" RETURN p;
nebula> GO 1 STEPS FROM "A" OVER follow YIELD src(edge),dst(edge);
为什么返回结果中会出现低于step_count跳数的关系?¶
查询到没有多余子图数据时会停止查询,且不会返回空值。
nebula> GET SUBGRAPH 100 STEPS FROM "player101" OUT follow YIELD VERTICES AS nodes, EDGES AS relationships;
+----------------------------------------------------+--------------------------------------------------------------------------------------+
| nodes | relationships |
+----------------------------------------------------+--------------------------------------------------------------------------------------+
| [("player101" :player{})] | [[:follow "player101"->"player100" @0 {}], [:follow "player101"->"player102" @0 {}]] |
| [("player100" :player{}), ("player102" :player{})] | [[:follow "player102"->"player100" @0 {}]] |
+----------------------------------------------------+--------------------------------------------------------------------------------------+FIND PATH¶
FIND PATH语句查找指定起始点和目的点之间的路径。
语法¶
FIND { SHORTEST | ALL | NOLOOP } PATH [WITH PROP] FROM <vertex_id_list> TO <vertex_id_list>
OVER <edge_type_list> [REVERSELY | BIDIRECT]
[<WHERE clause>] [UPTO <N> STEPS]
YIELD path as <alias>
[| ORDER BY $-.path] [| LIMIT <M>];
<vertex_id_list> ::=
[vertex_id [, vertex_id] ...]
SHORTEST:查找最短路径。
ALL:查找所有路径。
NOLOOP:查找非循环路径。
WITH PROP:展示点和边的属性。不添加本参数则隐藏属性。
<vertex_id_list>:点 ID 列表。多个点用英文逗号(,)分隔。支持$-和$var。
<edge_type_list>:Edge type 列表。多个 Edge type 用英文逗号(,)分隔。*表示所有 Edge type。
REVERSELY | BIDIRECT:REVERSELY表示反向,BIDIRECT表示双向。
<WHERE clause>:可以使用WHERE子句过滤边属性。
<N>:路径的最大跳数。默认值为5。
<M>:指定返回的最大行数。
Note
FIND PATH语句检索的路径类型为trail,即检索的路径只有点可以重复,边不可以重复。详情请参见路径。
限制¶
- 指定起始点和目的点的列表后,会返回起始点和目的点所有组合的路径。
- 搜索所有路径时可能会出现循环。
- 使用
WHERE子句时只能过滤边属性,暂不支持过滤点属性,且不支持函数。
- graphd 是单进程查询,会占用很多内存。
示例¶
返回的路径格式类似于(<vertex_id>)-[:<edge_type_name>@<rank>]->(<vertex_id)。
nebula> FIND SHORTEST PATH FROM "player102" TO "team204" OVER * YIELD path AS p;
+--------------------------------------------+
| p |
+--------------------------------------------+
| <("player102")-[:serve@0 {}]->("team204")> |
+--------------------------------------------+
为啥是上面的结果,分析下:
(root@nebula) [basketballplayer]> FIND SHORTEST PATH FROM "player102" TO "team204" OVER * YIELD path AS p;
+--------------------------------------------+
| p |
+--------------------------------------------+
| <("player102")-[:serve@0 {}]->("team204")> |
+--------------------------------------------+
Got 1 rows (time spent 737/995 us)
Tue, 24 May 2022 20:02:34 CST
(root@nebula) [basketballplayer]> FIND all PATH FROM "player102" TO "team204" OVER * YIELD path AS p;
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| p |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| <("player102")-[:follow@0 {}]->("player101")-[:serve@0 {}]->("team204")> |
| <("player102")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player100")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player101")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player125")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player125")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player102")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player125")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player100")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player125")-[:follow@0 {}]->("player100")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player125")-[:follow@0 {}]->("player100")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player100")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player102")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player125")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player101")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player102")-[:follow@0 {}]->("player100")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player102")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player125")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player125")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player125")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player125")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player101")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player125")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player101")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player125")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player102")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player125")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player102")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player101")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player125")-[:follow@0 {}]->("player100")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player125")-[:follow@0 {}]->("player100")-[:serve@0 {}]->("team204")> |
| <("player102")-[:follow@0 {}]->("player100")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player102")-[:follow@0 {}]->("player101")-[:serve@0 {}]->("team204")> |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------+
Got 27 rows (time spent 2547/3444 us)
nebula> FIND SHORTEST PATH WITH PROP FROM "team204" TO "player100" OVER * REVERSELY YIELD path AS p;
+--------------------------------------------------------------------------------------------------------------------------------------+
| p |
+--------------------------------------------------------------------------------------------------------------------------------------+
| <("team204" :team{name: "Spurs"})<-[:serve@0 {end_year: 2016, start_year: 1997}]-("player100" :player{age: 42, name: "Tim Duncan"})> |
+--------------------------------------------------------------------------------------------------------------------------------------+
nebula> FIND ALL PATH FROM "player100" TO "team204" OVER * WHERE follow.degree is EMPTY or follow.degree >=0 YIELD path AS p;
+------------------------------------------------------------------------------+
| p |
+------------------------------------------------------------------------------+
| <("player100")-[:serve@0 {}]->("team204")> |
| <("player100")-[:follow@0 {}]->("player125")-[:serve@0 {}]->("team204")> |
| <("player100")-[:follow@0 {}]->("player101")-[:serve@0 {}]->("team204")> |
| ... |
+------------------------------------------------------------------------------+
nebula> FIND NOLOOP PATH FROM "player100" TO "team204" OVER * YIELD path AS p;
+--------------------------------------------------------------------------------------------------------+
| p |
+--------------------------------------------------------------------------------------------------------+
| <("player100")-[:serve@0 {}]->("team204")> |
| <("player100")-[:follow@0 {}]->("player125")-[:serve@0 {}]->("team204")> |
| <("player100")-[:follow@0 {}]->("player101")-[:serve@0 {}]->("team204")> |
| <("player100")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player125")-[:serve@0 {}]->("team204")> |
| <("player100")-[:follow@0 {}]->("player101")-[:follow@0 {}]->("player102")-[:serve@0 {}]->("team204")> |
| ... |
+--------------------------------------------------------------------------------------------------------+
FAQ¶
是否支持 WHERE 子句,以实现图遍历过程中的条件过滤?¶
支持使用WHERE子句过滤,但只能过滤边属性,不支持过滤点属性。
如示例中的 WHERE follow.degree is EMPTY or follow.degree >= 0。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号